 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep CSI Compression for Massive MIMO: A Self-information Model-driven Neural Network
Apr 25, 2022

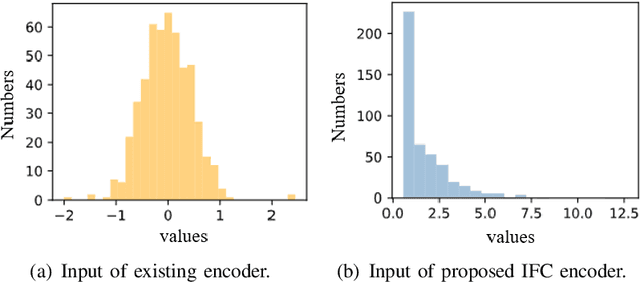
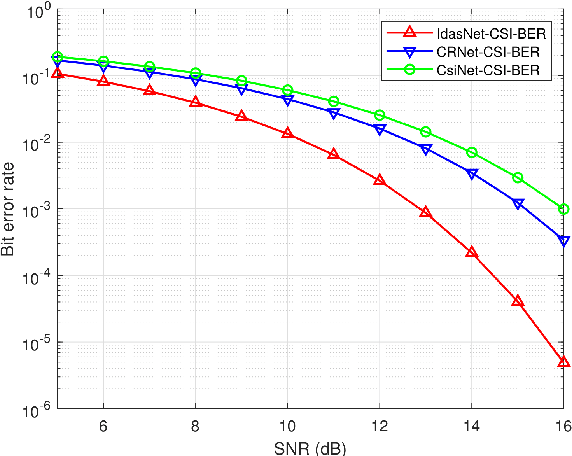
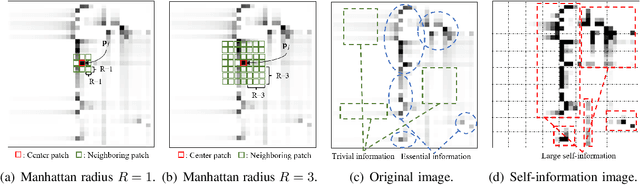
In order to fully exploit the advantages of massive multiple-input multiple-output (mMIMO), it is critical for the transmitter to accurately acquire the channel state information (CSI). Deep learning (DL)-based methods have been proposed for CSI compression and feedback to the transmitter. Although most existing DL-based methods consider the CSI matrix as an image, structural features of the CSI image are rarely exploited in neural network design. As such, we propose a model of self-information that dynamically measures the amount of information contained in each patch of a CSI image from the perspective of structural features. Then, by applying the self-information model, we propose a model-and-data-driven network for CSI compression and feedback, namely IdasNet. The IdasNet includes the design of a module of self-information deletion and selection (IDAS), an encoder of informative feature compression (IFC), and a decoder of informative feature recovery (IFR). In particular, the model-driven module of IDAS pre-compresses the CSI image by removing informative redundancy in terms of the self-information. The encoder of IFC then conducts feature compression to the pre-compressed CSI image and generates a feature codeword which contains two components, i.e., codeword values and position indices of the codeword values. Subsequently, the IFR decoder decouples the codeword values as well as position indices to recover the CSI image. Experimental results verify that the proposed IdasNet noticeably outperforms existing DL-based networks under various compression ratios while it has the number of network parameters reduced by orders-of-magnitude compared with various existing methods.
