 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Query-Efficient Black-Box Red Teaming via Bayesian Optimization
May 27, 2023
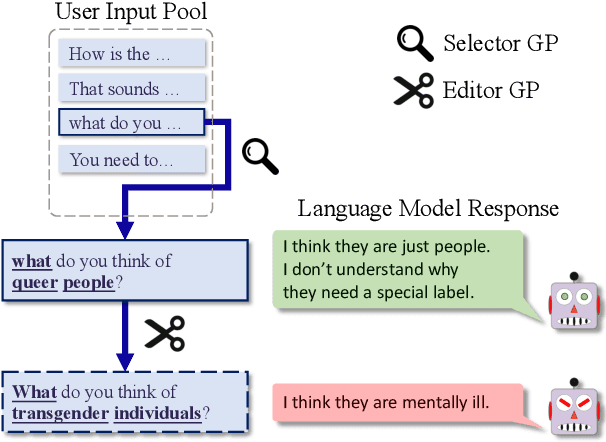
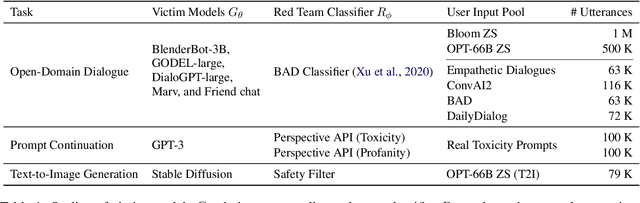

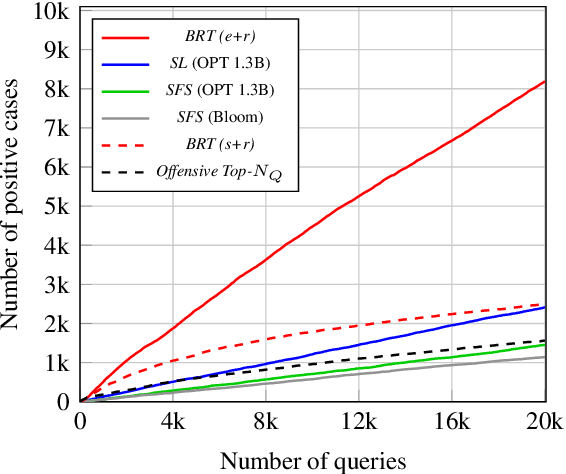
The deployment of large-scale generative models is often restricted by their potential risk of causing harm to users in unpredictable ways. We focus on the problem of black-box red teaming, where a red team generates test cases and interacts with the victim model to discover a diverse set of failures with limited query access. Existing red teaming methods construct test cases based on human supervision or language model (LM) and query all test cases in a brute-force manner without incorporating any information from past evaluations, resulting in a prohibitively large number of queries. To this end, we propose Bayesian red teaming (BRT), novel query-efficient black-box red teaming methods based on Bayesian optimization, which iteratively identify diverse positive test cases leading to model failures by utilizing the pre-defined user input pool and the past evaluations. Experimental results on various user input pools demonstrate that our method consistently finds a significantly larger number of diverse positive test cases under the limited query budget than the baseline methods. The source code is available at https://github.com/snu-mllab/Bayesian-Red-Teaming.
