 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Machine Learning and Cybersecurity: Risks, Challenges, and Legal Implications
May 23, 2023
In July 2022, the Center for Security and Emerging Technology (CSET) at Georgetown University and the Program on Geopolitics, Technology, and Governance at the Stanford Cyber Policy Center convened a workshop of experts to examine the relationship between vulnerabilities in artificial intelligence systems and more traditional types of software vulnerabilities. Topics discussed included the extent to which AI vulnerabilities can be handled under standard cybersecurity processes, the barriers currently preventing the accurate sharing of information about AI vulnerabilities, legal issues associated with adversarial attacks on AI systems, and potential areas where government support could improve AI vulnerability management and mitigation. This report is meant to accomplish two things. First, it provides a high-level discussion of AI vulnerabilities, including the ways in which they are disanalogous to other types of vulnerabilities, and the current state of affairs regarding information sharing and legal oversight of AI vulnerabilities. Second, it attempts to articulate broad recommendations as endorsed by the majority of participants at the workshop.
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023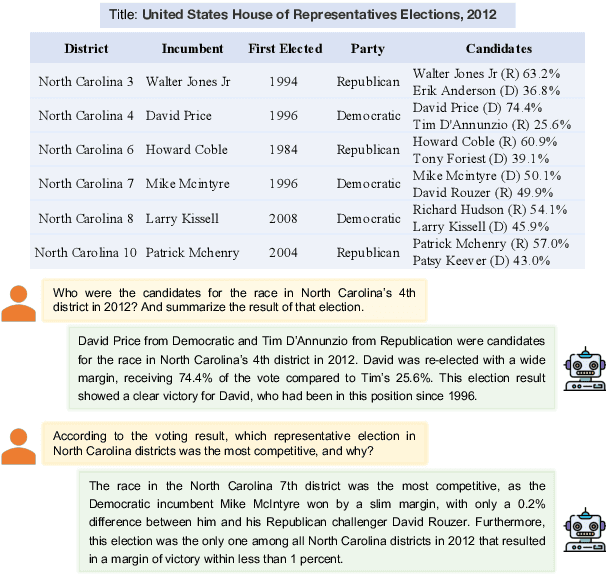
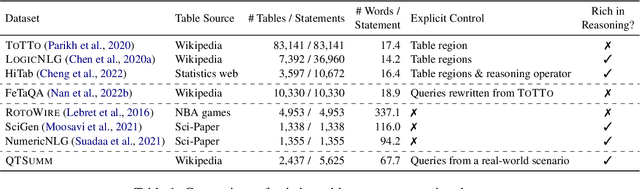

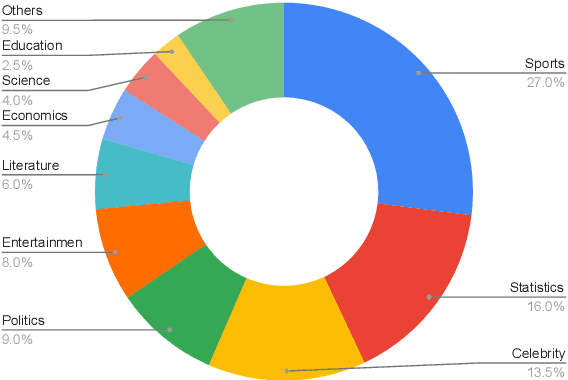
People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.
Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment
May 23, 2023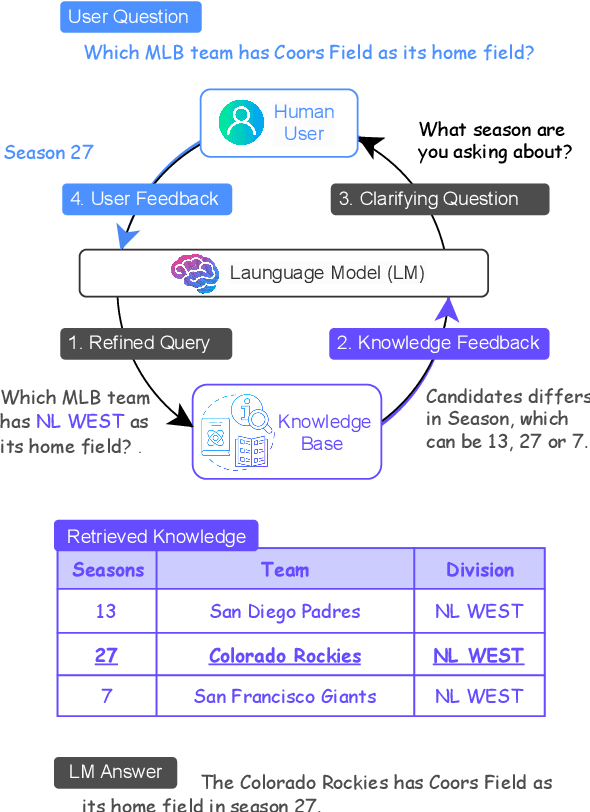
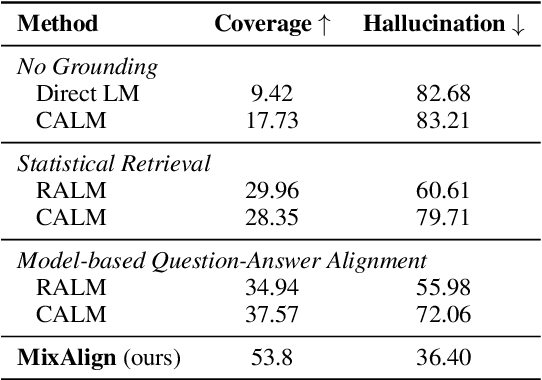
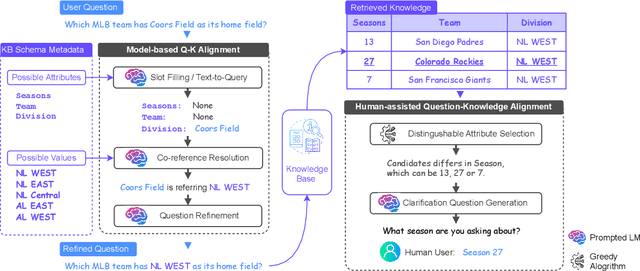
Despite the remarkable recent advances in language models, they still struggle with the hallucination problem and can generate misleading and unsupported responses. A common approach to mitigate the hallucination issue is retrieving and incorporating supporting evidence from a knowledge base. However, user questions usually do not align well with the stored knowledge, as they are unaware of the information available before asking questions. This misalignment can limit the language model's ability to locate and utilize the knowledge, potentially forcing it to hallucinate by ignoring or overriding the retrieved evidence. To address this issue, we introduce MixAlign, a framework that interacts with both the user and the knowledge base to obtain and integrate clarifications on how the user question relates to the stored information. MixAlign employs a language model to achieve automatic question-knowledge alignment and, if necessary, further enhances this alignment through human user clarifications. Experimental results demonstrate significant improvements over state-of-the-art methods, showcasing the effectiveness of MixAlign in mitigating language model hallucination.
