 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxTuning: Directly Injecting the Object Box for Multimodal Model Fine-Tuning
Apr 13, 2026Object-level spatial-temporal understanding is essential for video question answering, yet existing multimodal large language models (MLLMs) encode frames holistically and lack explicit mechanisms for fine-grained object grounding. Recent work addresses this by serializing bounding box coordinates as text tokens, but this text-coordinate paradigm suffers from a fundamental modality mismatch: object information is inherently visual, yet encoding it as text incurs a high token cost that forces aggressive temporal downsampling. We propose BoxTuning, which resolves this mismatch by injecting object spatial-temporal information directly into the visual modality. Colored bounding boxes and trajectory trails are rendered onto video frames as visual prompts, with only a concise color-to-object legend retained as text. This reduces the token cost significantly, achieving 87-93% text token reduction in practice. It also preserves full temporal resolution, where the trajectory trails further encode inter-frame motion direction and speed within each keyframe, recovering fine-grained dynamics that text-coordinate methods are forced to discard. Experimental results on five video QA benchmarks (CLEVRER, Perception Test, STAR, NExT-QA, IntentQA) show that BoxTuning surpasses text-coordinate baselines on spatially oriented tasks and nearly eliminates the accuracy degradation observed on reasoning-centric tasks, establishing visual prompting as a more natural and efficient paradigm for conveying object information to video MLLMs.
COVTrack++: Learning Open-Vocabulary Multi-Object Tracking from Continuous Videos via a Synergistic Paradigm
Mar 25, 2026Multi-Object Tracking (MOT) has traditionally focused on a few specific categories, restricting its applicability to real-world scenarios involving diverse objects. Open-Vocabulary Multi-Object Tracking (OVMOT) addresses this by enabling tracking of arbitrary categories, including novel objects unseen during training. However, current progress is constrained by two challenges: the lack of continuously annotated video data for training, and the lack of a customized OVMOT framework to synergistically handle detection and association. We address the data bottleneck by constructing C-TAO, the first continuously annotated training set for OVMOT, which increases annotation density by 26x over the original TAO and captures smooth motion dynamics and intermediate object states. For the framework bottleneck, we propose COVTrack++, a synergistic framework that achieves a bidirectional reciprocal mechanism between detection and association through three modules: (1) Multi-Cue Adaptive Fusion (MCF) dynamically balances appearance, motion, and semantic cues for association feature learning; (2) Multi-Granularity Hierarchical Aggregation (MGA) exploits hierarchical spatial relationships in dense detections, where visible child nodes (e.g., object parts) assist occluded parent objects (e.g., whole body) for association feature enhancement; (3) Temporal Confidence Propagation (TCP) recovers flickering detections through high-confidence tracked objects boosting low-confidence candidates across frames, stabilizing trajectories. Extensive experiments on TAO demonstrate state-of-the-art performance, with novel TETA reaching 35.4% and 30.5% on validation and test sets, improving novel AssocA by 4.8% and novel LocA by 5.8% over previous methods, and show strong zero-shot generalization on BDD100K. The code and dataset will be publicly available.
VOVTrack: Exploring the Potentiality in Videos for Open-Vocabulary Object Tracking
Oct 11, 2024



Open-vocabulary multi-object tracking (OVMOT) represents a critical new challenge involving the detection and tracking of diverse object categories in videos, encompassing both seen categories (base classes) and unseen categories (novel classes). This issue amalgamates the complexities of open-vocabulary object detection (OVD) and multi-object tracking (MOT). Existing approaches to OVMOT often merge OVD and MOT methodologies as separate modules, predominantly focusing on the problem through an image-centric lens. In this paper, we propose VOVTrack, a novel method that integrates object states relevant to MOT and video-centric training to address this challenge from a video object tracking standpoint. First, we consider the tracking-related state of the objects during tracking and propose a new prompt-guided attention mechanism for more accurate localization and classification (detection) of the time-varying objects. Subsequently, we leverage raw video data without annotations for training by formulating a self-supervised object similarity learning technique to facilitate temporal object association (tracking). Experimental results underscore that VOVTrack outperforms existing methods, establishing itself as a state-of-the-art solution for open-vocabulary tracking task.
OCTrack: Benchmarking the Open-Corpus Multi-Object Tracking
Jul 19, 2024



