 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Probabilistic Modelling of Signal Mixtures with Differentiable Dictionaries
Nov 28, 2022
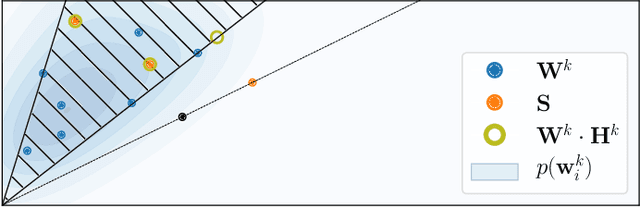
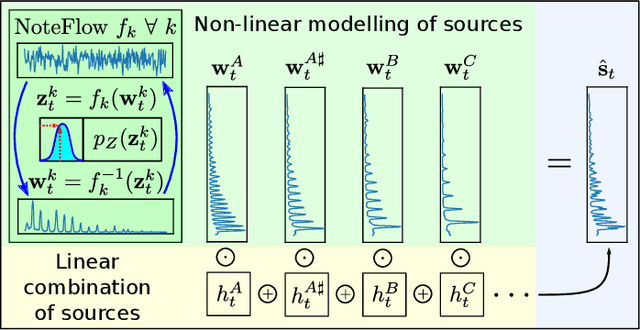
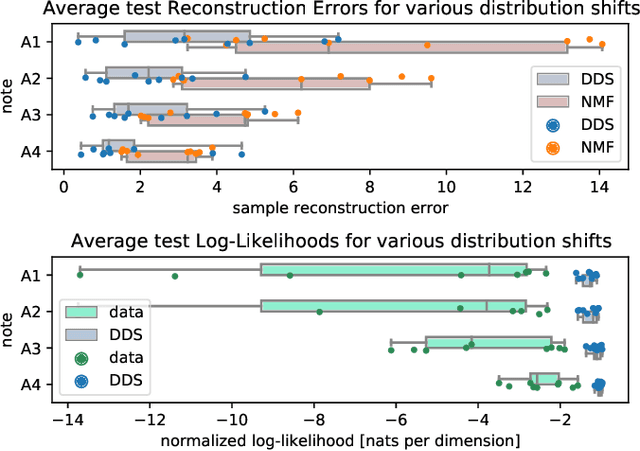
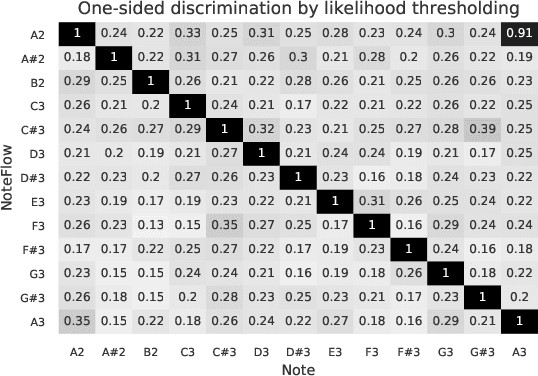
We introduce a novel way to incorporate prior information into (semi-) supervised non-negative matrix factorization, which we call differentiable dictionary search. It enables general, highly flexible and principled modelling of mixtures where non-linear sources are linearly mixed. We study its behavior on an audio decomposition task, and conduct an extensive, highly controlled study of its modelling capabilities.