Efficient Multi-Scale Attention Module with Cross-Spatial Learning
May 23, 2023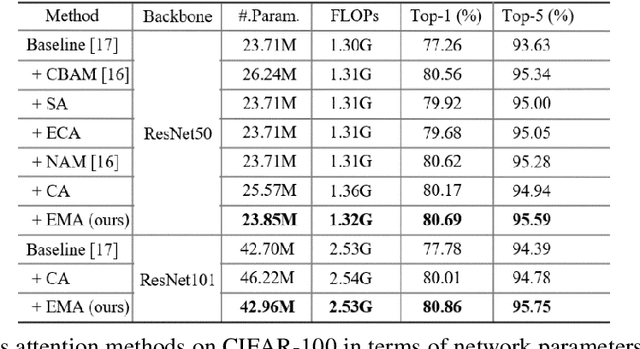
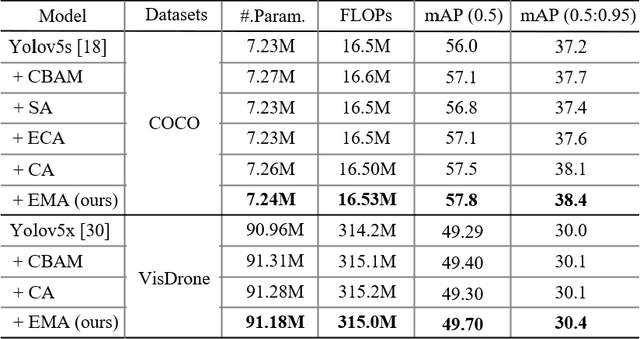
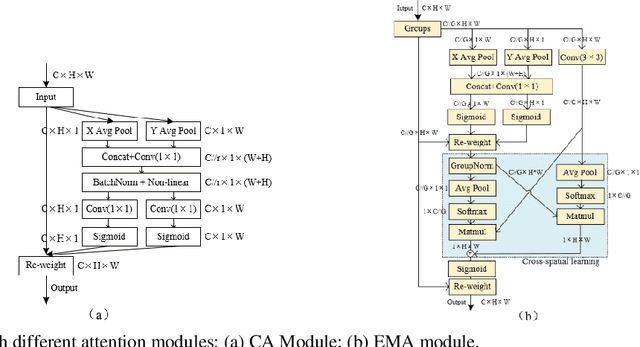
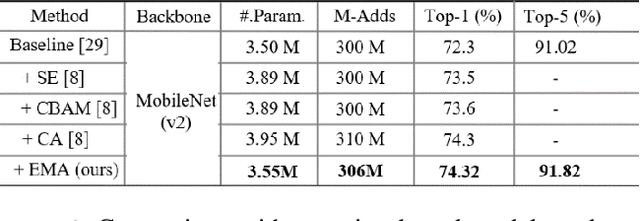
Remarkable effectiveness of the channel or spatial attention mechanisms for producing more discernible feature representation are illustrated in various computer vision tasks. However, modeling the cross-channel relationships with channel dimensionality reduction may bring side effect in extracting deep visual representations. In this paper, a novel efficient multi-scale attention (EMA) module is proposed. Focusing on retaining the information on per channel and decreasing the computational overhead, we reshape the partly channels into the batch dimensions and group the channel dimensions into multiple sub-features which make the spatial semantic features well-distributed inside each feature group. Specifically, apart from encoding the global information to re-calibrate the channel-wise weight in each parallel branch, the output features of the two parallel branches are further aggregated by a cross-dimension interaction for capturing pixel-level pairwise relationship. We conduct extensive ablation studies and experiments on image classification and object detection tasks with popular benchmarks (e.g., CIFAR-100, ImageNet-1k, MS COCO and VisDrone2019) for evaluating its performance.
