 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrepSeek: Training Search Agents for Direct Corpus Interaction
May 28, 2026Large Language Model (LLM) search agents have shown strong promise for knowledge-intensive language tasks through multiple rounds of reasoning and information retrieval. Most existing systems access information using a retriever that takes a keyword or natural language query and returns a ranked list of documents using an index of pre-computed document representations. In this work, we explore a complementary perspective in which the search agent treats the corpus itself as the search environment and finds evidence by issuing executable shell commands. We introduce GrepSeek, an optimized direct corpus interaction (DCI) search agent that trains a compact search agent to find, filter, and compose evidence from large text corpora. To address the instability of learning behavior directly with reinforcement learning on large corpora, we propose a two-stage training pipeline. First, we construct a cold-start dataset using an answer-aware Tutor and answer-blind Planner to generate verified, causally grounded search trajectories. Second, we refine the initialized policy with Group Relative Policy Optimization (GRPO), allowing the agent to improve its task-oriented search behavior through direct interaction with the corpus. To make DCI practical at scale, we further use a semantics-preserving sharded-parallel execution engine that accelerates shell-based retrieval by up to $7.6\times$ while preserving byte-exact equivalence with sequential execution of the shell command. Experiments across seven open-domain question answering benchmarks show that GrepSeek achieves the strongest overall token-level $F_1$ and Exact Match. Our analysis also highlights the limitations of purely lexical interaction on queries with substantial surface-form variation, suggesting DCI as a practical and competitive method for search agents that can complement existing retrieval paradigms in the real world.
PRIME: Planning and Retrieval-Integrated Memory for Enhanced Reasoning
Sep 26, 2025Inspired by the dual-process theory of human cognition from \textit{Thinking, Fast and Slow}, we introduce \textbf{PRIME} (Planning and Retrieval-Integrated Memory for Enhanced Reasoning), a multi-agent reasoning framework that dynamically integrates \textbf{System 1} (fast, intuitive thinking) and \textbf{System 2} (slow, deliberate thinking). PRIME first employs a Quick Thinking Agent (System 1) to generate a rapid answer; if uncertainty is detected, it then triggers a structured System 2 reasoning pipeline composed of specialized agents for \textit{planning}, \textit{hypothesis generation}, \textit{retrieval}, \textit{information integration}, and \textit{decision-making}. This multi-agent design faithfully mimics human cognitive processes and enhances both efficiency and accuracy. Experimental results with LLaMA 3 models demonstrate that PRIME enables open-source LLMs to perform competitively with state-of-the-art closed-source models like GPT-4 and GPT-4o on benchmarks requiring multi-hop and knowledge-grounded reasoning. This research establishes PRIME as a scalable solution for improving LLMs in domains requiring complex, knowledge-intensive reasoning.
RaDeR: Reasoning-aware Dense Retrieval Models
May 23, 2025



We propose RaDeR, a set of reasoning-based dense retrieval models trained with data derived from mathematical problem solving using large language models (LLMs). Our method leverages retrieval-augmented reasoning trajectories of an LLM and self-reflective relevance evaluation, enabling the creation of both diverse and hard-negative samples for reasoning-intensive relevance. RaDeR retrievers, trained for mathematical reasoning, effectively generalize to diverse reasoning tasks in the BRIGHT and RAR-b benchmarks, consistently outperforming strong baselines in overall performance.Notably, RaDeR achieves significantly higher performance than baselines on the Math and Coding splits. In addition, RaDeR presents the first dense retriever that outperforms BM25 when queries are Chain-of-Thought reasoning steps, underscoring the critical role of reasoning-based retrieval to augment reasoning language models. Furthermore, RaDeR achieves comparable or superior performance while using only 2.5% of the training data used by the concurrent work REASONIR, highlighting the quality of our synthesized training data.
Discovering Biases in Information Retrieval Models Using Relevance Thesaurus as Global Explanation
Oct 04, 2024



Most efforts in interpreting neural relevance models have focused on local explanations, which explain the relevance of a document to a query but are not useful in predicting the model's behavior on unseen query-document pairs. We propose a novel method to globally explain neural relevance models by constructing a "relevance thesaurus" containing semantically relevant query and document term pairs. This thesaurus is used to augment lexical matching models such as BM25 to approximate the neural model's predictions. Our method involves training a neural relevance model to score the relevance of partial query and document segments, which is then used to identify relevant terms across the vocabulary space. We evaluate the obtained thesaurus explanation based on ranking effectiveness and fidelity to the target neural ranking model. Notably, our thesaurus reveals the existence of brand name bias in ranking models, demonstrating one advantage of our explanation method.
PaRaDe: Passage Ranking using Demonstrations with Large Language Models
Oct 22, 2023