Predicting dominant hand from spatiotemporal context varying physiological data
Dec 08, 2022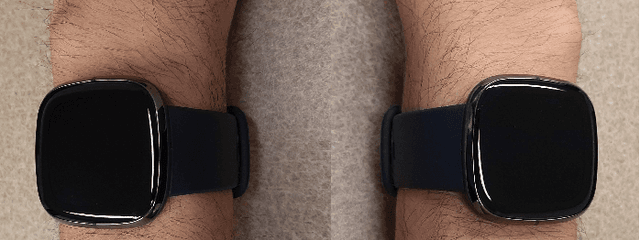
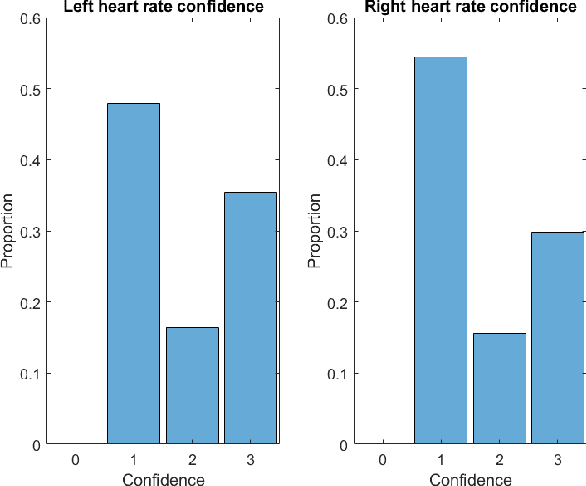
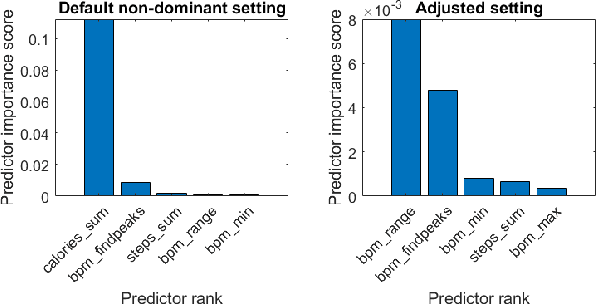
Health metrics from wrist-worn devices demand an automatic dominant hand prediction to keep an accurate operation. The prediction would improve reliability, enhance the consumer experience, and encourage further development of healthcare applications. This paper aims to evaluate the use of physiological and spatiotemporal context information from a two-hand experiment to predict the wrist placement of a commercial smartwatch. The main contribution is a methodology to obtain an effective model and features from low sample rate physiological sensors and a self-reported context survey. Results show an effective dominant hand prediction using data from a single subject under real-life conditions.
Deep Cost-sensitive Learning for Wheat Frost Detection
Dec 25, 2022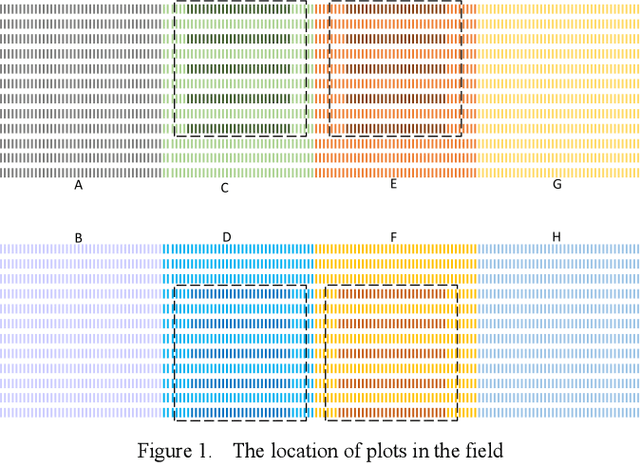
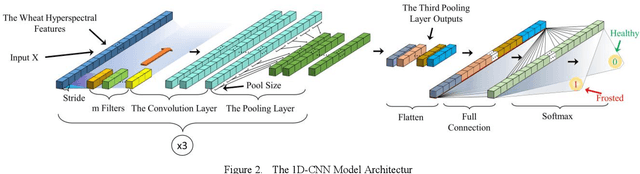
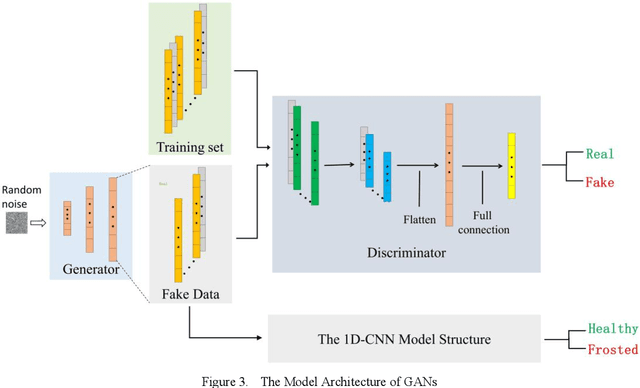
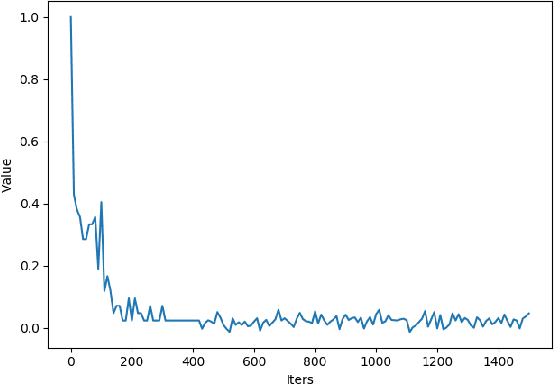
Frost damage is one of the main factors leading to wheat yield reduction. Therefore, the detection of wheat frost accurately and efficiently is beneficial for growers to take corresponding measures in time to reduce economic loss. To detect the wheat frost, in this paper we create a hyperspectral wheat frost data set by