 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Dataset of Coordinated Cryptocurrency-Related Social Media Campaigns
Jan 16, 2023
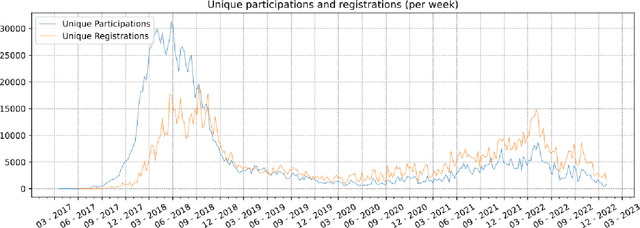
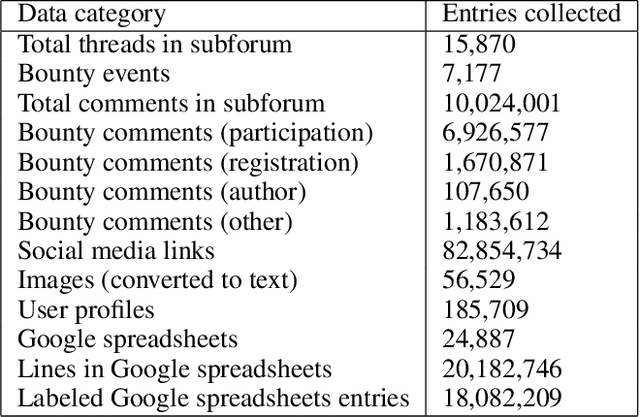
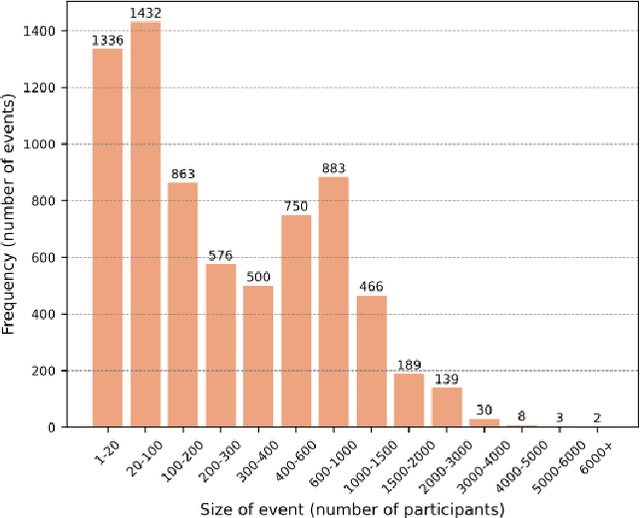
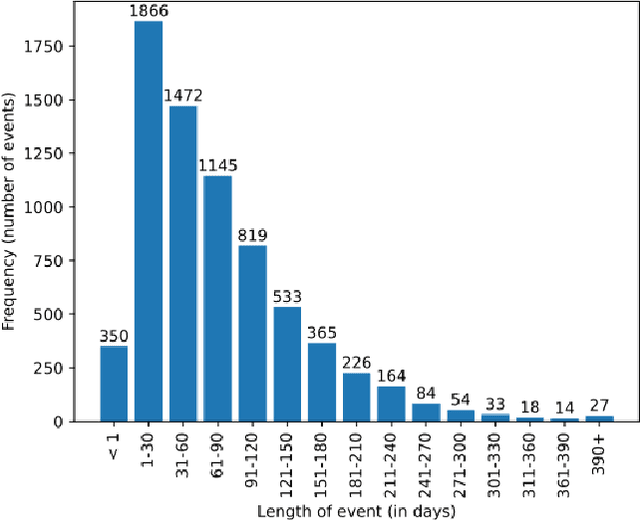
The rise in adoption of cryptoassets has brought many new and inexperienced investors in the cryptocurrency space. These investors can be disproportionally influenced by information they receive online, and particularly from social media. This paper presents a dataset of crypto-related bounty events and the users that participate in them. These events coordinate social media campaigns to create artificial "hype" around a crypto project in order to influence the price of its token. The dataset consists of information about 15.8K cross-media bounty events, 185K participants, 10M forum comments and 82M social media URLs collected from the Bounties(Altcoins) subforum of the BitcoinTalk online forum from May 2014 to December 2022. We describe the data collection and the data processing methods employed, we present a basic characterization of the dataset, and we describe potential research opportunities afforded by the dataset across many disciplines.