Images in Language Space: Exploring the Suitability of Large Language Models for Vision & Language Tasks
May 23, 2023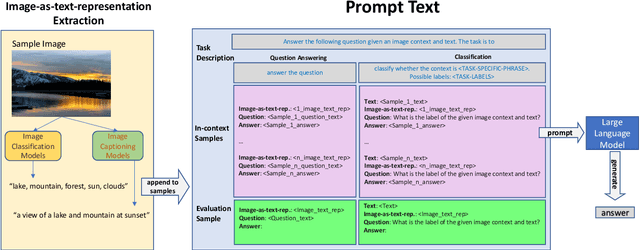
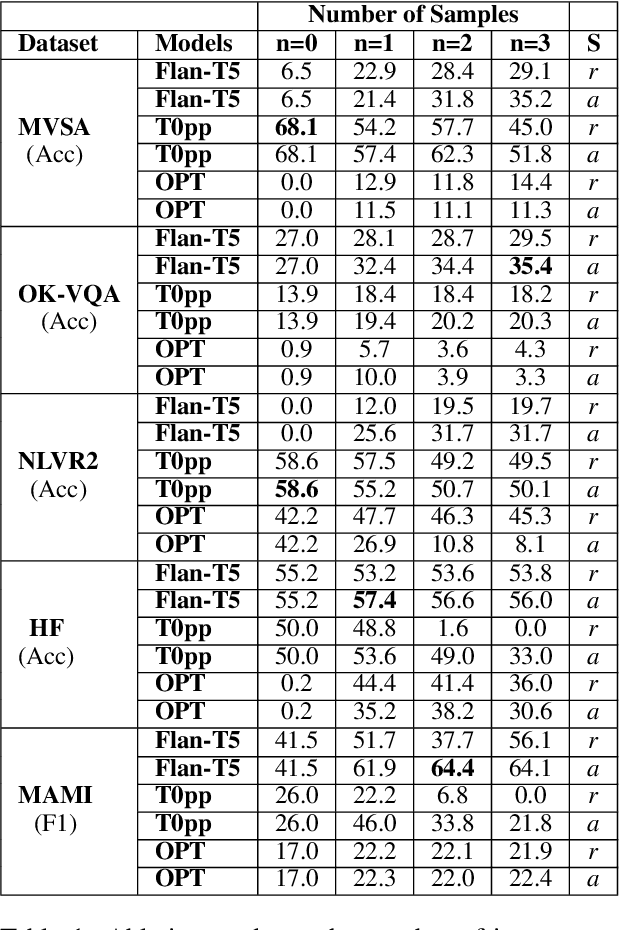
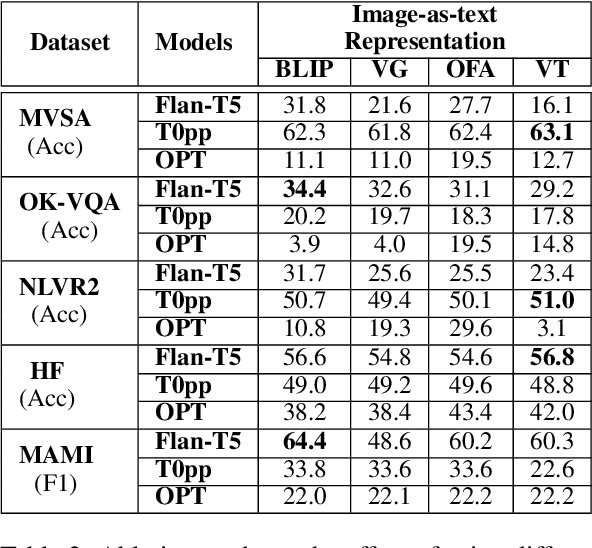
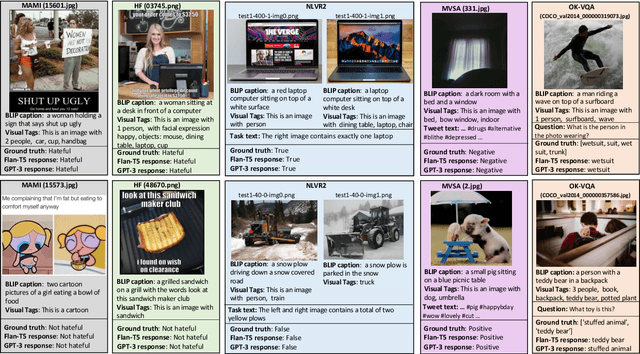
Large language models have demonstrated robust performance on various language tasks using zero-shot or few-shot learning paradigms. While being actively researched, multimodal models that can additionally handle images as input have yet to catch up in size and generality with language-only models. In this work, we ask whether language-only models can be utilised for tasks that require visual input -- but also, as we argue, often require a strong reasoning component. Similar to some recent related work, we make visual information accessible to the language model using separate verbalisation models. Specifically, we investigate the performance of open-source, open-access language models against GPT-3 on five vision-language tasks when given textually-encoded visual information. Our results suggest that language models are effective for solving vision-language tasks even with limited samples. This approach also enhances the interpretability of a model's output by providing a means of tracing the output back through the verbalised image content.
