 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PTDE: Personalized Training with Distillated Execution for Multi-Agent Reinforcement Learning
Oct 17, 2022
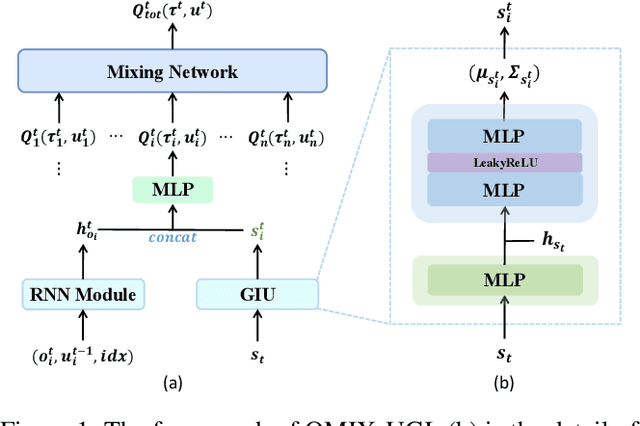
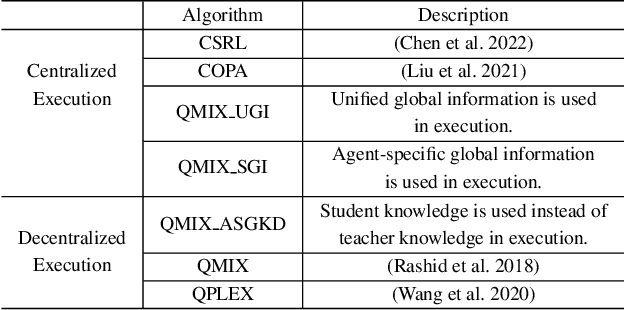
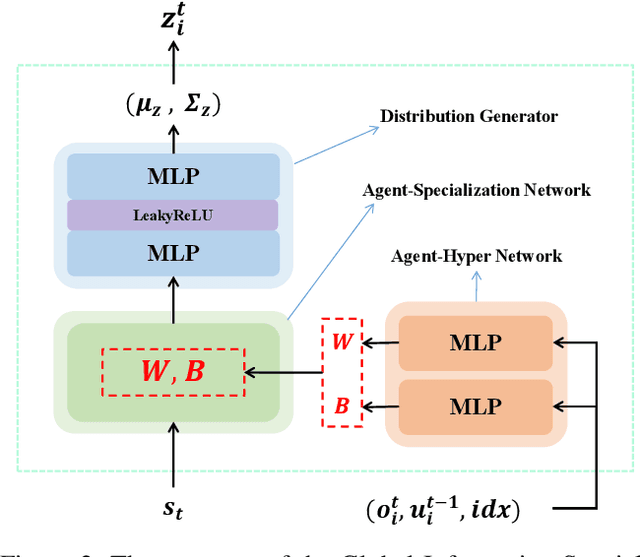
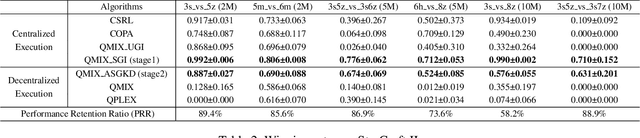
Centralized Training with Decentralized Execution (CTDE) has been a very popular paradigm for multi-agent reinforcement learning. One of its main features is making full use of the global information to learn a better joint $Q$-function or centralized critic. In this paper, we in turn explore how to leverage the global information to directly learn a better individual $Q$-function or individual actor. We find that applying the same global information to all agents indiscriminately is not enough for good performance, and thus propose to specify the global information for each agent to obtain agent-specific global information for better performance. Furthermore, we distill such agent-specific global information into the agent's local information, which is used during decentralized execution without too much performance degradation. We call this new paradigm Personalized Training with Distillated Execution (PTDE). PTDE can be easily combined with many state-of-the-art algorithms to further improve their performance, which is verified in both SMAC and Google Research Football scenarios.