Recent studies show that large language models (LLMs) can be instructed to effectively perform zero-shot passage re-ranking, in which the results of a first stage retrieval method, such as BM25, are rated and reordered to improve relevance. In this work, we improve LLM-based re-ranking by algorithmically selecting few-shot demonstrations to include in the prompt. Our analysis investigates the conditions where demonstrations are most helpful, and shows that adding even one demonstration is significantly beneficial. We propose a novel demonstration selection strategy based on difficulty rather than the commonly used semantic similarity. Furthermore, we find that demonstrations helpful for ranking are also effective at question generation. We hope our work will spur more principled research into question generation and passage ranking.
Rank-LIME: Local Model-Agnostic Feature Attribution for Learning to Rank
Dec 24, 2022


Understanding why a model makes certain predictions is crucial when adapting it for real world decision making. LIME is a popular model-agnostic feature attribution method for the tasks of classification and regression. However, the task of learning to rank in information retrieval is more complex in comparison with either classification or regression. In this work, we extend LIME to propose Rank-LIME, a model-agnostic, local, post-hoc linear feature attribution method for the task of learning to rank that generates explanations for ranked lists. We employ novel correlation-based perturbations, differentiable ranking loss functions and introduce new metrics to evaluate ranking based additive feature attribution models. We compare Rank-LIME with a variety of competing systems, with models trained on the MS MARCO datasets and observe that Rank-LIME outperforms existing explanation algorithms in terms of Model Fidelity and Explain-NDCG. With this we propose one of the first algorithms to generate additive feature attributions for explaining ranked lists.
You can't pick your neighbors, or can you? When and how to rely on retrieval in the $k$NN-LM
Oct 28, 2022



Retrieval-enhanced language models (LMs), which condition their predictions on text retrieved from large external datastores, have recently shown significant perplexity improvements compared to standard LMs. One such approach, the $k$NN-LM, interpolates any existing LM's predictions with the output of a $k$-nearest neighbors model and requires no additional training. In this paper, we explore the importance of lexical and semantic matching in the context of items retrieved by $k$NN-LM. We find two trends: (1) the presence of large overlapping $n$-grams between the datastore and evaluation set plays an important factor in strong performance, even when the datastore is derived from the training data; and (2) the $k$NN-LM is most beneficial when retrieved items have high semantic similarity with the query. Based on our analysis, we define a new formulation of the $k$NN-LM that uses retrieval quality to assign the interpolation coefficient. We empirically measure the effectiveness of our approach on two English language modeling datasets, Wikitext-103 and PG-19. Our re-formulation of the $k$NN-LM is beneficial in both cases, and leads to nearly 4% improvement in perplexity on the Wikitext-103 test set.
Explaining Documents' Relevance to Search Queries
Nov 02, 2021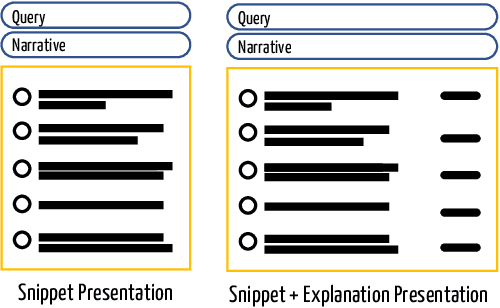

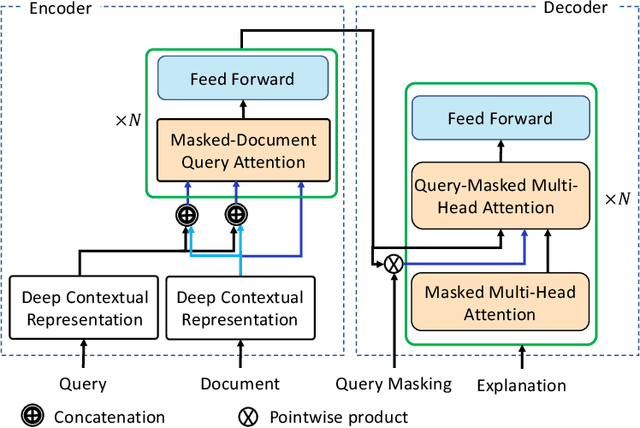
We present GenEx, a generative model to explain search results to users beyond just showing matches between query and document words. Adding GenEx explanations to search results greatly impacts user satisfaction and search performance. Search engines mostly provide document titles, URLs, and snippets for each result. Existing model-agnostic explanation methods similarly focus on word matching or content-based features. However, a recent user study shows that word matching features are quite obvious to users and thus of slight value. GenEx explains a search result by providing a terse description for the query aspect covered by that result. We cast the task as a sequence transduction problem and propose a novel model based on the Transformer architecture. To represent documents with respect to the given queries and yet not generate the queries themselves as explanations, two query-attention layers and masked-query decoding are added to the Transformer architecture. The model is trained without using any human-generated explanations. Training data are instead automatically constructed to ensure a tolerable noise level and a generalizable learned model. Experimental evaluation shows that our explanation models significantly outperform the baseline models. Evaluation through user studies also demonstrates that our explanation model generates short yet useful explanations.
Mixed Attention Transformer for Leveraging Word-Level Knowledge to Neural Cross-Lingual Information Retrieval
Sep 14, 2021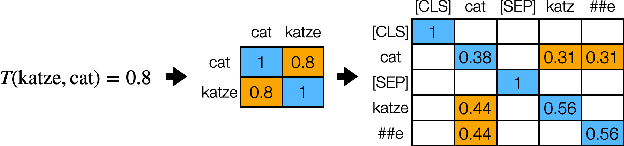