collecting the data characterized by temperature, wheat yield, and hyperspectral information provided by the handheld hyperspectral spectrometer. However, due to the imbalance of data, that is, the number of healthy samples is much higher than the number of frost damage samples, a deep learning algorithm tends to predict biasedly towards the healthy samples resulting in model overfitting of the healthy samples. Therefore, we propose a method based on deep cost-sensitive learning, which uses a one-dimensional convolutional neural network as the basic framework and incorporates cost-sensitive learning with fixed factors and adjustment factors into the loss function to train the network. Meanwhile, the accuracy and score are used as evaluation metrics. Experimental results show that the detection accuracy and the score reached 0.943 and 0.623 respectively, this demonstration shows that this method not only ensures the overall accuracy but also effectively improves the detection rate of frost samples.
Modeling Global Distribution for Federated Learning with Label Distribution Skew
Dec 17, 2022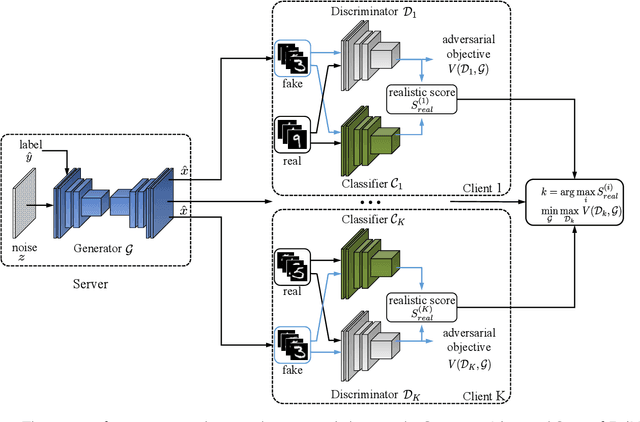
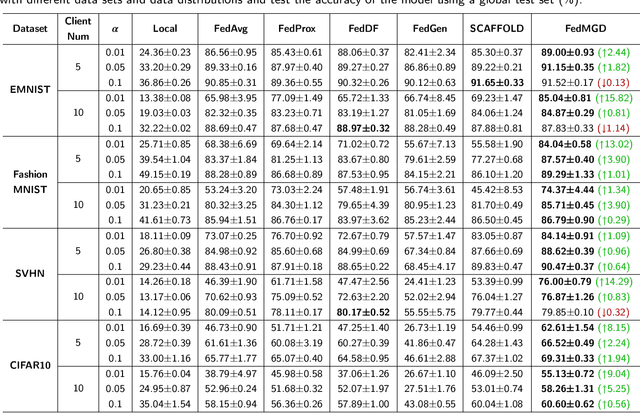
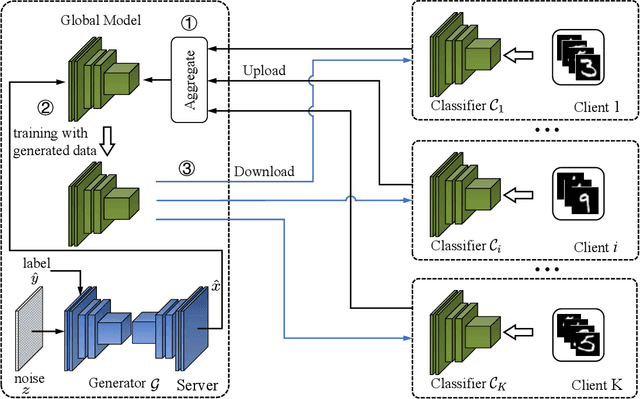
Federated learning achieves joint training of deep models by connecting decentralized data sources, which can significantly mitigate the risk of privacy leakage. However, in a more general case, the distributions of labels among clients