 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperspectral Image Super-Resolution via Dual-domain Network Based on Hybrid Convolution
Apr 11, 2023
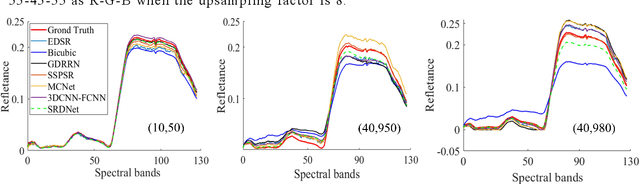
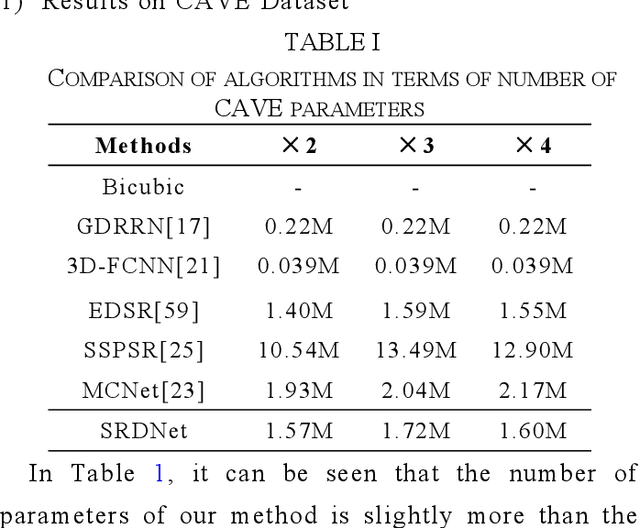
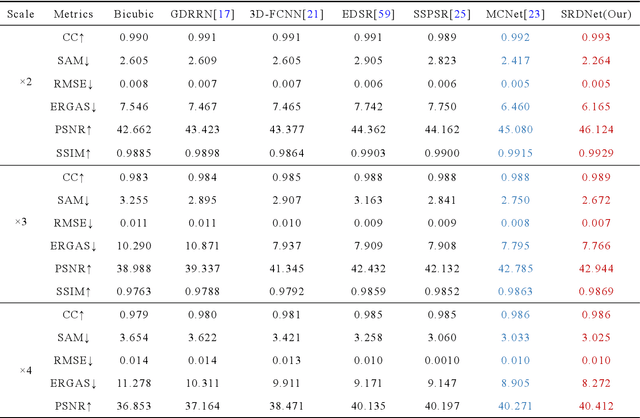
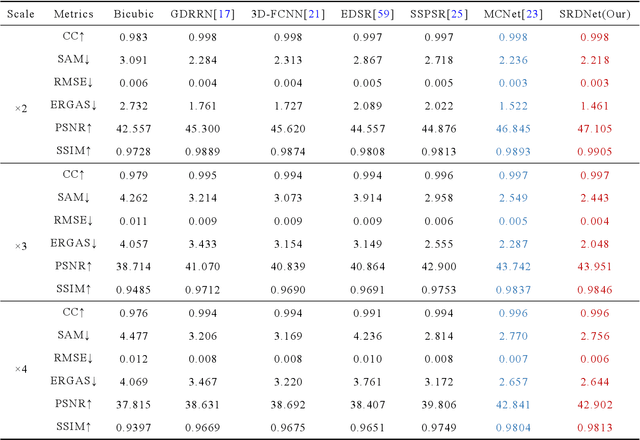
Since the number of incident energies is limited, it is difficult to directly acquire hyperspectral images (HSI) with high spatial resolution. Considering the high dimensionality and correlation of HSI, super-resolution (SR) of HSI remains a challenge in the absence of auxiliary high-resolution images. Furthermore, it is very important to extract the spatial features effectively and make full use of the spectral information. This paper proposes a novel HSI super-resolution algorithm, termed dual-domain network based on hybrid convolution (SRDNet). Specifically, a dual-domain network is designed to fully exploit the spatial-spectral and frequency information among the hyper-spectral data. To capture inter-spectral self-similarity, a self-attention learning mechanism (HSL) is devised in the spatial domain. Meanwhile the pyramid structure is applied to increase the acceptance field of attention, which further reinforces the feature representation ability of the network. Moreover, to further improve the perceptual quality of HSI, a frequency loss(HFL) is introduced to optimize the model in the frequency domain. The dynamic weighting mechanism drives the network to gradually refine the generated frequency and excessive smoothing caused by spatial loss. Finally, In order to better fully obtain the mapping relationship between high-resolution space and low-resolution space, a hybrid module of 2D and 3D units with progressive upsampling strategy is utilized in our method. Experiments on a widely used benchmark dataset illustrate that the proposed SRDNet method enhances the texture information of HSI and is superior to state-of-the-art methods.