AIONER: All-in-one scheme-based biomedical named entity recognition using deep learning
Dec 19, 2022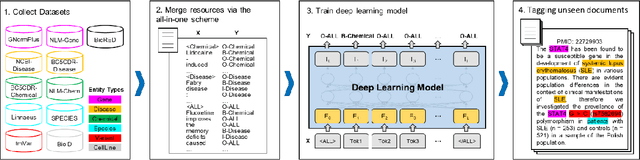
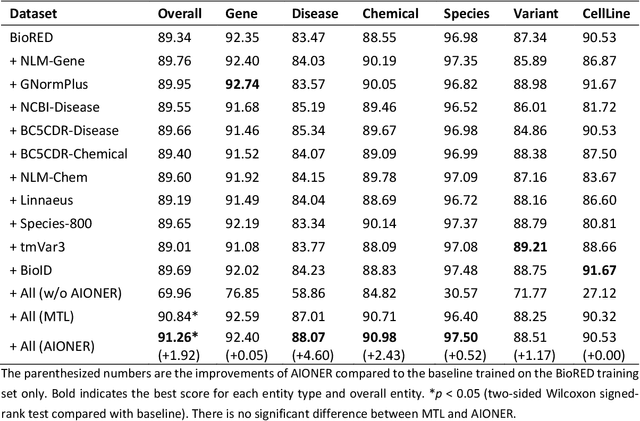
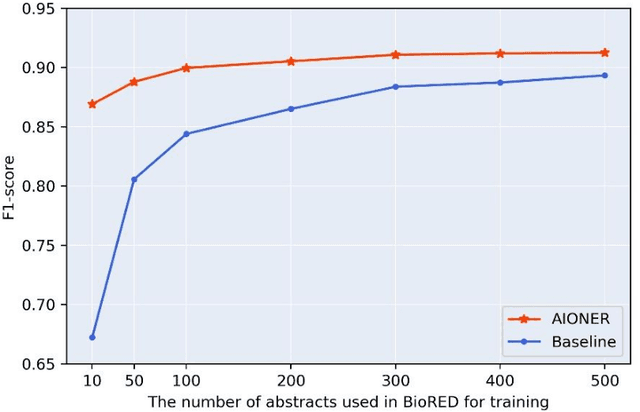
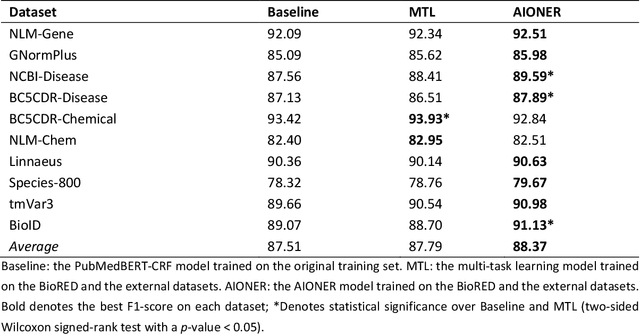
Biomedical named entity recognition (BioNER) seeks to automatically recognize biomedical entities in natural language text, serving as a necessary foundation for downstream text mining tasks and applications such as information extraction and question answering. Manually labeling training data for the BioNER task is costly, however, due to the significant domain expertise required for accurate annotation. The resulting data scarcity causes current BioNER approaches to be prone to overfitting, to suffer from limited generalizability, and to address a single entity type at a time (e.g., gene or disease). We therefore propose a novel all-in-one (AIO) scheme that uses external data from existing annotated resources to improve generalization. We further present AIONER, a general-purpose BioNER tool based on cutting-edge deep learning and our AIO schema. We evaluate AIONER on 14 BioNER benchmark tasks and show that AIONER is effective, robust, and compares favorably to other state-of-the-art approaches such as multi-task learning. We further demonstrate the practical utility of AIONER in three independent tasks to recognize entity types not previously seen in training data, as well as the advantages of AIONER over existing methods for processing biomedical text at a large scale (e.g., the entire PubMed data).