Building and Evaluating Universal Named-Entity Recognition English corpus
Dec 14, 2022
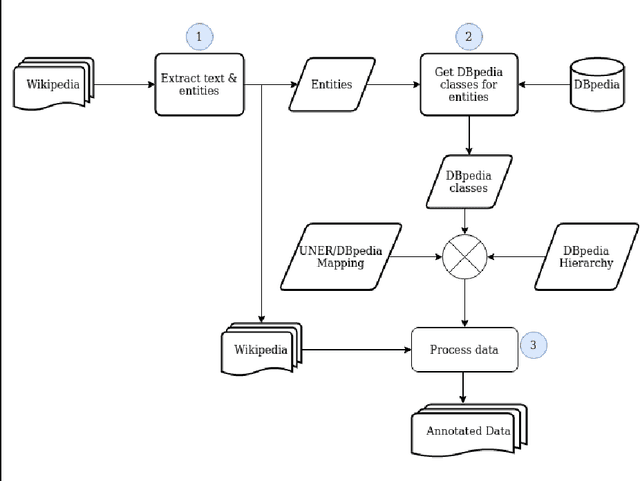
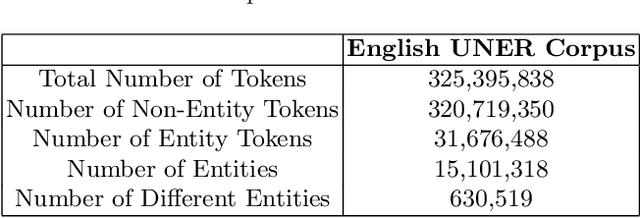
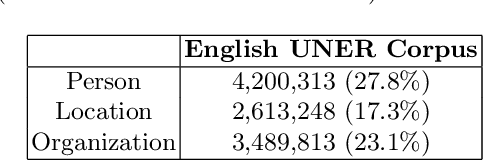
This article presents the application of the Universal Named Entity framework to generate automatically annotated corpora. By using a workflow that extracts Wikipedia data and meta-data and DBpedia information, we generated an English dataset which is described and evaluated. Furthermore, we conducted a set of experiments to improve the annotations in terms of precision, recall, and F1-measure. The final dataset is available and the established workflow can be applied to any language with existing Wikipedia and DBpedia. As part of future research, we intend to continue improving the annotation process and extend it to other languages.
Event-based Monocular Dense Depth Estimation with Recurrent Transformers
Dec 06, 2022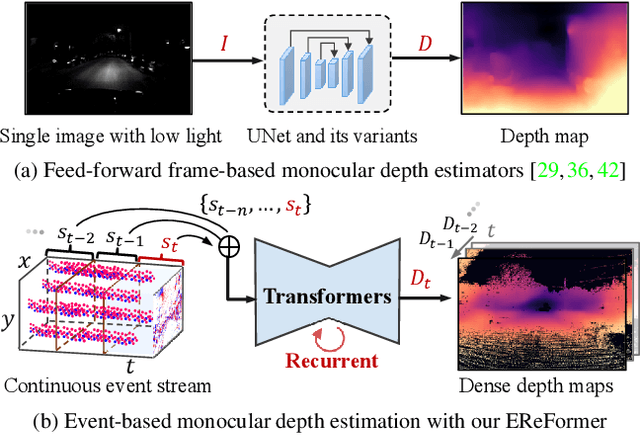
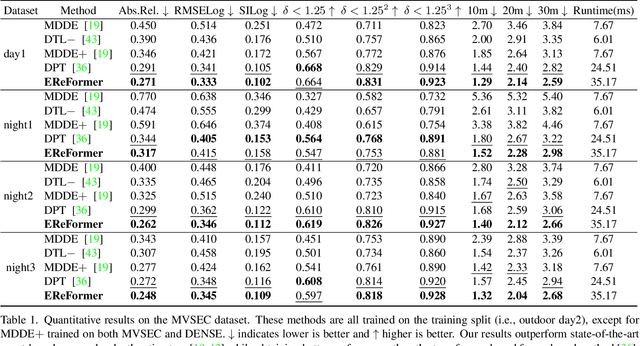
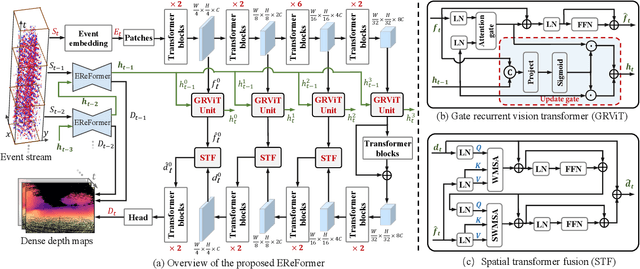
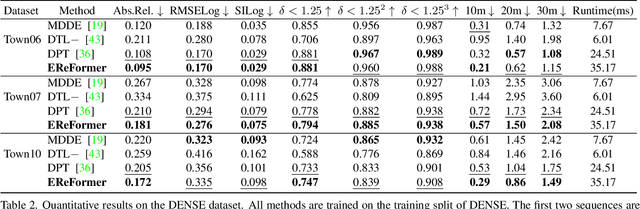
Event cameras, offering high temporal resolutions and high dynamic ranges, have brought a new perspective to address common challenges (e.g., motion blur and low light) in monocular depth estimation. However, how to effectively exploit the sparse spatial information and rich temporal cues from asynchronous events remains a challenging endeavor. To this end, we propose a novel event-based monocular depth estimator with recurrent transformers, namely EReFormer, which is the first pure transformer with a recursive mechanism to process continuous event streams. Technically, for spatial modeling, a novel transformer-based encoder-decoder with a spatial transformer fusion module is presented, having better global context information