Deep Learning for Event-based Vision: A Comprehensive Survey and Benchmarks
Feb 17, 2023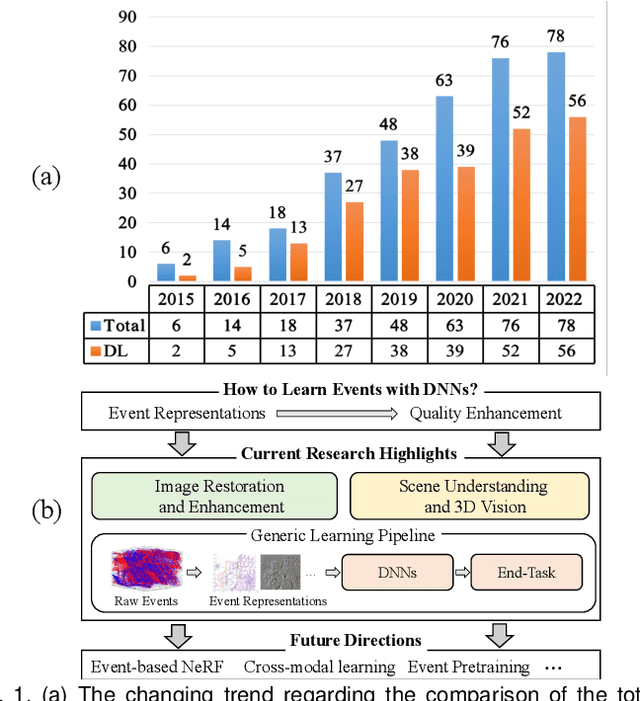
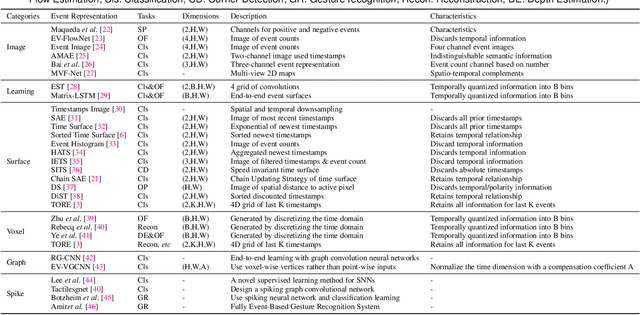

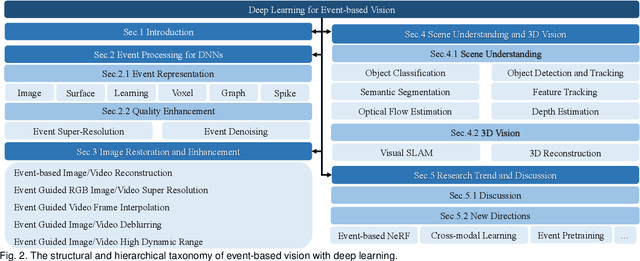
Event cameras are bio-inspired sensors that capture the per-pixel intensity changes asynchronously and produce event streams encoding the time, pixel position, and polarity (sign) of the intensity changes. Event cameras possess a myriad of advantages over canonical frame-based cameras, such as high temporal resolution, high dynamic range, low latency, etc. Being capable of capturing information in challenging visual conditions, event cameras have the potential to overcome the limitations of frame-based cameras in the computer vision and robotics community. In very recent years, deep learning (DL) has been brought to this emerging field and inspired active research endeavors in mining its potential. However, the technical advances still remain unknown, thus making it urgent and necessary to conduct a systematic overview. To this end, we conduct the first yet comprehensive and in-depth survey, with a focus on the latest developments of DL techniques for event-based vision. We first scrutinize the typical event representations with quality enhancement methods as they play a pivotal role as inputs to the DL models. We then provide a comprehensive taxonomy for existing DL-based methods by structurally grouping them into two major categories: 1) image reconstruction and restoration; 2) event-based scene understanding 3D vision. Importantly, we conduct benchmark experiments for the existing methods in some representative research directions (eg, object recognition and optical flow estimation) to identify some critical insights and problems. Finally, we make important discussions regarding the challenges and provide new perspectives for motivating future research studies.
