 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Writing your own book: A method for going from closed to open book QA to improve robustness and performance of smaller LLMs
May 18, 2023

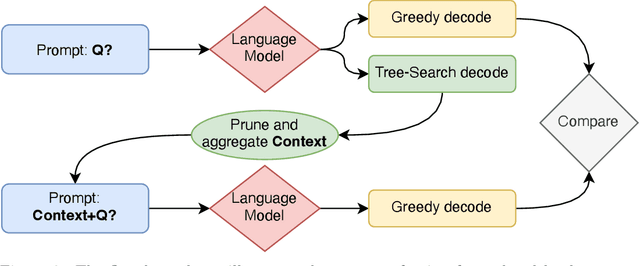
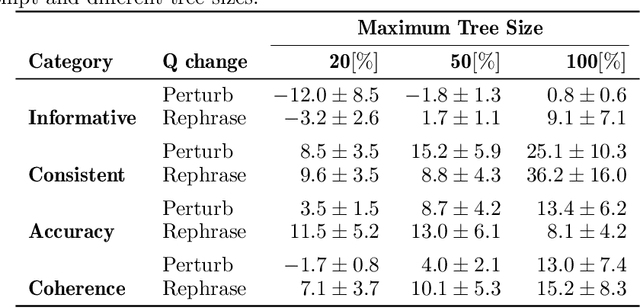
We introduce two novel methods, Tree-Search and Self-contextualizing QA, designed to enhance the performance of large language models (LLMs) in question-answering tasks. Tree-Search is a sampling technique specifically created to extract diverse information from an LLM for a given prompt. Self-contextualizing QA leverages Tree-Search to enable the model to create its own context using a wide range of information relevant to the prompt, evaluate it explicitly and return a open book answer to the initial prompt . We demonstrate that the quality of generated answers improves according to various metrics, including accuracy, informativeness, coherence, and consistency, as evaluated by GPT3.5(text-davinci-003). Furthermore, we show that our methods result in increased robustness and that performance is positively correlated with tree size, benefiting both answer quality and robustness. Finally, we discuss other promising applications of Tree-Search, highlighting its potential to enhance a broad range of tasks beyond question-answering. \noindent We also discuss several areas for future work, including refining the Tree-Search and Self-Contextualizing QA methods, improving the coherence of the generated context, and investigating the impact of bootstrapping on model robustness
Machine Learning Recommendation System For Health Insurance Decision Making In Nigeria
May 18, 2023
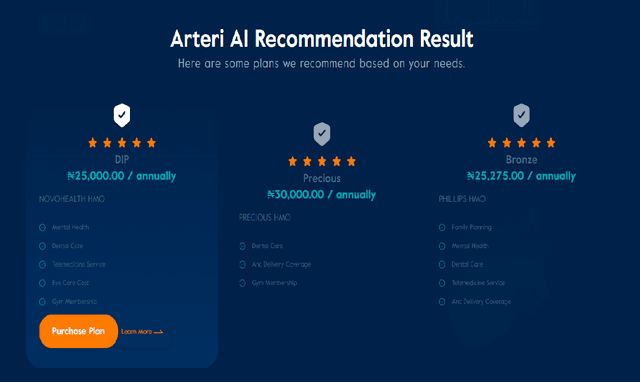
The uptake of health insurance has been poor in Nigeria, a significant step to improving this includes improved awareness, access to information and tools to support decision making. Artificial intelligence (AI) based recommender systems have gained popularity in helping individuals find movies, books, music, and different types of products on the internet including diverse applications in healthcare. The content-based methodology (item-based approach) was employed in the recommender system. We applied both the K-Nearest Neighbor (KNN) and Cosine similarity algorithm. We chose the Cosine similarity as our chosen algorithm after several evaluations based of their outcomes in comparison with domain knowledge. The recommender system takes into consideration the choices entered by the user, filters the health management organization (HMO) data by location and chosen prices. It then recommends the top 3 HMOs with closest similarity in services offered. A recommendation tool to help people find and select the best health insurance plan for them is useful in reducing the barrier of accessing health insurance. Users are empowered to easily find appropriate information on available plans, reduce cognitive overload in dealing with over 100 options available in the market and easily see what matches their financial capacity.