Analyzing Leakage of Personally Identifiable Information in Language Models
Feb 01, 2023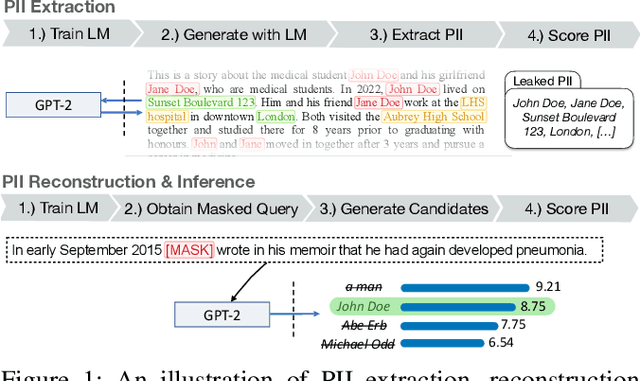

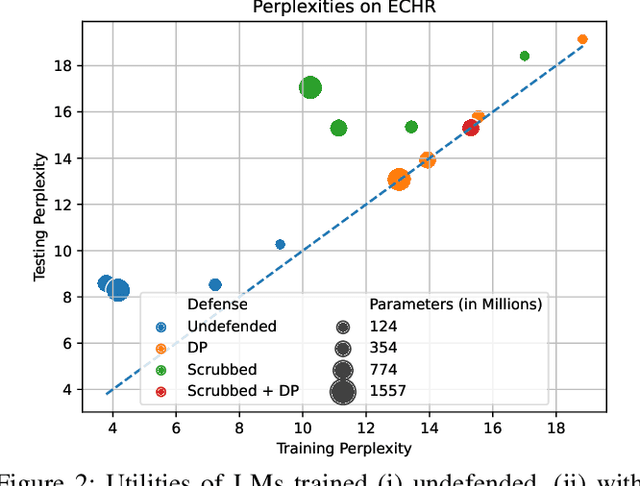

Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we propose (i) a taxonomy of PII leakage in LMs, (ii) metrics to quantify PII leakage, and (iii) attacks showing that PII leakage is a threat in practice. Our taxonomy provides rigorous game-based definitions for PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate attacks against GPT-2 models fine-tuned on three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10 times more PII sequences as existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction.
Direct Learning-Based Deep Spiking Neural Networks: A Review
Jun 04, 2023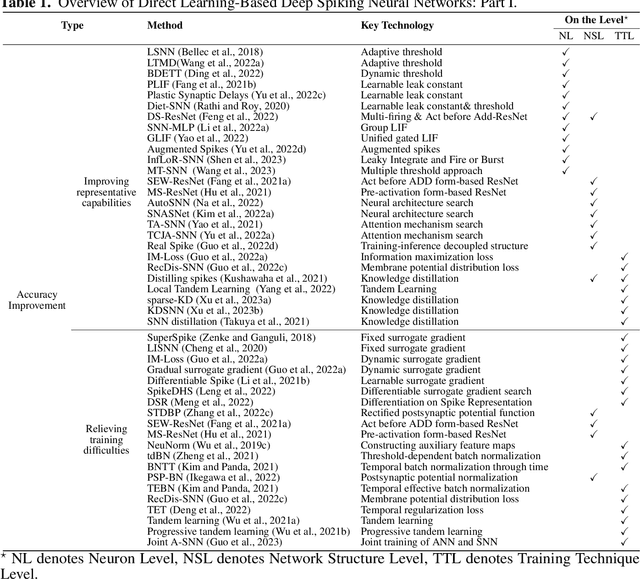
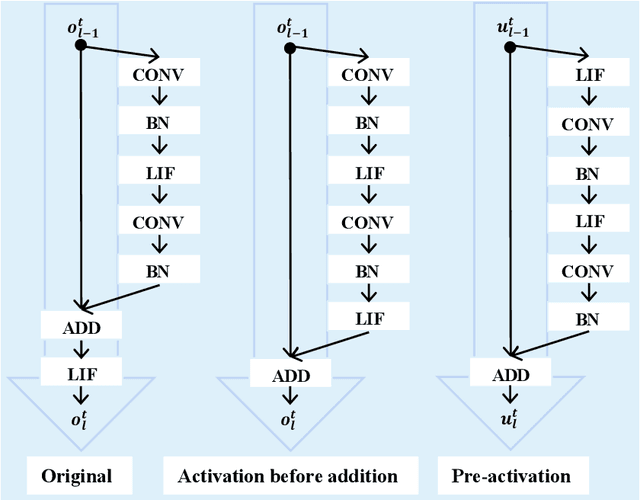
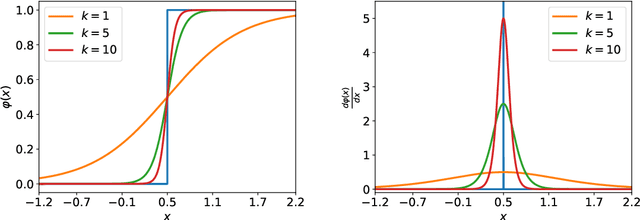
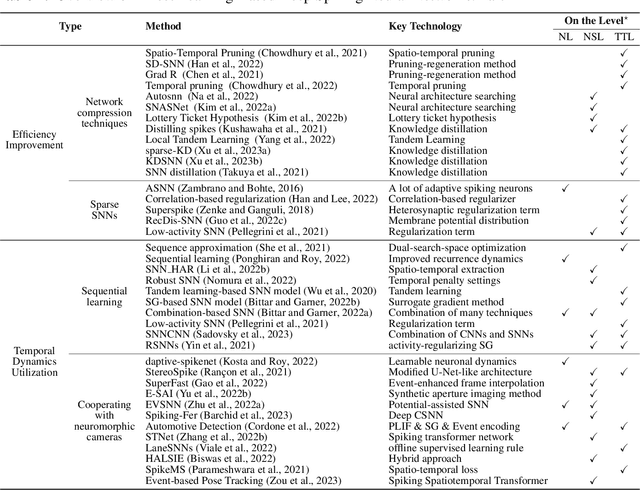
The spiking neural network (SNN), as a promising brain-inspired computational model with binary spike information transmission mechanism, rich spatially-temporal dynamics, and