Multiscale Graph Neural Network Autoencoders for Interpretable Scientific Machine Learning
Feb 17, 2023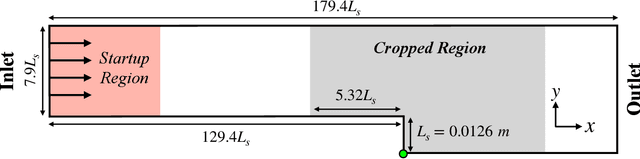
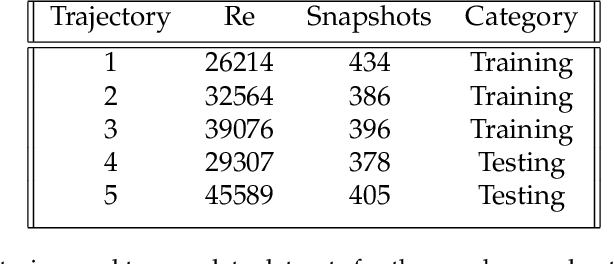
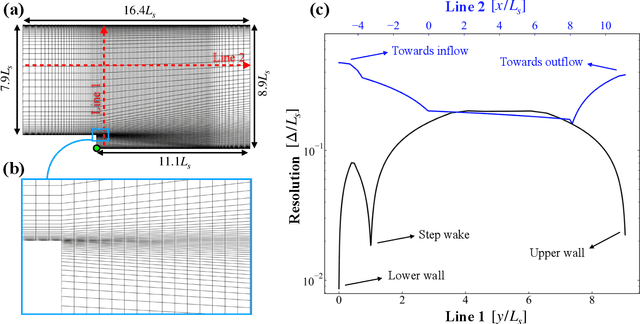
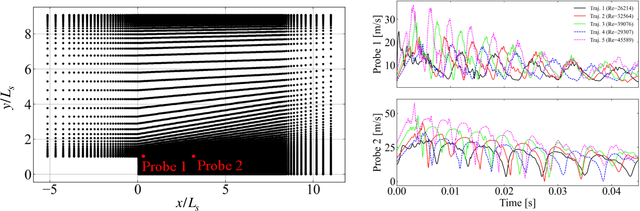
The goal of this work is to address two limitations in autoencoder-based models: latent space interpretability and compatibility with unstructured meshes. This is accomplished here with the development of a novel graph neural network (GNN) autoencoding architecture with demonstrations on complex fluid flow applications. To address the first goal of interpretability, the GNN autoencoder achieves reduction in the number nodes in the encoding stage through an adaptive graph reduction procedure. This reduction procedure essentially amounts to flowfield-conditioned node sampling and sensor identification, and produces interpretable latent graph representations tailored to the flowfield reconstruction task in the form of so-called masked fields. These masked fields allow the user to (a) visualize where in physical space a given latent graph is active, and (b) interpret the time-evolution of the latent graph connectivity in accordance with the time-evolution of unsteady flow features (e.g. recirculation zones, shear layers) in the domain. To address the goal of unstructured mesh compatibility, the autoencoding architecture utilizes a series of multi-scale message passing (MMP) layers, each of which models information exchange among node neighborhoods at various lengthscales. The MMP layer, which augments standard single-scale message passing with learnable coarsening operations, allows the decoder to more efficiently reconstruct the flowfield from the identified regions in the masked fields. Analysis of latent graphs produced by the autoencoder for various model settings are conducted using using unstructured snapshot data sourced from large-eddy simulations in a backward-facing step (BFS) flow configuration with an OpenFOAM-based flow solver at high Reynolds numbers.
Multi-Behavior Graph Neural Networks for Recommender System
Feb 17, 2023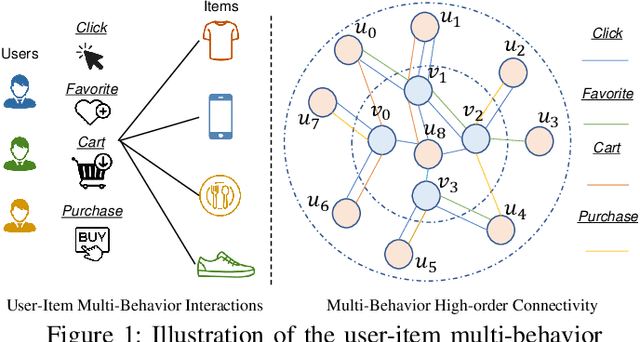
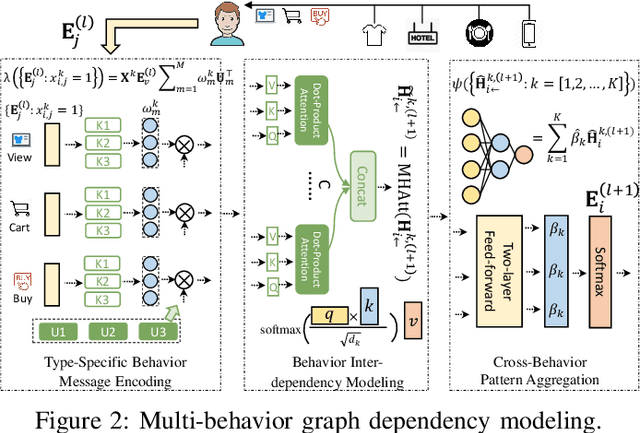
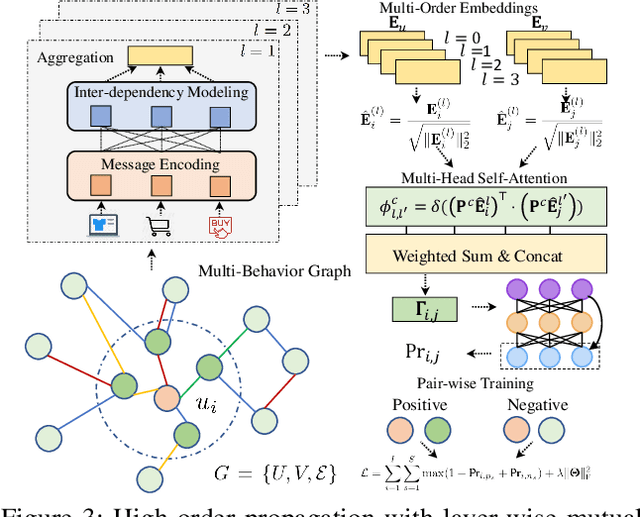
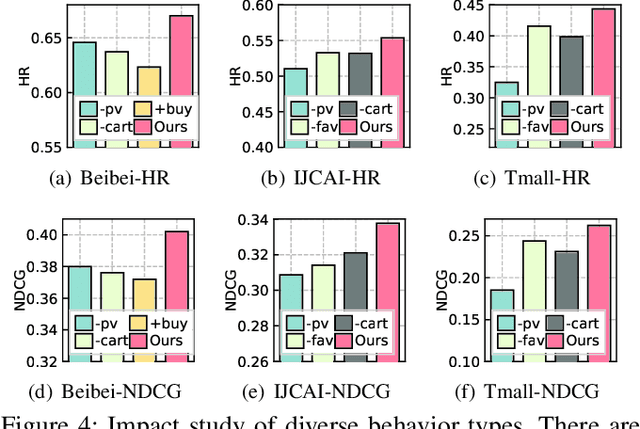
