 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoOtter: Evolutionary Reproduction Test Generator
Jul 03, 2026Before fixing an issue, it is useful to first reproduce it by generating a bug reproduction test (BRT). However, generating a BRT is itself a challenging task, because issue descriptions tend to be informal, making it difficult to determine whether a candidate BRT indeed fails for the reason in the issue. Prior work has attempted to tackle this problem via inference scaling, using large language models to generate many BRTs and patches, then using execution feedback to select and improve them. Unfortunately, this is expensive and the feedback is unreliable. This paper explores evolutionary programming for BRT generation to sharpen the feedback, while enhancing evolutionary programming to keep costs in check. Our new approach, EvoOtter, controls test execution costs via successive halving. Furthermore, it controls LLM costs via batched crossover for an entire generation in a single LLM call, as well as via rule-based code mutations, with a new fitness score tailored for BRTs. As a result, EvoOtter generates state-of-the-art quality BRTs at the fraction of the cost of prior inference-scaling approaches to this problem. More broadly, this paper points at how to efficiently and effectively combine evolutionary programming with large language models for software engineering.
Otter: Generating Tests from Issues to Validate SWE Patches
Feb 07, 2025While there has been plenty of work on generating tests from existing code, there has been limited work on generating tests from issues. A correct test must validate the code patch that resolves the issue. In this work, we focus on the scenario where the code patch does not exist yet. This approach supports two major use-cases. First, it supports TDD (test-driven development), the discipline of "test first, write code later" that has well-documented benefits for human software engineers. Second, it also validates SWE (software engineering) agents, which generate code patches for resolving issues. This paper introduces Otter, an LLM-based solution for generating tests from issues. Otter augments LLMs with rule-based analysis to check and repair their outputs, and introduces a novel self-reflective action planning stage. Experiments show Otter outperforming state-of-the-art systems for generating tests from issues, in addition to enhancing systems that generate patches from issues. We hope that Otter helps make developers more productive at resolving issues and leads to more robust, well-tested code.
TDD-Bench Verified: Can LLMs Generate Tests for Issues Before They Get Resolved?
Dec 03, 2024



Test-driven development (TDD) is the practice of writing tests first and coding later, and the proponents of TDD expound its numerous benefits. For instance, given an issue on a source code repository, tests can clarify the desired behavior among stake-holders before anyone writes code for the agreed-upon fix. Although there has been a lot of work on automated test generation for the practice "write code first, test later", there has been little such automation for TDD. Ideally, tests for TDD should be fail-to-pass (i.e., fail before the issue is resolved and pass after) and have good adequacy with respect to covering the code changed during issue resolution. This paper introduces TDD-Bench Verified, a high-quality benchmark suite of 449 issues mined from real-world GitHub code repositories. The benchmark's evaluation harness runs only relevant tests in isolation for simple yet accurate coverage measurements, and the benchmark's dataset is filtered both by human judges and by execution in the harness. This paper also presents Auto-TDD, an LLM-based solution that takes as input an issue description and a codebase (prior to issue resolution) and returns as output a test that can be used to validate the changes made for resolving the issue. Our evaluation shows that Auto-TDD yields a better fail-to-pass rate than the strongest prior work while also yielding high coverage adequacy. Overall, we hope that this work helps make developers more productive at resolving issues while simultaneously leading to more robust fixes.
Prompting and Fine-tuning Large Language Models for Automated Code Review Comment Generation
Nov 15, 2024



