 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Channelformer: Attention based Neural Solution for Wireless Channel Estimation and Effective Online Training
Feb 08, 2023
In this paper, we propose an encoder-decoder neural architecture (called Channelformer) to achieve improved channel estimation for orthogonal frequency-division multiplexing (OFDM) waveforms in downlink scenarios. The self-attention mechanism is employed to achieve input precoding for the input features before processing them in the decoder. In particular, we implement multi-head attention in the encoder and a residual convolutional neural architecture as the decoder, respectively. We also employ a customized weight-level pruning to slim the trained neural network with a fine-tuning process, which reduces the computational complexity significantly to realize a low complexity and low latency solution. This enables reductions of up to 70\% in the parameters, while maintaining an almost identical performance compared with the complete Channelformer. We also propose an effective online training method based on the fifth generation (5G) new radio (NR) configuration for the modern communication systems, which only needs the available information at the receiver for online training. Using industrial standard channel models, the simulations of attention-based solutions show superior estimation performance compared with other candidate neural network methods for channel estimation.
On the Feasibility of Out-of-Band Spatial Channel Information for Millimeter-Wave Beam Search
Aug 04, 2022
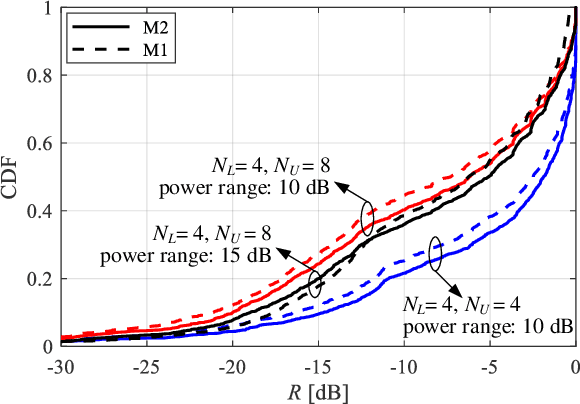
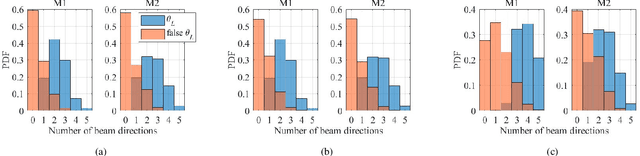
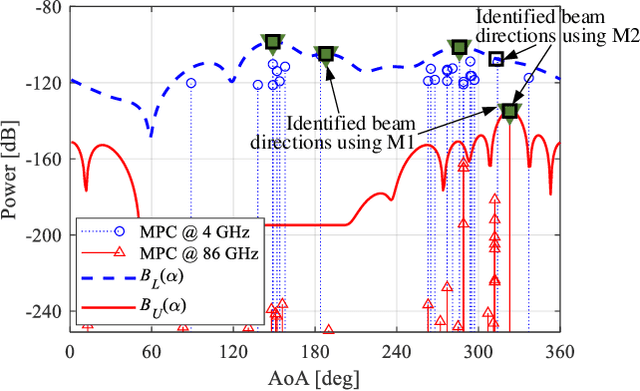
The rollout of millimeter-wave (mmWave) cellular network enables us to realize the full potential of 5G/6G with vastly improved throughput and ultra-low latency. MmWave communication relies on highly directional transmission, which significantly increase the training overhead for fine beam alignment. The concept of using out-of-band spatial information to aid mmWave beam search is developed when multi-band systems operating in parallel. The feasibility of leveraging low-band channel information for coarse estimation of high-band beam directions strongly depends on the spatial congruence between two frequency bands. In this paper, we try to provide insights into the answers of two important questions. First, how similar is the power angular spectra (PAS) of radio channels between two well-separated frequency bands? Then, what is the impact of practical system configurations on spatial channel similarity? Specifically, the beam direction-based metric is proposed to measure the power loss and number of false directions if out-of-band spatial information is used instead of in-band information. This metric is more practical and useful than comparing normalized PAS directly. Point cloud ray-tracing and measurement results across multiple frequency bands and environments show that the degree of spatial similarity of beamformed channels is related to antenna beamwidth, frequency gap, and radio link conditions.