Deep Temporal Graph Clustering
May 18, 2023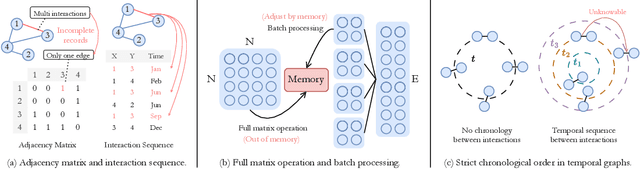
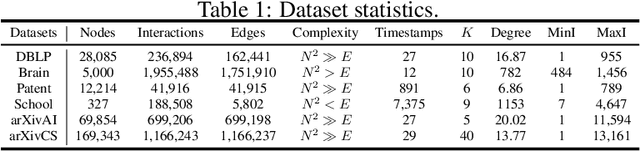
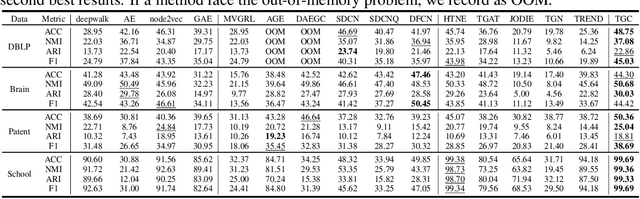
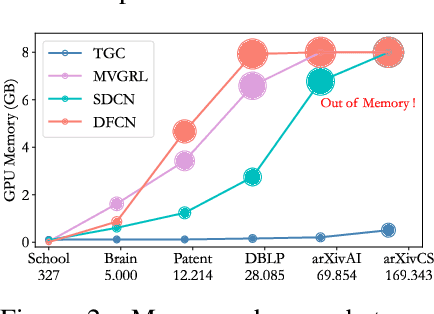
Deep graph clustering has recently received significant attention due to its ability to enhance the representation learning capabilities of models in unsupervised scenarios. Nevertheless, deep clustering for temporal graphs, which could capture crucial dynamic interaction information, has not been fully explored. It means that in many clustering-oriented real-world scenarios, temporal graphs can only be processed as static graphs. This not only causes the loss of dynamic information but also triggers huge computational consumption. To solve the problem, we propose a general framework for deep Temporal Graph Clustering called TGC, which adjusts deep clustering techniques (clustering assignment distribution and adjacency matrix reconstruction) to suit the interaction sequence-based batch-processing pattern of temporal graphs. In addition, we discuss differences between temporal graph clustering and existing static graph clustering from several levels. To verify the superiority of the proposed framework TGC, we conduct extensive experiments. The experimental results show that temporal graph clustering enables more flexibility in finding a balance between time and space requirements, and our framework can effectively improve the performance of existing temporal graph learning methods. Our code and supplementary material will be released after publication.