ChatGPT cites the most-cited articles and journals, relying solely on Google Scholar's citation counts. As a result, AI may amplify the Matthew Effect in environmental science
Apr 13, 2023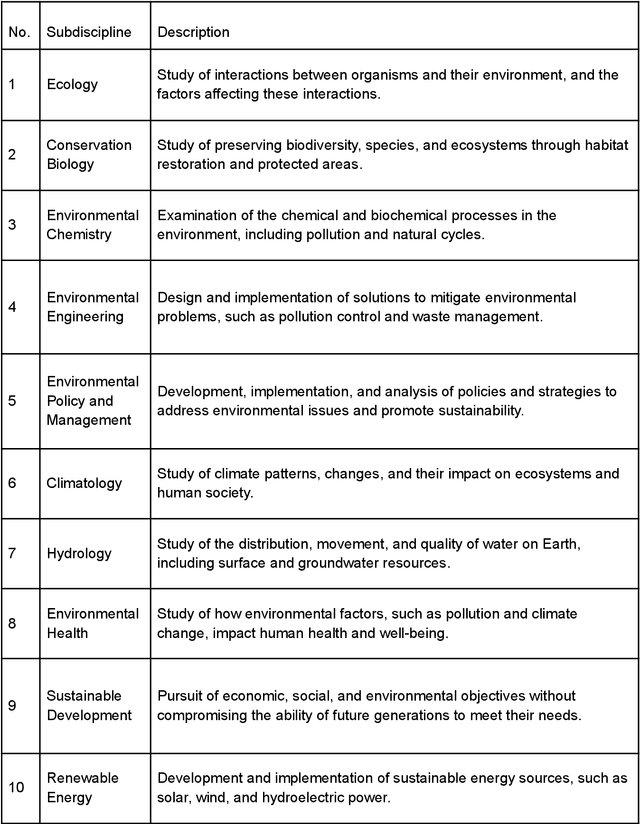
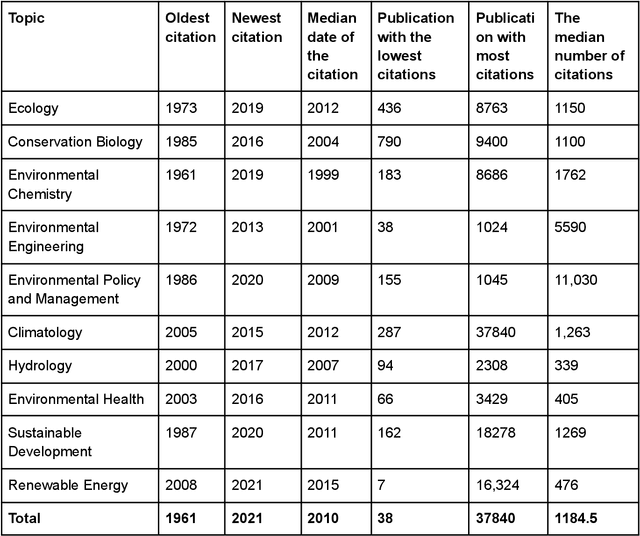
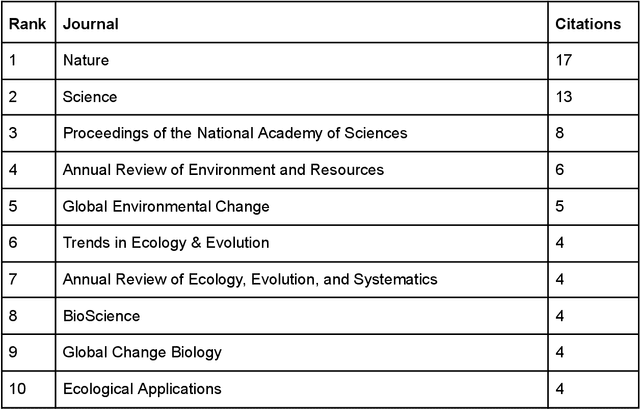
ChatGPT (GPT) has become one of the most talked-about innovations in recent years, with over 100 million users worldwide. However, there is still limited knowledge about the sources of information GPT utilizes. As a result, we carried out a study focusing on the sources of information within the field of environmental science. In our study, we asked GPT to identify the ten most significant subdisciplines within the field of environmental science. We then asked it to compose a scientific review article on each subdiscipline, including 25 references. We proceeded to analyze these references, focusing on factors such as the number of citations, publication date, and the journal in which the work was published. Our findings indicate that GPT tends to cite highly-cited publications in environmental science, with a median citation count of 1184.5. It also exhibits a preference for older publications, with a median publication year of 2010, and predominantly refers to well-respected journals in the field, with Nature being the most cited journal by GPT. Interestingly, our findings suggest that GPT seems to exclusively rely on citation count data from Google Scholar for the works it cites, rather than utilizing citation information from other scientific databases such as Web of Science or Scopus. In conclusion, our study suggests that Google Scholar citations play a significant role as a predictor for mentioning a study in GPT-generated content. This finding reinforces the dominance of Google Scholar among scientific databases and perpetuates the Matthew Effect in science, where the rich get richer in terms of citations. With many scholars already utilizing GPT for literature review purposes, we can anticipate further disparities and an expanding gap between lesser-cited and highly-cited publications.
