 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Watching the News: Towards VideoQA Models that can Read
Nov 10, 2022
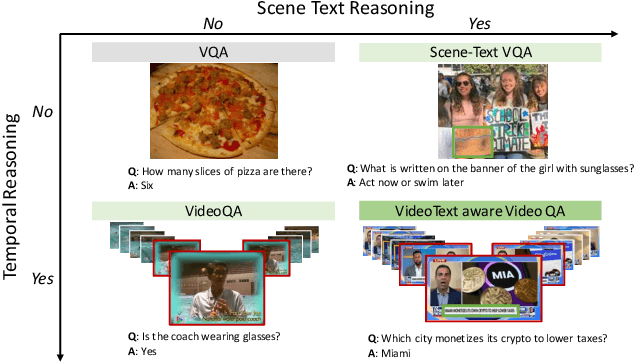
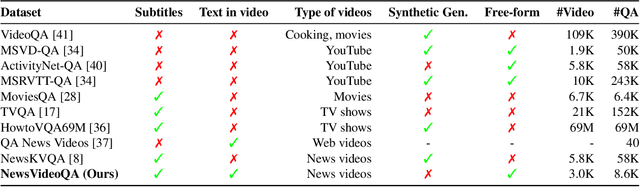

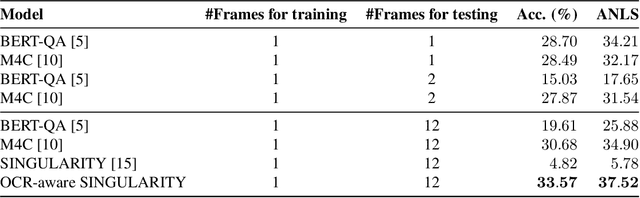
Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisation cues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the ``NewsVideoQA'' dataset that comprises more than $8,600$ QA pairs on $3,000+$ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022
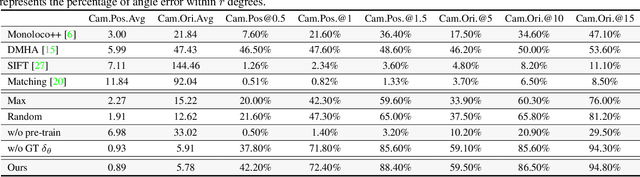
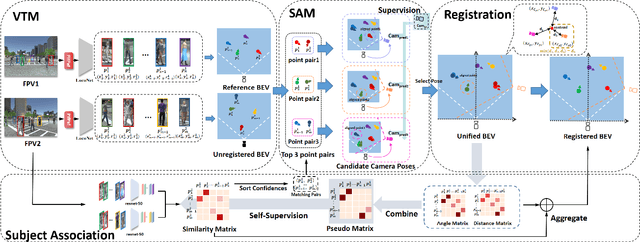
We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
Observability-aware online multi-lidar extrinsic calibration
Dec 19, 2022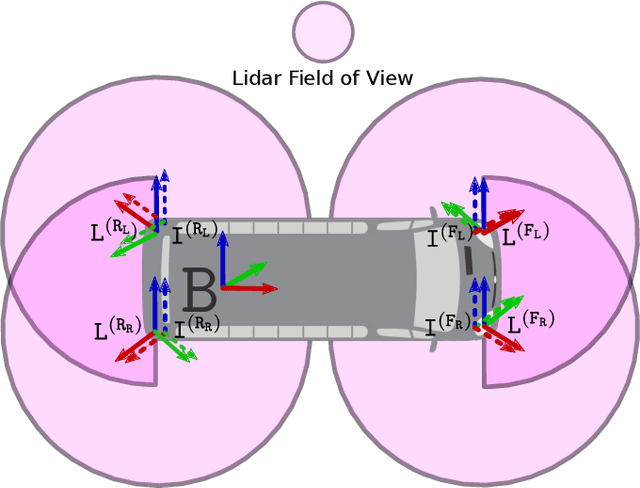

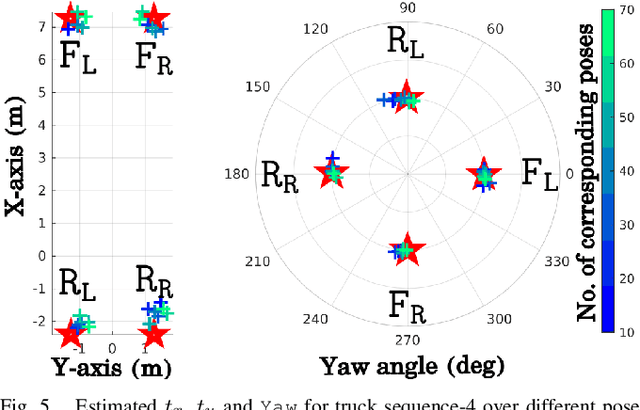

Accurate and robust extrinsic calibration is necessary for deploying autonomous systems which need multiple sensors for perception. In this paper, we present a robust system for real-time extrinsic calibration of multiple lidars in vehicle base frame without the need for any fiducial markers or features. We base our approach on matching absolute GNSS and estimated lidar poses in real-time. Comparing rotation components allows us to improve the robustness of the solution than traditional least-square approach comparing translation components only. Additionally, instead of comparing all corresponding poses, we select poses comprising maximum mutual information based on our novel observability criteria. This allows us to identify a subset of the poses helpful for real-time calibration. We also provide stopping criteria for ensuring calibration completion. To validate our approach extensive