Exploring Temporal Information Dynamics in Spiking Neural Networks
Nov 30, 2022
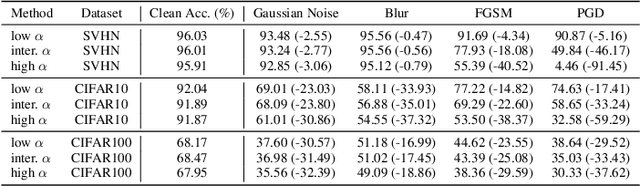
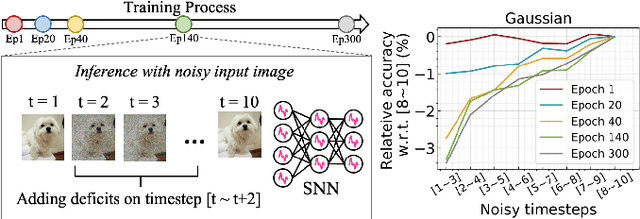
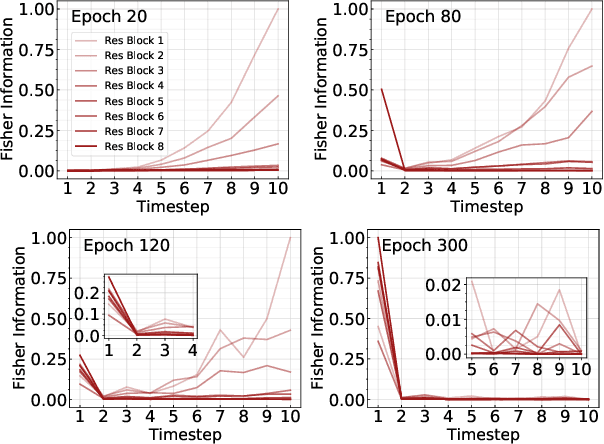
Most existing Spiking Neural Network (SNN) works state that SNNs may utilize temporal information dynamics of spikes. However, an explicit analysis of temporal information dynamics is still missing. In this paper, we ask several important questions for providing a fundamental understanding of SNNs: What are temporal information dynamics inside SNNs? How can we measure the temporal information dynamics? How do the temporal information dynamics affect the overall learning performance? To answer these questions, we estimate the Fisher Information of the weights to measure the distribution of temporal information during training in an empirical manner. Surprisingly, as training goes on, Fisher information starts to concentrate in the early timesteps. After training, we observe that information becomes highly concentrated in earlier few timesteps, a phenomenon we refer to as temporal information concentration. We observe that the temporal information concentration phenomenon is a common learning feature of SNNs by conducting extensive experiments on various configurations such as architecture, dataset, optimization strategy, time constant, and timesteps. Furthermore, to reveal how temporal information concentration affects the performance of SNNs, we design a loss function to change the trend of temporal information. We find that temporal information concentration is crucial to building a robust SNN but has little effect on classification accuracy. Finally, we propose an efficient iterative pruning method based on our observation on temporal information concentration. Code is available at https://github.com/Intelligent-Computing-Lab-Yale/Exploring-Temporal-Information-Dynamics-in-Spiking-Neural-Networks.
SWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages
May 30, 2023
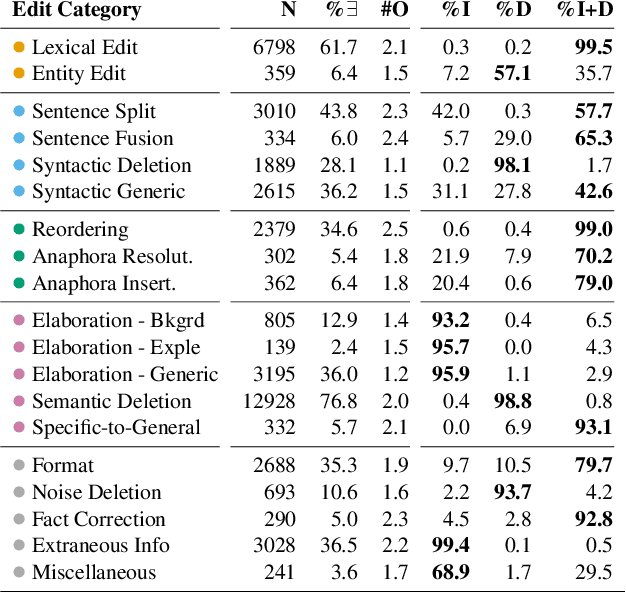
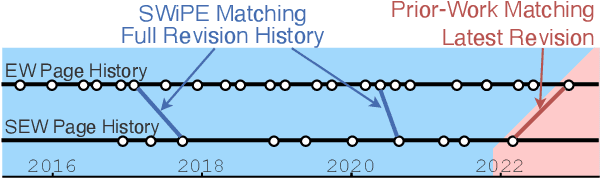
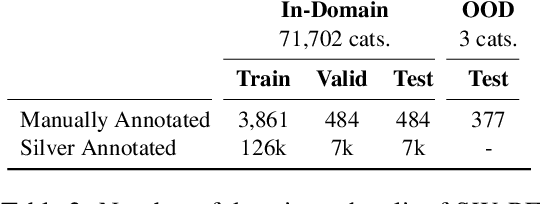
Text simplification research has mostly focused on sentence-level simplification, even though many desirable edits - such as adding relevant background information or reordering content - may require document-level context. Prior work has also predominantly framed simplification as a single-step, input-to-output task, only implicitly modeling the fine-grained, span-level edits that elucidate the simplification process. To address both gaps, we introduce the SWiPE dataset, which reconstructs the document-level editing process from English Wikipedia (EW) articles to paired Simple Wikipedia (SEW) articles. In contrast to prior work, SWiPE leverages the entire revision history when pairing pages in order to better identify simplification edits. We work with Wikipedia editors to annotate 5,000 EW-SEW document pairs, labeling more than 40,000 edits with proposed 19 categories. To scale our efforts, we propose several models to automatically label edits, achieving an F-1 score of up to 70.6, indicating that this is a tractable but challenging NLU task. Finally, we categorize the edits produced by several simplification models and find that SWiPE-trained models generate more complex edits while reducing unwanted edits.
