 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SeCG: Semantic-Enhanced 3D Visual Grounding via Cross-modal Graph Attention
Mar 13, 2024

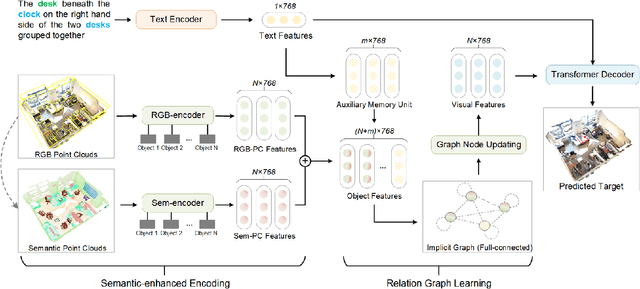
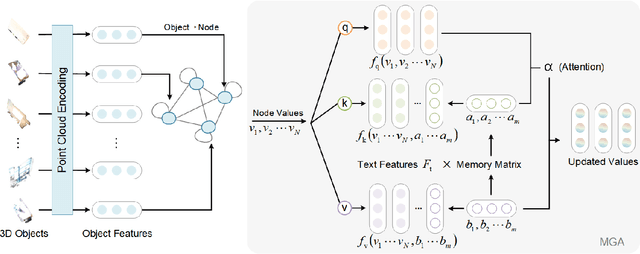
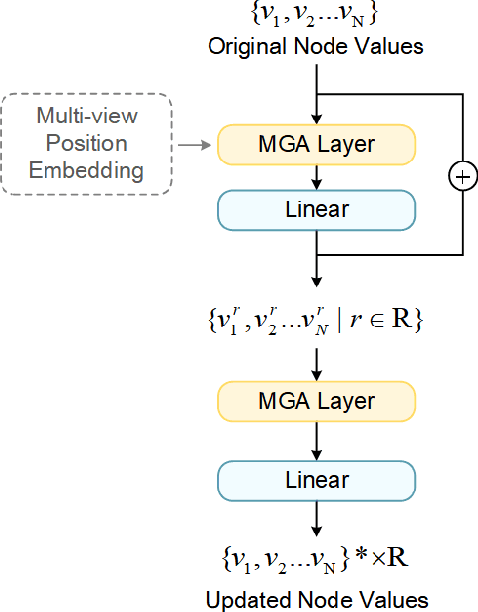
3D visual grounding aims to automatically locate the 3D region of the specified object given the corresponding textual description. Existing works fail to distinguish similar objects especially when multiple referred objects are involved in the description. Experiments show that direct matching of language and visual modal has limited capacity to comprehend complex referential relationships in utterances. It is mainly due to the interference caused by redundant visual information in cross-modal alignment. To strengthen relation-orientated mapping between different modalities, we propose SeCG, a semantic-enhanced relational learning model based on a graph network with our designed memory graph attention layer. Our method replaces original language-independent encoding with cross-modal encoding in visual analysis. More text-related feature expressions are obtained through the guidance of global semantics and implicit relationships. Experimental results on ReferIt3D and ScanRefer benchmarks show that the proposed method outperforms the existing state-of-the-art methods, particularly improving the localization performance for the multi-relation challenges.
Rich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Mar 13, 2024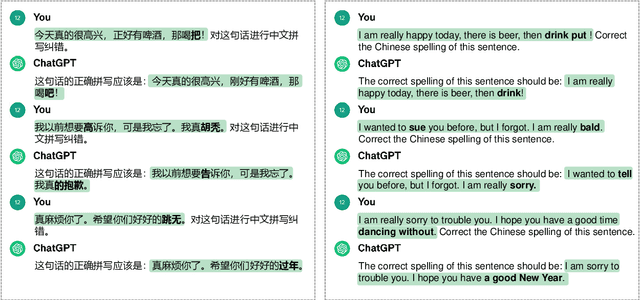
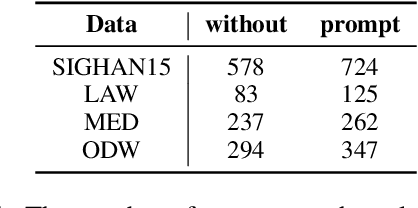
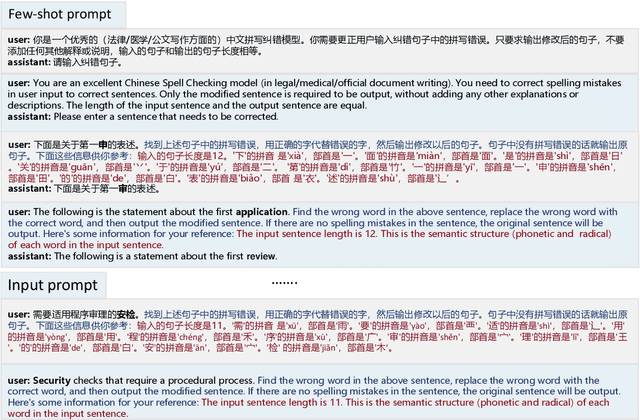
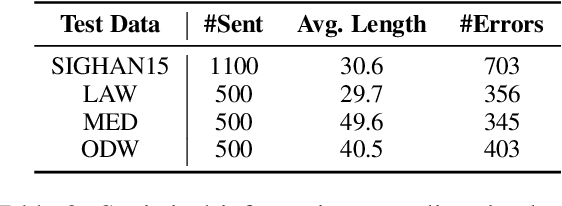
Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.
