 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferAD-R1: A Difference-Guided IndustrialAnomaly Localization with Multimodal LargeLanguage Models
Jun 15, 2026Industrial anomaly localization aims to accurately identify and localize abnormal regions in industrial products, addressing the critical challenge of detecting unseen defect categories in real-world scenarios. Traditional closed-set methods often suffer from poor cross-scenario generalization, while existingMultimodal Large Language Model (MLLM)-based approachesface two core limitations: they either adopt QA-style paradigmsmisaligned with the practical demands of localization, or relyon standard optimization techniques such as Group RelativePolicy Optimization (GRPO), which fails to deliver effectivelearning signals for subtle defects. To tackle these issues, thispaper proposes DifferAD-R1, an MLLM-augmented reinforcement learning framework tailored for industrial anomaly localization. We design a Difference-Guided dual-image paradigm,which reformulates the localization task as a one-shot difference grounding problem to effectively explore cross-scenarioanomalies. A Dual-Consistency Localization Reward is developedfor hard-to-detect anomalies, enhancing optimization stabilityand robustness. Additionally, we integrate a difficulty-awarestrategy with adaptive reweighting and group-wise resamplingto prioritize learning on challenging instances. To facilitateevaluations in real-world industrial settings, we construct theAD-DualDiff dataset, comprising 13K paired images across 20categories. Experimental results demonstrate that DifferADR1 significantly outperforms existing baselines and achievescompetitive performance compared to large-scale models likeQwen3-VL (235B parameters). Our code is publicly availableat: https://github.com/Rong2026/work-1.
AG-VAS: Anchor-Guided Zero-Shot Visual Anomaly Segmentation with Large Multimodal Models
Mar 01, 2026Large multimodal models (LMMs) exhibit strong task generalization capabilities, offering new opportunities for zero-shot visual anomaly segmentation (ZSAS). However, existing LMM-based segmentation approaches still face fundamental limitations: anomaly concepts are inherently abstract and context-dependent, lacking stable visual prototypes, and the weak alignment between high-level semantic embeddings and pixel-level spatial features hinders precise anomaly localization. To address these challenges, we present AG-VAS (Anchor-Guided Visual Anomaly Segmentation), a new framework that expands the LMM vocabulary with three learnable semantic anchor tokens-[SEG], [NOR], and [ANO], establishing a unified anchor-guided segmentation paradigm. Specifically, [SEG] serves as an absolute semantic anchor that translates abstract anomaly semantics into explicit, spatially grounded visual entities (e.g., holes or scratches), while [NOR] and [ANO] act as relative anchors that model the contextual contrast between normal and abnormal patterns across categories. To further enhance cross-modal alignment, we introduce a Semantic-Pixel Alignment Module (SPAM) that aligns language-level semantic embeddings with high-resolution visual features, along with an Anchor-Guided Mask Decoder (AGMD) that performs anchor-conditioned mask prediction for precise anomaly localization. In addition, we curate Anomaly-Instruct20K, a large-scale instruction dataset that organizes anomaly knowledge into structured descriptions of appearance, shape, and spatial attributes, facilitating effective learning and integration of the proposed semantic anchors. Extensive experiments on six industrial and medical benchmarks demonstrate that AG-VAS achieves consistent state-of-the-art performance in the zero-shot setting.
Reinforced Compressive Neural Architecture Search for Versatile Adversarial Robustness
Jun 10, 2024



Prior neural architecture search (NAS) for adversarial robustness works have discovered that a lightweight and adversarially robust neural network architecture could exist in a non-robust large teacher network, generally disclosed by heuristic rules through statistical analysis and neural architecture search, generally disclosed by heuristic rules from neural architecture search. However, heuristic methods cannot uniformly handle different adversarial attacks and "teacher" network capacity. To solve this challenge, we propose a Reinforced Compressive Neural Architecture Search (RC-NAS) for Versatile Adversarial Robustness. Specifically, we define task settings that compose datasets, adversarial attacks, and teacher network information. Given diverse tasks, we conduct a novel dual-level training paradigm that consists of a meta-training and a fine-tuning phase to effectively expose the RL agent to diverse attack scenarios (in meta-training), and making it adapt quickly to locate a sub-network (in fine-tuning) for any previously unseen scenarios. Experiments show that our framework could achieve adaptive compression towards different initial teacher networks, datasets, and adversarial attacks, resulting in more lightweight and adversarially robust architectures.
LIBR+: Improving Intraoperative Liver Registration by Learning the Residual of Biomechanics-Based Deformable Registration
Mar 11, 2024



The surgical environment imposes unique challenges to the intraoperative registration of organ shapes to their preoperatively-imaged geometry. Biomechanical model-based registration remains popular, while deep learning solutions remain limited due to the sparsity and variability of intraoperative measurements and the limited ground-truth deformation of an organ that can be obtained during the surgery. In this paper, we propose a novel \textit{hybrid} registration approach that leverage a linearized iterative boundary reconstruction (LIBR) method based on linear elastic biomechanics, and use deep neural networks to learn its residual to the ground-truth deformation (LIBR+). We further formulate a dual-branch spline-residual graph convolutional neural network (SR-GCN) to assimilate information from sparse and variable intraoperative measurements and effectively propagate it through the geometry of the 3D organ. Experiments on a large intraoperative liver registration dataset demonstrated the consistent improvements achieved by LIBR+ in comparison to existing rigid, biomechnical model-based non-rigid, and deep-learning based non-rigid approaches to intraoperative liver registration.