An AMR-based Link Prediction Approach for Document-level Event Argument Extraction
May 30, 2023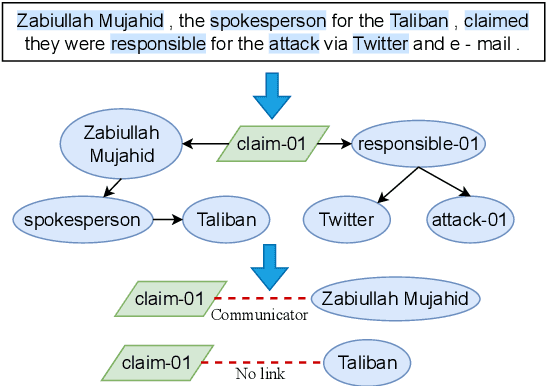

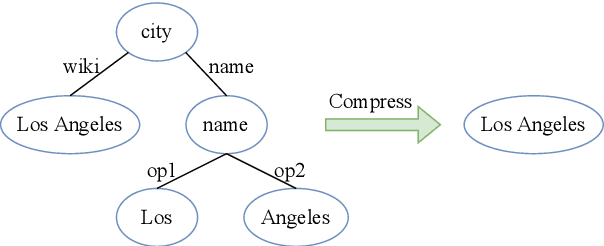
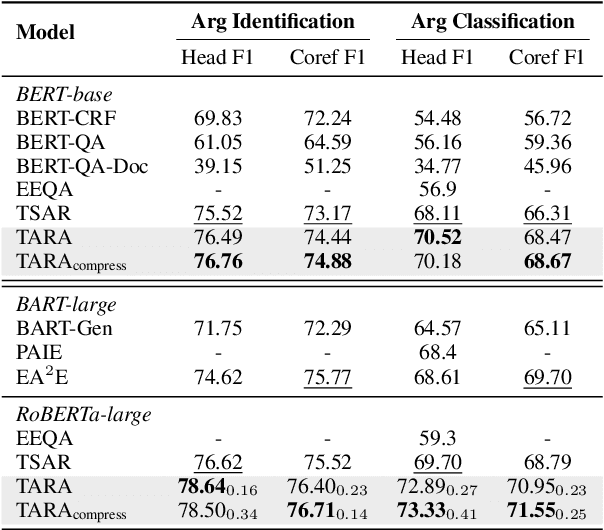
Recent works have introduced Abstract Meaning Representation (AMR) for Document-level Event Argument Extraction (Doc-level EAE), since AMR provides a useful interpretation of complex semantic structures and helps to capture long-distance dependency. However, in these works AMR is used only implicitly, for instance, as additional features or training signals. Motivated by the fact that all event structures can be inferred from AMR, this work reformulates EAE as a link prediction problem on AMR graphs. Since AMR is a generic structure and does not perfectly suit EAE, we propose a novel graph structure, Tailored AMR Graph (TAG), which compresses less informative subgraphs and edge types, integrates span information, and highlights surrounding events in the same document. With TAG, we further propose a novel method using graph neural networks as a link prediction model to find event arguments. Our extensive experiments on WikiEvents and RAMS show that this simpler approach outperforms the state-of-the-art models by 3.63pt and 2.33pt F1, respectively, and do so with reduced 56% inference time. The code is availabel at https://github.com/ayyyq/TARA.