event-driven characteristics, has received extensive attention. However, its intricately discontinuous spike mechanism brings difficulty to the optimization of the deep SNN. Since the surrogate gradient method can greatly mitigate the optimization difficulty and shows great potential in directly training deep SNNs, a variety of direct learning-based deep SNN works have been proposed and achieved satisfying progress in recent years. In this paper, we present a comprehensive survey of these direct learning-based deep SNN works, mainly categorized into accuracy improvement methods, efficiency improvement methods, and temporal dynamics utilization methods. In addition, we also divide these categorizations into finer granularities further to better organize and introduce them. Finally, the challenges and trends that may be faced in future research are prospected.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023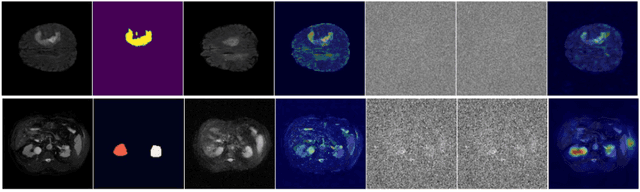
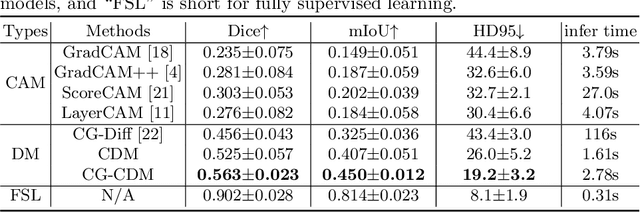
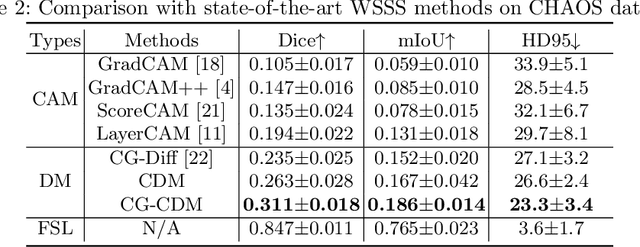

Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.
