 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Dataset Cartography for Large Language Model Alignment: Mapping and Diagnosing Preference Data
May 29, 2025Human preference data plays a critical role in aligning large language models (LLMs) with human values. However, collecting such data is often expensive and inefficient, posing a significant scalability challenge. To address this, we introduce Alignment Data Map, a GPT-4o-assisted tool for analyzing and diagnosing preference data. Using GPT-4o as a proxy for LLM alignment, we compute alignment scores for LLM-generated responses to instructions from existing preference datasets. These scores are then used to construct an Alignment Data Map based on their mean and variance. Our experiments show that using only 33 percent of the data, specifically samples in the high-mean, low-variance region, achieves performance comparable to or better than using the entire dataset. This finding suggests that the Alignment Data Map can significantly improve data collection efficiency by identifying high-quality samples for LLM alignment without requiring explicit annotations. Moreover, the Alignment Data Map can diagnose existing preference datasets. Our analysis shows that it effectively detects low-impact or potentially misannotated samples. Source code is available online.
Drift: Decoding-time Personalized Alignments with Implicit User Preferences
Feb 21, 2025



Personalized alignments for individual users have been a long-standing goal in large language models (LLMs). We introduce Drift, a novel framework that personalizes LLMs at decoding time with implicit user preferences. Traditional Reinforcement Learning from Human Feedback (RLHF) requires thousands of annotated examples and expensive gradient updates. In contrast, Drift personalizes LLMs in a training-free manner, using only a few dozen examples to steer a frozen model through efficient preference modeling. Our approach models user preferences as a composition of predefined, interpretable attributes and aligns them at decoding time to enable personalized generation. Experiments on both a synthetic persona dataset (Perspective) and a real human-annotated dataset (PRISM) demonstrate that Drift significantly outperforms RLHF baselines while using only 50-100 examples. Our results and analysis show that Drift is both computationally efficient and interpretable.
Code-Switching Curriculum Learning for Multilingual Transfer in LLMs
Nov 04, 2024



Large language models (LLMs) now exhibit near human-level performance in various tasks, but their performance drops drastically after a handful of high-resource languages due to the imbalance in pre-training data. Inspired by the human process of second language acquisition, particularly code-switching (the practice of language alternation in a conversation), we propose code-switching curriculum learning (CSCL) to enhance cross-lingual transfer for LLMs. CSCL mimics the stages of human language learning by progressively training models with a curriculum consisting of 1) token-level code-switching, 2) sentence-level code-switching, and 3) monolingual corpora. Using Qwen 2 as our underlying model, we demonstrate the efficacy of the CSCL in improving language transfer to Korean, achieving significant performance gains compared to monolingual continual pre-training methods. Ablation studies reveal that both token- and sentence-level code-switching significantly enhance cross-lingual transfer and that curriculum learning amplifies these effects. We also extend our findings into various languages, including Japanese (high-resource) and Indonesian (low-resource), and using two additional models (Gemma 2 and Phi 3.5). We further show that CSCL mitigates spurious correlations between language resources and safety alignment, presenting a robust, efficient framework for more equitable language transfer in LLMs. We observe that CSCL is effective for low-resource settings where high-quality, monolingual corpora for language transfer are hardly available.
Guaranteed Generation from Large Language Models
Oct 09, 2024



As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD's theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
MAQA: Evaluating Uncertainty Quantification in LLMs Regarding Data Uncertainty
Aug 13, 2024Although large language models (LLMs) are capable of performing various tasks, they still suffer from producing plausible but incorrect responses. To improve the reliability of LLMs, recent research has focused on uncertainty quantification to predict whether a response is correct or not. However, most uncertainty quantification methods have been evaluated on questions requiring a single clear answer, ignoring the existence of data uncertainty that arises from irreducible randomness. Instead, these methods only consider model uncertainty, which arises from a lack of knowledge. In this paper, we investigate previous uncertainty quantification methods under the presence of data uncertainty. Our contributions are two-fold: 1) proposing a new Multi-Answer Question Answering dataset, MAQA, consisting of world knowledge, mathematical reasoning, and commonsense reasoning tasks to evaluate uncertainty quantification regarding data uncertainty, and 2) assessing 5 uncertainty quantification methods of diverse white- and black-box LLMs. Our findings show that entropy and consistency-based methods estimate the model uncertainty well even under data uncertainty, while other methods for white- and black-box LLMs struggle depending on the tasks. Additionally, methods designed for white-box LLMs suffer from overconfidence in reasoning tasks compared to simple knowledge queries. We believe our observations will pave the way for future work on uncertainty quantification in realistic setting.
CSRT: Evaluation and Analysis of LLMs using Code-Switching Red-Teaming Dataset
Jun 17, 2024