Few-shot Classification with Shrinkage Exemplars
May 30, 2023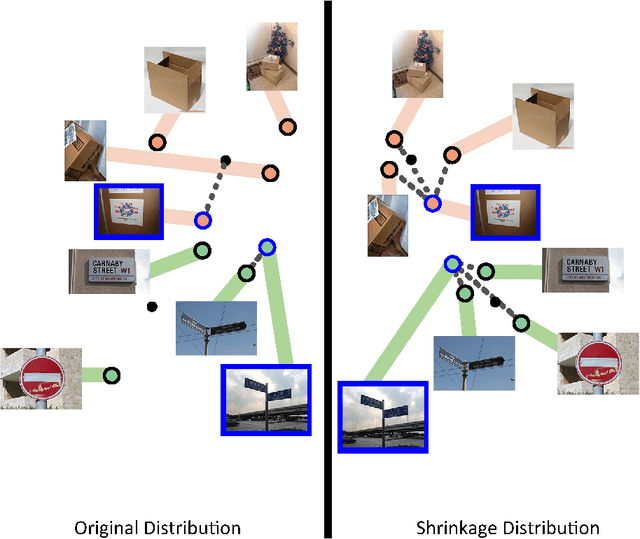
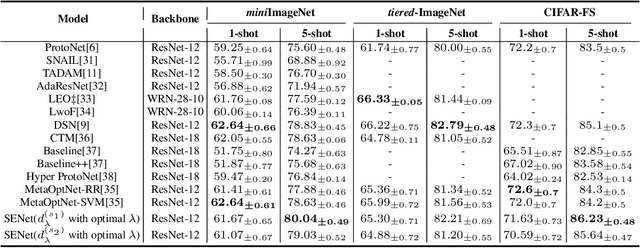
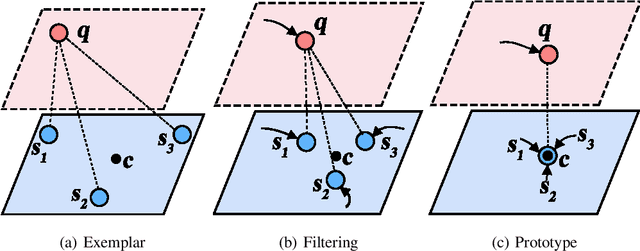
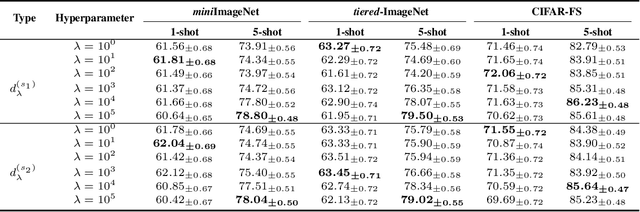
Prototype is widely used to represent internal structure of category for few-shot learning, which was proposed as a simple inductive bias to address the issue of overfitting. However, since prototype representation is normally averaged from individual samples, it cannot flexibly adjust the retention ability of sample differences that may leads to underfitting in some cases of sample distribution. To address this problem, in this work, we propose Shrinkage Exemplar Networks (SENet) for few-shot classification. SENet balances the prototype representations (high-bias, low-variance) and example representations (low-bias, high-variance) using a shrinkage estimator, where the categories are represented by the embedings of samples that shrink to their mean via spectral filtering. Furthermore, a shrinkage exemplar loss is proposed to replace the widely used cross entropy loss for capturing the information of individual shrinkage samples. Several experiments were conducted on miniImageNet, tiered-ImageNet and CIFAR-FS datasets. We demonstrate that our proposed model is superior to the example model and the prototype model for some tasks.