tests were carried out on data collected using Scania test vehicles (7 sequences for a total of ~ 6.5 Km). The results presented in this paper show that our approach is able to accurately determine the extrinsic calibration for various combinations of sensor setups.
ARO-Net: Learning Neural Fields from Anchored Radial Observations
Dec 19, 2022
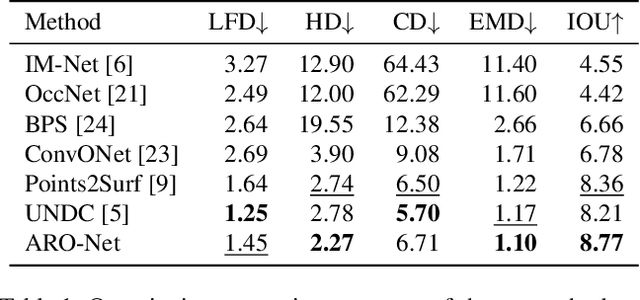
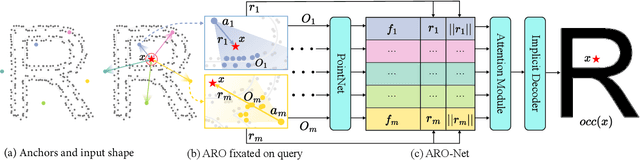
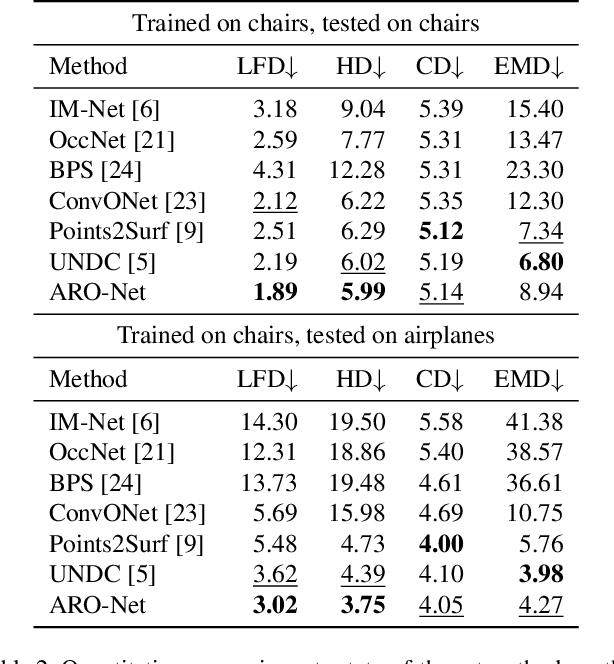
We introduce anchored radial observations (ARO), a novel shape encoding for learning neural field representation of shapes that is category-agnostic and generalizable amid significant shape variations. The main idea behind our work is to reason about shapes through partial observations from a set of viewpoints, called anchors. We develop a general and unified shape representation by employing a fixed set of anchors, via Fibonacci sampling, and designing a coordinate-based deep neural network to predict the occupancy value of a query point in space. Differently from prior neural implicit models, that use global shape feature, our shape encoder operates on contextual, query-specific features. To predict point occupancy, locally observed shape information from the perspective of the anchors surrounding the input query point are encoded and aggregated through an attention module, before implicit decoding is performed. We demonstrate the quality and generality of our network, coined ARO-Net, on surface reconstruction from sparse point clouds, with tests on novel and unseen object categories, "one-shape" training, and comparisons to state-of-the-art neural and classical methods for reconstruction and tessellation.