Knowledge Transfer across Multiple Principal Component Analysis Studies
Mar 12, 2024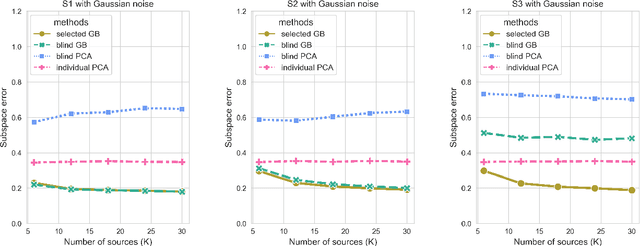
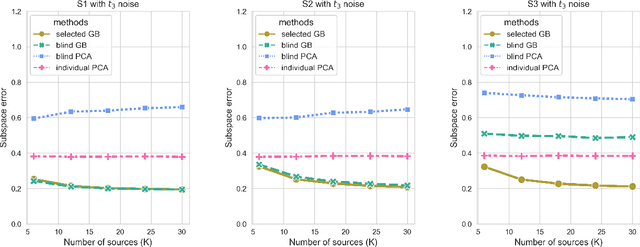
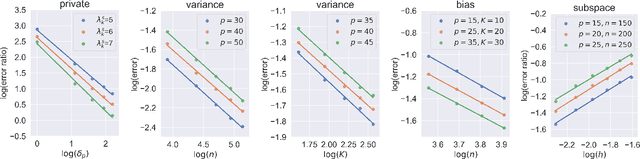
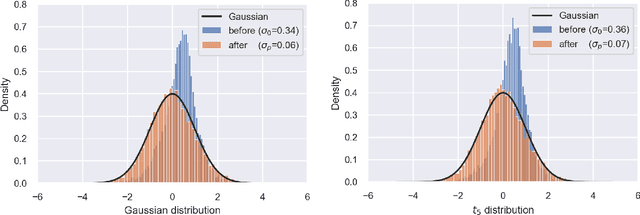
Transfer learning has aroused great interest in the statistical community. In this article, we focus on knowledge transfer for unsupervised learning tasks in contrast to the supervised learning tasks in the literature. Given the transferable source populations, we propose a two-step transfer learning algorithm to extract useful information from multiple source principal component analysis (PCA) studies, thereby enhancing estimation accuracy for the target PCA task. In the first step, we integrate the shared subspace information across multiple studies by a proposed method named as Grassmannian barycenter, instead of directly performing PCA on the pooled dataset. The proposed Grassmannian barycenter method enjoys robustness and computational advantages in more general cases. Then the resulting estimator for the shared subspace from the first step is further utilized to estimate the target private subspace in the second step. Our theoretical analysis credits the gain of knowledge transfer between PCA studies to the enlarged eigenvalue gap, which is different from the existing supervised transfer learning tasks where sparsity plays the central role. In addition, we prove that the bilinear forms of the empirical spectral projectors have asymptotic normality under weaker eigenvalue gap conditions after knowledge transfer. When the set of informativesources is unknown, we endow our algorithm with the capability of useful dataset selection by solving a rectified optimization problem on the Grassmann manifold, which in turn leads to a computationally friendly rectified Grassmannian K-means procedure. In the end, extensive numerical simulation results and a real data case concerning activity recognition are reported to support our theoretical claims and to illustrate the empirical usefulness of the proposed transfer learning methods.
Information-based Transductive Active Learning
Feb 13, 2024We generalize active learning to address real-world settings where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. To this end, we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified prediction targets. We show, under general regularity assumptions, that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate ITL in two key applications: Few-shot fine-tuning of large neural networks and safe Bayesian optimization, and in both cases, ITL significantly outperforms the state-of-the-art.
