 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATSumm: Auxiliary information enhanced approach for abstractive disaster Tweet Summarization with sparse training data
May 10, 2024



The abundance of situational information on Twitter poses a challenge for users to manually discern vital and relevant information during disasters. A concise and human-interpretable overview of this information helps decision-makers in implementing efficient and quick disaster response. Existing abstractive summarization approaches can be categorized as sentence-based or key-phrase-based approaches. This paper focuses on sentence-based approach, which is typically implemented as a dual-phase procedure in literature. The initial phase, known as the extractive phase, involves identifying the most relevant tweets. The subsequent phase, referred to as the abstractive phase, entails generating a more human-interpretable summary. In this study, we adopt the methodology from prior research for the extractive phase. For the abstractive phase of summarization, most existing approaches employ deep learning-based frameworks, which can either be pre-trained or require training from scratch. However, to achieve the appropriate level of performance, it is imperative to have substantial training data for both methods, which is not readily available. This work presents an Abstractive Tweet Summarizer (ATSumm) that effectively addresses the issue of data sparsity by using auxiliary information. We introduced the Auxiliary Pointer Generator Network (AuxPGN) model, which utilizes a unique attention mechanism called Key-phrase attention. This attention mechanism incorporates auxiliary information in the form of key-phrases and their corresponding importance scores from the input tweets. We evaluate the proposed approach by comparing it with 10 state-of-the-art approaches across 13 disaster datasets. The evaluation results indicate that ATSumm achieves superior performance compared to state-of-the-art approaches, with improvement of 4-80% in ROUGE-N F1-score.
ADSumm: Annotated Ground-truth Summary Datasets for Disaster Tweet Summarization
May 10, 2024



Online social media platforms, such as Twitter, provide valuable information during disaster events. Existing tweet disaster summarization approaches provide a summary of these events to aid government agencies, humanitarian organizations, etc., to ensure effective disaster response. In the literature, there are two types of approaches for disaster summarization, namely, supervised and unsupervised approaches. Although supervised approaches are typically more effective, they necessitate a sizable number of disaster event summaries for testing and training. However, there is a lack of good number of disaster summary datasets for training and evaluation. This motivates us to add more datasets to make supervised learning approaches more efficient. In this paper, we present ADSumm, which adds annotated ground-truth summaries for eight disaster events which consist of both natural and man-made disaster events belonging to seven different countries. Our experimental analysis shows that the newly added datasets improve the performance of the supervised summarization approaches by 8-28% in terms of ROUGE-N F1-score. Moreover, in newly annotated dataset, we have added a category label for each input tweet which helps to ensure good coverage from different categories in summary. Additionally, we have added two other features relevance label and key-phrase, which provide information about the quality of a tweet and explanation about the inclusion of the tweet into summary, respectively. For ground-truth summary creation, we provide the annotation procedure adapted in detail, which has not been described in existing literature. Experimental analysis shows the quality of ground-truth summary is very good with Coverage, Relevance and Diversity.
TONE: A 3-Tiered ONtology for Emotion analysis
Jan 11, 2024



Emotions have played an important part in many sectors, including psychology, medicine, mental health, computer science, and so on, and categorizing them has proven extremely useful in separating one emotion from another. Emotions can be classified using the following two methods: (1) The supervised method's efficiency is strongly dependent on the size and domain of the data collected. A categorization established using relevant data from one domain may not work well in another. (2) An unsupervised method that uses either domain expertise or a knowledge base of emotion types already exists. Though this second approach provides a suitable and generic categorization of emotions and is cost-effective, the literature doesn't possess a publicly available knowledge base that can be directly applied to any emotion categorization-related task. This pushes us to create a knowledge base that can be used for emotion classification across domains, and ontology is often used for this purpose. In this study, we provide TONE, an emotion-based ontology that effectively creates an emotional hierarchy based on Dr. Gerrod Parrot's group of emotions. In addition to ontology development, we introduce a semi-automated vocabulary construction process to generate a detailed collection of terms for emotions at each tier of the hierarchy. We also demonstrate automated methods for establishing three sorts of dependencies in order to develop linkages between different emotions. Our human and automatic evaluation results show the ontology's quality. Furthermore, we describe three distinct use cases that demonstrate the applicability of our ontology.