Multi hash embeddings in spaCy
Dec 19, 2022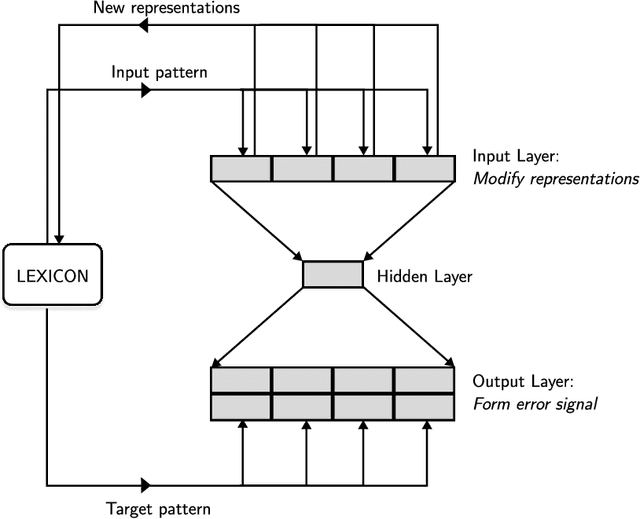


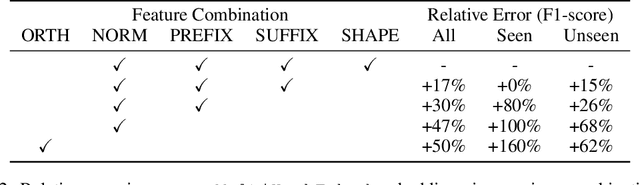
The distributed representation of symbols is one of the key technologies in machine learning systems today, playing a pivotal role in modern natural language processing. Traditional word embeddings associate a separate vector with each word. While this approach is simple and leads to good performance, it requires a lot of memory for representing a large vocabulary. To reduce the memory footprint, the default embedding layer in spaCy is a hash embeddings layer. It is a stochastic approximation of traditional embeddings that provides unique vectors for a large number of words without explicitly storing a separate vector for each of them. To be able to compute meaningful representations for both known and unknown words, hash embeddings represent each word as a summary of the normalized word form, subword information and word shape. Together, these features produce a multi-embedding of a word. In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy's embedders, but we also uncover a few surprising results.
Meta-Learning Fast Weight Language Models
Dec 05, 2022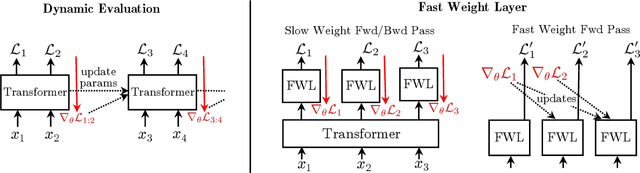
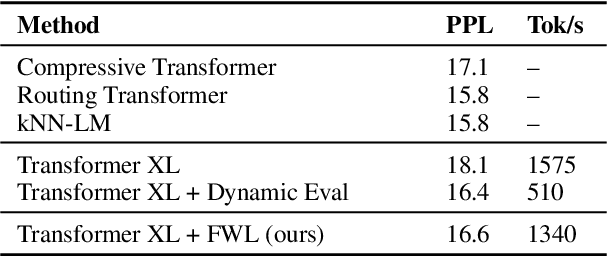
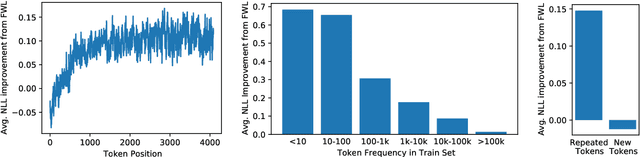
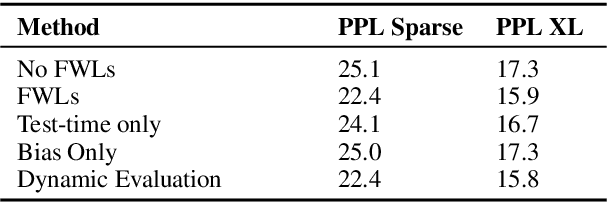
Dynamic evaluation of language models (LMs) adapts model parameters at test time using gradient information from previous tokens and substantially improves LM performance. However, it requires over 3x more compute than standard inference. We present Fast Weight Layers (FWLs), a neural component that provides the benefits of dynamic evaluation much more efficiently by expressing gradient updates as linear attention. A key improvement over dynamic evaluation is that FWLs can also be applied at training time so the model learns to make good use of gradient updates. FWLs can easily be added on top of existing transformer models, require relatively little extra compute or memory to run, and significantly improve language modeling perplexity.