Predicting Ejection Fraction from Chest X-rays Using Computer Vision for Diagnosing Heart Failure
Dec 19, 2022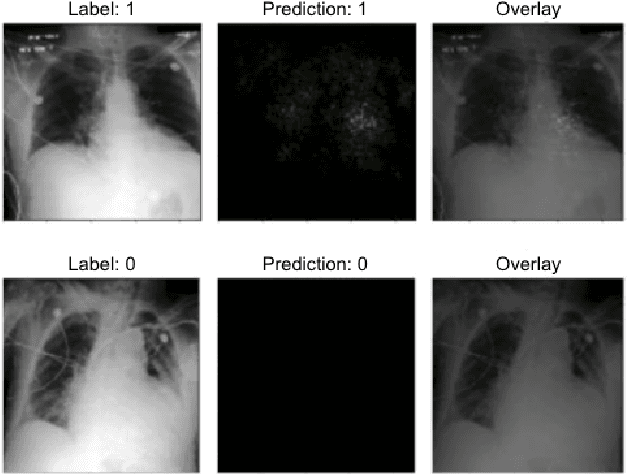
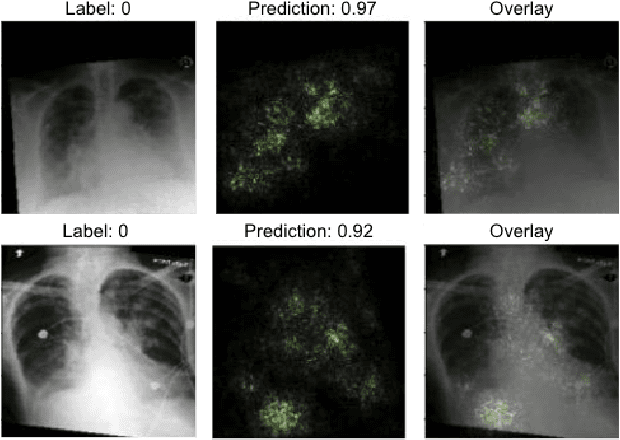
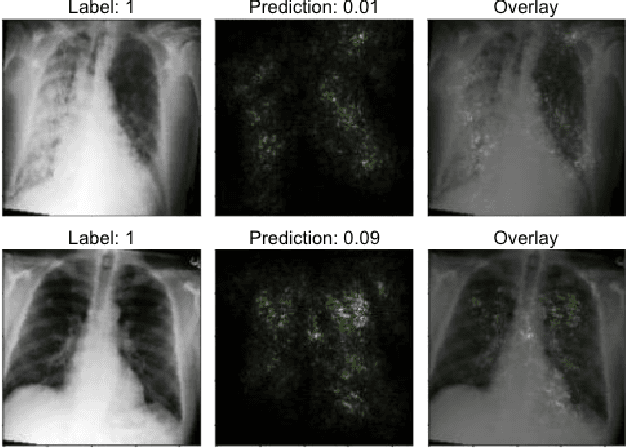
Heart failure remains a major public health challenge with growing costs. Ejection fraction (EF) is a key metric for the diagnosis and management of heart failure however estimation of EF using echocardiography remains expensive for the healthcare system and subject to intra/inter operator variability. While chest x-rays (CXR) are quick, inexpensive, and require less expertise, they do not provide sufficient information to the human eye to estimate EF. This work explores the efficacy of computer vision techniques to predict reduced EF solely from CXRs. We studied a dataset of 3488 CXRs from the MIMIC CXR-jpg (MCR) dataset. Our work establishes benchmarks using multiple state-of-the-art convolutional neural network architectures. The subsequent analysis shows increasing model sizes from 8M to 23M parameters improved classification performance without overfitting the dataset. We further show how data augmentation techniques such as CXR rotation and random cropping further improves model performance another ~5%. Finally, we conduct an error analysis using saliency maps and Grad-CAMs to better understand the failure modes of convolutional models on this task.
