 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UKP-SQuARE: An Interactive Tool for Teaching Question Answering
Jun 02, 2023
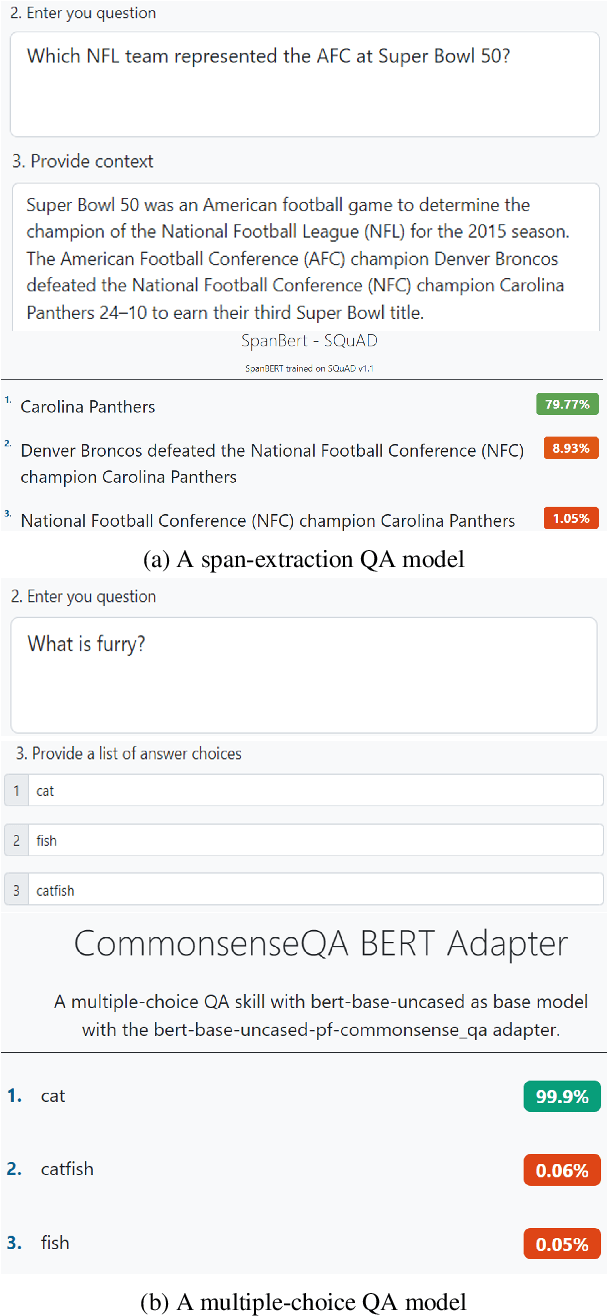
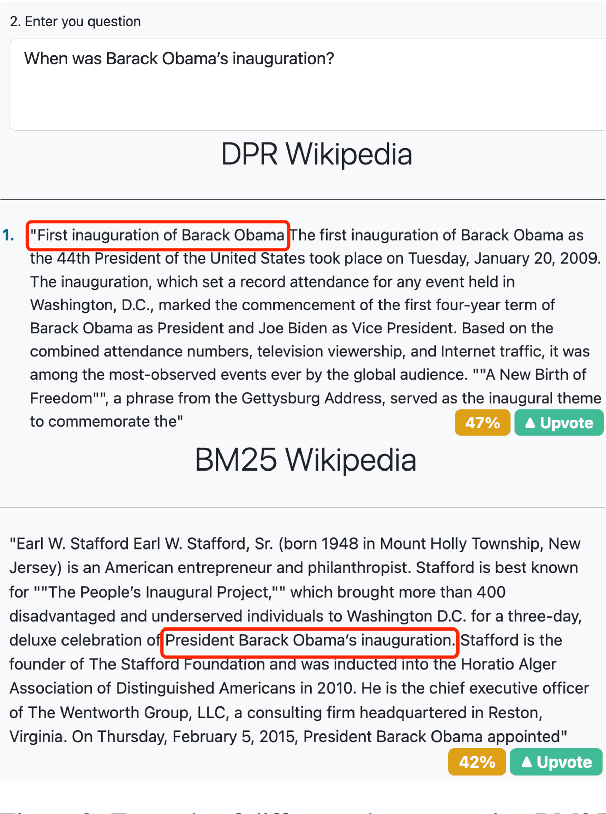


The exponential growth of question answering (QA) has made it an indispensable topic in any Natural Language Processing (NLP) course. Additionally, the breadth of QA derived from this exponential growth makes it an ideal scenario for teaching related NLP topics such as information retrieval, explainability, and adversarial attacks among others. In this paper, we introduce UKP-SQuARE as a platform for QA education. This platform provides an interactive environment where students can run, compare, and analyze various QA models from different perspectives, such as general behavior, explainability, and robustness. Therefore, students can get a first-hand experience in different QA techniques during the class. Thanks to this, we propose a learner-centered approach for QA education in which students proactively learn theoretical concepts and acquire problem-solving skills through interactive exploration, experimentation, and practical assignments, rather than solely relying on traditional lectures. To evaluate the effectiveness of UKP-SQuARE in teaching scenarios, we adopted it in a postgraduate NLP course and surveyed the students after the course. Their positive feedback shows the platform's effectiveness in their course and invites a wider adoption.
Counting Crowds in Bad Weather
Jun 02, 2023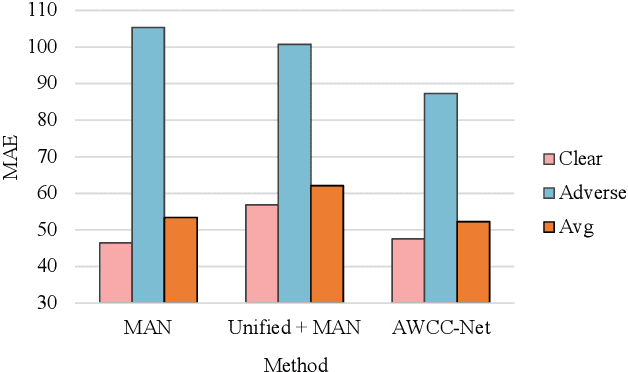
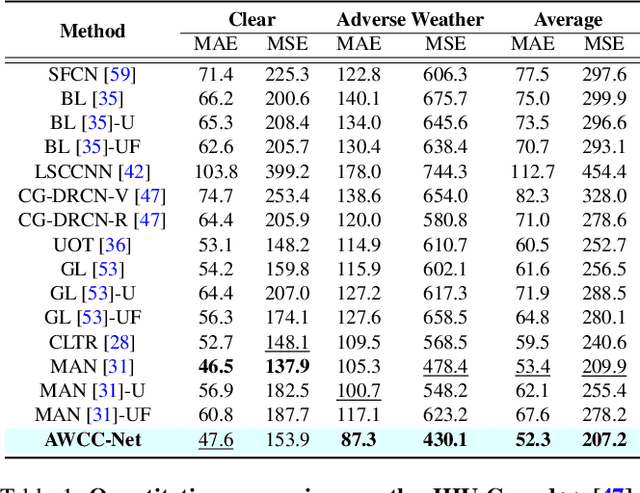
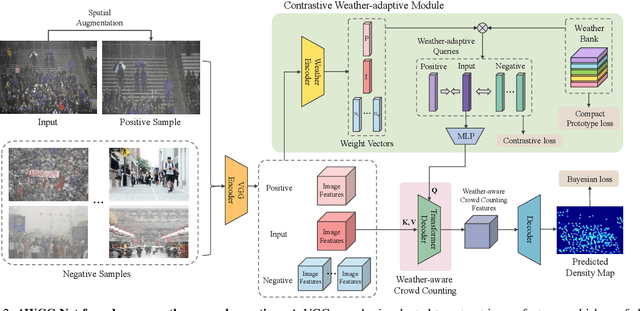
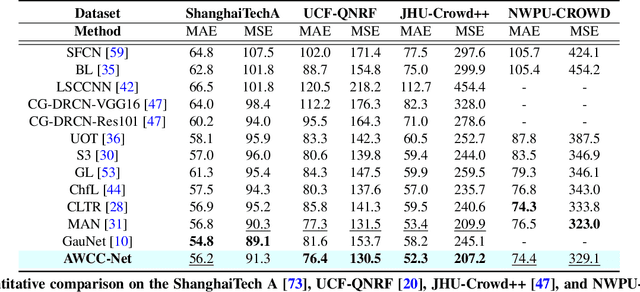