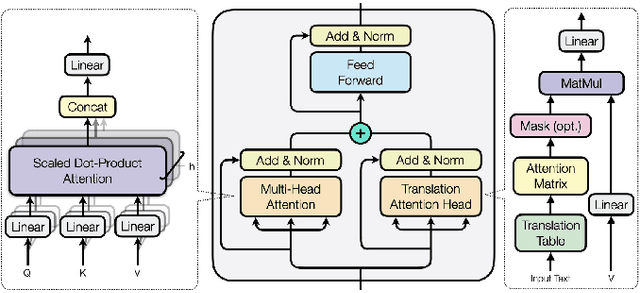
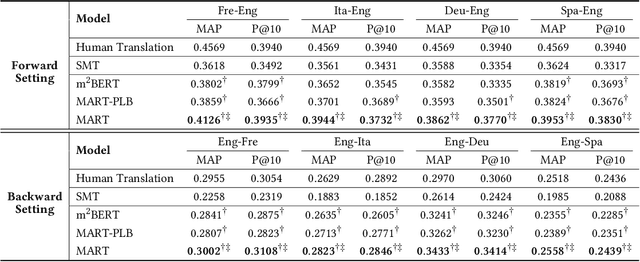
Pretrained contextualized representations offer great success for many downstream tasks, including document ranking. The multilingual versions of such pretrained representations provide a possibility of jointly learning many languages with the same model. Although it is expected to gain big with such joint training, in the case of cross lingual information retrieval (CLIR), the models under a multilingual setting are not achieving the same level of performance as those under a monolingual setting. We hypothesize that the performance drop is due to the translation gap between query and documents. In the monolingual retrieval task, because of the same lexical inputs, it is easier for model to identify the query terms that occurred in documents. However, in the multilingual pretrained models that the words in different languages are projected into the same hyperspace, the model tends to translate query terms into related terms, i.e., terms that appear in a similar context, in addition to or sometimes rather than synonyms in the target language. This property is creating difficulties for the model to connect terms that cooccur in both query and document. To address this issue, we propose a novel Mixed Attention Transformer (MAT) that incorporates external word level knowledge, such as a dictionary or translation table. We design a sandwich like architecture to embed MAT into the recent transformer based deep neural models. By encoding the translation knowledge into an attention matrix, the model with MAT is able to focus on the mutually translated words in the input sequence. Experimental results demonstrate the effectiveness of the external knowledge and the significant improvement of MAT embedded neural reranking model on CLIR task.
Query-driven Segment Selection for Ranking Long Documents
Sep 10, 2021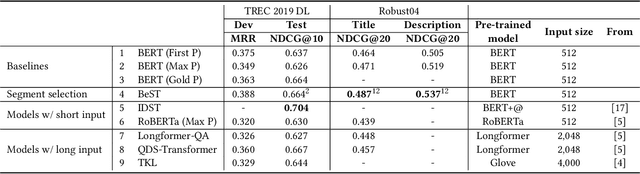
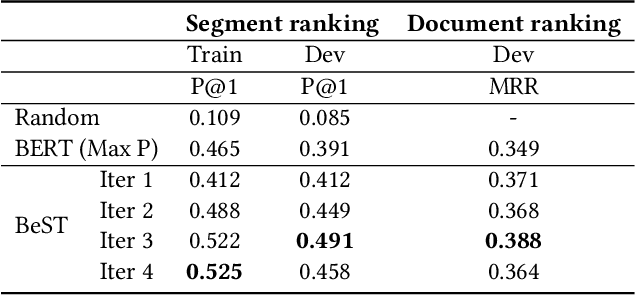
Transformer-based rankers have shown state-of-the-art performance. However, their self-attention operation is mostly unable to process long sequences. One of the common approaches to train these rankers is to heuristically select some segments of each document, such as the first segment, as training data. However, these segments may not contain the query-related parts of documents. To address this problem, we propose query-driven segment selection from long documents to build training data. The segment selector provides relevant samples with more accurate labels and non-relevant samples which are harder to be predicted. The experimental results show that the basic BERT-based ranker trained with the proposed segment selector significantly outperforms that trained by the heuristically selected segments, and performs equally to the state-of-the-art model with localized self-attention that can process longer input sequences. Our findings open up new direction to design efficient transformer-based rankers.
* 5 pages, 0 figure