PORTRAIT: a hybrid aPproach tO cReate extractive ground-TRuth summAry for dIsaster evenT
May 19, 2023



Disaster summarization approaches provide an overview of the important information posted during disaster events on social media platforms, such as, Twitter. However, the type of information posted significantly varies across disasters depending on several factors like the location, type, severity, etc. Verification of the effectiveness of disaster summarization approaches still suffer due to the lack of availability of good spectrum of datasets along with the ground-truth summary. Existing approaches for ground-truth summary generation (ground-truth for extractive summarization) relies on the wisdom and intuition of the annotators. Annotators are provided with a complete set of input tweets from which a subset of tweets is selected by the annotators for the summary. This process requires immense human effort and significant time. Additionally, this intuition-based selection of the tweets might lead to a high variance in summaries generated across annotators. Therefore, to handle these challenges, we propose a hybrid (semi-automated) approach (PORTRAIT) where we partly automate the ground-truth summary generation procedure. This approach reduces the effort and time of the annotators while ensuring the quality of the created ground-truth summary. We validate the effectiveness of PORTRAIT on 5 disaster events through quantitative and qualitative comparisons of ground-truth summaries generated by existing intuitive approaches, a semi-automated approach, and PORTRAIT. We prepare and release the ground-truth summaries for 5 disaster events which consist of both natural and man-made disaster events belonging to 4 different countries. Finally, we provide a study about the performance of various state-of-the-art summarization approaches on the ground-truth summaries generated by PORTRAIT using ROUGE-N F1-scores.
IKDSumm: Incorporating Key-phrases into BERT for extractive Disaster Tweet Summarization
May 19, 2023Online social media platforms, such as Twitter, are one of the most valuable sources of information during disaster events. Therefore, humanitarian organizations, government agencies, and volunteers rely on a summary of this information, i.e., tweets, for effective disaster management. Although there are several existing supervised and unsupervised approaches for automated tweet summary approaches, these