Crowd counting has recently attracted significant attention in the field of computer vision due to its wide applications to image understanding. Numerous methods have been proposed and achieved state-of-the-art performance for real-world tasks. However, existing approaches do not perform well under adverse weather such as haze, rain, and snow since the visual appearances of crowds in such scenes are drastically different from those images in clear weather of typical datasets. In this paper, we propose a method for robust crowd counting in adverse weather scenarios. Instead of using a two-stage approach that involves image restoration and crowd counting modules, our model learns effective features and adaptive queries to account for large appearance variations. With these weather queries, the proposed model can learn the weather information according to the degradation of the input image and optimize with the crowd counting module simultaneously. Experimental results show that the proposed algorithm is effective in counting crowds under different weather types on benchmark datasets. The source code and trained models will be made available to the public.
Unsupervised Statistical Feature-Guided Diffusion Model for Sensor-based Human Activity Recognition
May 30, 2023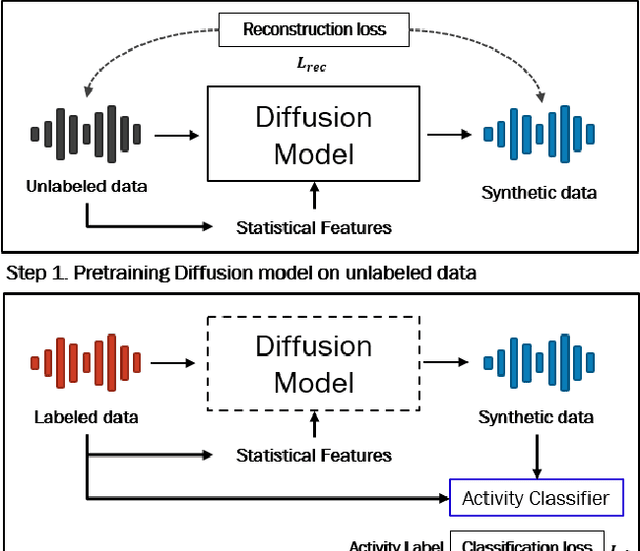
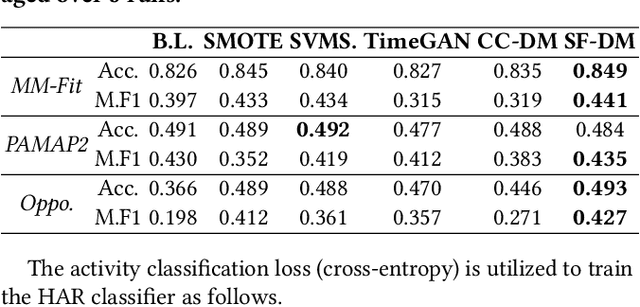
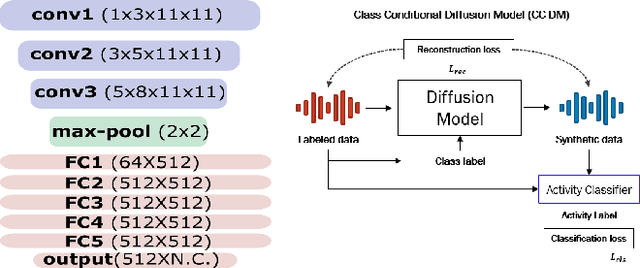
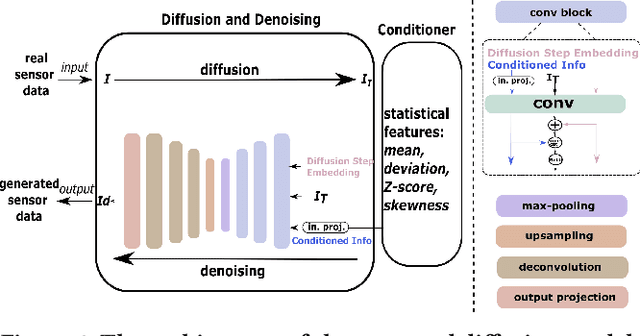