Recommender systems have been demonstrated to be effective to meet user's personalized interests for many online services (e.g., E-commerce and online advertising platforms). Recent years have witnessed the emerging success of many deep learning-based recommendation models for augmenting collaborative filtering architectures with various neural network architectures, such as multi-layer perceptron and autoencoder. However, the majority of them model the user-item relationship with single type of interaction, while overlooking the diversity of user behaviors on interacting with items, which can be click, add-to-cart, tag-as-favorite and purchase. Such various types of interaction behaviors have great potential in providing rich information for understanding the user preferences. In this paper, we pay special attention on user-item relationships with the exploration of multi-typed user behaviors. Technically, we contribute a new multi-behavior graph neural network (MBRec), which specially accounts for diverse interaction patterns as well as the underlying cross-type behavior inter-dependencies. In the MBRec framework, we develop a graph-structured learning framework to perform expressive modeling of high-order connectivity in behavior-aware user-item interaction graph. After that, a mutual relation encoder is proposed to adaptively uncover complex relational structures and make aggregations across layer-specific behavior representations. Through comprehensive evaluation on real-world datasets, the advantages of our MBRec method have been validated under different experimental settings. Further analysis verifies the positive effects of incorporating the multi-behavioral context into the recommendation paradigm. Additionally, the conducted case studies offer insights into the interpretability of user multi-behavior representations.
Algorithmic Hallucinations of Near-Surface Winds: Statistical Downscaling with Generative Adversarial Networks to Convection-Permitting Scales
Feb 17, 2023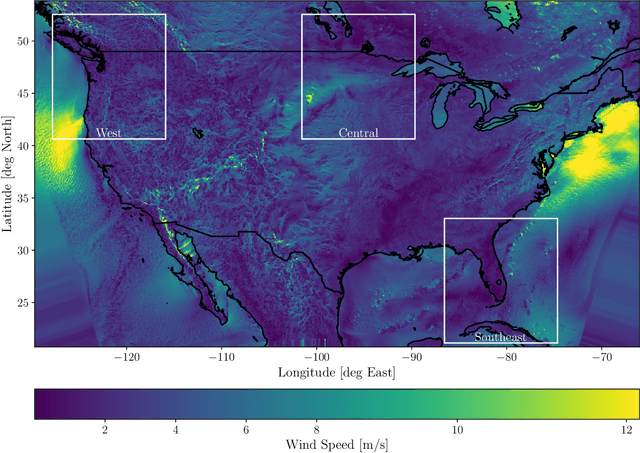

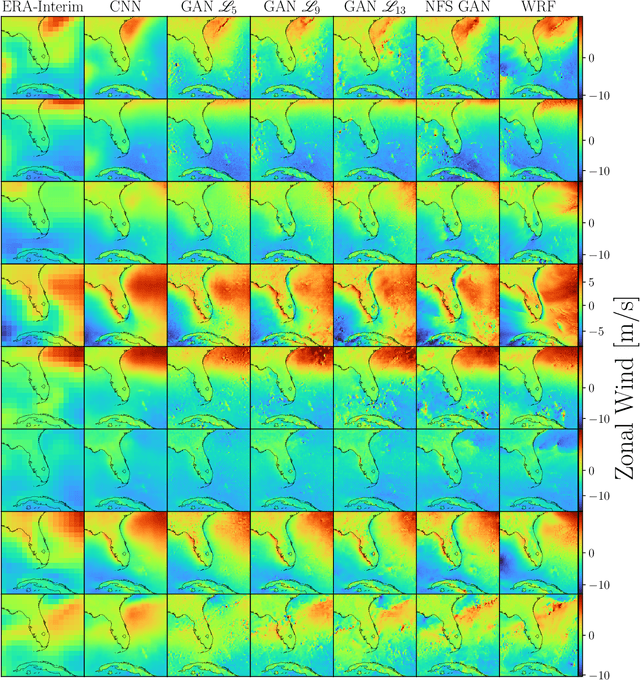
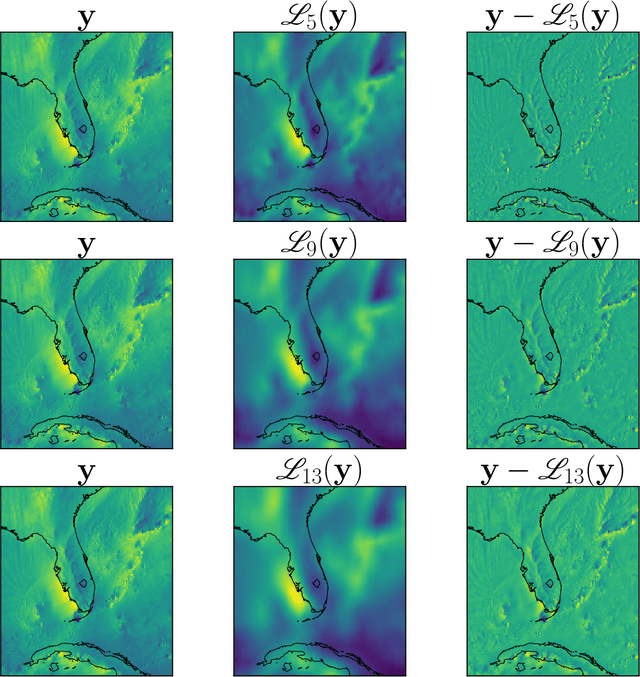
Providing small-scale information about weather and climate is challenging, especially for variables strongly controlled by processes that are unresolved by low-resolution (LR) models. This paper explores emerging machine learning methods from the fields of image super-resolution (SR) and deep learning for statistical downscaling of near-surface winds to convection-permitting scales. Specifically, Generative Adversarial