Improving Few-Shot Prompts with Relevant Static Analysis Products
Apr 13, 2023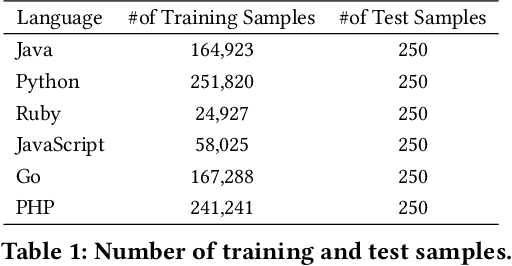
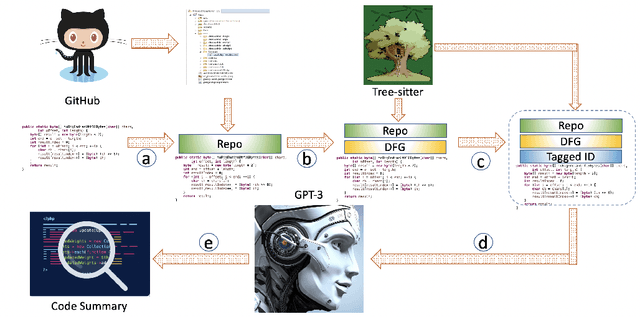

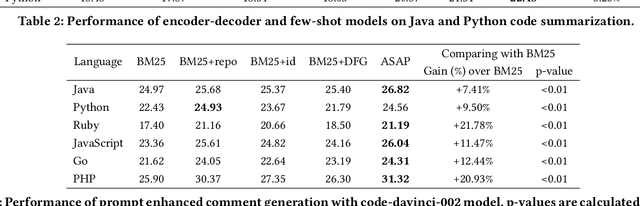
Large Language Models (LLM) are a new class of computation engines, "programmed" via prompt engineering. We are still learning how to best "program" these LLMs to help developers. We start with the intuition that developers tend to consciously and unconsciously have a collection of semantics facts in mind when working on coding tasks. Mostly these are shallow, simple facts arising from a quick read. For a function, examples of facts might include parameter and local variable names, return expressions, simple pre- and post-conditions, and basic control and data flow, etc. One might assume that the powerful multi-layer architecture of transformer-style LLMs makes them inherently capable of doing this simple level of "code analysis" and extracting such information, implicitly, while processing code: but are they, really? If they aren't, could explicitly adding this information help? Our goal here is to investigate this question, using the code summarization task and evaluate whether automatically augmenting an LLM's prompt with semantic facts explicitly, actually helps. Prior work shows that LLM performance on code summarization benefits from few-shot samples drawn either from the same-project or from examples found via information retrieval methods (such as BM25). While summarization performance has steadily increased since the early days, there is still room for improvement: LLM performance on code summarization still lags its performance on natural-language tasks like translation and text summarization. We find that adding semantic facts actually does help! This approach improves performance in several different settings suggested by prior work, including for two different Large Language Models. In most cases, improvement nears or exceeds 2 BLEU; for the PHP language in the challenging CodeSearchNet dataset, this augmentation actually yields performance surpassing 30 BLEU.