Recognizing human activities from sensor data is a vital task in various domains, but obtaining diverse and labeled sensor data remains challenging and costly. In this paper, we propose an unsupervised statistical feature-guided diffusion model for sensor-based human activity recognition. The proposed method aims to generate synthetic time-series sensor data without relying on labeled data, addressing the scarcity and annotation difficulties associated with real-world sensor data. By conditioning the diffusion model on statistical information such as mean, standard deviation, Z-score, and skewness, we generate diverse and representative synthetic sensor data. We conducted experiments on public human activity recognition datasets and compared the proposed method to conventional oversampling methods and state-of-the-art generative adversarial network methods. The experimental results demonstrate that the proposed method can improve the performance of human activity recognition and outperform existing techniques.
Learning Perturbations to Explain Time Series Predictions
May 30, 2023Explaining predictions based on multivariate time series data carries the additional difficulty of handling not only multiple features, but also time dependencies. It matters not only what happened, but also when, and the same feature could have a very different impact on a prediction depending on this time information. Previous work has used perturbation-based saliency methods to tackle this issue, perturbing an input using a trainable mask to discover which features at which times are driving the predictions. However these methods introduce fixed perturbations, inspired from similar methods on static data, while there seems to be little motivation to do so on temporal data. In this work, we aim to explain predictions by learning not only masks, but also associated perturbations. We empirically show that learning these perturbations significantly improves the quality of these explanations on time series data.