are different, called ``label distribution skew''. Directly applying conventional federated learning without consideration of label distribution skew issue significantly hurts the performance of the global model. To this end, we propose a novel federated learning method, named FedMGD, to alleviate the performance degradation caused by the label distribution skew issue. It introduces a global Generative Adversarial Network to model the global data distribution without access to local datasets, so the global model can be trained using the global information of data distribution without privacy leakage. The experimental results demonstrate that our proposed method significantly outperforms the state-of-the-art on several public benchmarks. Code is available at \url{https://github.com/Sheng-T/FedMGD}.
LIDAR GAIT: Benchmarking 3D Gait Recognition with Point Clouds
Nov 19, 2022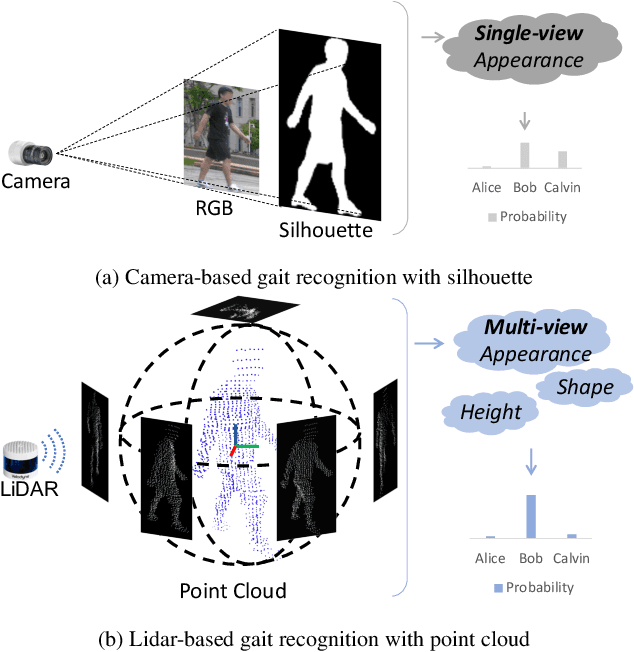
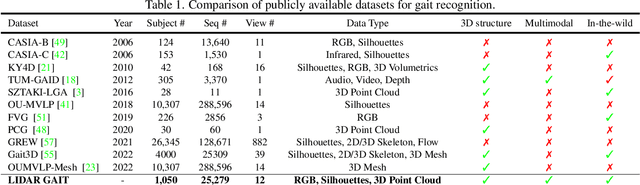
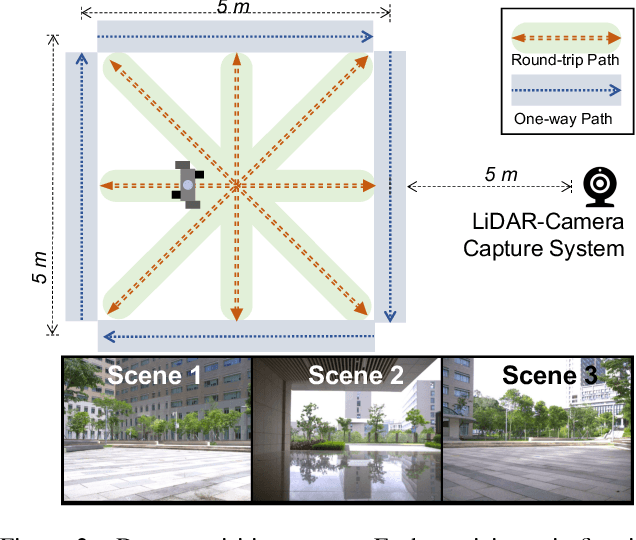
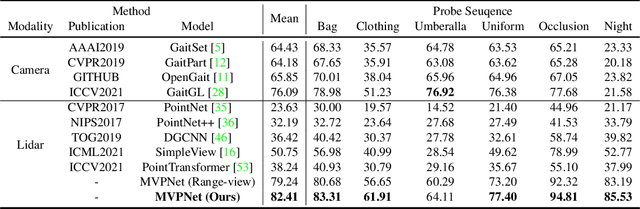
Video-based gait recognition has achieved impressive results in constrained scenarios. However, visual cameras neglect human 3D structure information, which limits the feasibility of gait recognition in the 3D wild world. In this work, instead of extracting gait features from images, we explore precise 3D gait features from point clouds and propose a simple yet efficient 3D gait recognition framework, termed multi-view