Leveraging Road Area Semantic Segmentation with Auxiliary Steering Task
Dec 19, 2022Robustness of different pattern recognition methods is one of the key challenges in autonomous driving, especially when driving in the high variety of road environments and weather conditions, such as gravel roads and snowfall. Although one can collect data from these adverse conditions using cars equipped with sensors, it is quite tedious to annotate the data for training. In this work, we address this limitation and propose a CNN-based method that can leverage the steering wheel angle information to improve the road area semantic segmentation. As the steering wheel angle data can be easily acquired with the associated images, one could improve the accuracy of road area semantic segmentation by collecting data in new road environments without manual data annotation. We demonstrate the effectiveness of the proposed approach on two challenging data sets for autonomous driving and show that when the steering task is used in our segmentation model training, it leads to a 0.1-2.9% gain in the road area mIoU (mean Intersection over Union) compared to the corresponding reference transfer learning model.
* 11 pages, 4 figures (Supplementary material 6 pages, 3 figures). Author's accepted version of the contribution included in proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP), 2022
Absolute Wrong Makes Better: Boosting Weakly Supervised Object Detection via Negative Deterministic Information
Apr 21, 2022
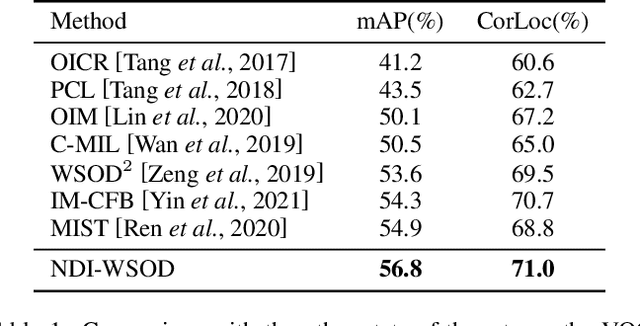
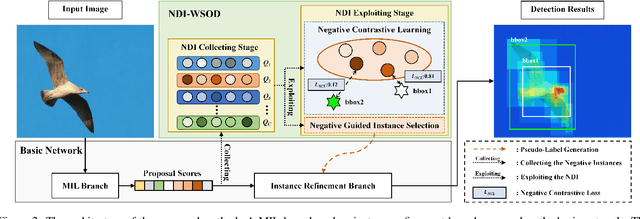
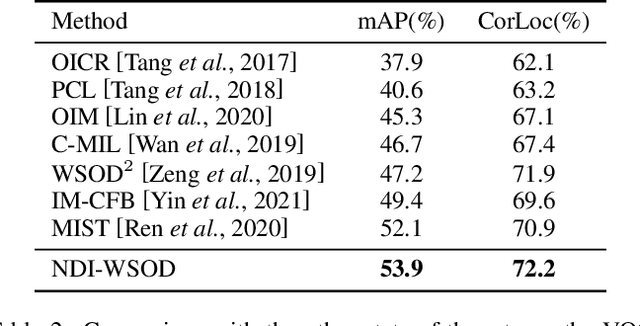
Weakly supervised object detection (WSOD) is a challenging task, in which image-level labels (e.g., categories of the instances in the whole image) are used to train an object detector. Many existing methods follow the standard multiple instance learning (MIL) paradigm and have achieved promising performance. However, the lack of deterministic information leads to part domination and missing instances. To address these issues, this paper focuses on identifying and fully exploiting the deterministic information in WSOD. We discover that negative instances (i.e. absolutely wrong instances), ignored in most of the previous studies, normally contain valuable deterministic