LabelPrompt: Effective Prompt-based Learning for Relation Classification
Feb 16, 2023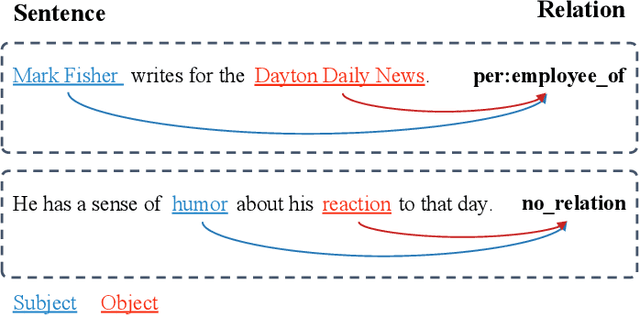
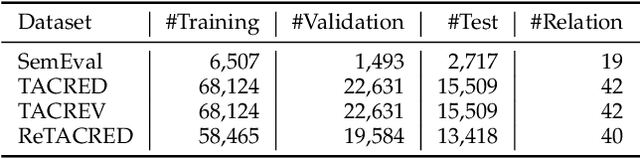
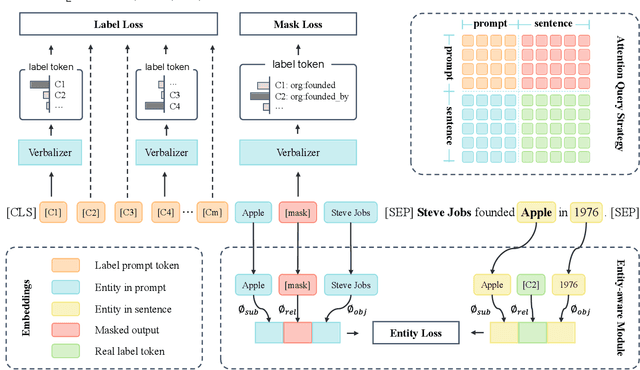
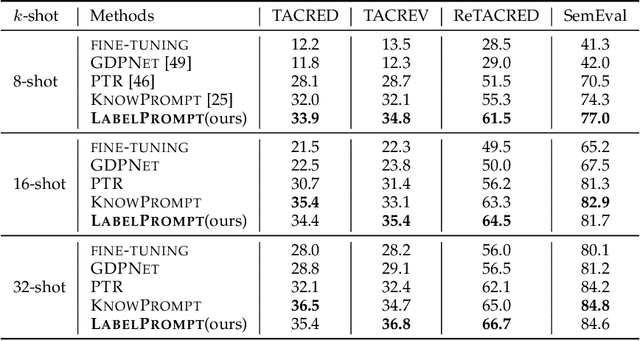
Recently, prompt-based learning has become a very popular solution in many Natural Language Processing (NLP) tasks by inserting a template into model input, which converts the task into a cloze-style one to smoothing out differences between the Pre-trained Language Model (PLM) and the current task. But in the case of relation classification, it is difficult to map the masked output to the relation labels because of its abundant semantic information, e.g. org:founded_by''. Therefore, a pre-trained model still needs enough labelled data to fit the relations. To mitigate this challenge, in this paper, we present a novel prompt-based learning method, namely LabelPrompt, for the relation classification task. It is an extraordinary intuitive approach by a motivation: ``GIVE MODEL CHOICES!''. First, we define some additional tokens to represent the relation labels, which regards these tokens as the verbalizer with semantic initialisation and constructs them with a prompt template method. Then we revisit the inconsistency of the predicted relation and the given entities, an entity-aware module with the thought of contrastive learning is designed to mitigate the problem. At last, we apply an attention query strategy to self-attention layers to resolve two types of tokens, prompt tokens and sequence tokens. The proposed strategy effectively improves the adaptation capability of prompt-based learning in the relation classification task when only a small labelled data is available. Extensive experimental results obtained on several bench-marking datasets demonstrate the superiority of the proposed LabelPrompt method, particularly in the few-shot scenario.