Knowledge Refinement via Interaction Between Search Engines and Large Language Models
May 21, 2023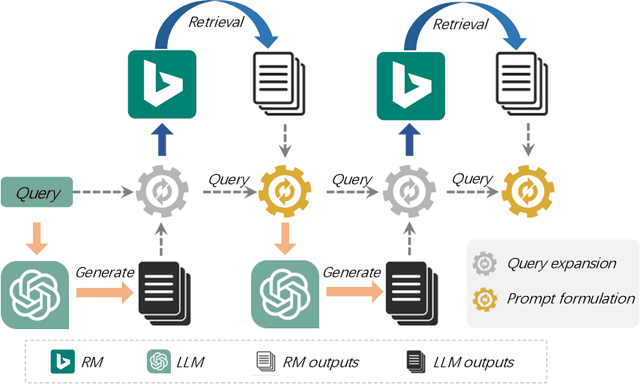
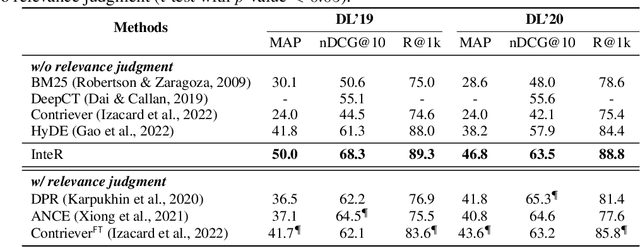
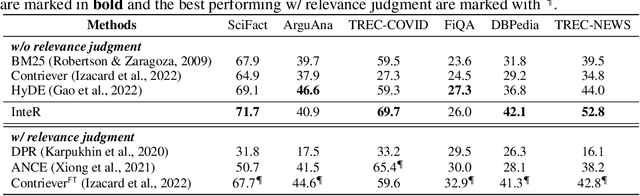
Information retrieval (IR) plays a crucial role in locating relevant resources from vast amounts of data, and its applications have evolved from traditional knowledge bases to modern search engines (SEs). The emergence of large language models (LLMs) has further revolutionized the IR field by enabling users to interact with search systems in natural language. In this paper, we explore the advantages and disadvantages of LLMs and SEs, highlighting their respective strengths in understanding user-issued queries and retrieving up-to-date information. To leverage the benefits of both paradigms while circumventing their limitations, we propose InteR, a novel framework that facilitates knowledge refinement through interaction between SEs and LLMs. InteR allows SEs to expand knowledge in queries using LLM-generated knowledge collections and enables LLMs to enhance prompt formulation using SE-retrieved documents. This iterative refinement process augments the inputs of SEs and LLMs, leading to more accurate retrieval. Experiments on large-scale retrieval benchmarks involving web search and low-resource retrieval tasks demonstrate that InteR achieves overall superior zero-shot retrieval performance compared to state-of-the-art methods, even those using relevance judgment. Source code is available at https://github.com/Cyril-JZ/InteR