information. Based on this observation, we here propose a negative deterministic information (NDI) based method for improving WSOD, namely NDI-WSOD. Specifically, our method consists of two stages: NDI collecting and exploiting. In the collecting stage, we design several processes to identify and distill the NDI from negative instances online. In the exploiting stage, we utilize the extracted NDI to construct a novel negative contrastive learning mechanism and a negative guided instance selection strategy for dealing with the issues of part domination and missing instances, respectively. Experimental results on several public benchmarks including VOC 2007, VOC 2012 and MS COCO show that our method achieves satisfactory performance.
Realtime Fewshot Portrait Stylization Based On Geometric Alignment
Nov 28, 2022
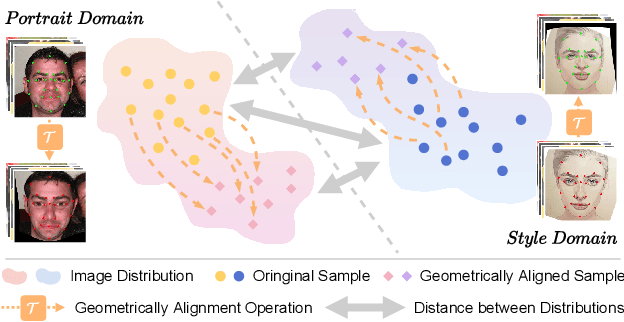
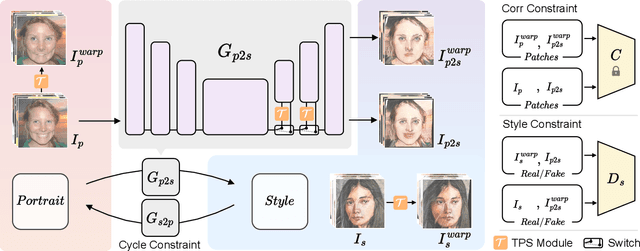
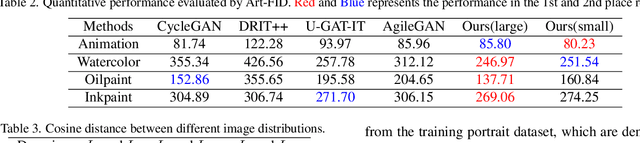
This paper presents a portrait stylization method designed for real-time mobile applications with limited style examples available. Previous learning based stylization methods suffer from the geometric and semantic gaps between portrait domain and style domain, which obstacles the style information to be correctly transferred to the portrait images, leading to poor stylization quality. Based on the geometric prior of human facial attributions, we propose to utilize geometric alignment to tackle this issue. Firstly, we apply Thin-Plate-Spline (TPS) on feature maps in the generator network and also directly to style images in pixel space, generating aligned portrait-style image pairs with identical landmarks, which closes the geometric gaps between two domains. Secondly, adversarial learning maps the textures and colors of portrait images to the style domain. Finally, geometric aware cycle consistency preserves the content and identity information unchanged, and deformation invariant constraint suppresses artifacts and distortions. Qualitative and quantitative comparison validate our method outperforms existing methods, and experiments proof our method could be trained with limited style examples (100 or less) in real-time (more than 40 FPS) on mobile devices. Ablation study demonstrates the effectiveness of each component in the framework.