Isotopic envelope identification by analysis of the spatial distribution of components in MALDI-MSI data
Feb 13, 2023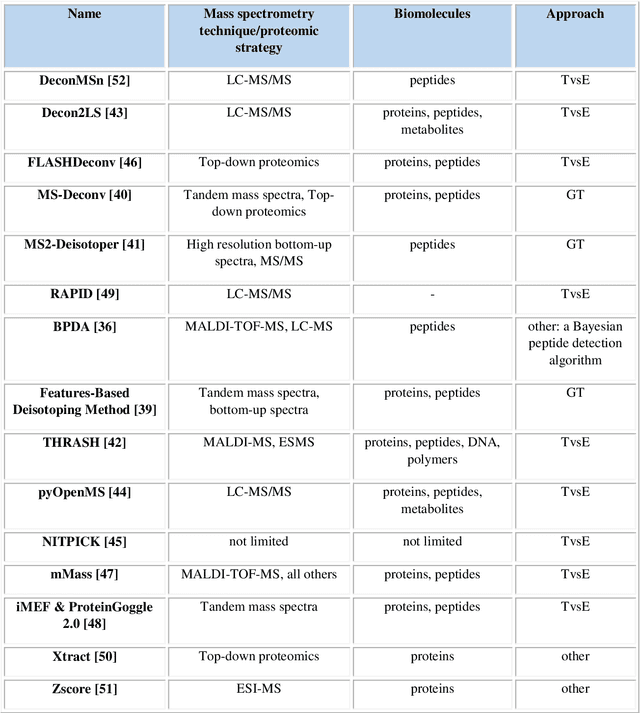
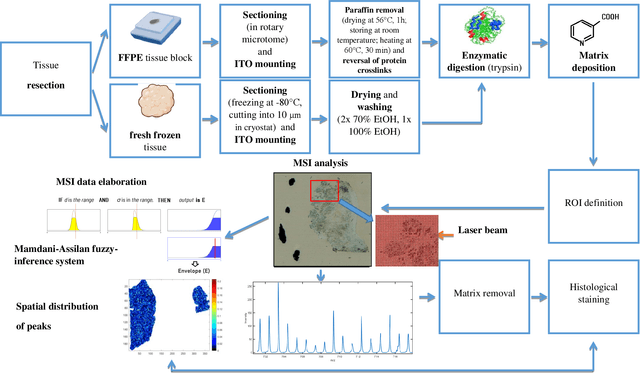
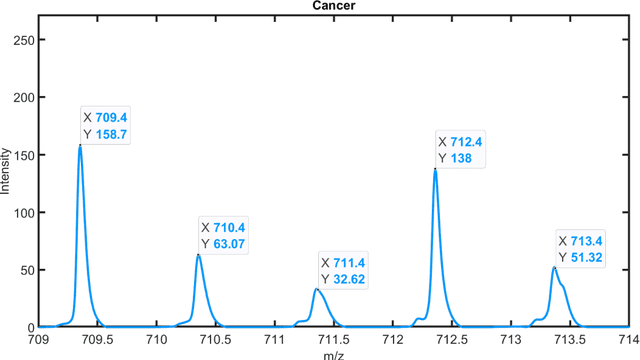
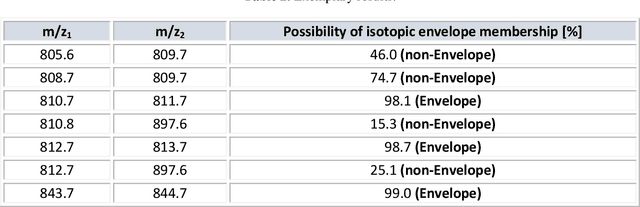
One of the significant steps in the process leading to the identification of proteins is mass spectrometry, which allows for obtaining information about the structure of proteins. Removing isotope peaks from the mass spectrum is vital and it is done in a process called deisotoping. There are different algorithms for deisotoping, but they have their limitations, they are dedicated to different methods of mass spectrometry. Data from experiments performed with the MALDI-ToF technique are characterized by high dimensionality. This paper presents a method for identifying isotope envelopes in MALDI-ToF molecular imaging data based on the Mamdani-Assilan fuzzy system and spatial maps of the molecular distribution of peaks included in the isotopic envelope. Several image texture measures were used to evaluate spatial molecular distribution maps. The algorithm was tested on eight datasets obtained from the MALDI-ToF experiment on samples from the National Institute of Oncology in Gliwice from patients with cancer of the head and neck region. The data were subjected to pre-processing and feature extraction. The results were collected and compared with three existing deisotoping algorithms. The analysis of the obtained results showed that the method for identifying isotopic envelopes proposed in this paper enables the detection of overlapping envelopes by using the approach oriented to study peak pairs. Moreover, the proposed algorithm enables the analysis of large data sets.