High-Dimensional Smoothed Entropy Estimation via Dimensionality Reduction
May 11, 2023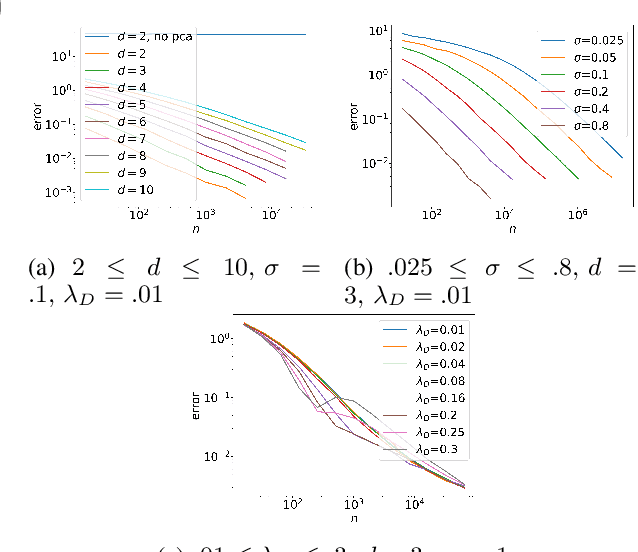
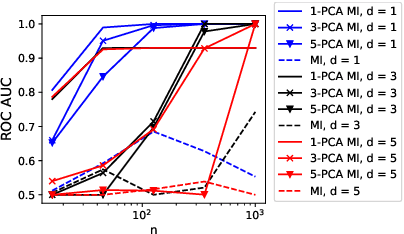
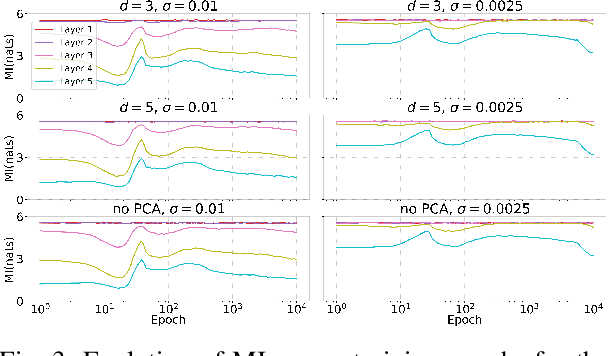
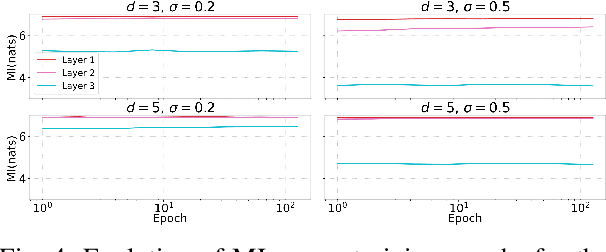
We study the problem of overcoming exponential sample complexity in differential entropy estimation under Gaussian convolutions. Specifically, we consider the estimation of the differential entropy $h(X+Z)$ via $n$ independently and identically distributed samples of $X$, where $X$ and $Z$ are independent $D$-dimensional random variables with $X$ sub-Gaussian with bounded second moment and $Z\sim\mathcal{N}(0,\sigma^2I_D)$. Under the absolute-error loss, the above problem has a parametric estimation rate of $\frac{c^D}{\sqrt{n}}$, which is exponential in data dimension $D$ and often problematic for applications. We overcome this exponential sample complexity by projecting $X$ to a low-dimensional space via principal component analysis (PCA) before the entropy estimation, and show that the asymptotic error overhead vanishes as the unexplained variance of the PCA vanishes. This implies near-optimal performance for inherently low-dimensional structures embedded in high-dimensional spaces, including hidden-layer outputs of deep neural networks (DNN), which can be used to estimate mutual information (MI) in DNNs. We provide numerical results verifying the performance of our PCA approach on Gaussian and spiral data. We also apply our method to analysis of information flow through neural network layers (c.f. information bottleneck), with results measuring mutual information in a noisy fully connected network and a noisy convolutional neural network (CNN) for MNIST classification.