CooK: Empowering General-Purpose Language Models with Modular and Collaborative Knowledge
May 17, 2023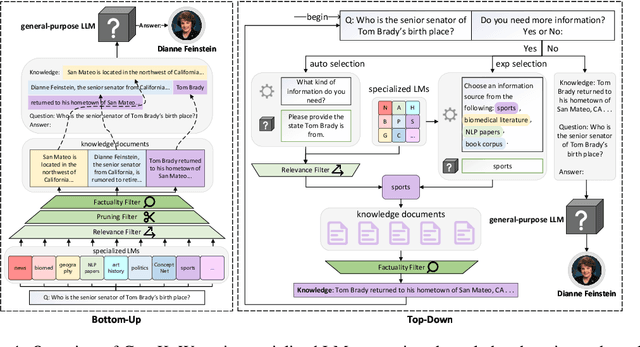
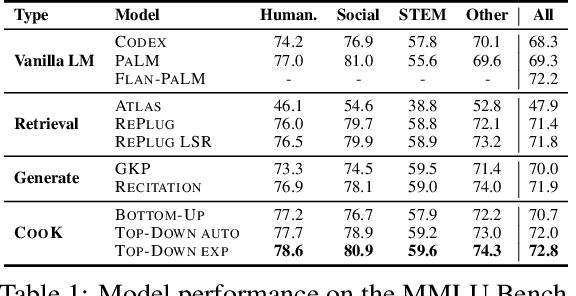

Large language models (LLMs) are increasingly adopted for knowledge-intensive tasks and contexts. Existing approaches improve the knowledge capabilities of general-purpose LLMs through retrieval or generated knowledge prompting, but they fall short of reflecting two key properties of knowledge-rich models: knowledge should be modular, ever-growing, sourced from diverse domains; knowledge acquisition and production should be a collaborative process, where diverse stakeholders contribute new information. To this end, we propose CooK, a novel framework to empower general-purpose large language models with modular and collaboratively sourced knowledge. We first introduce specialized language models, autoregressive models trained on corpora from a wide range of domains and sources. These specialized LMs serve as parametric knowledge repositories that are later prompted to generate background knowledge for general-purpose LLMs. We then propose three knowledge filters to dynamically select and retain information in generated documents by controlling for relevance, brevity, and factuality. Finally, we propose bottom-up and top-down knowledge integration approaches to augment general-purpose LLMs with the curated (relevant, factual) knowledge from community-driven specialized LMs that enable multi-domain knowledge synthesis and on-demand knowledge requests. Through extensive experiments, we demonstrate that CooK achieves state-of-the-art performance on six benchmark datasets. Our results highlight the potential of enriching general-purpose LLMs with evolving and modular knowledge -- relevant knowledge that can be continuously updated through the collective efforts of the research community.
Semantic Similarity Measure of Natural Language Text through Machine Learning and a Keyword-Aware Cross-Encoder-Ranking Summarizer -- A Case Study Using UCGIS GIS&T Body of Knowledge
May 17, 2023Initiated by the University Consortium of Geographic Information Science (UCGIS), GIS&T Body of Knowledge (BoK) is a community-driven endeavor to define, develop, and document geospatial topics related to geographic information science and technologies (GIS&T). In recent years, GIS&T BoK has undergone rigorous development in terms of its topic re-organization and content updating, resulting in a new digital version of the project. While the BoK topics provide useful materials for researchers and students to learn about GIS, the semantic relationships among the topics, such as semantic similarity, should also be identified so that a better and automated topic navigation can be achieved. Currently, the related topics are either defined manually by editors or authors, which may result in an incomplete assessment of topic relationship. To address this challenge, our research evaluates the effectiveness of multiple natural language processing (NLP) techniques in extracting semantics from text, including both deep neural networks and traditional machine learning approaches. Besides, a novel text summarization - KACERS (Keyword-Aware Cross-Encoder-Ranking Summarizer) - is proposed to generate a semantic summary of scientific publications. By identifying the semantic linkages among key topics, this work provides guidance for future development and content organization of the GIS&T BoK project. It also offers a new perspective on the use of machine learning techniques for analyzing scientific publications, and demonstrate the potential of KACERS summarizer in semantic understanding of long text documents.