Inspecting class hierarchies in classification-based metric learning models
Jan 26, 2023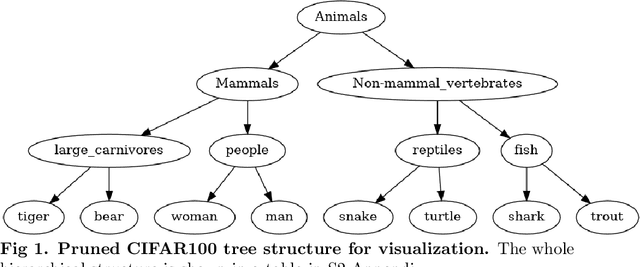
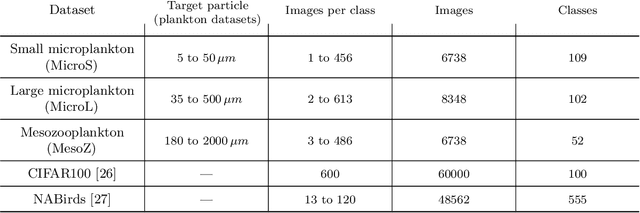

Most classification models treat all misclassifications equally. However, different classes may be related, and these hierarchical relationships must be considered in some classification problems. These problems can be addressed by using hierarchical information during training. Unfortunately, this information is not available for all datasets. Many classification-based metric learning methods use class representatives in embedding space to represent different classes. The relationships among the learned class representatives can then be used to estimate class hierarchical structures. If we have a predefined class hierarchy, the learned class representatives can be assessed to determine whether the metric learning model learned semantic distances that match our prior knowledge. In this work, we train a softmax classifier and three metric learning models with several training options on benchmark and real-world datasets. In addition to the standard classification accuracy, we evaluate the hierarchical inference performance by inspecting learned class representatives and the hierarchy-informed performance, i.e., the classification performance, and the metric learning performance by considering predefined hierarchical structures. Furthermore, we investigate how the considered measures are affected by various models and training options. When our proposed ProxyDR model is trained without using predefined hierarchical structures, the hierarchical inference performance is significantly better than that of the popular NormFace model. Additionally, our model enhances some hierarchy-informed performance measures under the same training options. We also found that convolutional neural networks (CNNs) with random weights correspond to the predefined hierarchies better than random chance.
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Jan 29, 2023