projection network (MVPNet). MVPNet first projects point clouds into multiple depth maps from different perspectives, and then fuse depth images together, to learn the compact representation with 3D geometry information. Due to the lack of point cloud datasets, we build the first large-scale Lidar-based gait recognition dataset, LIDAR GAIT, collected by a Lidar sensor and an RGB camera mounted on a robot. The dataset contains 25,279 sequences from 1,050 subjects and covers many different variations, including visibility, views, occlusions, clothing, carrying, and scenes. Extensive experiments show that, (1) 3D structure information serves as a significant feature for gait recognition. (2) MVPNet not only competes with five representative point-based methods, but it also outperforms existing camera-based methods by large margins. (3) The Lidar sensor is superior to the RGB camera for gait recognition in the wild. LIDAR GAIT dataset and MVPNet code will be publicly available.
MHCCL: Masked Hierarchical Cluster-wise Contrastive Learning for Multivariate Time Series
Dec 02, 2022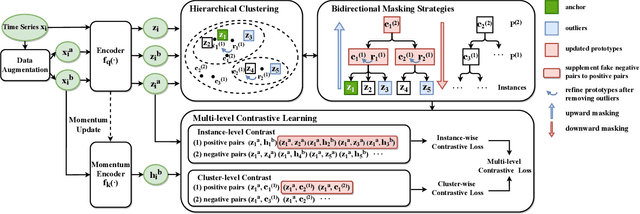
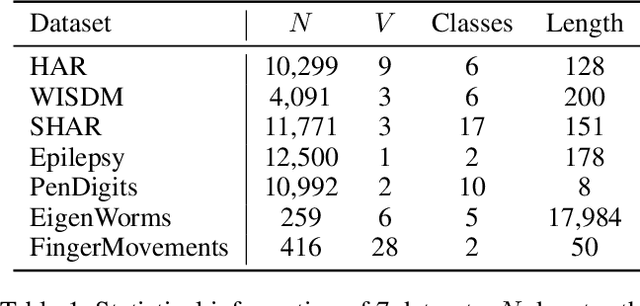
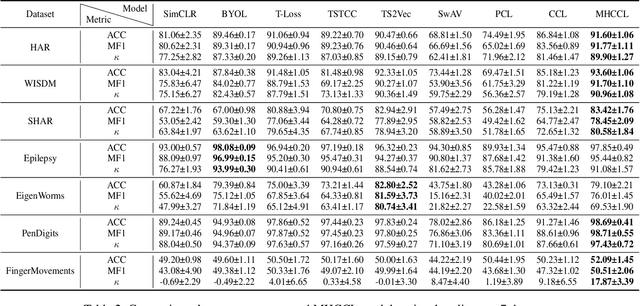
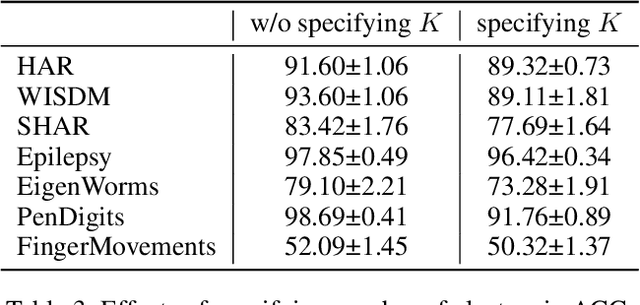