Networks (GANs) are conditioned on LR inputs from a global reanalysis to generate high-resolution (HR) surface winds that emulate those simulated over North America by the Weather Research and Forecasting (WRF) model. Unlike traditional SR models, where LR inputs are idealized coarsened versions of the HR images, WRF emulation involves non-idealized LR inputs from a coarse-resolution reanalysis. In addition to matching the statistical properties of WRF simulations, GANs quickly generate HR fields with impressive realism. However, objectively assessing the realism of the SR models requires careful selection of evaluation metrics. In particular, performance measures based on spatial power spectra reveal the way that GAN configurations change spatial structures in the generated fields, where biases in spatial variability originate, and how models depend on different LR covariates. Inspired by recent computer vision research, a novel methodology that separates spatial frequencies in HR fields is used in an attempt to optimize the SR GANs further. This method, called frequency separation, resulted in deterioration in realism of the generated HR fields. However, frequency separation did show how spatial structures are influenced by the metrics used to optimize the SR models, which led to the development of a more effective partial frequency separation approach.
On Leave-One-Out Conditional Mutual Information For Generalization
Jul 01, 2022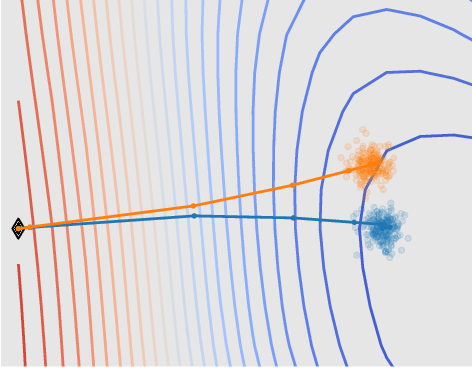

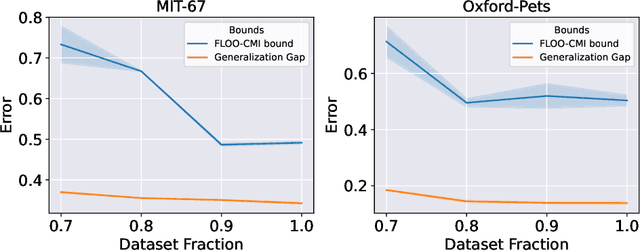
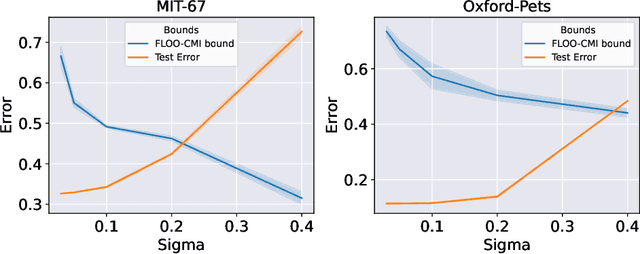
We derive information theoretic generalization bounds for supervised learning algorithms based on a new measure of leave-one-out conditional mutual information (loo-CMI). Contrary to other CMI bounds, which are black-box bounds that do not exploit the structure of the problem and may be hard to evaluate in practice, our loo-CMI bounds can be computed easily and can be interpreted in connection to other notions such as classical leave-one-out cross-validation, stability of the optimization algorithm, and the geometry of the loss-landscape. It applies both to the output of training algorithms as well as their predictions. We empirically validate the quality of the bound by evaluating its predicted generalization gap in scenarios for deep learning. In particular, our bounds are non-vacuous on large-scale image-classification tasks.