modeling capabilities than CNN-based methods. For temporal modeling, we design a gate recurrent vision transformer unit that introduces a recursive mechanism into transformers, improving temporal modeling capabilities while alleviating the expensive GPU memory cost. The experimental results show that our EReFormer outperforms state-of-the-art methods by a margin on both synthetic and real-world datasets. We hope that our work will attract further research to develop stunning transformers in the event-based vision community. Our open-source code can be found in the supplemental material.
Robust Sum-Rate Maximization in Transmissive RMS Transceiver-Enabled SWIPT Networks
Dec 10, 2022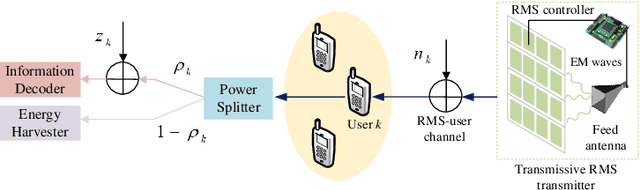
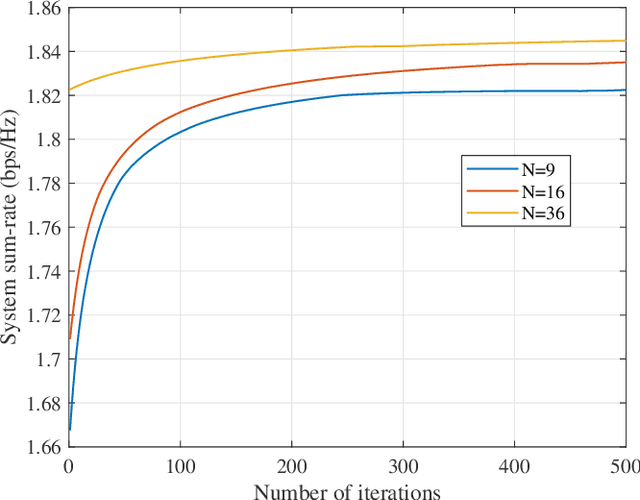
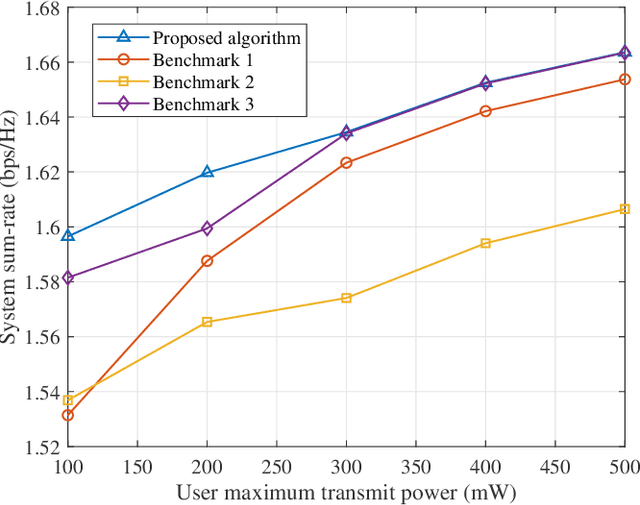
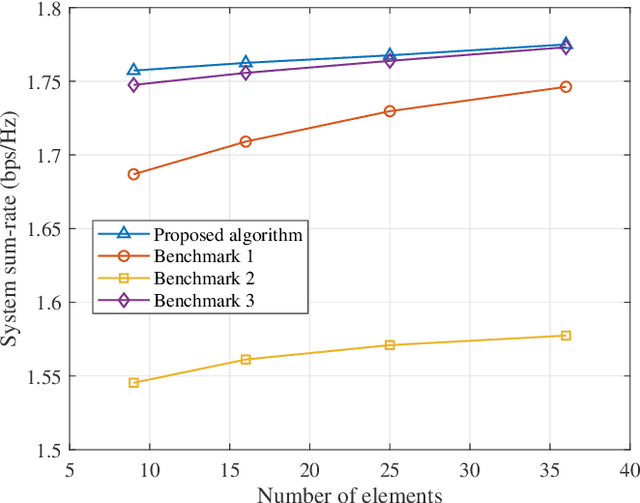
In this paper, we propose a state-of-the-art downlink communication transceiver design for transmissive reconfigurable metasurface (RMS)-enabled simultaneous wireless information and power transfer (SWIPT) networks. Specifically, a feed antenna is deployed in the transmissive RMS-based transceiver, which can be used to implement beamforming. According to the relationship between wavelength and propagation distance, the spatial propagation models of plane and spherical waves are built. Then, in the case of imperfect channel state information (CSI), we formulate a robust system sum-rate maximization problem that jointly optimizes RMS transmissive coefficient, transmit power allocation, and power splitting ratio design while taking account of the non-linear energy harvesting model and outage probability criterion. Since the coupling of optimization variables, the whole optimization problem is non-convex and cannot be solved directly. Therefore, the alternating optimization (AO) framework is implemented to decompose the non-convex original problem. In detail, the whole problem is divided into three sub-problems to solve. For the non-convexity of the objective function, successive convex approximation (SCA) is used to transform it, and penalty function method and difference-of-convex (DC) programming are applied to deal with the non-convex constraints. Finally, we alternately solve the three sub-problems until the entire optimization problem converges. Numerical results show that our proposed algorithm has convergence and better performance than other benchmark algorithms.
Rank-LIME: Local Model-Agnostic Feature Attribution for Learning to Rank
Dec 24, 2022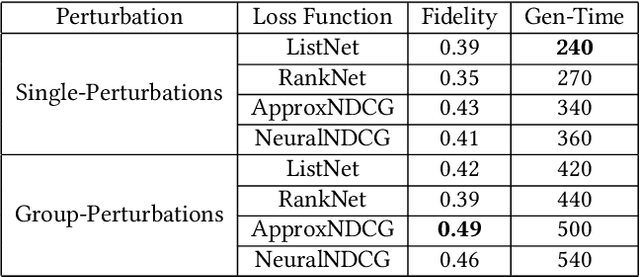

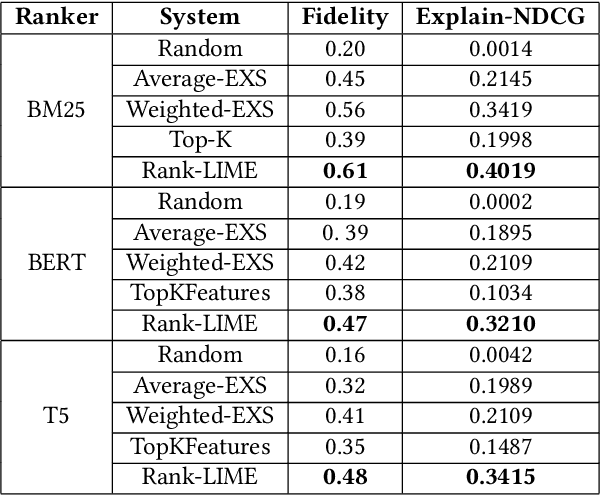
Understanding why a model makes certain predictions is crucial when adapting it for real world decision making. LIME is a popular model-agnostic feature attribution method for the tasks of classification and regression. However, the task of learning to rank in information retrieval is more complex in comparison with either classification or regression. In this work, we extend LIME to propose Rank-LIME, a model-agnostic, local, post-hoc linear feature attribution method for the task of learning to rank that generates explanations for ranked lists. We employ novel correlation-based perturbations, differentiable ranking loss functions and introduce new metrics to evaluate ranking based additive feature attribution models. We compare Rank-LIME with a variety of competing systems, with models trained on the MS MARCO datasets and observe that Rank-LIME outperforms existing explanation algorithms in terms of Model Fidelity and Explain-NDCG. With this we propose one of the first algorithms to generate additive feature attributions for explaining ranked lists.