approaches either require extensive labeled information or do not incorporate specific domain knowledge of disasters. Additionally, the most recent approaches to disaster summarization have proposed BERT-based models to enhance the summary quality. However, for further improved performance, we introduce the utilization of domain-specific knowledge without any human efforts to understand the importance (salience) of a tweet which further aids in summary creation and improves summary quality. In this paper, we propose a disaster-specific tweet summarization framework, IKDSumm, which initially identifies the crucial and important information from each tweet related to a disaster through key-phrases of that tweet. We identify these key-phrases by utilizing the domain knowledge (using existing ontology) of disasters without any human intervention. Further, we utilize these key-phrases to automatically generate a summary of the tweets. Therefore, given tweets related to a disaster, IKDSumm ensures fulfillment of the summarization key objectives, such as information coverage, relevance, and diversity in summary without any human intervention. We evaluate the performance of IKDSumm with 8 state-of-the-art techniques on 12 disaster datasets. The evaluation results show that IKDSumm outperforms existing techniques by approximately 2-79% in terms of ROUGE-N F1-score.
Predicting Tomorrow's Headline using Today's Twitter Deliberations
Jan 27, 2019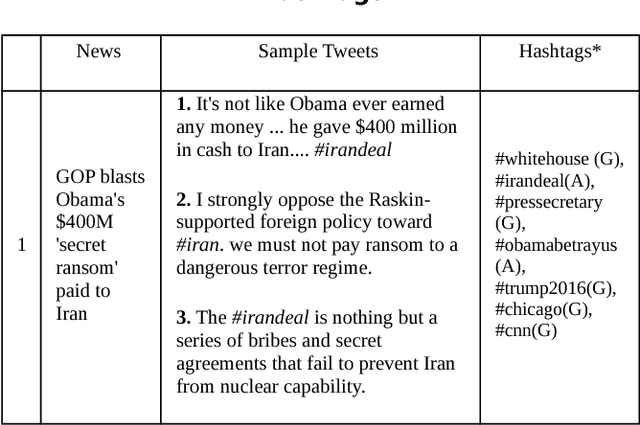
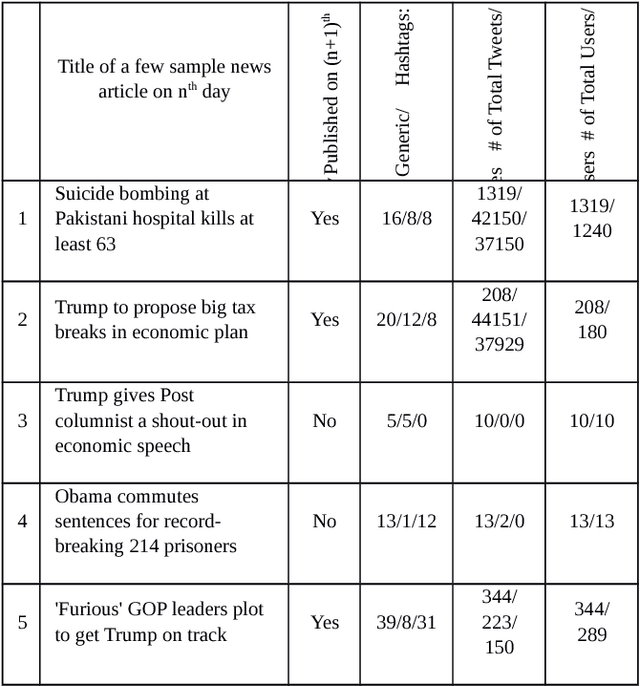
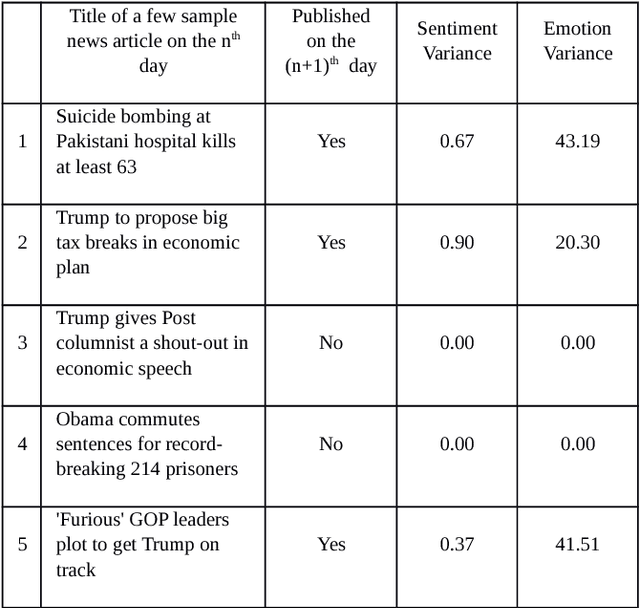
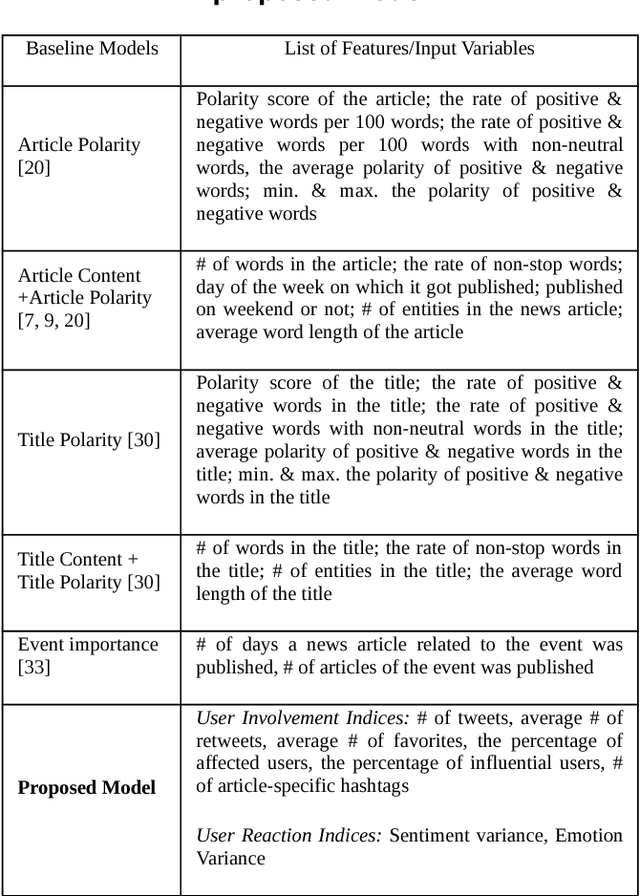
Predicting the popularity of news article is a challenging task. Existing literature mostly focused on article contents and polarity to predict popularity. However, existing research has not considered the users' preference towards a particular article. Understanding users' preference is an important aspect for predicting the popularity of news articles. Hence, we consider the social media data, from the Twitter platform, to address this research gap. In our proposed model, we have considered the users' involvement as well as the users' reaction towards an article to predict the popularity of the article. In short, we are predicting tomorrow's headline by probing today's Twitter discussion. We have considered 300 political news article from the New York Post, and our proposed approach has outperformed other baseline models.