Active Retrieval Augmented Generation
May 11, 2023

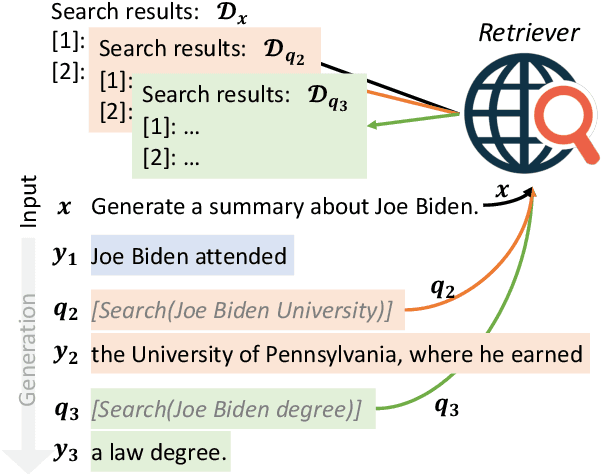
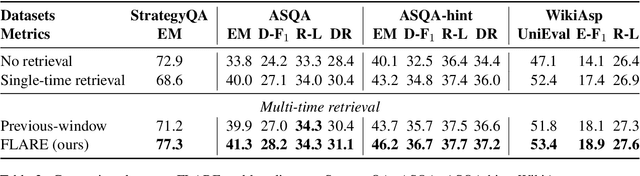
Despite the remarkable ability of large language models (LMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output. Augmenting LMs by retrieving information from external knowledge resources is one promising solution. Most existing retrieval-augmented LMs employ a retrieve-and-generate setup that only retrieves information once based on the input. This is limiting, however, in more general scenarios involving generation of long texts, where continually gathering information throughout the generation process is essential. There have been some past efforts to retrieve information multiple times while generating outputs, which mostly retrieve documents at fixed intervals using the previous context as queries. In this work, we provide a generalized view of active retrieval augmented generation, methods that actively decide when and what to retrieve across the course of the generation. We propose Forward-Looking Active REtrieval augmented generation (FLARE), a generic retrieval-augmented generation method which iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilized as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens. We test FLARE along with baselines comprehensively over 4 long-form knowledge-intensive generation tasks/datasets. FLARE achieves superior or competitive performance on all tasks, demonstrating the effectiveness of our method. Code and datasets are available at https://github.com/jzbjyb/FLARE.