Interference Mitigation in LEO Constellations with Limited Radio Environment Information
Feb 19, 2024This research paper delves into interference mitigation within Low Earth Orbit (LEO) satellite constellations, particularly when operating under constraints of limited radio environment information. Leveraging cognitive capabilities facilitated by the Radio Environment Map (REM), we explore strategies to mitigate the impact of both intentional and unintentional interference using planar antenna array (PAA) beamforming techniques. We address the complexities encountered in the design of beamforming weights, a challenge exacerbated by the array size and the increasing number of directions of interest and avoidance. Furthermore, we conduct an extensive analysis of beamforming performance from various perspectives associated with limited REM information: static versus dynamic, partial versus full, and perfect versus imperfect. To substantiate our findings, we provide simulation results and offer conclusions based on the outcomes of our investigation.
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Mar 14, 2024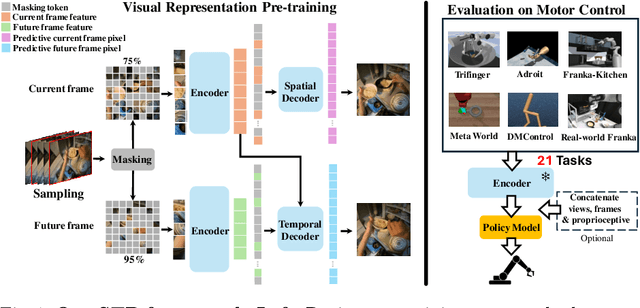
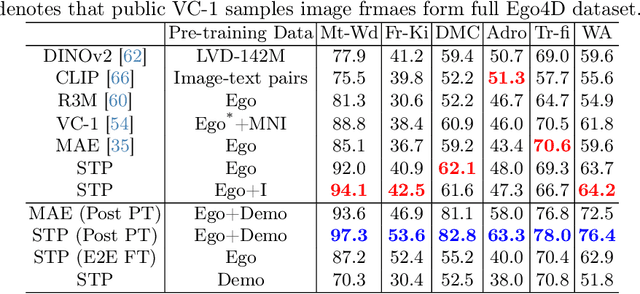


Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal predictive learning utilizing large-scale video data, termed as STP. Our STP samples paired frames from video clips. It adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. These efficient designs ensure that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training.
BRIEDGE: EEG-Adaptive Edge AI for Multi-Brain to Multi-Robot Interaction
Mar 14, 2024Recent advances in EEG-based BCI technologies have revealed the potential of brain-to-robot collaboration through the integration of sensing, computing, communication, and control. In this paper, we present BRIEDGE as an end-to-end system for multi-brain to multi-robot interaction through an EEG-adaptive neural network and an encoding-decoding communication framework, as illustrated in Fig.1. As depicted, the edge mobile server or edge portable server will collect EEG data from the users and utilize the EEG-adaptive neural network to identify the users' intentions. The encoding-decoding communication framework then encodes the EEG-based semantic information and decodes it into commands in the process of data transmission. To better extract the joint features of heterogeneous EEG data as well as enhance classification accuracy, BRIEDGE introduces an informer-based ProbSparse self-attention mechanism. Meanwhile, parallel and secure transmissions for multi-user multi-task scenarios under physical channels are addressed by dynamic autoencoder and autodecoder communications. From mobile computing and edge AI perspectives, model compression schemes composed of pruning, weight sharing, and quantization are also used to deploy lightweight EEG-adaptive models running on both transmitter and receiver sides. Based on the effectiveness of these components, a code map representing various commands enables multiple users to control multiple intelligent agents concurrently. Our experiments in comparison with state-of-the-art works show that BRIEDGE achieves the best classification accuracy of heterogeneous EEG data, and more stable performance under noisy environments.
Radar Rainbow Beams For Wideband mmWave Communication: Beam Training And Tracking
Mar 14, 2024We propose a novel integrated sensing and communication (ISAC) system that leverages sensing to assist communication, ensuring fast initial access, seamless user tracking, and uninterrupted communication for millimeter wave (mmWave) wideband systems. True-time-delayers (TTDs) are utilized to generate frequency-dependent radar rainbow beams by controlling the beam squint effect. These beams cover users across the entire angular space simultaneously for fast beam training using just one orthogonal frequency-division multiplexing (OFDM) symbol. Three detection and estimation schemes are proposed based on radar rainbow beams for estimation of the users' angles, distances, and velocities, which are then exploited for communication beamformer design. The first proposed scheme utilizes a single-antenna radar receiver and one set of rainbow beams, but may cause a Doppler ambiguity. To tackle this limitation, two additional schemes are introduced, utilizing two sets of rainbow beams and a multi-antenna receiver, respectively. Furthermore, the proposed detection and estimation schemes are extended to realize user tracking by choosing different subsets of OFDM subcarriers. This approach eliminates the need to switch phase shifters and TTDs, which are typically necessary in existing tracking technologies, thereby reducing the demands on the control circurity. Simulation results reveal the effectiveness of the proposed rainbow beam-based training and tracking methods for mobile users. Notably, the scheme employing a multi-antenna radar receiver can accurately estimate the channel parameters and can support communication rates comparable to those achieved with perfect channel information.