We study a novel yet practical problem of open-corpus multi-object tracking (OCMOT), which extends the MOT into localizing, associating, and recognizing generic-category objects of both seen (base) and unseen (novel) classes, but without the category text list as prompt. To study this problem, the top priority is to build a benchmark. In this work, we build OCTrackB, a large-scale and comprehensive benchmark, to provide a standard evaluation platform for the OCMOT problem. Compared to previous datasets, OCTrackB has more abundant and balanced base/novel classes and the corresponding samples for evaluation with less bias. We also propose a new multi-granularity recognition metric to better evaluate the generative object recognition in OCMOT. By conducting the extensive benchmark evaluation, we report and analyze the results of various state-of-the-art methods, which demonstrate the rationale of OCMOT, as well as the usefulness and advantages of OCTrackB.
Unveiling the Power of Self-supervision for Multi-view Multi-human Association and Tracking
Jan 31, 2024Multi-view multi-human association and tracking (MvMHAT), is a new but important problem for multi-person scene video surveillance, aiming to track a group of people over time in each view, as well as to identify the same person across different views at the same time, which is different from previous MOT and multi-camera MOT tasks only considering the over-time human tracking. This way, the videos for MvMHAT require more complex annotations while containing more information for self learning. In this work, we tackle this problem with a self-supervised learning aware end-to-end network. Specifically, we propose to take advantage of the spatial-temporal self-consistency rationale by considering three properties of reflexivity, symmetry and transitivity. Besides the reflexivity property that naturally holds, we design the self-supervised learning losses based on the properties of symmetry and transitivity, for both appearance feature learning and assignment matrix optimization, to associate the multiple humans over time and across views. Furthermore, to promote the research on MvMHAT, we build two new large-scale benchmarks for the network training and testing of different algorithms. Extensive experiments on the proposed benchmarks verify the effectiveness of our method. We have released the benchmark and code to the public.
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022



We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
Self-supervised Social Relation Representation for Human Group Detection
Mar 08, 2022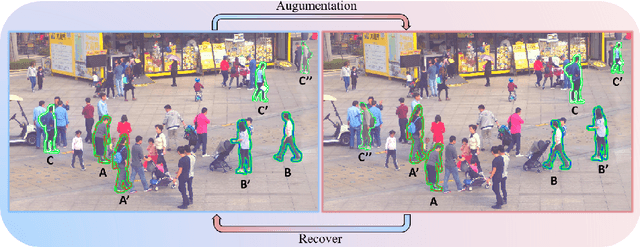
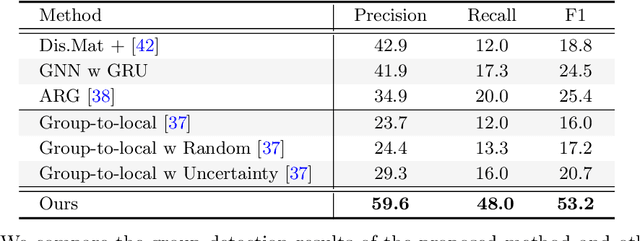
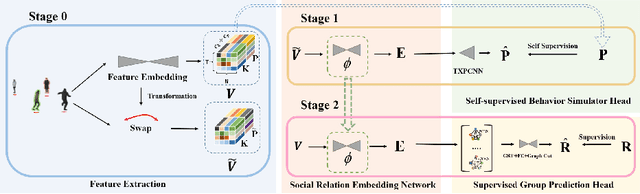
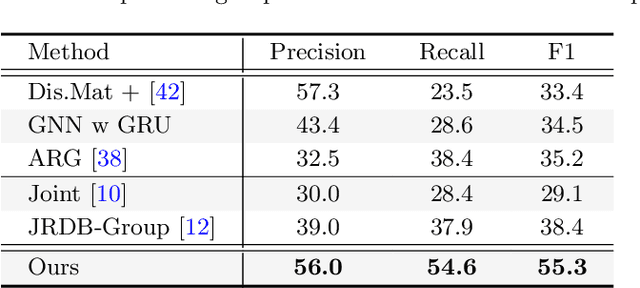
Human group detection, which splits crowd of people into groups, is an important step for video-based human social activity analysis. The core of human group detection is the human social relation representation and division.In this paper, we propose a new two-stage multi-head framework for human group detection. In the first stage, we propose a human behavior simulator head to learn the social relation feature embedding, which is self-supervisely trained by leveraging the socially grounded multi-person behavior relationship. In the second stage, based on the social relation embedding, we develop a self-attention inspired network for human group detection. Remarkable performance on two state-of-the-art large-scale benchmarks, i.e., PANDA and JRDB-Group, verifies the effectiveness of the proposed framework. Benefiting from the self-supervised social relation embedding, our method can provide promising results with very few (labeled) training data. We will release the source code to the public.