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Dec 05, 2022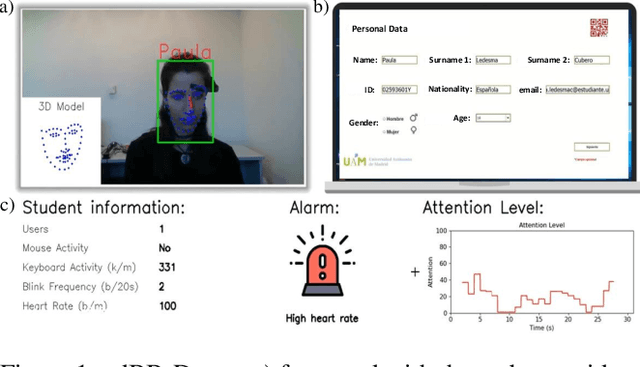
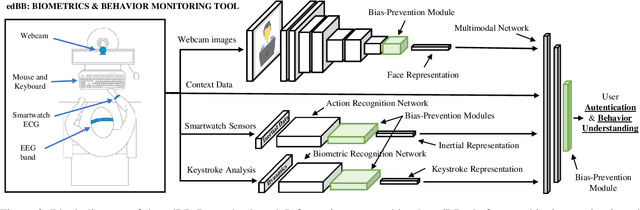
We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
Monotone Improvement of Information-Geometric Optimization Algorithms with a Surrogate Function
Apr 06, 2022A surrogate function is often employed to reduce the number of objective function evaluations for optimization. However, the effect of using a surrogate model in evolutionary approaches has not been theoretically investigated. This paper theoretically analyzes the information-geometric optimization framework using a surrogate function. The value of the expected objective function under the candidate sampling distribution is used as the measure of progress of the algorithm. We assume that the surrogate function is maintained so that the population version of the Kendall's rank correlation coefficient between the surrogate function and the objective function under the candidate sampling distribution is greater than or equal to a predefined threshold. We prove that information-geometric optimization using such a surrogate function leads to a monotonic decrease in the expected objective function value if the threshold is sufficiently close to one. The acceptable threshold value is analyzed for the case of the information-geometric optimization instantiated with Gaussian distributions, i.e., the rank-$\mu$ update CMA-ES, on a convex quadratic objective function. As an alternative to the Kendall's rank correlation coefficient, we investigate the use of the Pearson correlation coefficient between the weights assigned to candidate solutions based on the objective function and the surrogate function.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022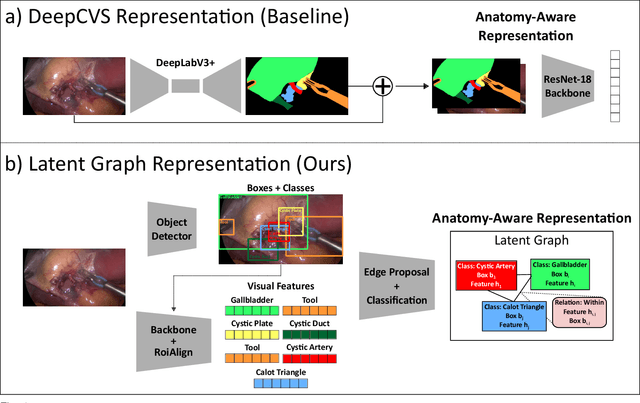