Recent studies in large language models (LLMs) shed light on their multilingual ability and safety, beyond conventional tasks in language modeling. Still, current benchmarks reveal their inability to comprehensively evaluate them and are excessively dependent on manual annotations. In this paper, we introduce code-switching red-teaming (CSRT), a simple yet effective red-teaming technique that simultaneously tests multilingual understanding and safety of LLMs. We release the CSRT dataset, which comprises 315 code-switching queries combining up to 10 languages and eliciting a wide range of undesirable behaviors. Through extensive experiments with ten state-of-the-art LLMs, we demonstrate that CSRT significantly outperforms existing multilingual red-teaming techniques, achieving 46.7% more attacks than existing methods in English. We analyze the harmful responses toward the CSRT dataset concerning various aspects under ablation studies with 16K samples, including but not limited to scaling laws, unsafe behavior categories, and input conditions for optimal data generation. Additionally, we validate the extensibility of CSRT, by generating code-switching attack prompts with monolingual data.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024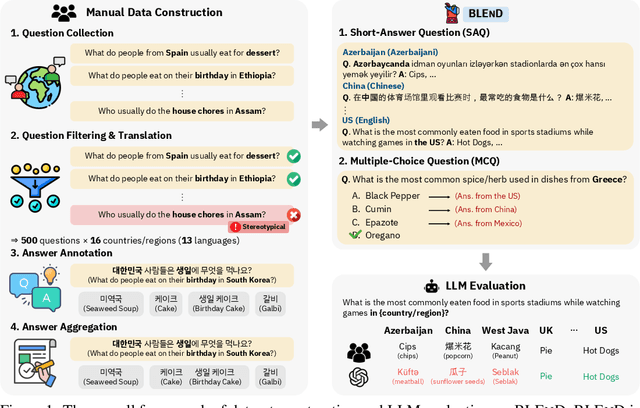
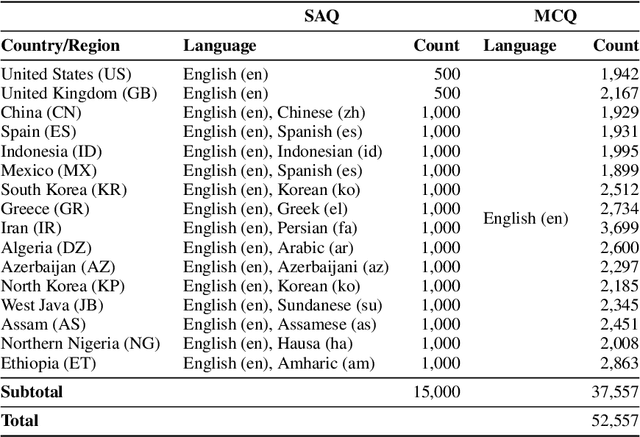
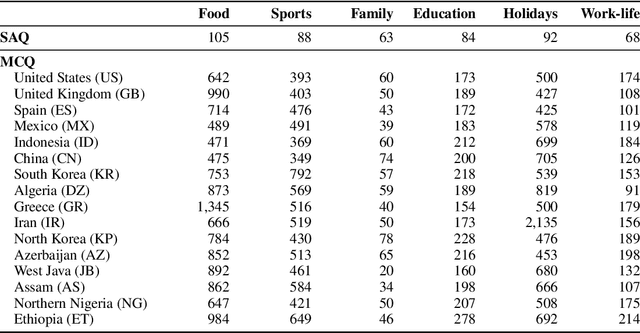
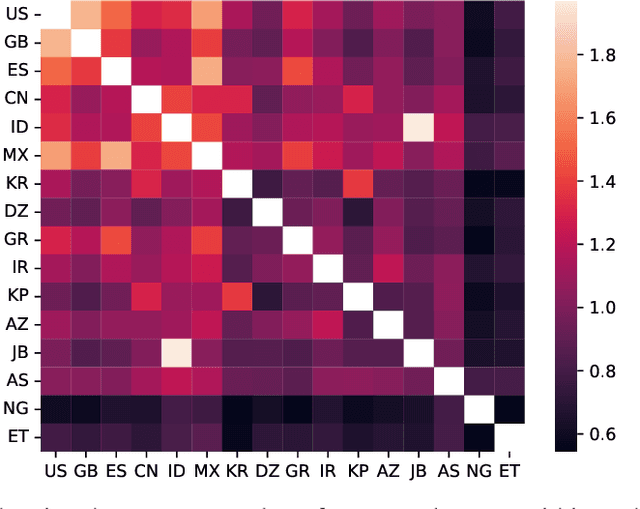
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
TimeChara: Evaluating Point-in-Time Character Hallucination of Role-Playing Large Language Models
May 28, 2024While Large Language Models (LLMs) can serve as agents to simulate human behaviors (i.e., role-playing agents), we emphasize the importance of point-in-time role-playing. This situates characters at specific moments in the narrative progression for three main reasons: (i) enhancing users' narrative immersion, (ii) avoiding spoilers, and (iii) fostering engagement in fandom role-playing. To accurately represent characters at specific time points, agents must avoid character hallucination, where they display knowledge that contradicts their characters' identities and historical timelines. We introduce TimeChara, a new benchmark designed to evaluate point-in-time character hallucination in role-playing LLMs. Comprising 10,895 instances generated through an automated pipeline, this benchmark reveals significant hallucination issues in current state-of-the-art LLMs (e.g., GPT-4o). To counter this challenge, we propose Narrative-Experts, a method that decomposes the reasoning steps and utilizes narrative experts to reduce point-in-time character hallucinations effectively. Still, our findings with TimeChara highlight the ongoing challenges of point-in-time character hallucination, calling for further study.
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
Apr 18, 2024



As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.