Do SSL Models Have Déjà Vu? A Case of Unintended Memorization in Self-supervised Learning
Apr 28, 2023
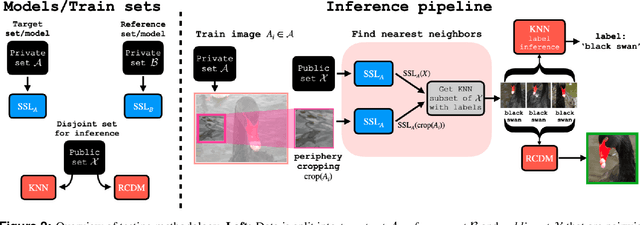
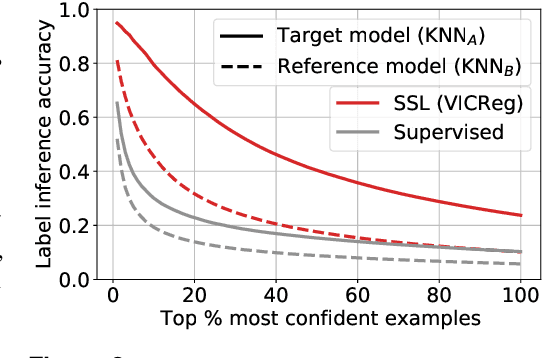
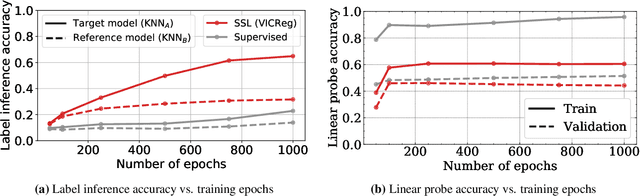
Self-supervised learning (SSL) algorithms can produce useful image representations by learning to associate different parts of natural images with one another. However, when taken to the extreme, SSL models can unintendedly memorize specific parts in individual training samples rather than learning semantically meaningful associations. In this work, we perform a systematic study of the unintended memorization of image-specific information in SSL models -- which we refer to as d\'ej\`a vu memorization. Concretely, we show that given the trained model and a crop of a training image containing only the background (e.g., water, sky, grass), it is possible to infer the foreground object with high accuracy or even visually reconstruct it. Furthermore, we show that d\'ej\`a vu memorization is common to different SSL algorithms, is exacerbated by certain design choices, and cannot be detected by conventional techniques for evaluating representation quality. Our study of d\'ej\`a vu memorization reveals previously unknown privacy risks in SSL models, as well as suggests potential practical mitigation strategies. Code is available at https://github.com/facebookresearch/DejaVu.
NeRF-LiDAR: Generating Realistic LiDAR Point Clouds with Neural Radiance Fields
Apr 28, 2023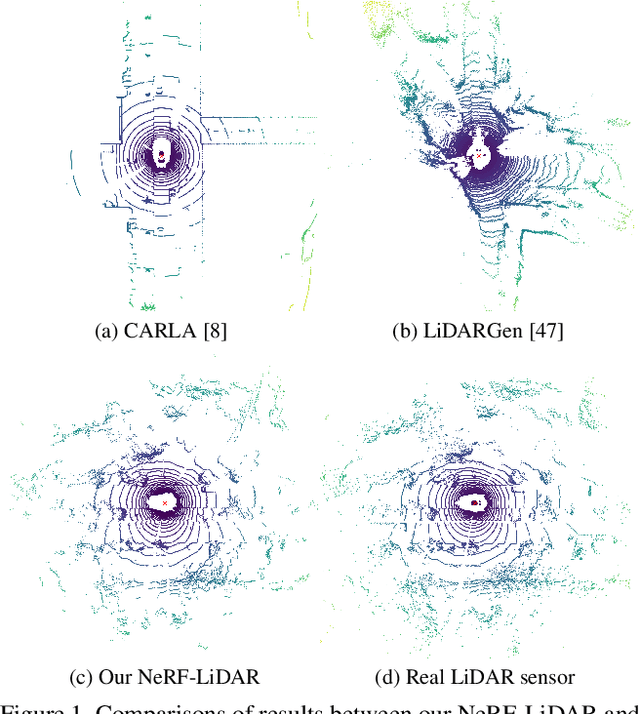
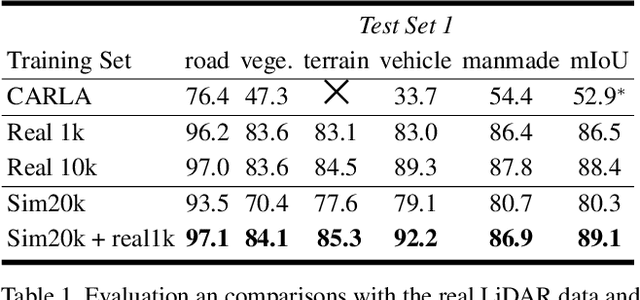
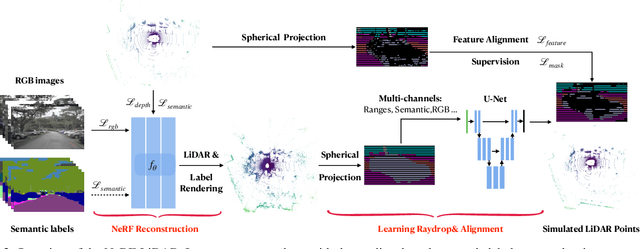
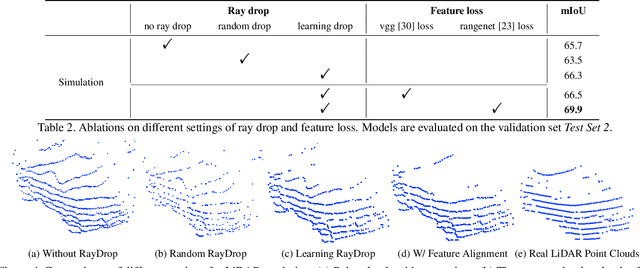
Labeling LiDAR point clouds for training autonomous driving is extremely expensive and difficult. LiDAR simulation aims at generating realistic LiDAR data with labels for training and verifying self-driving algorithms more efficiently. Recently, Neural Radiance Fields (NeRF) have been proposed for novel view synthesis using implicit reconstruction of 3D scenes. Inspired by this, we present NeRF-LIDAR, a novel LiDAR simulation method