Mutual Information Learned Regressor: an Information-theoretic Viewpoint of Training Regression Systems
Nov 23, 2022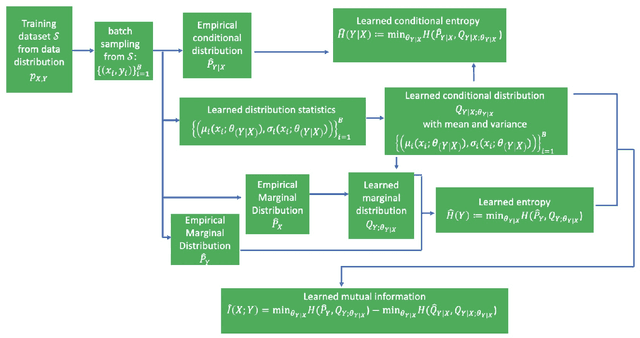

As one of the central tasks in machine learning, regression finds lots of applications in different fields. An existing common practice for solving regression problems is the mean square error (MSE) minimization approach or its regularized variants which require prior knowledge about the models. Recently, Yi et al., proposed a mutual information based supervised learning framework where they introduced a label entropy regularization which does not require any prior knowledge. When applied to classification tasks and solved via a stochastic gradient descent (SGD) optimization algorithm, their approach achieved significant improvement over the commonly used cross entropy loss and its variants. However, they did not provide a theoretical convergence analysis of the SGD algorithm for the proposed formulation. Besides, applying the framework to regression tasks is nontrivial due to the potentially infinite support set of the label. In this paper, we investigate the regression under the mutual information based supervised learning framework. We first argue that the MSE minimization approach is equivalent to a conditional entropy learning problem, and then propose a mutual information learning formulation for solving regression problems by using a reparameterization technique. For the proposed formulation, we give the convergence analysis of the SGD algorithm for solving it in practice. Finally, we consider a multi-output regression data model where we derive the generalization performance lower bound in terms of the mutual information associated with the underlying data distribution. The result shows that the high dimensionality can be a bless instead of a curse, which is controlled by a threshold. We hope our work will serve as a good starting point for further research on the mutual information based regression.
SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts
Jun 03, 2023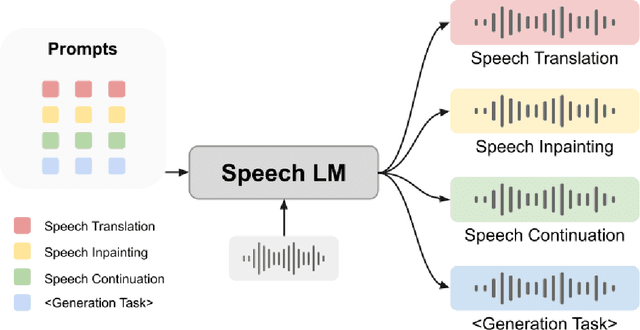

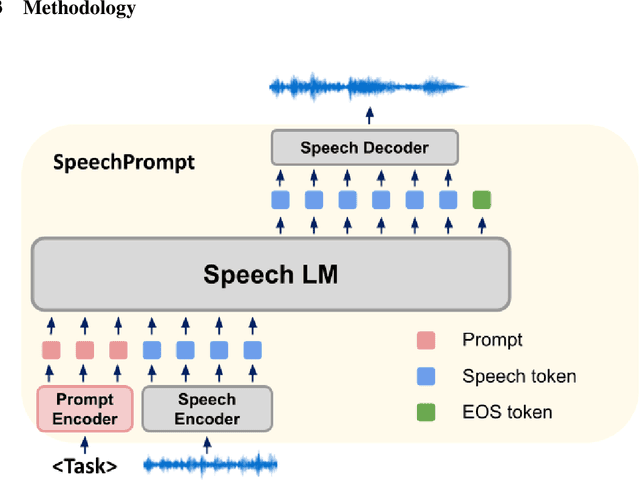
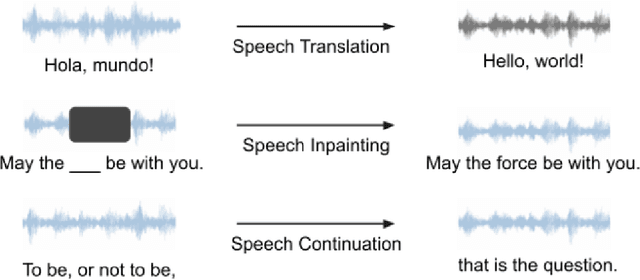