Sampling with Attribute-Related Information for Controlling Language Models
May 12, 2022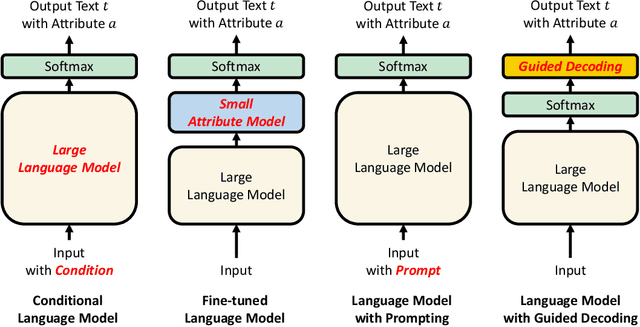
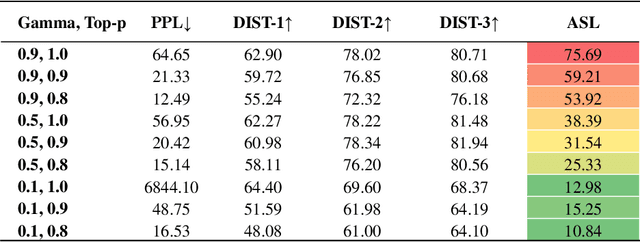
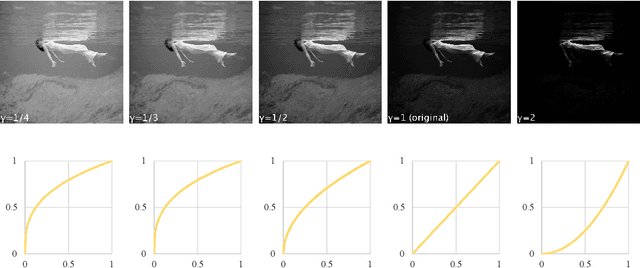

The dominant approaches for controlling language models are based on fine-tuning large language models or prompt engineering. However, these methods often require condition-specific data or considerable hand-crafting. We propose a new simple guided decoding method, Gamma Sampling, which does not require complex engineering and any extra data. Gamma Sampling introduces attribute-related information (provided by humans or language models themselves) into the sampling process to guide language models to generate texts with desired attributes. Experiments on controlling topics and sentiments of generated text show Gamma Sampling to be superior in diversity, attribute relevance and overall quality of generated samples while maintaining a fast generation speed. In addition, we successfully applied Gamma Sampling to control other attributes of language such as relatedness and repetition, which further demonstrates the versatility and effectiveness of this method. Gamma Sampling is now available in the python package samplings via import gamma sampling from samplings.
Fairness in Contextual Resource Allocation Systems: Metrics and Incompatibility Results
Dec 04, 2022We study critical systems that allocate scarce resources to satisfy basic needs, such as homeless services that provide housing. These systems often support communities disproportionately affected by systemic racial, gender, or other injustices, so it is crucial to design these systems with fairness considerations in mind. To address this problem, we propose a framework for evaluating fairness in contextual resource allocation systems that is inspired by fairness metrics in machine learning. This framework can be applied to evaluate the fairness properties of a historical policy, as well as to impose constraints in the design of new (counterfactual) allocation policies. Our work culminates with a set of incompatibility results that investigate the interplay between the different fairness metrics we propose. Notably, we demonstrate that: 1) fairness in allocation and fairness in outcomes are usually incompatible; 2) policies that prioritize based on a vulnerability score will usually result in unequal outcomes across groups, even if the score is perfectly calibrated; 3) policies using contextual information beyond what is needed to characterize baseline risk and treatment effects can be fairer in their outcomes than those using just baseline risk and treatment effects; and 4) policies using group status in addition to baseline risk and treatment effects are as fair as possible given all available information. Our framework can help guide the discussion among stakeholders in deciding which fairness metrics to impose when allocating scarce resources.