Optimal Top-Two Method for Best Arm Identification and Fluid Analysis
Mar 14, 2024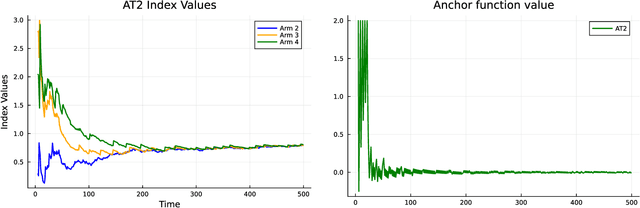

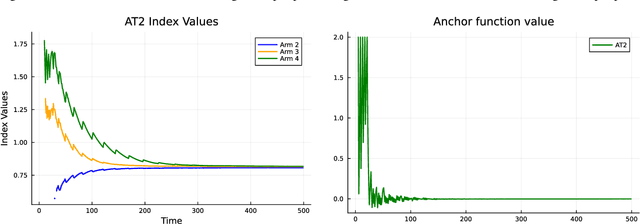
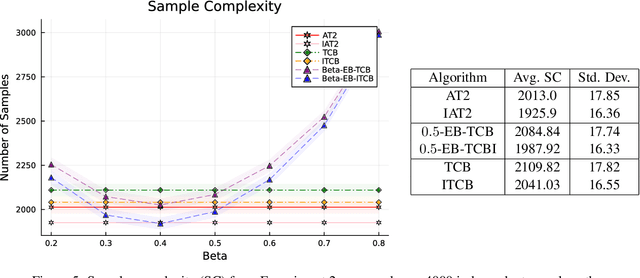
Top-$2$ methods have become popular in solving the best arm identification (BAI) problem. The best arm, or the arm with the largest mean amongst finitely many, is identified through an algorithm that at any sequential step independently pulls the empirical best arm, with a fixed probability $\beta$, and pulls the best challenger arm otherwise. The probability of incorrect selection is guaranteed to lie below a specified $\delta >0$. Information theoretic lower bounds on sample complexity are well known for BAI problem and are matched asymptotically as $\delta \rightarrow 0$ by computationally demanding plug-in methods. The above top 2 algorithm for any $\beta \in (0,1)$ has sample complexity within a constant of the lower bound. However, determining the optimal $\beta$ that matches the lower bound has proven difficult. In this paper, we address this and propose an optimal top-2 type algorithm. We consider a function of allocations anchored at a threshold. If it exceeds the threshold then the algorithm samples the empirical best arm. Otherwise, it samples the challenger arm. We show that the proposed algorithm is optimal as $\delta \rightarrow 0$. Our analysis relies on identifying a limiting fluid dynamics of allocations that satisfy a series of ordinary differential equations pasted together and that describe the asymptotic path followed by our algorithm. We rely on the implicit function theorem to show existence and uniqueness of these fluid ode's and to show that the proposed algorithm remains close to the ode solution.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024
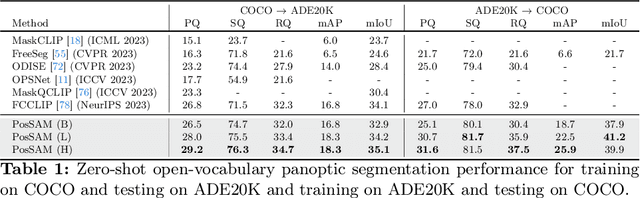

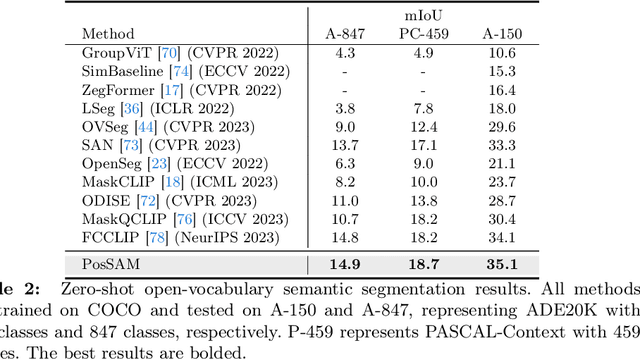
In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.