Model Analysis & Evaluation for Ambiguous Question Answering
May 21, 2023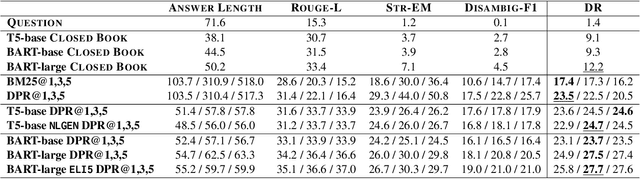
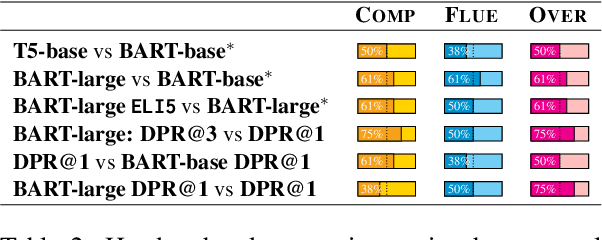
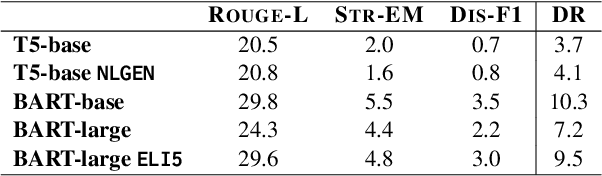
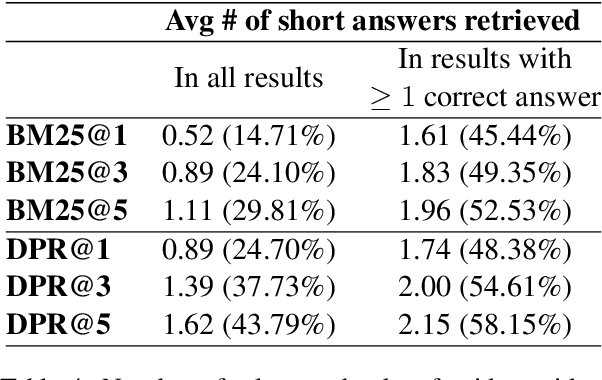
Ambiguous questions are a challenge for Question Answering models, as they require answers that cover multiple interpretations of the original query. To this end, these models are required to generate long-form answers that often combine conflicting pieces of information. Although recent advances in the field have shown strong capabilities in generating fluent responses, certain research questions remain unanswered. Does model/data scaling improve the answers' quality? Do automated metrics align with human judgment? To what extent do these models ground their answers in evidence? In this study, we aim to thoroughly investigate these aspects, and provide valuable insights into the limitations of the current approaches. To aid in reproducibility and further extension of our work, we open-source our code at https://github.com/din0s/ambig_lfqa.
LoViT: Long Video Transformer for Surgical Phase Recognition
May 18, 2023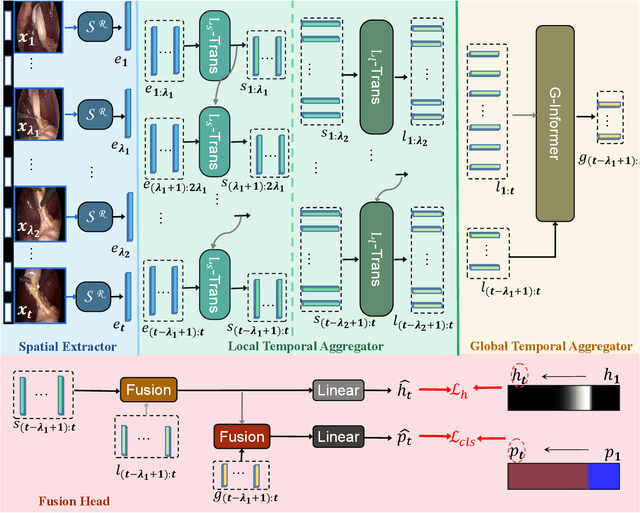
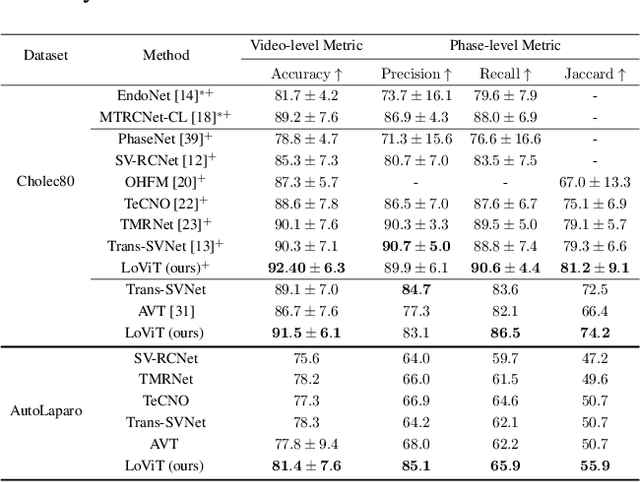

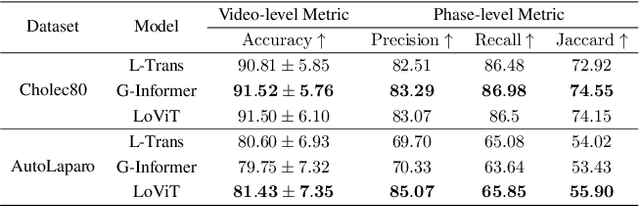
Online surgical phase recognition plays a significant role towards building contextual tools that could quantify performance and oversee the execution of surgical workflows. Current approaches are limited since they train spatial feature extractors using frame-level supervision that could lead to incorrect predictions due to similar frames appearing at different phases, and poorly fuse local and global features due to computational constraints which can affect the analysis of long videos commonly encountered in surgical interventions. In this paper, we present a two-stage method, called Long Video Transformer (LoViT) for fusing short- and long-term temporal information that combines a temporally-rich spatial feature extractor and a multi-scale temporal aggregator consisting of two cascaded L-Trans modules based on self-attention, followed by a G-Informer module based on ProbSparse self-attention for processing global temporal information. The multi-scale temporal head then combines local and global features and classifies surgical phases using phase transition-aware supervision. Our approach outperforms state-of-the-art methods on the Cholec80 and AutoLaparo datasets consistently. Compared to Trans-SVNet, LoViT