Generating accurate code review comments remains a significant challenge due to the inherently diverse and non-unique nature of the task output. Large language models pretrained on both programming and natural language data tend to perform well in code-oriented tasks. However, large-scale pretraining is not always feasible due to its environmental impact and project-specific generalizability issues. In this work, first we fine-tune open-source Large language models (LLM) in parameter-efficient, quantized low-rank (QLoRA) fashion on consumer-grade hardware to improve review comment generation. Recent studies demonstrate the efficacy of augmenting semantic metadata information into prompts to boost performance in other code-related tasks. To explore this in code review activities, we also prompt proprietary, closed-source LLMs augmenting the input code patch with function call graphs and code summaries. Both of our strategies improve the review comment generation performance, with function call graph augmented few-shot prompting on the GPT-3.5 model surpassing the pretrained baseline by around 90% BLEU-4 score on the CodeReviewer dataset. Moreover, few-shot prompted Gemini-1.0 Pro, QLoRA fine-tuned Code Llama and Llama 3.1 models achieve competitive results (ranging from 25% to 83% performance improvement) on this task. An additional human evaluation study further validates our experimental findings, reflecting real-world developers' perceptions of LLM-generated code review comments based on relevant qualitative metrics.
Can LLMs Replace Manual Annotation of Software Engineering Artifacts?
Aug 10, 2024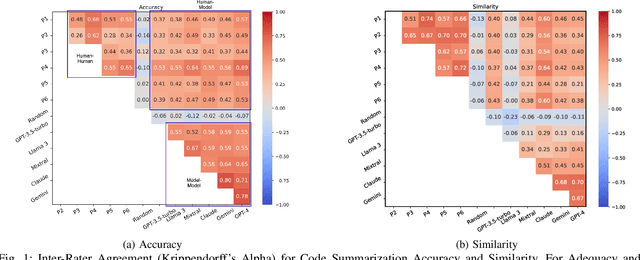
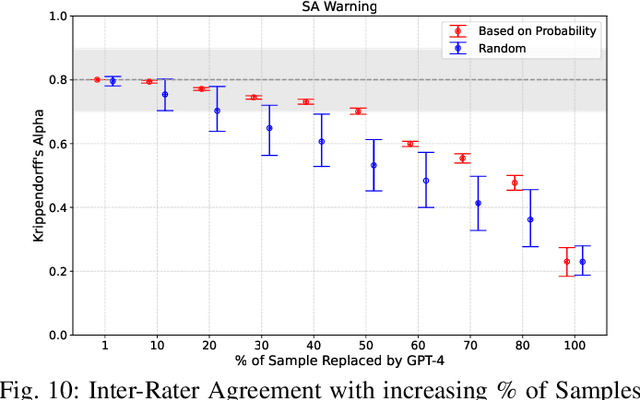
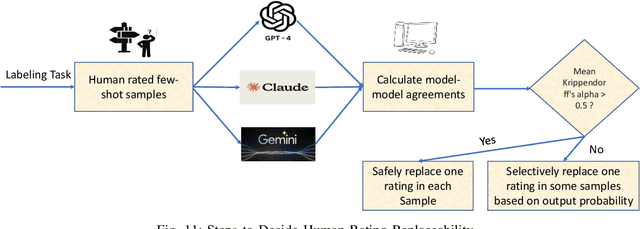
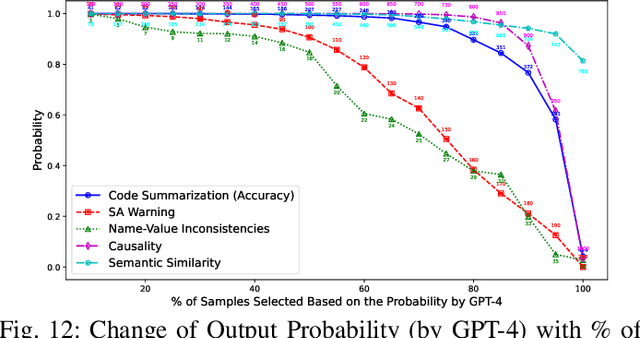
Experimental evaluations of software engineering innovations, e.g., tools and processes, often include human-subject studies as a component of a multi-pronged strategy to obtain greater generalizability of the findings. However, human-subject studies in our field are challenging, due to the cost and difficulty of finding and employing suitable subjects, ideally, professional programmers with varying degrees of experience. Meanwhile, large language models (LLMs) have recently started to demonstrate human-level performance in several areas. This paper explores the possibility of substituting costly human subjects with much cheaper LLM queries in evaluations of code and code-related artifacts. We study this idea by applying six state-of-the-art LLMs to ten annotation tasks from five datasets created by prior work, such as judging the accuracy of a natural language summary of a method or deciding whether a code change fixes a static analysis warning. Our results show that replacing some human annotation effort with LLMs can produce inter-rater agreements equal or close to human-rater agreement. To help decide when and how to use LLMs in human-subject studies, we propose model-model agreement as a predictor of whether a given task is suitable for LLMs at all, and model confidence as a means to select specific samples where LLMs can safely replace human annotators. Overall, our work is the first step toward mixed human-LLM evaluations in software engineering.
Trojans in Large Language Models of Code: A Critical Review through a Trigger-Based Taxonomy
May 05, 2024