that leverages real-world information to generate realistic LIDAR point clouds. Different from existing LiDAR simulators, we use real images and point cloud data collected by self-driving cars to learn the 3D scene representation, point cloud generation and label rendering. We verify the effectiveness of our NeRF-LiDAR by training different 3D segmentation models on the generated LiDAR point clouds. It reveals that the trained models are able to achieve similar accuracy when compared with the same model trained on the real LiDAR data. Besides, the generated data is capable of boosting the accuracy through pre-training which helps reduce the requirements of the real labeled data.
Improving Knowledge Graph Entity Alignment with Graph Augmentation
Apr 28, 2023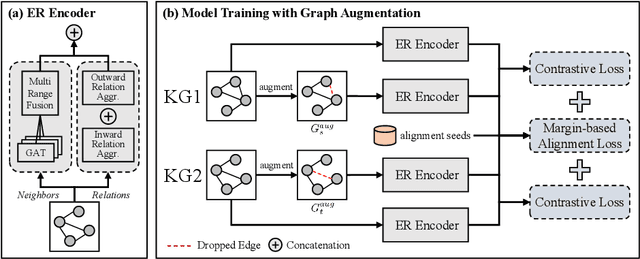
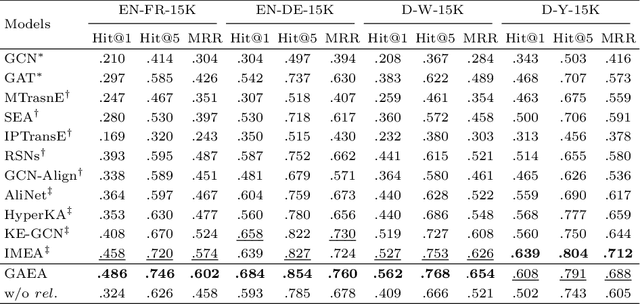
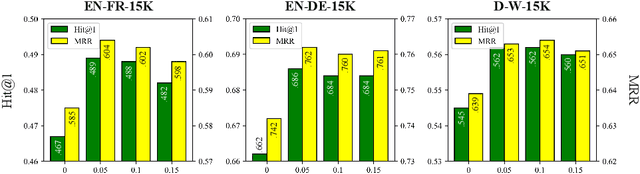

Entity alignment (EA) which links equivalent entities across different knowledge graphs (KGs) plays a crucial role in knowledge fusion. In recent years, graph neural networks (GNNs) have been successfully applied in many embedding-based EA methods. However, existing GNN-based methods either suffer from the structural heterogeneity issue that especially appears in the real KG distributions or ignore the heterogeneous representation learning for unseen (unlabeled) entities, which would lead the model to overfit on few alignment seeds (i.e., training data) and thus cause unsatisfactory alignment performance. To enhance the EA ability, we propose GAEA, a novel EA approach based on graph augmentation. In this model, we design a simple Entity-Relation (ER) Encoder to generate latent representations for entities via jointly modeling comprehensive structural information and rich relation semantics. Moreover, we use graph augmentation to create two graph views for margin-based alignment learning and contrastive entity representation learning, thus mitigating structural heterogeneity and further improving the model's alignment performance. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of our method.