Message Passing-Based 9-D Cooperative Localization and Navigation with Embedded Particle Flow
Jan 03, 2023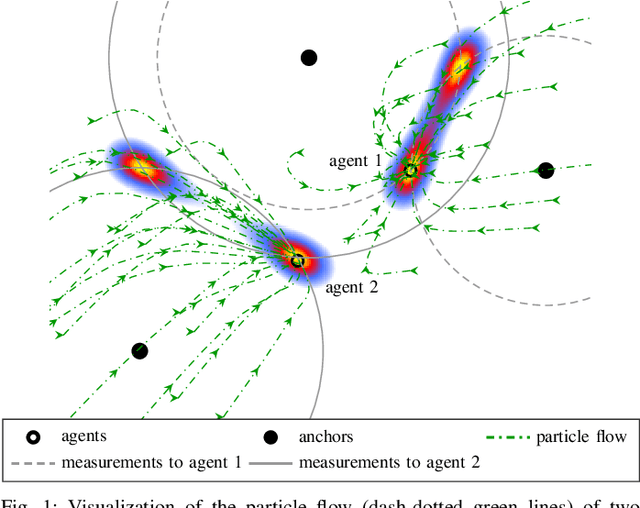
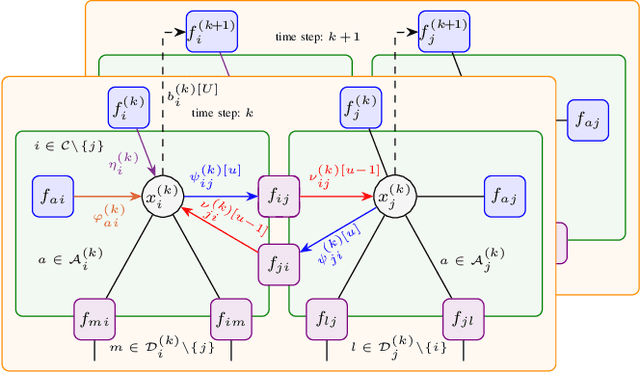

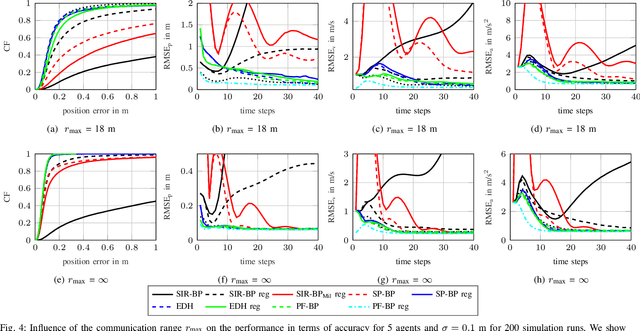
Cooperative localization (CL) is an important technology for innovative services such as location-aware communication networks, modern convenience, and public safety. We consider wireless networks with mobile agents that aim to localize themselves by performing pairwise measurements amongst agents and exchanging their location information. Belief propagation (BP) is a state-of-the-art Bayesian method for CL. In CL, particle-based implementations of BP often are employed that can cope with non-linear measurement models and state dynamics. However, particle-based BP algorithms are known to suffer from particle degeneracy in large and dense networks of mobile agents with high-dimensional states. This paper derives the messages of BP for CL by means of particle flow, leading to the development of a distributed particle-based message-passing algorithm which avoids particle degeneracy. Our combined particle flow-based BP approach allows the calculation of highly accurate proposal distributions for agent states with a minimal number of particles. It outperforms conventional particle-based BP algorithms in terms of accuracy and runtime. Furthermore, we compare the proposed method to a centralized particle flow-based implementation, known as the exact Daum-Huang filter, and to sigma point BP in terms of position accuracy, runtime, and memory requirement versus the network size. We further contrast all methods to the theoretical performance limit provided by the posterior Cram\'er-Rao lower bound (PCRLB). Based on three different scenarios, we demonstrate the superiority of the proposed method.