Randomized prior wavelet neural operator for uncertainty quantification
Feb 02, 2023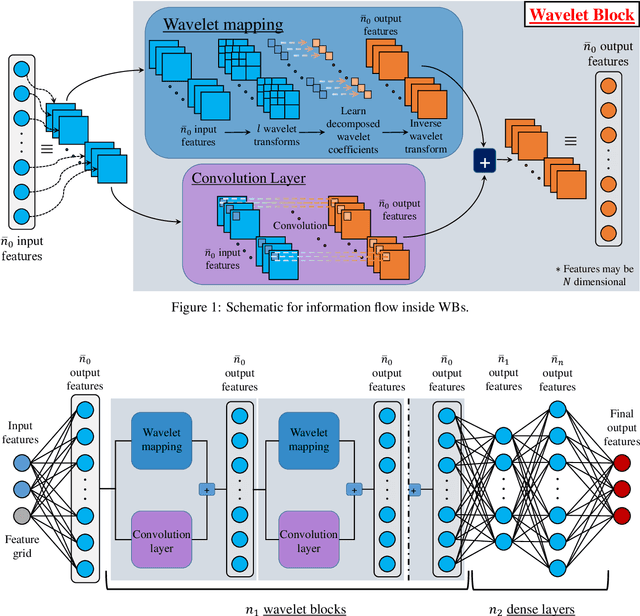


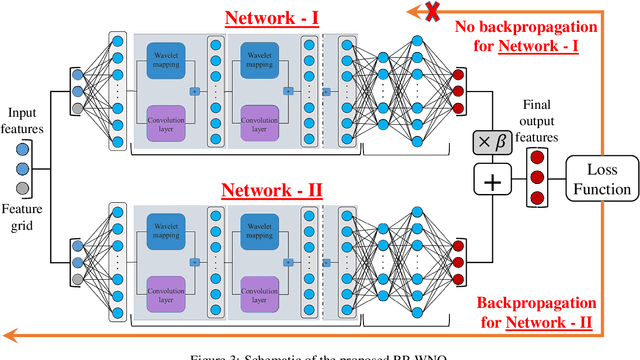
In this paper, we propose a novel data-driven operator learning framework referred to as the \textit{Randomized Prior Wavelet Neural Operator} (RP-WNO). The proposed RP-WNO is an extension of the recently proposed wavelet neural operator, which boasts excellent generalizing capabilities but cannot estimate the uncertainty associated with its predictions. RP-WNO, unlike the vanilla WNO, comes with inherent uncertainty quantification module and hence, is expected to be extremely useful for scientists and engineers alike. RP-WNO utilizes randomized prior networks, which can account for prior information and is easier to implement for large, complex deep-learning architectures than its Bayesian counterpart. Four examples have been solved to test the proposed framework, and the results produced advocate favorably for the efficacy of the proposed framework.