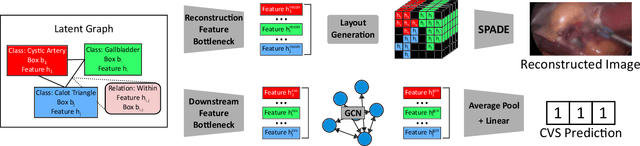
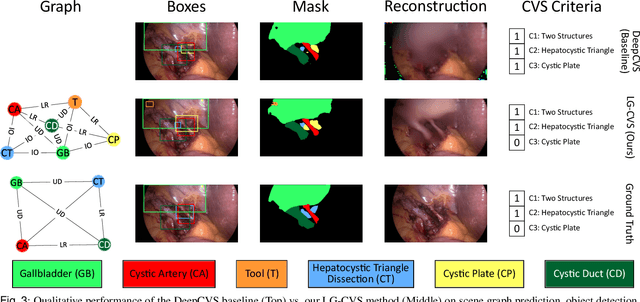
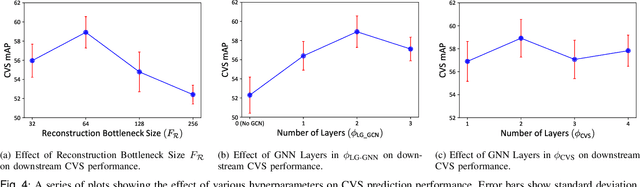
Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
LG-Hand: Advancing 3D Hand Pose Estimation with Locally and Globally Kinematic Knowledge
Nov 06, 2022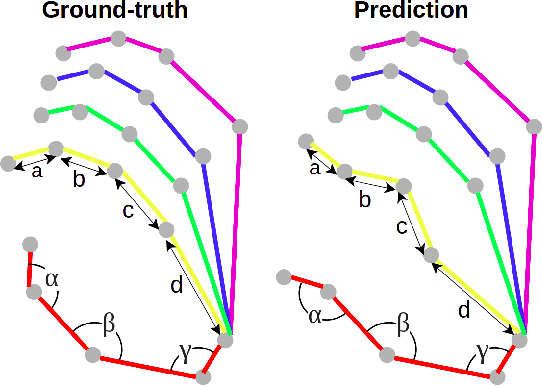
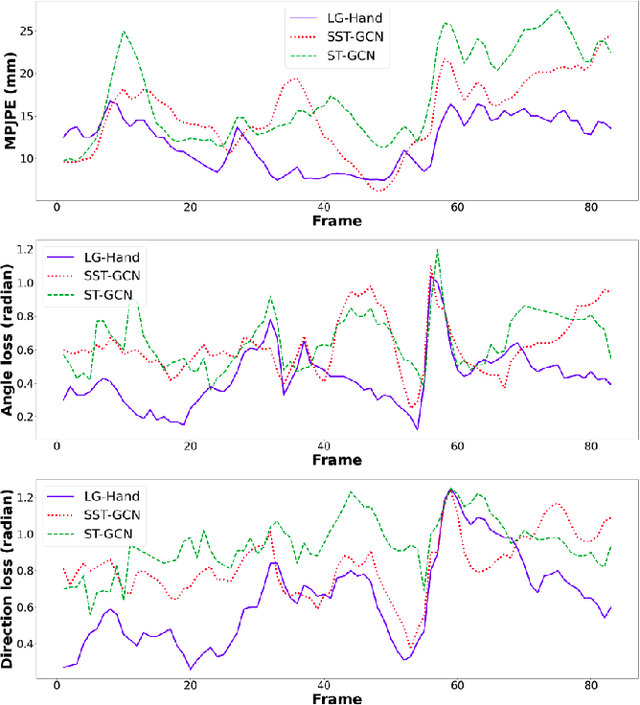
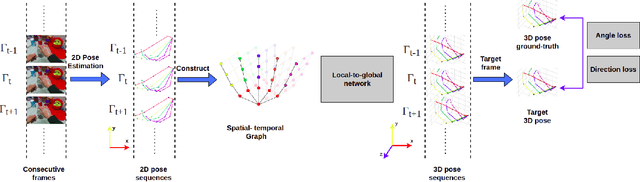
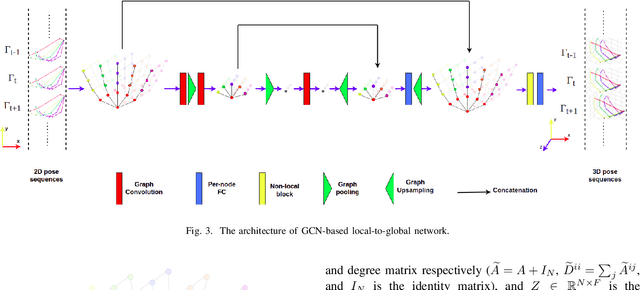
3D hand pose estimation from RGB images suffers from the difficulty of obtaining the depth information. Therefore, a great deal of attention has been spent on estimating 3D hand pose from 2D hand joints. In this paper, we leverage the advantage of spatial-temporal Graph Convolutional Neural Networks and propose LG-Hand, a powerful method for 3D hand pose estimation. Our method incorporates both spatial and temporal dependencies into a single process. We argue that kinematic information plays an important role, contributing to the performance of 3D hand pose estimation. We thereby introduce two new objective functions, Angle and Direction loss, to take the hand structure into account. While Angle loss covers locally kinematic information, Direction loss handles globally kinematic one. Our LG-Hand achieves promising results on the First-Person Hand Action Benchmark (FPHAB) dataset. We also perform an ablation study to show the efficacy of the two proposed objective functions.