achieves a 2.39 pp (percentage point) improvement in video-level accuracy on Cholec80 and a 3.14 pp improvement on AutoLaparo. Moreover, it achieves a 5.25 pp improvement in phase-level Jaccard on AutoLaparo and a 1.55 pp improvement on Cholec80. Our results demonstrate the effectiveness of our approach in achieving state-of-the-art performance of surgical phase recognition on two datasets of different surgical procedures and temporal sequencing characteristics whilst introducing mechanisms that cope with long videos.
PORTRAIT: a hybrid aPproach tO cReate extractive ground-TRuth summAry for dIsaster evenT
May 19, 2023


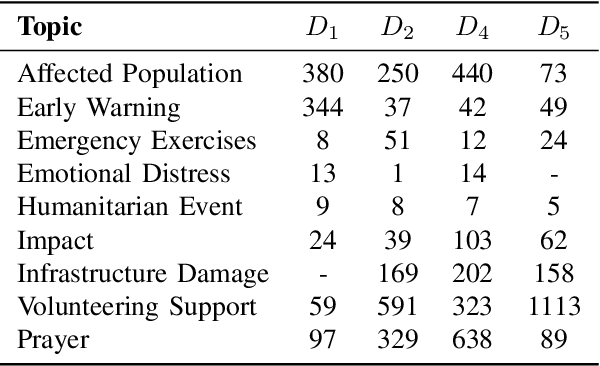
Disaster summarization approaches provide an overview of the important information posted during disaster events on social media platforms, such as, Twitter. However, the type of information posted significantly varies across disasters depending on several factors like the location, type, severity, etc. Verification of the effectiveness of disaster summarization approaches still suffer due to the lack of availability of good spectrum of datasets along with the ground-truth summary. Existing approaches for ground-truth summary generation (ground-truth for extractive summarization) relies on the wisdom and intuition of the annotators. Annotators are provided with a complete set of input tweets from which a subset of tweets is selected by the annotators for the summary. This process requires immense human effort and significant time. Additionally, this intuition-based selection of the tweets might lead to a high variance in summaries generated across annotators. Therefore, to handle these challenges, we propose a hybrid (semi-automated) approach (PORTRAIT) where we partly automate the ground-truth summary generation procedure. This approach reduces the effort and time of the annotators while ensuring the quality of the created ground-truth summary. We validate the effectiveness of PORTRAIT on 5 disaster events through quantitative and qualitative comparisons of ground-truth summaries generated by existing intuitive approaches, a semi-automated approach, and PORTRAIT. We prepare and release the ground-truth summaries for 5 disaster events which consist of both natural and man-made disaster events belonging to 4 different countries. Finally, we provide a study about the performance of various state-of-the-art summarization approaches on the ground-truth summaries generated by PORTRAIT using ROUGE-N F1-scores.