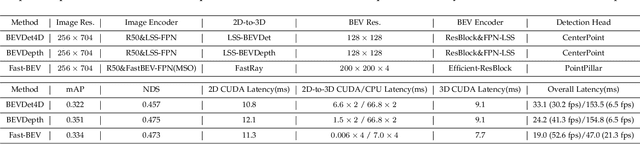
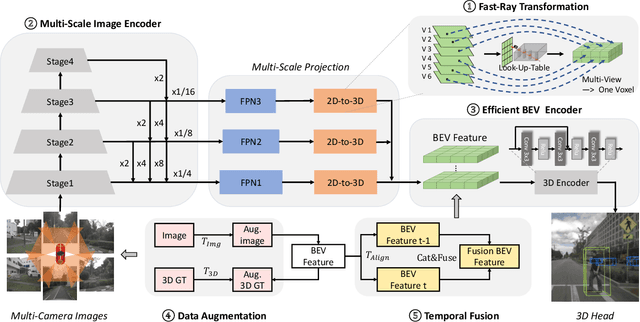
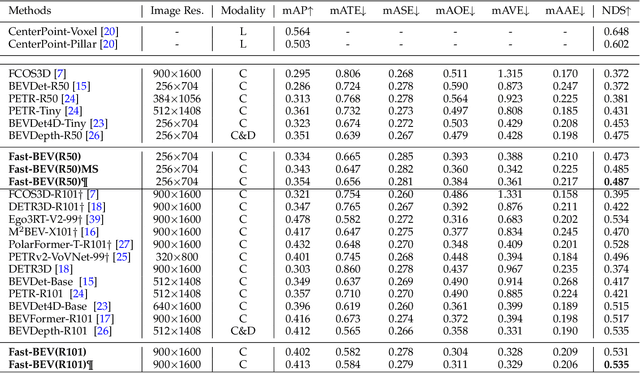
Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
Decoupled Side Information Fusion for Sequential Recommendation
Apr 23, 2022
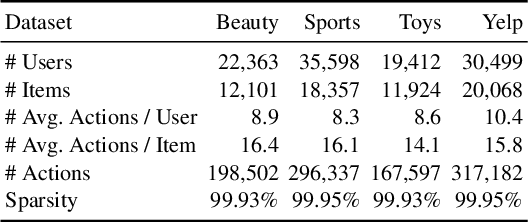
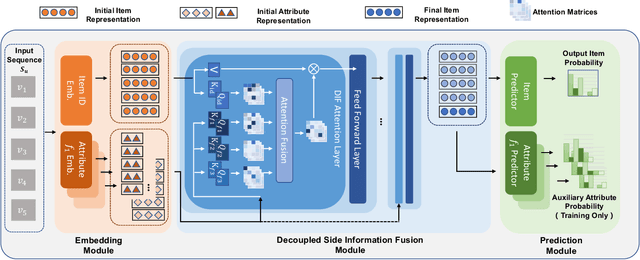
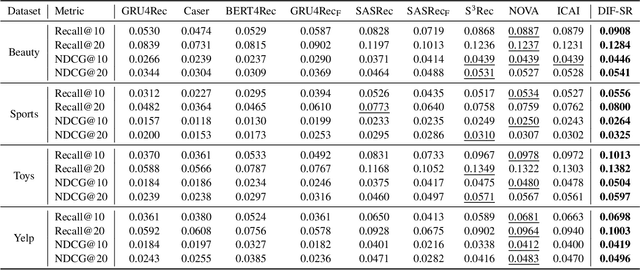
Side information fusion for sequential recommendation (SR) aims to effectively leverage various side information to enhance the performance of next-item prediction. Most state-of-the-art methods build on self-attention networks and focus on exploring various solutions to integrate the item embedding and side information embeddings before the attention layer. However, our analysis shows that the early integration of various types of embeddings limits the expressiveness of attention matrices due to a rank bottleneck and constrains the flexibility of gradients. Also, it involves mixed correlations among the different heterogeneous information resources, which brings extra disturbance to attention calculation. Motivated by this, we propose Decoupled Side Information Fusion for Sequential Recommendation (DIF-SR), which moves the side information from the input to the attention layer and decouples the attention calculation of various side information and item representation. We theoretically and empirically show that the proposed solution allows higher-rank attention matrices and flexible gradients to enhance the modeling capacity of side information fusion. Also, auxiliary attribute predictors are proposed to further activate the beneficial interaction between side information and item representation learning. Extensive experiments on four real-world datasets demonstrate that our proposed solution stably outperforms state-of-the-art SR models. Further studies show that our proposed solution can be readily incorporated into current attention-based SR models and significantly boost performance. Our source code is available at https://github.com/AIM-SE/DIF-SR.