Deep Reinforced Attention Regression for Partial Sketch Based Image Retrieval
Nov 21, 2021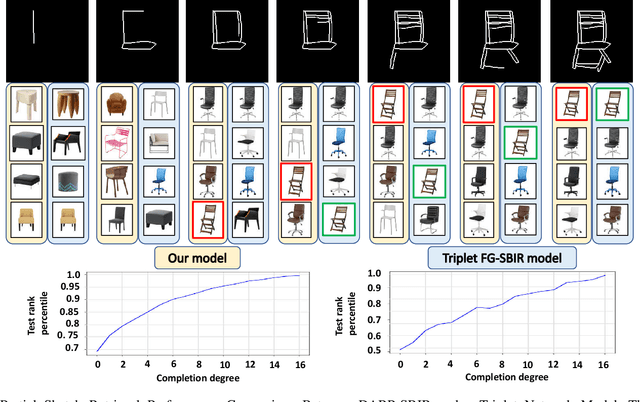
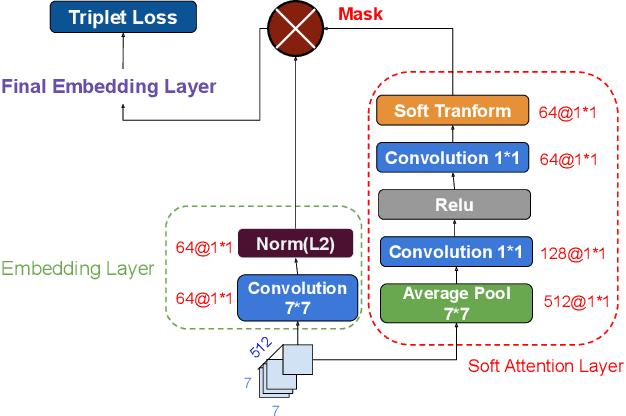
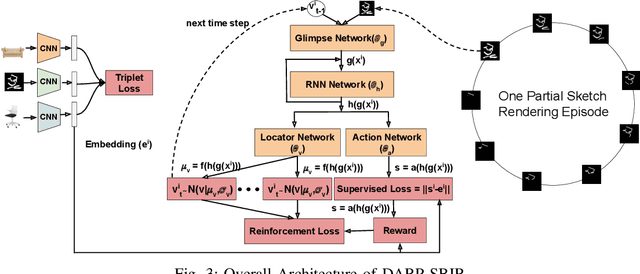
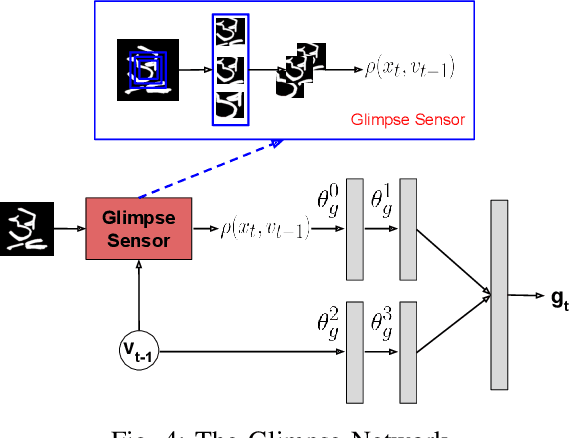
Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) aims at finding a specific image from a large gallery given a query sketch. Despite the widespread applicability of FG-SBIR in many critical domains (e.g., crime activity tracking), existing approaches still suffer from a low accuracy while being sensitive to external noises such as unnecessary strokes in the sketch. The retrieval performance will further deteriorate under a more practical on-the-fly setting, where only a partially complete sketch with only a few (noisy) strokes are available to retrieve corresponding images. We propose a novel framework that leverages a uniquely designed deep reinforcement learning model that performs a dual-level exploration to deal with partial sketch training and attention region selection. By enforcing the model's attention on the important regions of the original sketches, it remains robust to unnecessary stroke noises and improve the retrieval accuracy by a large margin. To sufficiently explore partial sketches and locate the important regions to attend, the model performs bootstrapped policy gradient for global exploration while adjusting a standard deviation term that governs a locator network for local exploration. The training process is guided by a hybrid loss that integrates a reinforcement loss and a supervised loss. A dynamic ranking reward is developed to fit the on-the-fly image retrieval process using partial sketches. The extensive experimentation performed on three public datasets shows that our proposed approach achieves the state-of-the-art performance on partial sketch based image retrieval.