Large language models (LLMs) have gained considerable attention for Artificial Intelligence Generated Content (AIGC), particularly with the emergence of ChatGPT. However, the direct adaptation of continuous speech to LLMs that process discrete tokens remains an unsolved challenge, hindering the application of LLMs for speech generation. The advanced speech LMs are in the corner, as that speech signals encapsulate a wealth of information, including speaker and emotion, beyond textual data alone. Prompt tuning has demonstrated notable gains in parameter efficiency and competitive performance on some speech classification tasks. However, the extent to which prompts can effectively elicit generation tasks from speech LMs remains an open question. In this paper, we present pioneering research that explores the application of prompt tuning to stimulate speech LMs for various generation tasks, within a unified framework called SpeechGen, with around 10M trainable parameters. The proposed unified framework holds great promise for efficiency and effectiveness, particularly with the imminent arrival of advanced speech LMs, which will significantly enhance the capabilities of the framework. The code and demos of SpeechGen will be available on the project website: \url{https://ga642381.github.io/SpeechPrompt/speechgen}
Mutual Information-based Generalized Category Discovery
Dec 01, 2022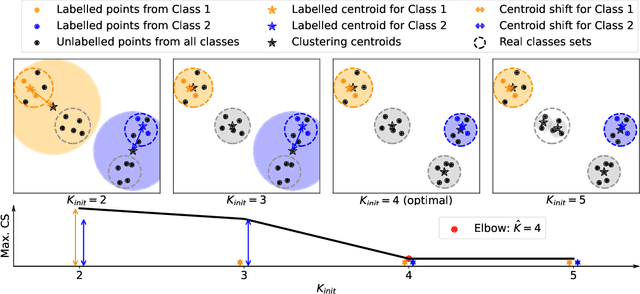

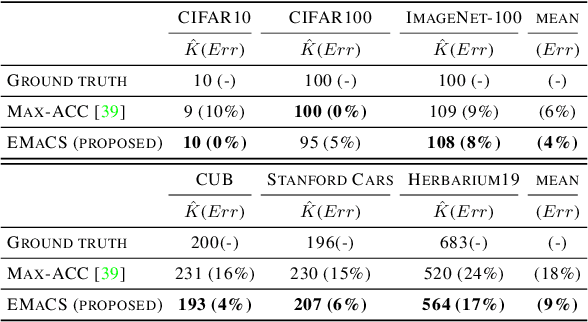
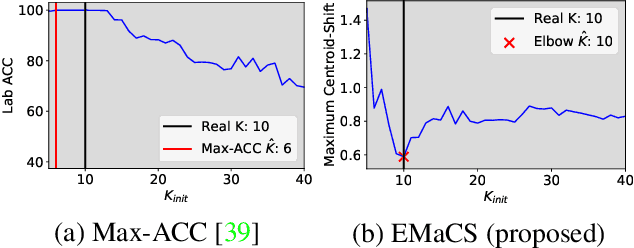
We introduce an information-maximization approach for the Generalized Category Discovery (GCD) problem. Specifically, we explore a parametric family of loss functions evaluating the mutual information between the features and the labels, and find automatically the one that maximizes the predictive performances. Furthermore, we introduce the Elbow Maximum Centroid-Shift (EMaCS) technique, which estimates the number of classes in the unlabeled set. We report comprehensive experiments, which show that our mutual information-based approach (MIB) is both versatile and highly competitive under various GCD scenarios. The gap between the proposed approach and the existing methods is significant, more so when dealing with fine-grained classification problems. Our code: \url{https://github.com/fchiaroni/Mutual-Information-Based-GCD}.