Strategic Reasoning with Language Models
May 30, 2023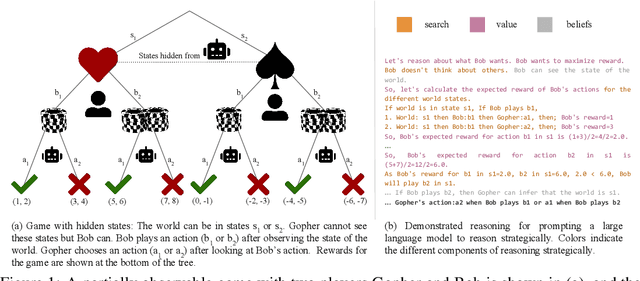
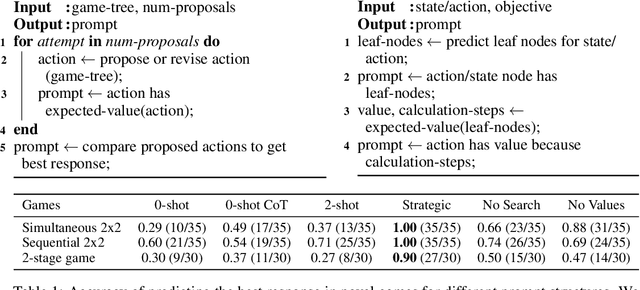
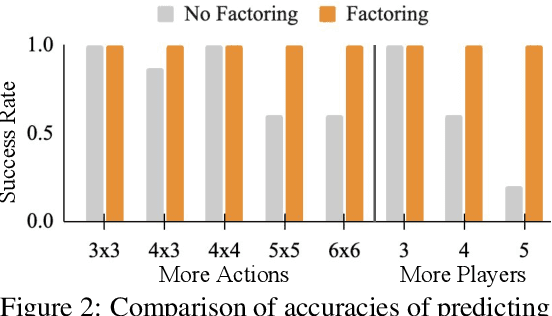

Strategic reasoning enables agents to cooperate, communicate, and compete with other agents in diverse situations. Existing approaches to solving strategic games rely on extensive training, yielding strategies that do not generalize to new scenarios or games without retraining. Large Language Models (LLMs), with their ability to comprehend and generate complex, context-rich language, could prove powerful as tools for strategic gameplay. This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstrations of reasoning about states, values, and beliefs to prompt the model. Using extensive variations of simple matrix games, we show that strategies that are derived based on systematically generated prompts generalize almost perfectly to new game structures, alternate objectives, and hidden information. Additionally, we demonstrate our approach can lead to human-like negotiation strategies in realistic scenarios without any extra training or fine-tuning. Our results highlight the ability of LLMs, guided by systematic reasoning demonstrations, to adapt and excel in diverse strategic scenarios.
Clip21: Error Feedback for Gradient Clipping
May 30, 2023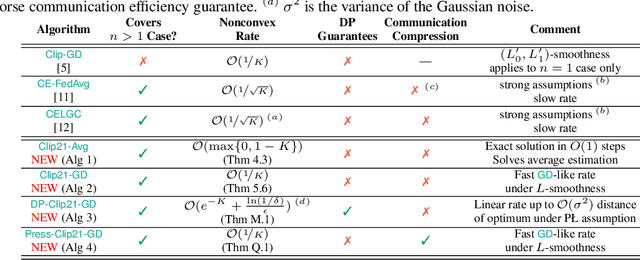
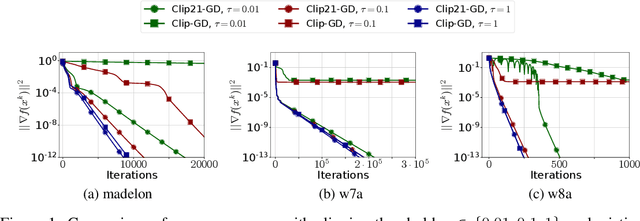
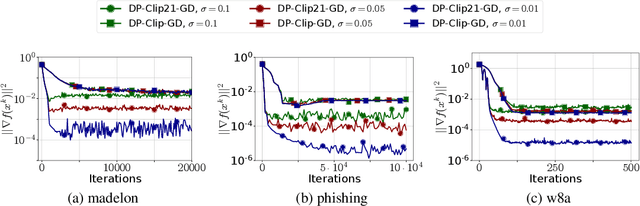
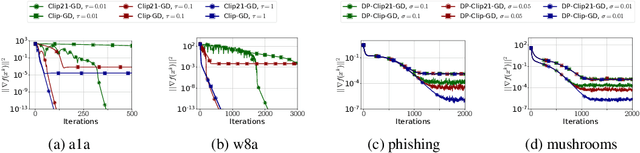