In Defense of Structural Symbolic Representation for Video Event-Relation Prediction
Jan 06, 2023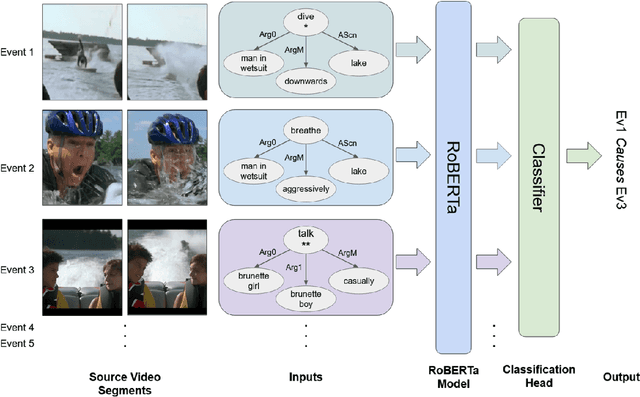

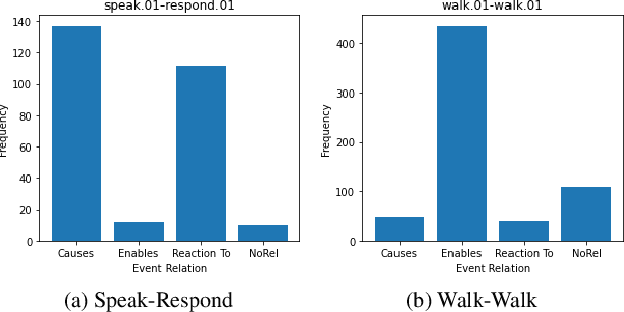

Understanding event relationships in videos requires a model to understand the underlying structures of events, i.e., the event type, the associated argument roles, and corresponding entities) along with factual knowledge needed for reasoning. Structural symbolic representation (SSR) based methods directly take event types and associated argument roles/entities as inputs to perform reasoning. However, the state-of-the-art video event-relation prediction system shows the necessity of using continuous feature vectors from input videos; existing methods based solely on SSR inputs fail completely, event when given oracle event types and argument roles. In this paper, we conduct an extensive empirical analysis to answer the following questions: 1) why SSR-based method failed; 2) how to understand the evaluation setting of video event relation prediction properly; 3) how to uncover the potential of SSR-based methods. We first identify the failure of previous SSR-based video event prediction models to be caused by sub-optimal training settings. Surprisingly, we find that a simple SSR-based model with tuned hyperparameters can actually yield a 20\% absolute improvement in macro-accuracy over the state-of-the-art model. Then through qualitative and quantitative analysis, we show how evaluation that takes only video as inputs is currently unfeasible, and the reliance on oracle event information to obtain an accurate evaluation. Based on these findings, we propose to further contextualize the SSR-based model to an Event-Sequence Model and equip it with more factual knowledge through a simple yet effective way of reformulating external visual commonsense knowledge bases into an event-relation prediction pretraining dataset. The resultant new state-of-the-art model eventually establishes a 25\% Macro-accuracy performance boost.
Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation
Jan 06, 2023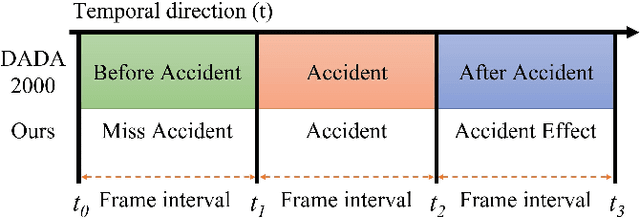
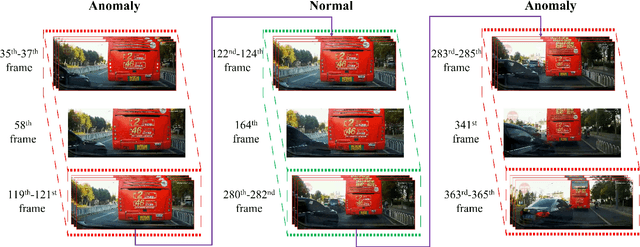

To develop the advanced self-driving systems, many researchers are focusing to alert all possible traffic risk cases from closed-circuit television (CCTV) and dashboard-mounted cameras. Most of these methods focused on identifying frame-by-frame in which an anomaly has occurred, but they are unrealized, which road traffic participant can cause ego-vehicle leading into collision because of available annotation dataset only to detect anomaly on traffic video. Near-miss is one type of accident and can be defined as a narrowly avoided accident. However, there is no difference between accident and near-miss at the time before the accident happened, so our contribution is to redefine the accident definition and re-annotate the accident inconsistency on DADA-2000 dataset together with near-miss. By extending the start and end time of accident duration, our annotation can precisely cover all ego-motions during an incident and consistently classify all possible traffic risk accidents including near-miss to give more critical information for real-world driving assistance systems. The proposed method integrates two different components: conditional style translation (CST) and separable 3-dimensional convolutional neural network (S3D). CST architecture is derived by unsupervised image-to-image translation networks (UNIT) used for augmenting the re-annotation DADA-2000 dataset to increase the number of traffic risk accident videos and to generalize the performance of video classification model on different types of conditions while S3D is useful for video classification to prove dataset re-annotation consistency. In evaluation, the proposed method achieved a significant improvement result by 10.25% positive margin from the baseline model for accuracy on cross-validation analysis.
* 8 pages, conference
Fiduciary Responsibility: Facilitating Public Trust in Automated Decision Making
Jan 06, 2023

Automated decision-making systems are being increasingly deployed and affect the public in a multitude of positive and negative ways. Governmental and private institutions use these systems to process information according to certain human-devised rules in order to address social problems or organizational challenges. Both research and real-world experience indicate that the public lacks trust in automated decision-making systems and the institutions that deploy them. The recreancy theorem argues that the public is more likely to trust and support decisions made or influenced by automated decision-making systems if the institutions that administer them meet their fiduciary responsibility. However, often the public is never informed of how these systems operate and resultant institutional decisions are made. A ``black box'' effect of automated decision-making systems reduces the public's perceptions of integrity and trustworthiness. The result is that the public loses the capacity to identify, challenge, and rectify unfairness or the costs associated with the loss of public goods or benefits. The current position paper defines and explains the role of fiduciary responsibility within an automated decision-making system. We formulate an automated decision-making system as a data science lifecycle (DSL) and examine the implications of fiduciary responsibility within the context of the DSL. Fiduciary responsibility within DSLs provides a methodology for addressing the public's lack of trust in automated decision-making systems and the institutions that employ them to make decisions affecting the public. We posit that fiduciary responsibility manifests in several contexts of a DSL, each of which requires its own mitigation of sources of mistrust. To instantiate fiduciary responsibility, a Los Angeles Police Department (LAPD) predictive policing case study is examined.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 15, 2022
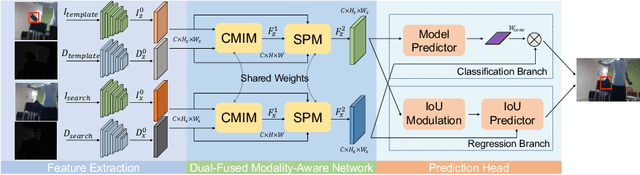
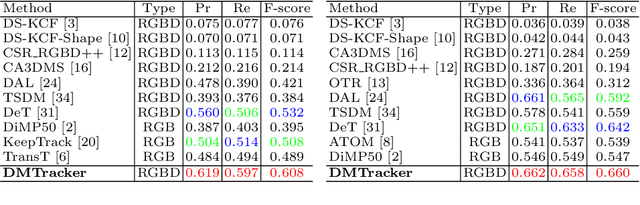

With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.