Information-Theoretic Text Hallucination Reduction for Video-grounded Dialogue
Dec 12, 2022
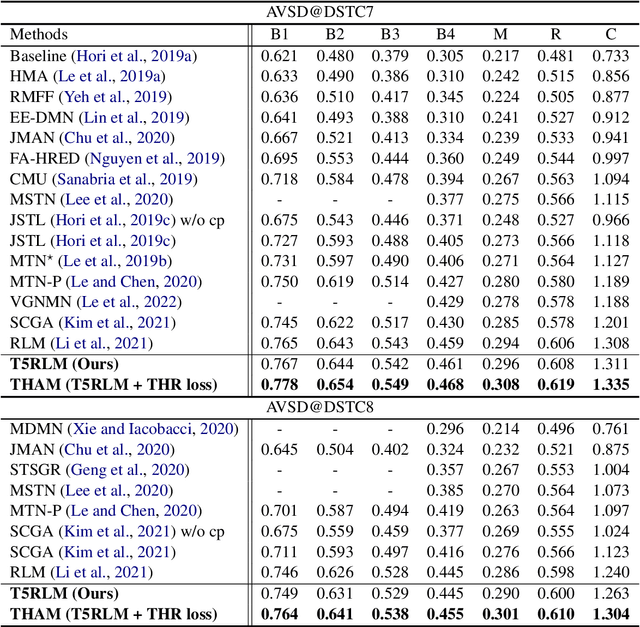
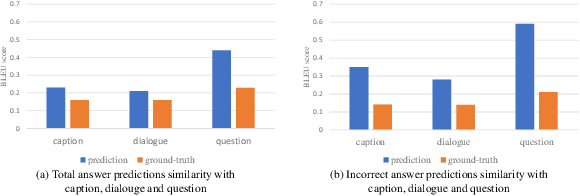
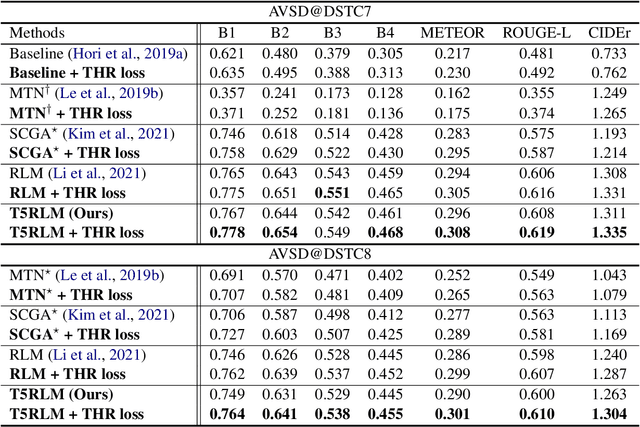
Video-grounded Dialogue (VGD) aims to decode an answer sentence to a question regarding a given video and dialogue context. Despite the recent success of multi-modal reasoning to generate answer sentences, existing dialogue systems still suffer from a text hallucination problem, which denotes indiscriminate text-copying from input texts without an understanding of the question. This is due to learning spurious correlations from the fact that answer sentences in the dataset usually include the words of input texts, thus the VGD system excessively relies on copying words from input texts by hoping those words to overlap with ground-truth texts. Hence, we design Text Hallucination Mitigating (THAM) framework, which incorporates Text Hallucination Regularization (THR) loss derived from the proposed information-theoretic text hallucination measurement approach. Applying THAM with current dialogue systems validates the effectiveness on VGD benchmarks (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows enhanced interpretability.