Learning semantic-rich representations from raw unlabeled time series data is critical for downstream tasks such as classification and forecasting. Contrastive learning has recently shown its promising representation learning capability in the absence of expert annotations. However, existing contrastive approaches generally treat each instance independently, which leads to false negative pairs that share the same semantics. To tackle this problem, we propose MHCCL, a Masked Hierarchical Cluster-wise Contrastive Learning model, which exploits semantic information obtained from the hierarchical structure consisting of multiple latent partitions for multivariate time series. Motivated by the observation that fine-grained clustering preserves higher purity while coarse-grained one reflects higher-level semantics, we propose a novel downward masking strategy to filter out fake negatives and supplement positives by incorporating the multi-granularity information from the clustering hierarchy. In addition, a novel upward masking strategy is designed in MHCCL to remove outliers of clusters at each partition to refine prototypes, which helps speed up the hierarchical clustering process and improves the clustering quality. We conduct experimental evaluations on seven widely-used multivariate time series datasets. The results demonstrate the superiority of MHCCL over the state-of-the-art approaches for unsupervised time series representation learning.
Geometry-Aware Network for Domain Adaptive Semantic Segmentation
Dec 02, 2022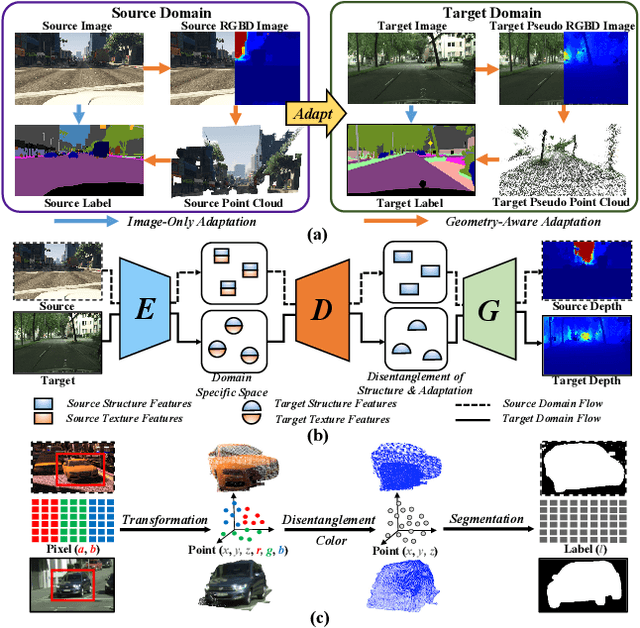

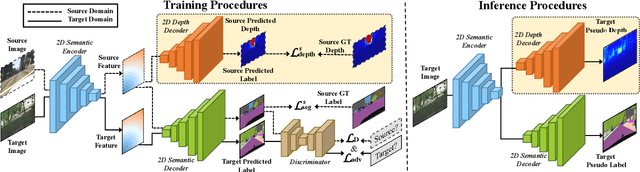

Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.
