 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limits of Model Merging for Multilinguality in Pre-Training
May 25, 2026Endowing models with consistent multilingual performance can be achieved by mixing pre-training data, or post-training approaches such as language-specific model merging. In this work, we test whether merging can be applied to monolingually pre-trained models. We conduct a controlled study on the efficacy of mixed, merged, and monolingual pre-training setups. We find that while monolingual pre-training results in strong in-language performance, merging any combination of monolingual models leads to performance collapse due to interference. Our analysis suggests representational similarity is a prerequisite for model merging. We therefore conclude that the flexibility of merging in fine-tuning does not extend trivially to language-specific pre-training.
When Contextual Inference Fails: Cancelability in Interactive Instruction Following
Mar 20, 2026We investigate the separation of literal interpretation from contextual inference in a collaborative block-building task where a builder must resolve underspecified instructions using contextual inferences. Building on an existing two-speaker psycholinguistic paradigm -- which contrasts a pragmatically cooperative speaker with one who is only literally reliable -- we introduce Build What I Mean (BWIM), an interactive benchmark for contextual meaning construction. In BWIM, models must resolve ambiguity by either performing a contextual inference or requesting clarification at a small communication cost. Evaluating several state-of-the-art LLMs, we find a dissociation between judgment and action: while models detect speaker unreliability in explicit confidence ratings, they fail to exploit this information to guide efficient clarification behavior. Instead, we observe suboptimal strategies, such as partner-blind over-clarification and question-averse guessing under uncertainty.
Self-Hinting Language Models Enhance Reinforcement Learning
Feb 03, 2026Group Relative Policy Optimization (GRPO) has recently emerged as a practical recipe for aligning large language models with verifiable objectives. However, under sparse terminal rewards, GRPO often stalls because rollouts within a group frequently receive identical rewards, causing relative advantages to collapse and updates to vanish. We propose self-hint aligned GRPO with privileged supervision (SAGE), an on-policy reinforcement learning framework that injects privileged hints during training to reshape the rollout distribution under the same terminal verifier reward. For each prompt $x$, the model samples a compact hint $h$ (e.g., a plan or decomposition) and then generates a solution $τ$ conditioned on $(x,h)$. Crucially, the task reward $R(x,τ)$ is unchanged; hints only increase within-group outcome diversity under finite sampling, preventing GRPO advantages from collapsing under sparse rewards. At test time, we set $h=\varnothing$ and deploy the no-hint policy without any privileged information. Moreover, sampling diverse self-hints serves as an adaptive curriculum that tracks the learner's bottlenecks more effectively than fixed hints from an initial policy or a stronger external model. Experiments over 6 benchmarks with 3 LLMs show that SAGE consistently outperforms GRPO, on average +2.0 on Llama-3.2-3B-Instruct, +1.2 on Qwen2.5-7B-Instruct and +1.3 on Qwen3-4B-Instruct. The code is available at https://github.com/BaohaoLiao/SAGE.
Do Language Models Reason Across Languages?
Jan 10, 2026The real-world information sources are inherently multilingual, which naturally raises a question about whether language models can synthesize information across languages. In this paper, we introduce a simple two-hop question answering setting, where answering a question requires making inferences over two multilingual documents. We find that language models are more sensitive to language variation in answer-span documents than in those providing bridging information, despite the equal importance of both documents for answering a question. Under a step-by-step sub-question evaluation, we further show that in up to 33% of multilingual cases, models fail to infer the bridging information in the first step yet still answer the overall question correctly. This indicates that reasoning in language models, especially in multilingual settings, does not follow a faithful step-by-step decomposition. Subsequently, we show that the absence of reasoning decomposition leads to around 18% composition failure, where both sub-questions are answered correctly but fail for the final two-hop questions. To mitigate this, we propose a simple three-stage SUBQ prompting method to guide the multi-step reasoning with sub-questions, which boosts accuracy from 10.1% to 66.5%.