Binary Embedding-based Retrieval at Tencent
Feb 17, 2023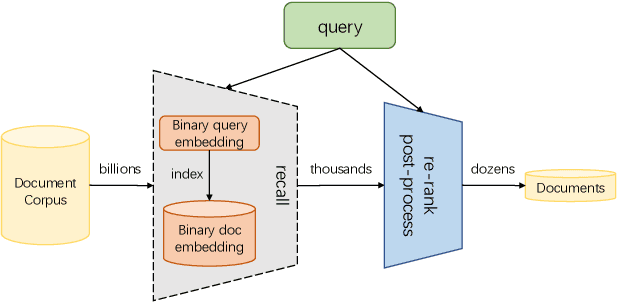

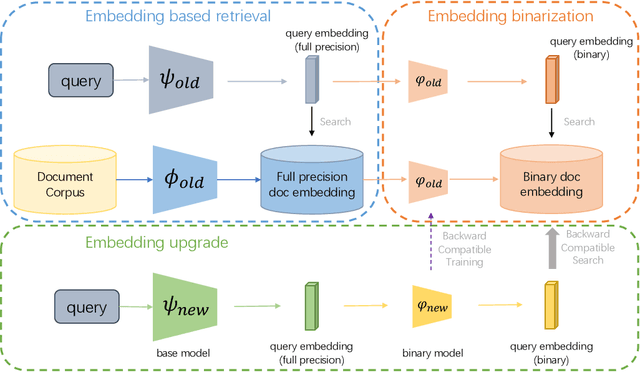

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
Leveraging Angular Information Between Feature and Classifier for Long-tailed Learning: A Prediction Reformulation Approach
Dec 03, 2022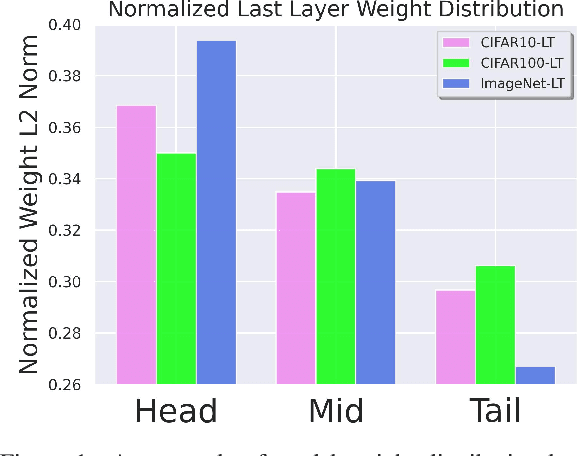
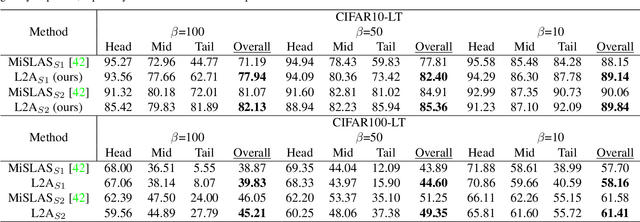
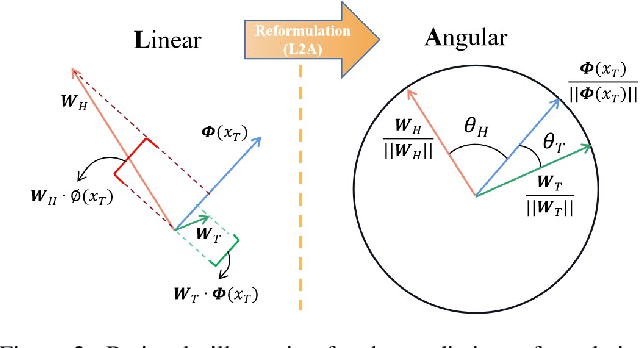
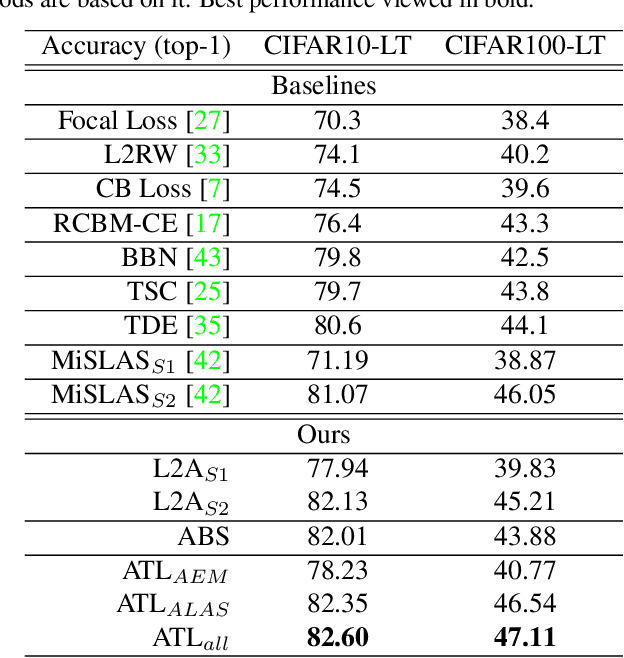
Deep neural networks still struggle on long-tailed image datasets, and one of the reasons is that the imbalance of training data across categories leads to the imbalance of trained model parameters. Motivated by the empirical findings that trained classifiers yield larger weight norms in head classes, we propose to reformulate the recognition probabilities through included angles without re-balancing the classifier weights. Specifically, we calculate the angles between the data feature and the class-wise classifier weights to obtain angle-based prediction results. Inspired by the performance improvement of the predictive form reformulation and the outstanding performance of the widely used two-stage learning framework, we explore the different properties of this angular prediction and propose novel modules to improve the performance of different components in the framework. Our method is able to obtain the best performance among peer methods without pretraining on CIFAR10/100-LT and ImageNet-LT. Source code will be made publicly available.