Distilling Robust and Non-Robust Features in Adversarial Examples by Information Bottleneck
Apr 06, 2022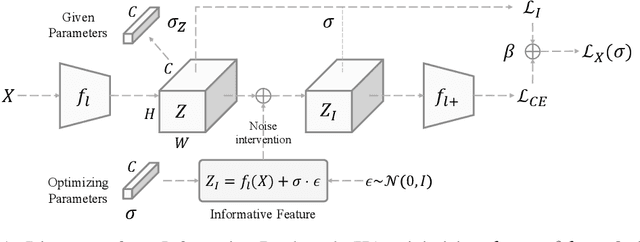
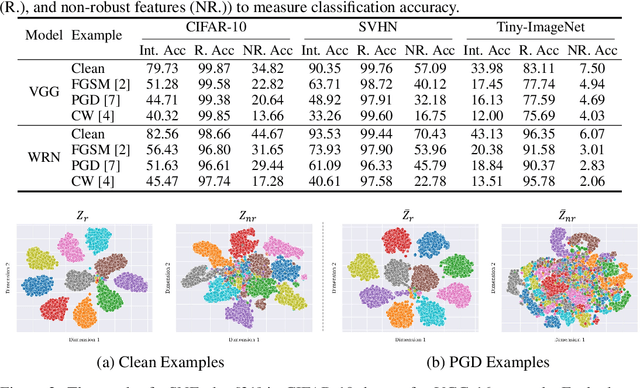


Adversarial examples, generated by carefully crafted perturbation, have attracted considerable attention in research fields. Recent works have argued that the existence of the robust and non-robust features is a primary cause of the adversarial examples, and investigated their internal interactions in the feature space. In this paper, we propose a way of explicitly distilling feature representation into the robust and non-robust features, using Information Bottleneck. Specifically, we inject noise variation to each feature unit and evaluate the information flow in the feature representation to dichotomize feature units either robust or non-robust, based on the noise variation magnitude. Through comprehensive experiments, we demonstrate that the distilled features are highly correlated with adversarial prediction, and they have human-perceptible semantic information by themselves. Furthermore, we present an attack mechanism intensifying the gradient of non-robust features that is directly related to the model prediction, and validate its effectiveness of breaking model robustness.
Real Estate Attribute Prediction from Multiple Visual Modalities with Missing Data
Nov 16, 2022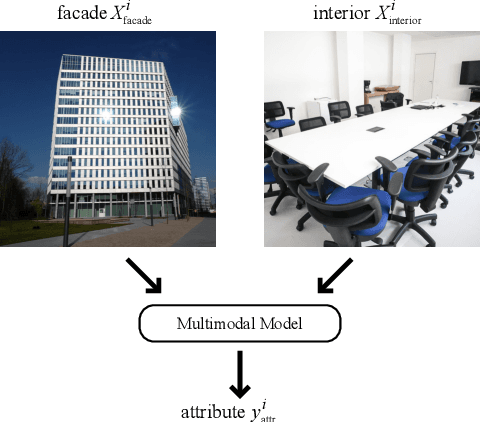
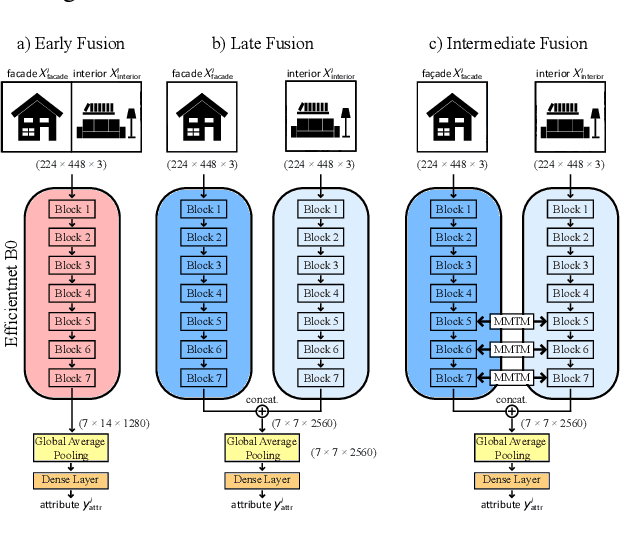
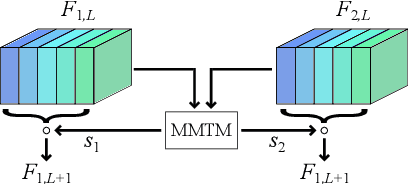

The assessment and valuation of real estate requires large datasets with real estate information. Unfortunately, real estate databases are usually sparse in practice, i.e., not for each property every important attribute is available. In this paper, we study the potential of predicting high-level real estate attributes from visual data, specifically from two visual modalities, namely indoor (interior) and outdoor (facade) photos. We design three models using different multimodal fusion strategies and evaluate them for three different use cases. Thereby, a particular challenge is to handle missing modalities. We evaluate different fusion strategies, present baselines for the different prediction tasks, and find that enriching the training data with additional incomplete samples can lead to an improvement in prediction accuracy. Furthermore, the fusion of information from indoor and outdoor photos results in a performance boost of up to 5% in Macro F1-score.
* included in the Proceedings of the OAGM Workshop 2021