Remedy-R: Generative Reasoning for Machine Translation Evaluation without Error Annotations
Dec 21, 2025Over the years, automatic MT metrics have hillclimbed benchmarks and presented strong and sometimes human-level agreement with human ratings. Yet they remain black-box, offering little insight into their decision-making and often failing under real-world out-of-distribution (OOD) inputs. We introduce Remedy-R, a reasoning-driven generative MT metric trained with reinforcement learning from pairwise translation preferences, without requiring error-span annotations or distillation from closed LLMs. Remedy-R produces step-by-step analyses of accuracy, fluency, and completeness, followed by a final score, enabling more interpretable assessments. With only 60K training pairs across two language pairs, Remedy-R remains competitive with top scalar metrics and GPT-4-based judges on WMT22-24 meta-evaluation, generalizes to other languages, and exhibits strong robustness on OOD stress tests. Moreover, Remedy-R models generate self-reflective feedback that can be reused for translation improvement. Building on this finding, we introduce Remedy-R Agent, a simple evaluate-revise pipeline that leverages Remedy-R's evaluation analysis to refine translations. This agent consistently improves translation quality across diverse models, including Qwen2.5, ALMA-R, GPT-4o-mini, and Gemini-2.0-Flash, suggesting that Remedy-R's reasoning captures translation-relevant information and is practically useful.
Reinforce-Ada: An Adaptive Sampling Framework for Reinforce-Style LLM Training
Oct 06, 2025Reinforcement learning applied to large language models (LLMs) for reasoning tasks is often bottlenecked by unstable gradient estimates due to fixed and uniform sampling of responses across prompts. Prior work such as GVM-RAFT addresses this by dynamically allocating inference budget per prompt to minimize stochastic gradient variance under a budget constraint. Inspired by this insight, we propose Reinforce-Ada, an adaptive sampling framework for online RL post-training of LLMs that continuously reallocates sampling effort to the prompts with the greatest uncertainty or learning potential. Unlike conventional two-stage allocation methods, Reinforce-Ada interleaves estimation and sampling in an online successive elimination process, and automatically stops sampling for a prompt once sufficient signal is collected. To stabilize updates, we form fixed-size groups with enforced reward diversity and compute advantage baselines using global statistics aggregated over the adaptive sampling phase. Empirical results across multiple model architectures and reasoning benchmarks show that Reinforce-Ada accelerates convergence and improves final performance compared to GRPO, especially when using the balanced sampling variant. Our work highlights the central role of variance-aware, adaptive data curation in enabling efficient and reliable reinforcement learning for reasoning-capable LLMs. Code is available at https://github.com/RLHFlow/Reinforce-Ada.
Best-of-L: Cross-Lingual Reward Modeling for Mathematical Reasoning
Sep 19, 2025While the reasoning abilities of large language models (LLMs) continue to advance, it remains unclear how such ability varies across languages in multilingual LLMs and whether different languages produce reasoning paths that complement each other. To investigate this question, we train a reward model to rank generated responses for a given question across languages. Our results show that our cross-lingual reward model substantially improves mathematical reasoning performance compared to using reward modeling within a single language, benefiting even high-resource languages. While English often exhibits the highest performance in multilingual models, we find that cross-lingual sampling particularly benefits English under low sampling budgets. Our findings reveal new opportunities to improve multilingual reasoning by leveraging the complementary strengths of diverse languages.