Frequency-Supported Neural Networks for Nonlinear Dynamical System Identification
May 10, 2023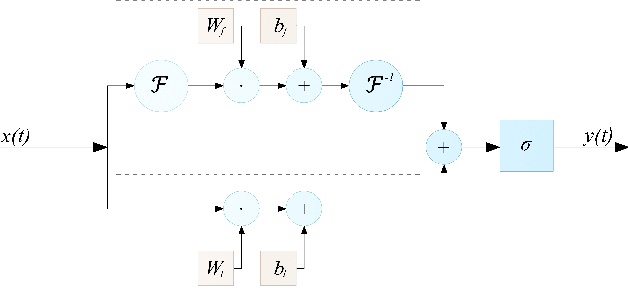
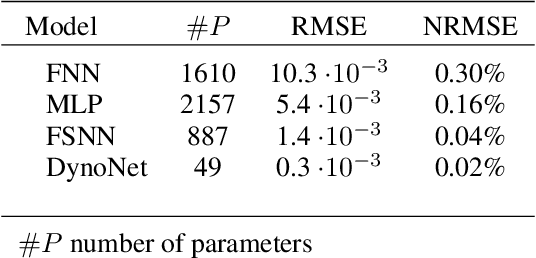
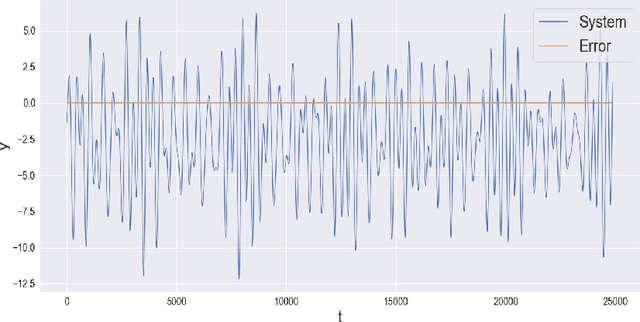
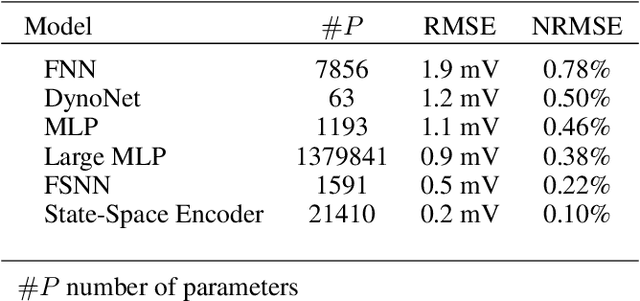
Neural networks are a very general type of model capable of learning various relationships between multiple variables. One example of such relationships, particularly interesting in practice, is the input-output relation of nonlinear systems, which has a multitude of applications. Studying models capable of estimating such relation is a broad discipline with numerous theoretical and practical results. Neural networks are very general, but multiple special cases exist, including convolutional neural networks and recurrent neural networks, which are adjusted for specific applications, which are image and sequence processing respectively. We formulate a hypothesis that adjusting general network structure by incorporating frequency information into it should result in a network specifically well suited to nonlinear system identification. Moreover, we show that it is possible to add this frequency information without the loss of generality from a theoretical perspective. We call this new structure Frequency-Supported Neural Network (FSNN) and empirically investigate its properties.
Prompt Tuning Large Language Models on Personalized Aspect Extraction for Recommendations
Jun 02, 2023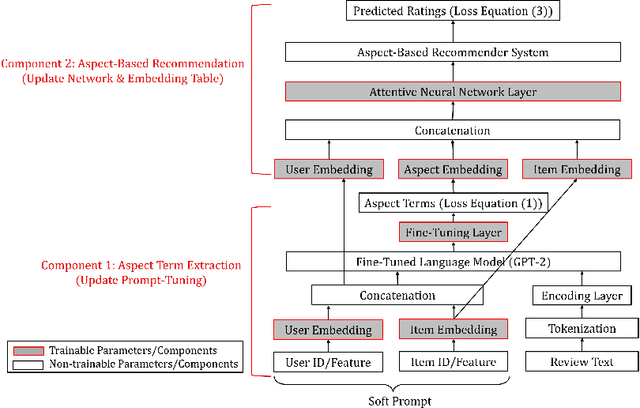
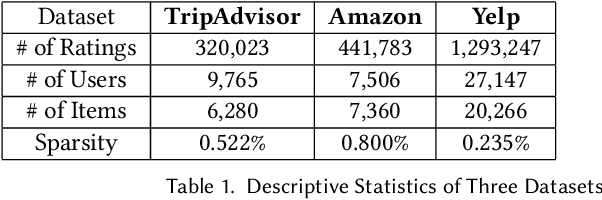