Integrated Sensing and Communication in Coordinated Cellular Networks
May 02, 2023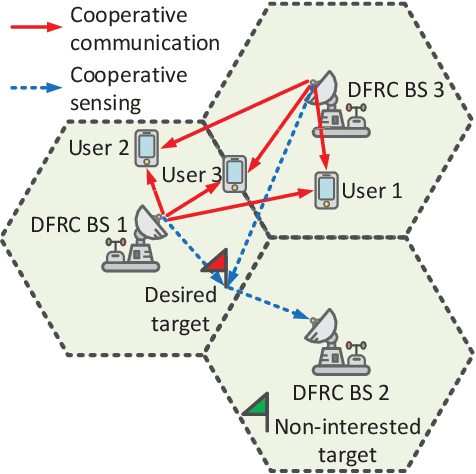
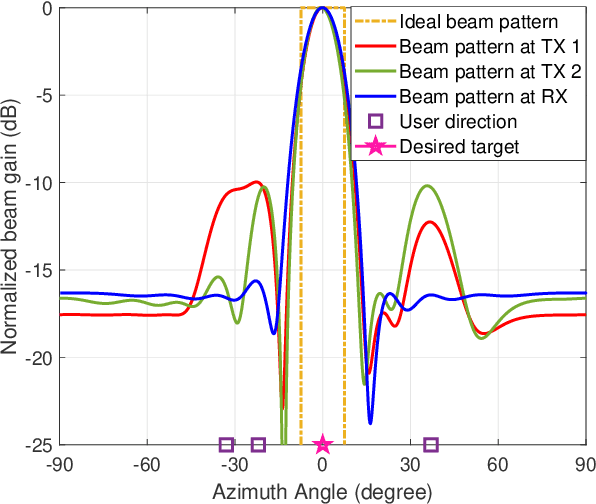
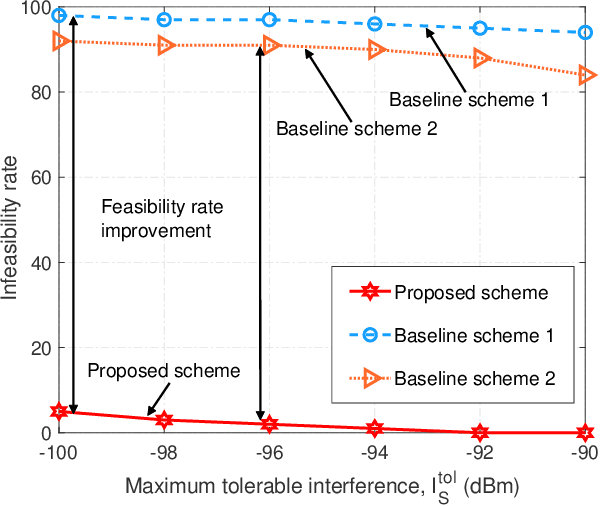
Integrated sensing and communication (ISAC) has recently merged as a promising technique to provide sensing services in future wireless networks. In the literature, numerous works have adopted a monostatic radar architecture to realize ISAC, i.e., employing the same base station (BS) to transmit the ISAC signal and receive the echo. Yet, the concurrent information transmission causes severe self-interference (SI) to the radar echo at the BS which cannot be effectively suppressed. To overcome this difficulty, in this paper, we propose a coordinated cellular network-supported multistatic radar architecture to implement ISAC. In particular, among all the coordinated BSs, we select a BS as the multistatic receiver to receive the sensing echo signal, while the other BSs act as the multistatic transmitters to collaborate with each other to facilitate cooperative ISAC. This allows us to spatially separate the ISAC signal transmission and radar echo reception, intrinsically circumventing the problem of SI. To this end, we jointly optimize the transmit and receive beamforming policy to minimize the sensing beam pattern mismatch error subject to both the communication and sensing quality-of-service requirements. The resulting non-convex optimization problem is tackled by a low-complexity alternating optimization-based suboptimal algorithm. Simulation results showed that the proposed scheme outperforms the two baseline schemes adopting conventional designs. Moreover, our results confirm that the proposed architecture is promising in achieving high-quality ISAC.