CARD: Semantic Segmentation with Efficient Class-Aware Regularized Decoder
Jan 11, 2023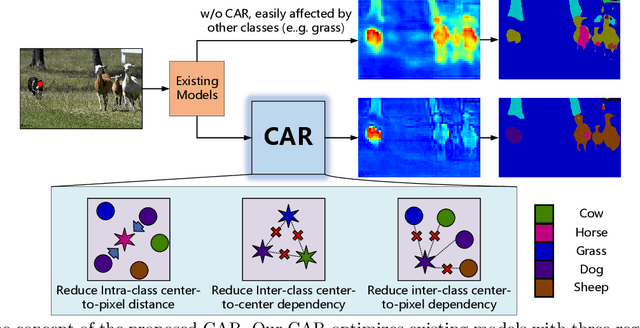

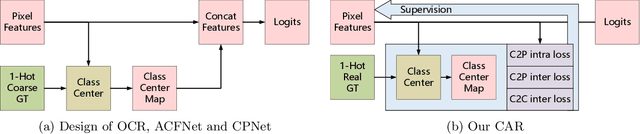
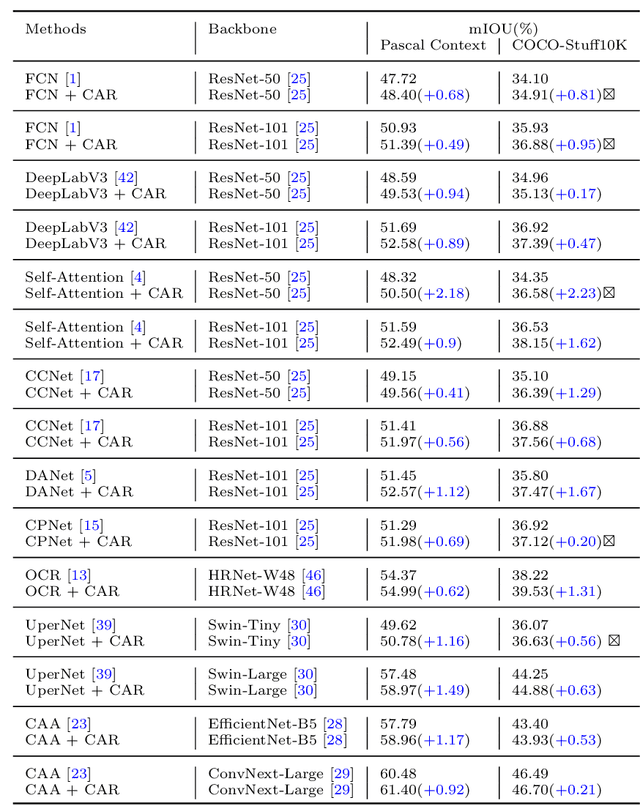
Semantic segmentation has recently achieved notable advances by exploiting "class-level" contextual information during learning. However, these approaches simply concatenate class-level information to pixel features to boost the pixel representation learning, which cannot fully utilize intra-class and inter-class contextual information. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. To better exploit class level information, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Moreover, we design a dedicated decoder for CAR (CARD), which consists of a novel spatial token mixer and an upsampling module, to maximize its gain for existing baselines while being highly efficient in terms of computational cost. Specifically, CAR consists of three novel loss functions. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. CAR can be directly applied to most existing segmentation models during training, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. CARD outperforms SOTA approaches on multiple benchmarks with a highly efficient architecture.
DiffFashion: Reference-based Fashion Design with Structure-aware Transfer by Diffusion Models
Feb 14, 2023
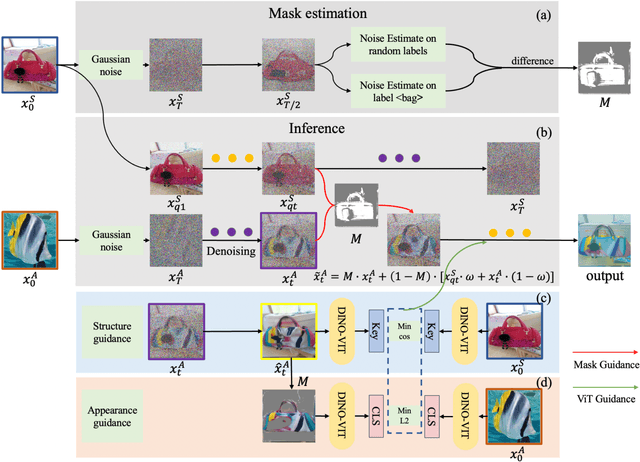


Image-based fashion design with AI techniques has attracted increasing attention in recent years. We focus on a new fashion design task, where we aim to transfer a reference appearance image onto a clothing image while preserving the structure of the clothing image. It is a challenging task since there are no reference images available for the newly designed output fashion images. Although diffusion-based image translation or neural style transfer (NST) has enabled flexible style transfer, it is often difficult to maintain the original structure of the image realistically during the reverse diffusion, especially when the referenced appearance image greatly differs from the common clothing appearance. To tackle this issue, we present a novel diffusion model-based unsupervised structure-aware transfer method to semantically generate new clothes from a given clothing image and a reference appearance image. In specific, we decouple the foreground clothing with automatically generated semantic masks by conditioned labels. And the mask is further used as guidance in the denoising process to preserve the structure information. Moreover, we use the pre-trained vision Transformer (ViT) for both appearance and structure guidance. Our experimental results show that the proposed method outperforms state-of-the-art baseline models, generating more realistic images in the fashion design task. Code and demo can be found at https://github.com/Rem105-210/DiffFashion.