Please Translate Again: Two Simple Experiments on Whether Human-Like Reasoning Helps Translation
Jun 05, 2025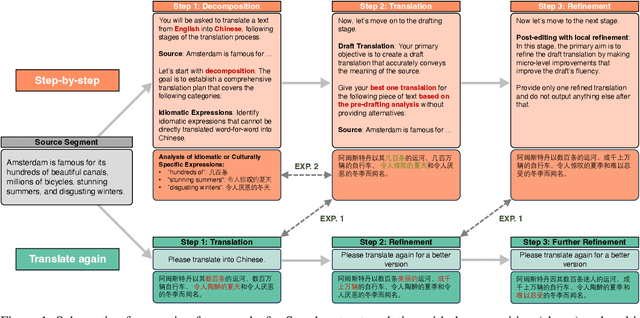
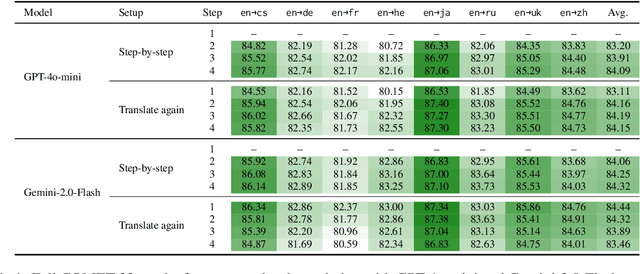
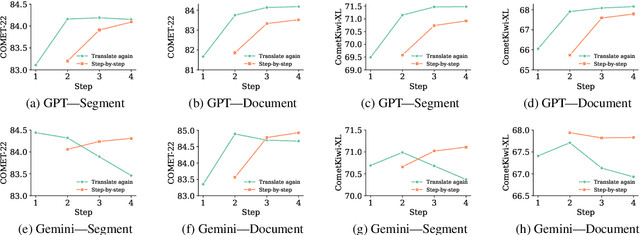
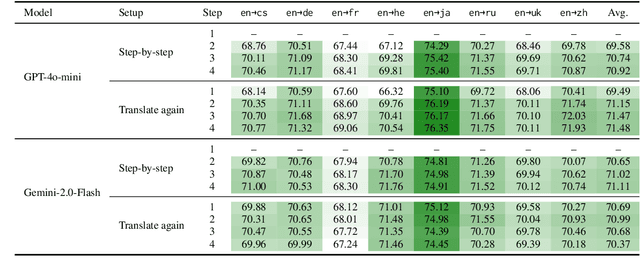
Large Language Models (LLMs) demonstrate strong reasoning capabilities for many tasks, often by explicitly decomposing the task via Chain-of-Thought (CoT) reasoning. Recent work on LLM-based translation designs hand-crafted prompts to decompose translation, or trains models to incorporate intermediate steps.~\textit{Translating Step-by-step}~\citep{briakou2024translating}, for instance, introduces a multi-step prompt with decomposition and refinement of translation with LLMs, which achieved state-of-the-art results on WMT24. In this work, we scrutinise this strategy's effectiveness. Empirically, we find no clear evidence that performance gains stem from explicitly decomposing the translation process, at least for the models on test; and we show that simply prompting LLMs to ``translate again'' yields even better results than human-like step-by-step prompting. Our analysis does not rule out the role of reasoning, but instead invites future work exploring the factors for CoT's effectiveness in the context of translation.
The Effect of Language Diversity When Fine-Tuning Large Language Models for Translation
May 19, 2025Prior research diverges on language diversity in LLM fine-tuning: Some studies report benefits while others find no advantages. Through controlled fine-tuning experiments across 132 translation directions, we systematically resolve these disparities. We find that expanding language diversity during fine-tuning improves translation quality for both unsupervised and -- surprisingly -- supervised pairs, despite less diverse models being fine-tuned exclusively on these supervised pairs. However, benefits plateau or decrease beyond a certain diversity threshold. We show that increased language diversity creates more language-agnostic representations. These representational adaptations help explain the improved performance in models fine-tuned with greater diversity.
Fractured Chain-of-Thought Reasoning
May 19, 2025Inference-time scaling techniques have significantly bolstered the reasoning capabilities of large language models (LLMs) by harnessing additional computational effort at inference without retraining. Similarly, Chain-of-Thought (CoT) prompting and its extension, Long CoT, improve accuracy by generating rich intermediate reasoning trajectories, but these approaches incur substantial token costs that impede their deployment in latency-sensitive settings. In this work, we first show that truncated CoT, which stops reasoning before completion and directly generates the final answer, often matches full CoT sampling while using dramatically fewer tokens. Building on this insight, we introduce Fractured Sampling, a unified inference-time strategy that interpolates between full CoT and solution-only sampling along three orthogonal axes: (1) the number of reasoning trajectories, (2) the number of final solutions per trajectory, and (3) the depth at which reasoning traces are truncated. Through extensive experiments on five diverse reasoning benchmarks and several model scales, we demonstrate that Fractured Sampling consistently achieves superior accuracy-cost trade-offs, yielding steep log-linear scaling gains in Pass@k versus token budget. Our analysis reveals how to allocate computation across these dimensions to maximize performance, paving the way for more efficient and scalable LLM reasoning.