Leveraging task dependency and contrastive learning for Legal Judgement Prediction on the European Court of Human Rights
Feb 03, 2023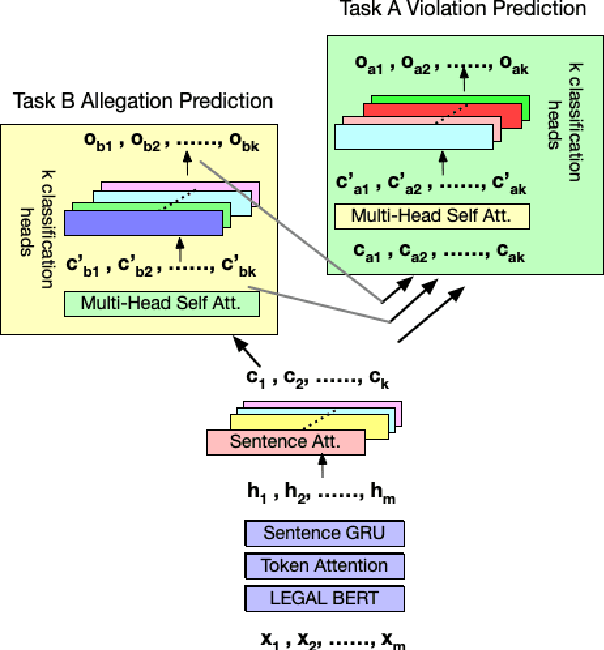
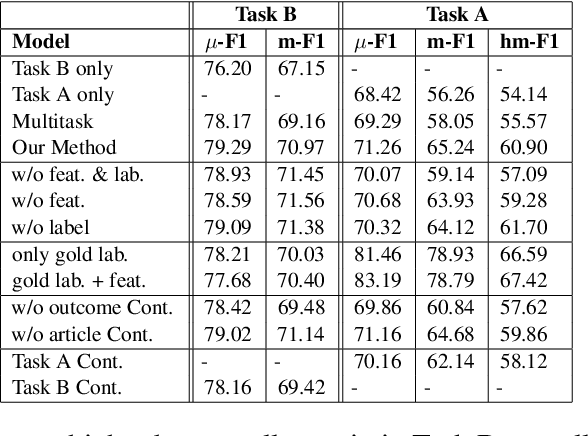
We report on an experiment in legal judgement prediction on European Court of Human Rights cases where our model first learns to predict the convention articles allegedly violated by the state from case facts descriptions, and subsequently utilizes that information to predict a finding of a violation by the court. We assess the dependency between these two tasks at the feature and outcome level. Furthermore, we leverage a hierarchical contrastive loss to pull together article specific representations of cases at the higher level level, leading to distinctive article clusters, and further pulls the cases in each article cluster based on their outcome leading to sub-clusters of cases with similar outcomes. Our experiment results demonstrate that, given a static pre-trained encoder, our models produce a small but consistent improvement in prediction performance over single-task and joint models without contrastive loss.