RGB-D based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 02, 2022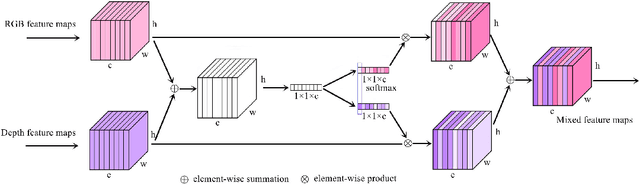
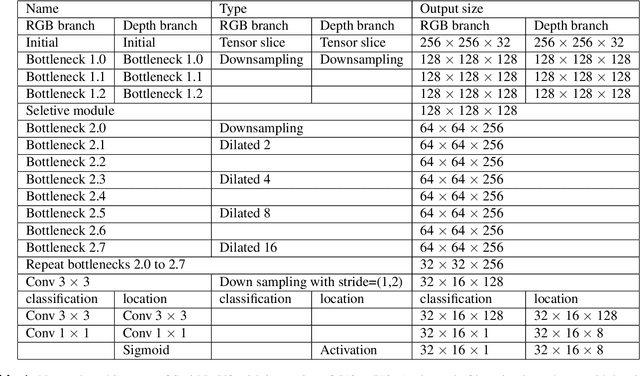
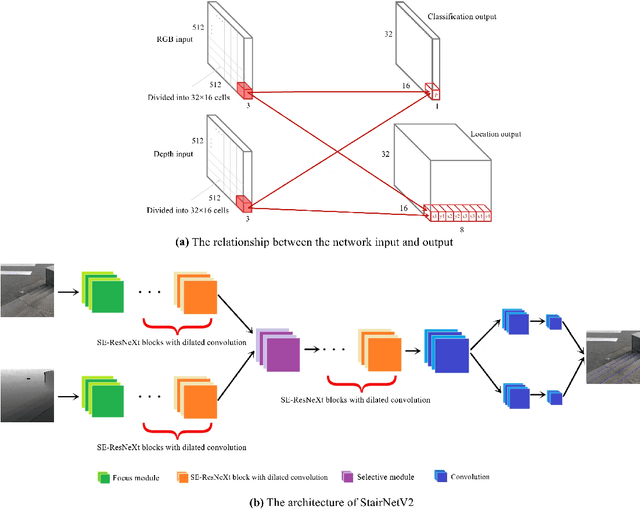
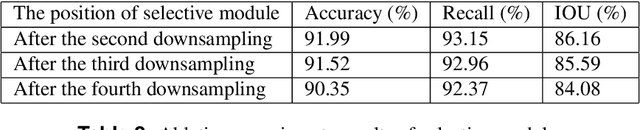
Stairs are common building structures in urban environment, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with inputs of both RGB map and depth map. Specifically, we design the selective module which can make the network learn the complementary relationship between RGB map and depth map and effectively combine the information from RGB map and depth map in different scenes. In addition, we also design a line clustering algorithm for the post-processing of detection results, which can make full use of the detection results to obtain the geometric parameters of stairs. Experiments on our dataset show that our method can achieve better accuracy and recall compared with the previous state-of-the-art deep learning method, which are 5.64% and 7.97%, respectively. Our method also has extremely fast detection speed, and a lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.
Band Relevance Factor (BRF): a novel automatic frequency band selection method based on vibration analysis for rotating machinery
Dec 04, 2022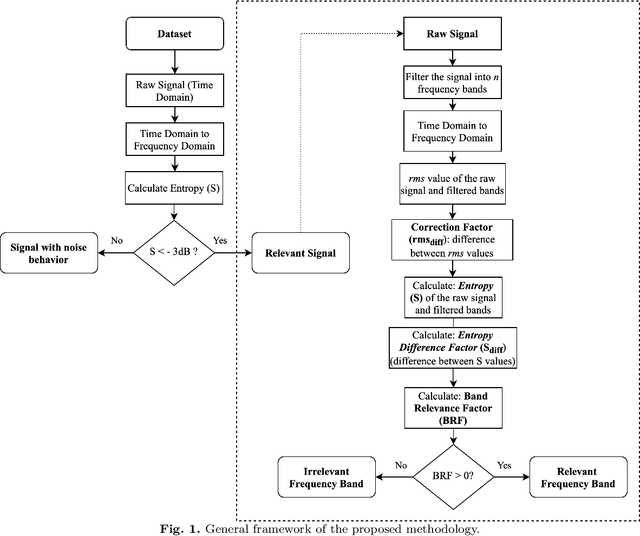
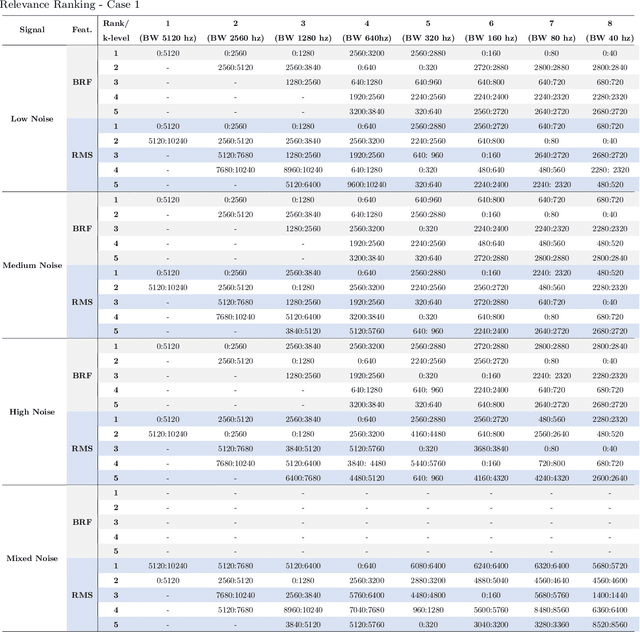

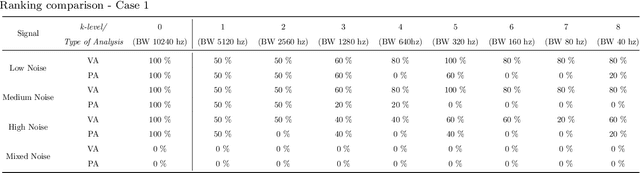
The monitoring of rotating machinery has now become a fundamental activity in the industry, given the high criticality in production processes. Extracting useful information from relevant signals is a key factor for effective monitoring: studies in the areas of Informative Frequency Band selection (IFB) and Feature Extraction/Selection have demonstrated to be effective approaches. However, in general, typical methods in such areas focuses on identifying bands where impulsive excitations are present or on analyzing the relevance of the features after its signal extraction: both approaches lack in terms of procedure automation and efficiency. Typically, the approaches presented in the literature fail to identify frequencies relevant for the vibration analysis of a rotating machinery; moreover, with such approaches features