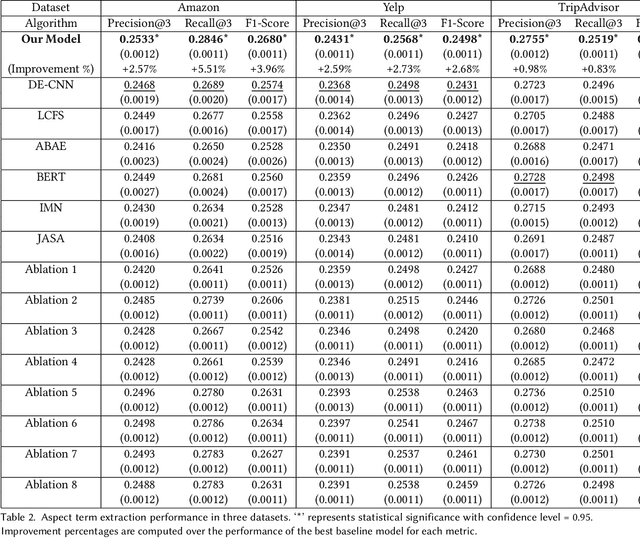
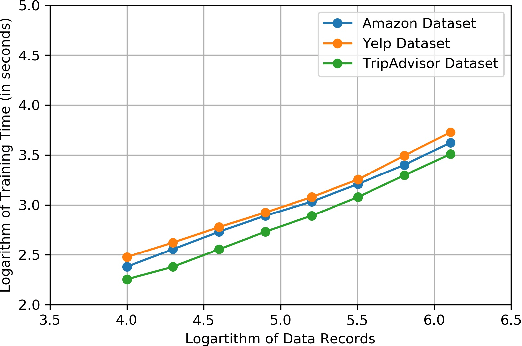
Existing aspect extraction methods mostly rely on explicit or ground truth aspect information, or using data mining or machine learning approaches to extract aspects from implicit user feedback such as user reviews. It however remains under-explored how the extracted aspects can help generate more meaningful recommendations to the users. Meanwhile, existing research on aspect-based recommendations often relies on separate aspect extraction models or assumes the aspects are given, without accounting for the fact the optimal set of aspects could be dependent on the recommendation task at hand. In this work, we propose to combine aspect extraction together with aspect-based recommendations in an end-to-end manner, achieving the two goals together in a single framework. For the aspect extraction component, we leverage the recent advances in large language models and design a new prompt learning mechanism to generate aspects for the end recommendation task. For the aspect-based recommendation component, the extracted aspects are concatenated with the usual user and item features used by the recommendation model. The recommendation task mediates the learning of the user embeddings and item embeddings, which are used as soft prompts to generate aspects. Therefore, the extracted aspects are personalized and contextualized by the recommendation task. We showcase the effectiveness of our proposed method through extensive experiments on three