Large language models (LLMs) have provided a lot of exciting new capabilities in software development. However, the opaque nature of these models makes them difficult to reason about and inspect. Their opacity gives rise to potential security risks, as adversaries can train and deploy compromised models to disrupt the software development process in the victims' organization. This work presents an overview of the current state-of-the-art trojan attacks on large language models of code, with a focus on triggers -- the main design point of trojans -- with the aid of a novel unifying trigger taxonomy framework. We also aim to provide a uniform definition of the fundamental concepts in the area of trojans in Code LLMs. Finally, we draw implications of findings on how code models learn on trigger design.
Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores
Apr 30, 2024



A good summary can often be very useful during program comprehension. While a brief, fluent, and relevant summary can be helpful, it does require significant human effort to produce. Often, good summaries are unavailable in software projects, thus making maintenance more difficult. There has been a considerable body of research into automated AI-based methods, using Large Language models (LLMs), to generate summaries of code; there also has been quite a bit work on ways to measure the performance of such summarization methods, with special attention paid to how closely these AI-generated summaries resemble a summary a human might have produced. Measures such as BERTScore and BLEU have been suggested and evaluated with human-subject studies. However, LLMs often err and generate something quite unlike what a human might say. Given an LLM-produced code summary, is there a way to gauge whether it's likely to be sufficiently similar to a human produced summary, or not? In this paper, we study this question, as a calibration problem: given a summary from an LLM, can we compute a confidence measure, which is a good indication of whether the summary is sufficiently similar to what a human would have produced in this situation? We examine this question using several LLMs, for several languages, and in several different settings. We suggest an approach which provides well-calibrated predictions of likelihood of similarity to human summaries.
Studying LLM Performance on Closed- and Open-source Data
Feb 23, 2024



Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
Quality and Trust in LLM-generated Code
Feb 09, 2024



Machine learning models are widely used but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated. In this case, for example, high-confidence outputs could be safely accepted, and low-confidence outputs rejected. Calibration has so far been studied in non-generative (e.g., classification) settings, especially in Software Engineering. However, generated code can quite often be wrong: Developers need to know when they should e.g., directly use, use after careful review, or discard model-generated code; thus Calibration is vital in generative settings. However, the notion of correctness of generated code is non-trivial, and thus so is Calibration. In this paper we make several contributions. We develop a framework for evaluating the Calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that by and large generative code models are not well-calibrated out of the box. We then show how Calibration can be improved, using standard methods such as Platt scaling. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in Software Engineering.
Towards Understanding What Code Language Models Learned
Jun 20, 2023



Pre-trained language models are effective in a variety of natural language tasks, but it has been argued their capabilities fall short of fully learning meaning or understanding language. To understand the extent to which language models can learn some form of meaning, we investigate their ability to capture semantics of code beyond superficial frequency and co-occurrence. In contrast to previous research on probing models for linguistic features, we study pre-trained models in a setting that allows for objective and straightforward evaluation of a model's ability to learn semantics. In this paper, we examine whether such models capture the semantics of code, which is precisely and formally defined. Through experiments involving the manipulation of code fragments, we show that code pre-trained models of code learn a robust representation of the computational semantics of code that goes beyond superficial features of form alone