can be extracted from irrelevant bands, leading to additional complexity in the analysis. To overcome such problems, the present study proposes a new approach called Band Relevance Factor (BRF). BRF aims to perform an automatic selection of all relevant frequency bands for a vibration analysis of a rotating machine based on spectral entropy. The results are presented through a relevance ranking and can be visually analyzed through a heatmap. The effectiveness of the approach is validated in a synthetically created dataset and two real dataset, showing that the BRF is able to identify the bands that present relevant information for the analysis of rotating machinery.
Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token
Nov 15, 2022![Figure 1 for Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Faa7fa3b6d22a770d6131580bd142360529a5175b%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Faa7fa3b6d22a770d6131580bd142360529a5175b%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Faa7fa3b6d22a770d6131580bd142360529a5175b%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Faa7fa3b6d22a770d6131580bd142360529a5175b%2F7-Table2-1.png&w=640&q=75)
The pre-training of masked language models (MLMs) consumes massive computation to achieve good results on downstream NLP tasks, resulting in a large carbon footprint. In the vanilla MLM, the virtual tokens, [MASK]s, act as placeholders and gather the contextualized information from unmasked tokens to restore the corrupted information. It raises the question of whether we can append [MASK]s at a later layer, to reduce the sequence length for earlier layers and make the pre-training more efficient. We show: (1) [MASK]s can indeed be appended at a later layer, being disentangled from the word embedding; (2) The gathering of contextualized information from unmasked tokens can be conducted with a few layers. By further increasing the masking rate from 15% to 50%, we can pre-train RoBERTa-base and RoBERTa-large from scratch with only 78% and 68% of the original computational budget without any degradation on the GLUE benchmark. When pre-training with the original budget, our method outperforms RoBERTa for 6 out of 8 GLUE tasks, on average by 0.4%.