Motivated by the increasing popularity and importance of large-scale training under differential privacy (DP) constraints, we study distributed gradient methods with gradient clipping, i.e., clipping applied to the gradients computed from local information at the nodes. While gradient clipping is an essential tool for injecting formal DP guarantees into gradient-based methods [1], it also induces bias which causes serious convergence issues specific to the distributed setting. Inspired by recent progress in the error-feedback literature which is focused on taming the bias/error introduced by communication compression operators such as Top-$k$ [2], and mathematical similarities between the clipping operator and contractive compression operators, we design Clip21 -- the first provably effective and practically useful error feedback mechanism for distributed methods with gradient clipping. We prove that our method converges at the same $\mathcal{O}\left(\frac{1}{K}\right)$ rate as distributed gradient descent in the smooth nonconvex regime, which improves the previous best $\mathcal{O}\left(\frac{1}{\sqrt{K}}\right)$ rate which was obtained under significantly stronger assumptions. Our method converges significantly faster in practice than competing methods.
VL-Fields: Towards Language-Grounded Neural Implicit Spatial Representations
May 21, 2023

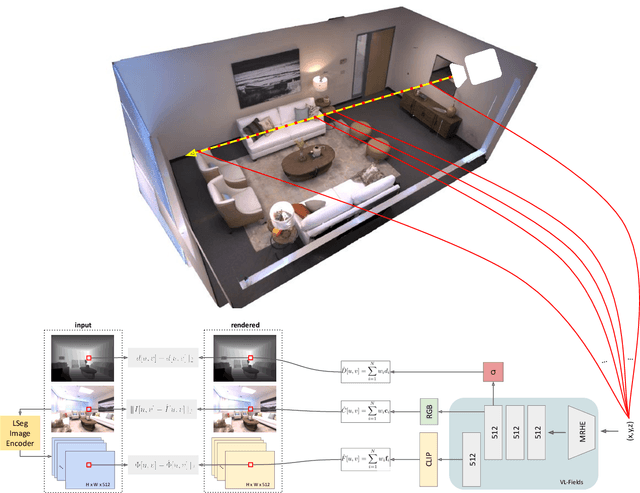
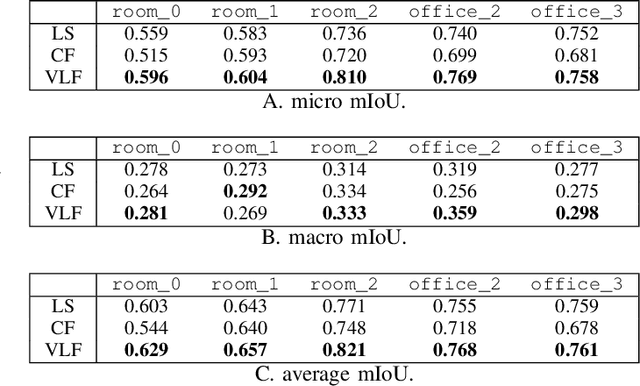
We present Visual-Language Fields (VL-Fields), a neural implicit spatial representation that enables open-vocabulary semantic queries. Our model encodes and fuses the geometry of a scene with vision-language trained latent features by distilling information from a language-driven segmentation model. VL-Fields is trained without requiring any prior knowledge of the scene object classes, which makes it a promising representation for the field of robotics. Our model outperformed the similar CLIP-Fields model in the task of semantic segmentation by almost 10%.