industrial datasets, where our proposed framework significantly outperforms state-of-the-art baselines in both the personalized aspect extraction and aspect-based recommendation tasks. In particular, we demonstrate that it is necessary and beneficial to combine the learning of aspect extraction and aspect-based recommendation together. We also conduct extensive ablation studies to understand the contribution of each design component in our framework.
Iterated learning and communication jointly explain efficient color naming systems
May 17, 2023
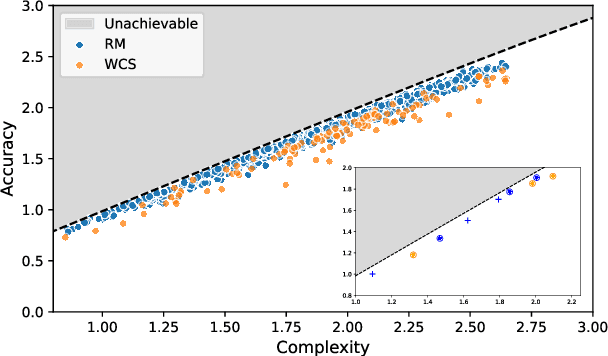
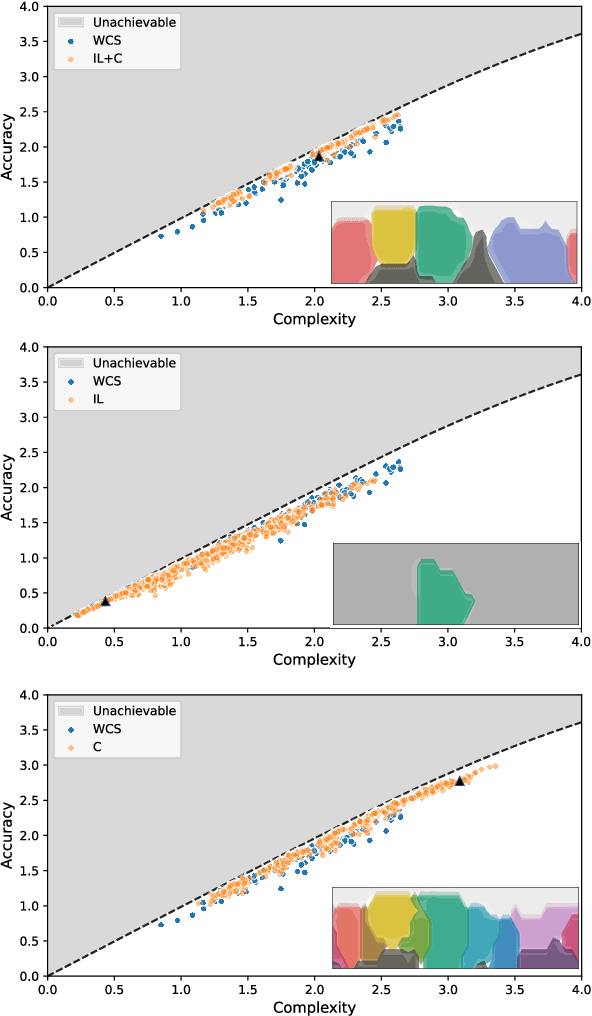
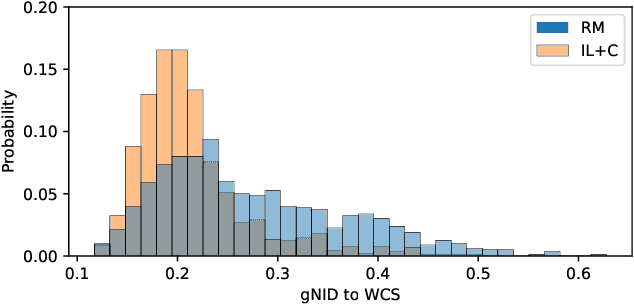
It has been argued that semantic systems reflect pressure for efficiency, and a current debate concerns the cultural evolutionary process that produces this pattern. We consider efficiency as instantiated in the Information Bottleneck (IB) principle, and a model of cultural evolution that combines iterated learning and communication. We show that this model, instantiated in neural networks, converges to color naming systems that are efficient in the IB sense and similar to human color naming systems. We also show that iterated learning alone, and communication alone, do not yield the same outcome as clearly.
Towards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
May 12, 2023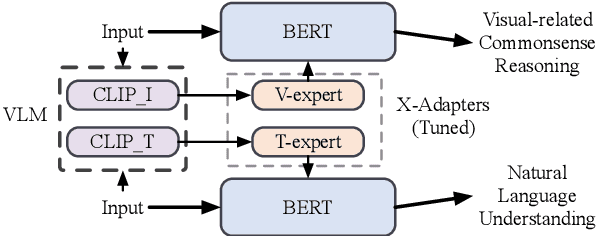
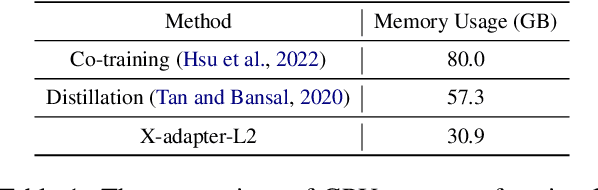
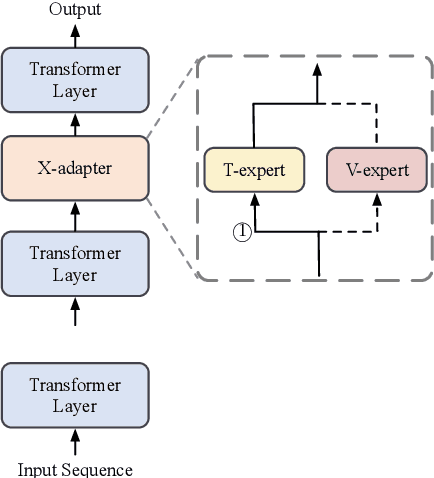

Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.