Stochastic Contextual Bandits with Graph-based Contexts
May 02, 2023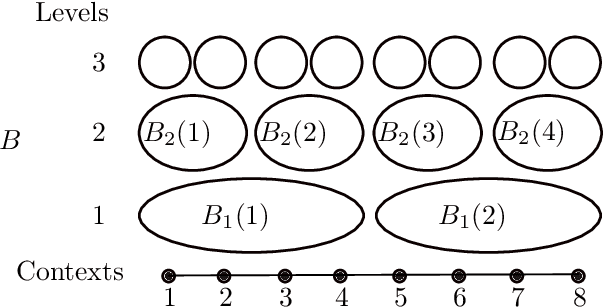
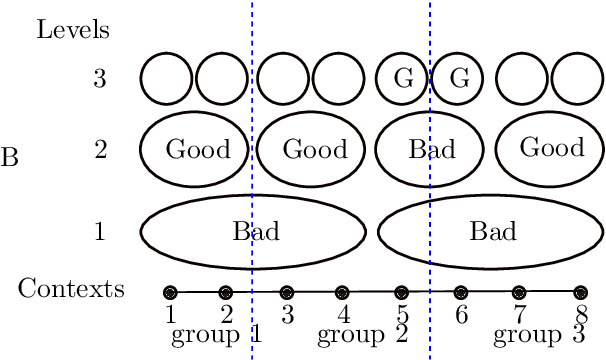
We naturally generalize the on-line graph prediction problem to a version of stochastic contextual bandit problems where contexts are vertices in a graph and the structure of the graph provides information on the similarity of contexts. More specifically, we are given a graph $G=(V,E)$, whose vertex set $V$ represents contexts with {\em unknown} vertex label $y$. In our stochastic contextual bandit setting, vertices with the same label share the same reward distribution. The standard notion of instance difficulties in graph label prediction is the cutsize $f$ defined to be the number of edges whose end points having different labels. For line graphs and trees we present an algorithm with regret bound of $\tilde{O}(T^{2/3}K^{1/3}f^{1/3})$ where $K$ is the number of arms. Our algorithm relies on the optimal stochastic bandit algorithm by Zimmert and Seldin~[AISTAT'19, JMLR'21]. When the best arm outperforms the other arms, the regret improves to $\tilde{O}(\sqrt{KT\cdot f})$. The regret bound in the later case is comparable to other optimal contextual bandit results in more general cases, but our algorithm is easy to analyze, runs very efficiently, and does not require an i.i.d. assumption on the input context sequence. The algorithm also works with general graphs using a standard random spanning tree reduction.
A Unified HDR Imaging Method with Pixel and Patch Level
Apr 17, 2023
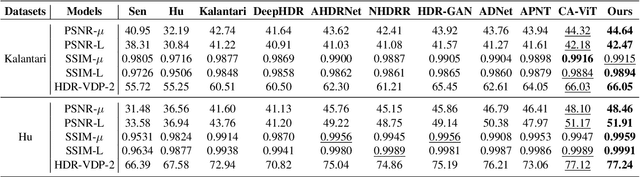
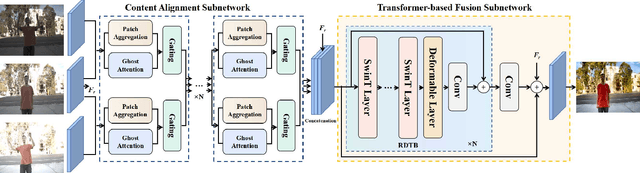
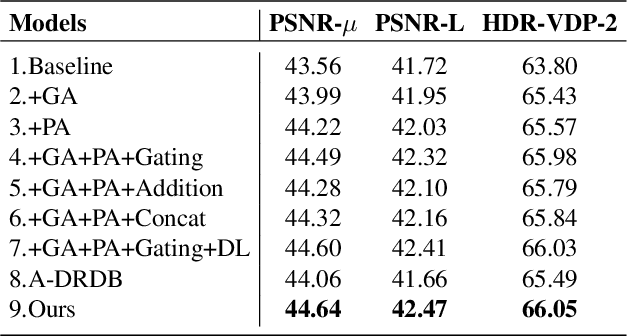
Mapping Low Dynamic Range (LDR) images with different exposures to High Dynamic Range (HDR) remains nontrivial and challenging on dynamic scenes due to ghosting caused by object motion or camera jitting. With the success of Deep Neural Networks (DNNs), several DNNs-based methods have been proposed to alleviate ghosting, they cannot generate approving results when motion and saturation occur. To generate visually pleasing HDR images in various cases, we propose a hybrid HDR deghosting network, called HyHDRNet, to learn the complicated relationship between reference and non-reference images. The proposed HyHDRNet consists of a content alignment subnetwork and a Transformer-based fusion subnetwork. Specifically, to effectively avoid ghosting from the source, the content alignment subnetwork uses patch aggregation and ghost attention to integrate similar content from other non-reference images with patch level and suppress undesired components with pixel level. To achieve mutual guidance between patch-level and pixel-level, we leverage a gating module to sufficiently swap useful information both in ghosted and saturated regions. Furthermore, to obtain a high-quality HDR image, the Transformer-based fusion subnetwork uses a Residual Deformable Transformer Block (RDTB) to adaptively merge information for different exposed regions. We examined the proposed method on four widely used public HDR image deghosting datasets. Experiments demonstrate that HyHDRNet outperforms state-of-the-art methods both quantitatively and qualitatively, achieving appealing HDR visualization with unified textures and colors.