Isotopic envelope identification by analysis of the spatial distribution of components in MALDI-MSI data
Feb 14, 2023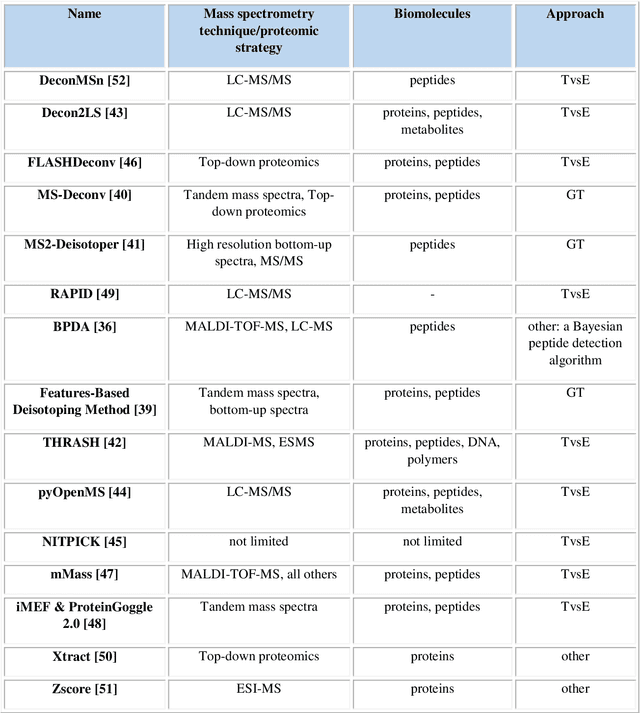
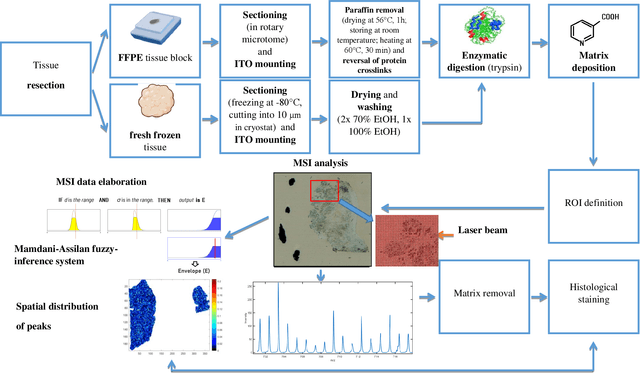
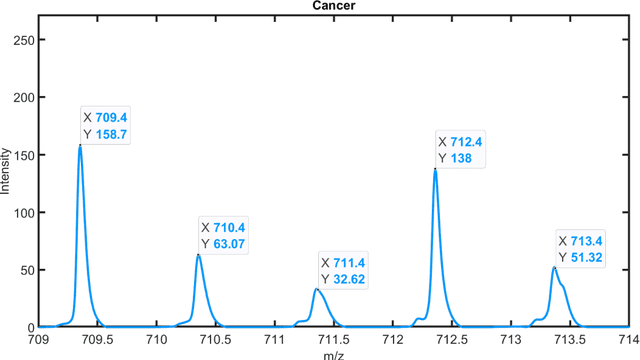
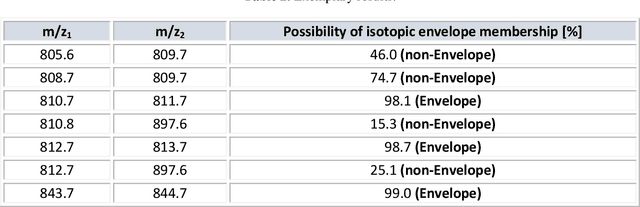
One of the significant steps in the process leading to the identification of proteins is mass spectrometry, which allows for obtaining information about the structure of proteins. Removing isotope peaks from the mass spectrum is vital and it is done in a process called deisotoping. There are different algorithms for deisotoping, but they have their limitations, they are dedicated to different methods of mass spectrometry. Data from experiments performed with the MALDI-ToF technique are characterized by high dimensionality. This paper presents a method for identifying isotope envelopes in MALDI-ToF molecular imaging data based on the Mamdani-Assilan fuzzy system and spatial maps of the molecular distribution of peaks included in the isotopic envelope. Several image texture measures were used to evaluate spatial molecular distribution maps. The algorithm was tested on eight datasets obtained from the MALDI-ToF experiment on samples from the National Institute of Oncology in Gliwice from patients with cancer of the head and neck region. The data were subjected to pre-processing and feature extraction. The results were collected and compared with three existing deisotoping algorithms. The analysis of the obtained results showed that the method for identifying isotopic envelopes proposed in this paper enables the detection of overlapping envelopes by using the approach oriented to study peak pairs. Moreover, the proposed algorithm enables the analysis of large data sets.