PQM: A Point Quality Evaluation Metric for Dense Maps
Jun 06, 2023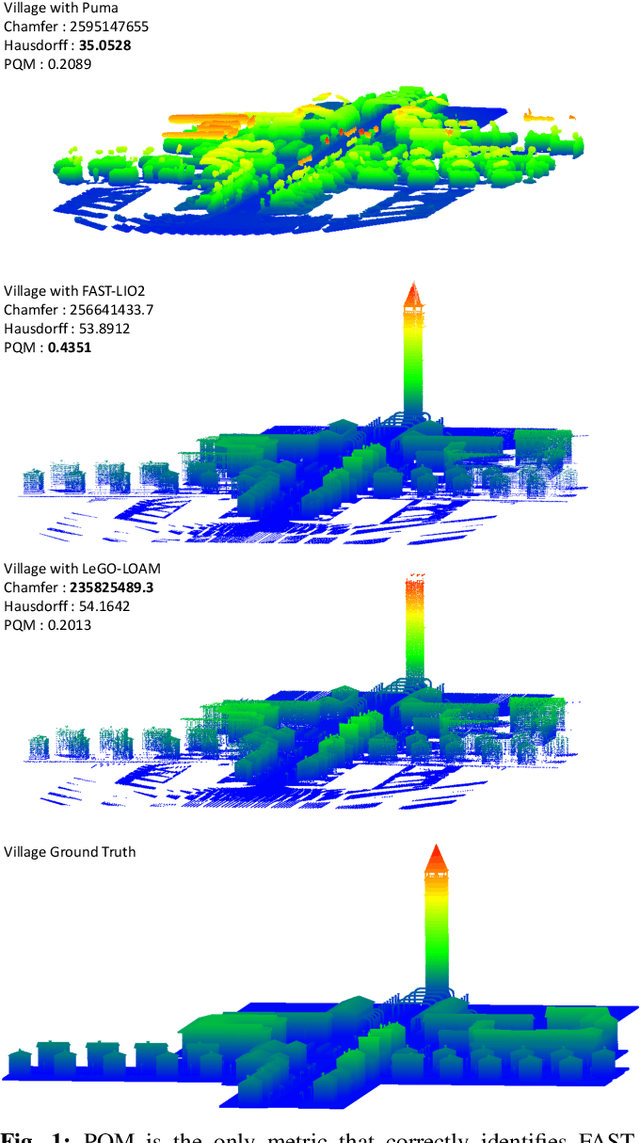
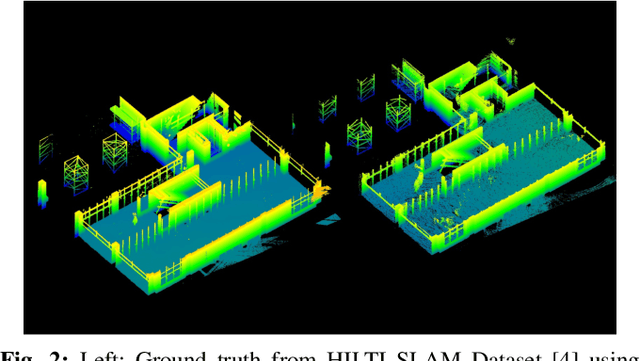
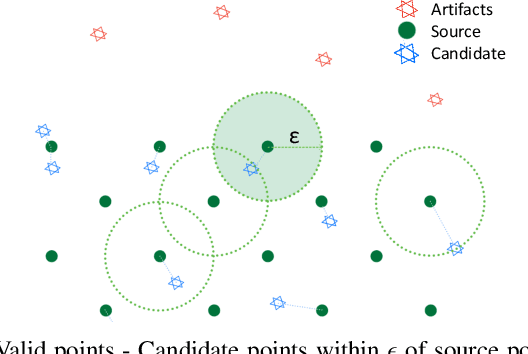

LiDAR-based mapping/reconstruction are important for various applications, but evaluating the quality of the dense maps they produce is challenging. The current methods have limitations, including the inability to capture completeness, structural information, and local variations in error. In this paper, we propose a novel point quality evaluation metric (PQM) that consists of four sub-metrics to provide a more comprehensive evaluation of point cloud quality. The completeness sub-metric evaluates the proportion of missing data, the artifact score sub-metric recognizes and characterizes artifacts, the accuracy sub-metric measures registration accuracy, and the resolution sub-metric quantifies point cloud density. Through an ablation study using a prototype dataset, we demonstrate the effectiveness of each of the sub-metrics and compare them to popular point cloud distance measures. Using three LiDAR SLAM systems to generate maps, we evaluate their output map quality and demonstrate the metrics robustness to noise and artifacts. Our implementation of PQM, datasets and detailed documentation on how to integrate with your custom dense mapping pipeline can be found at github.com/droneslab/pqm
SAM3D: Segment Anything in 3D Scenes
Jun 06, 2023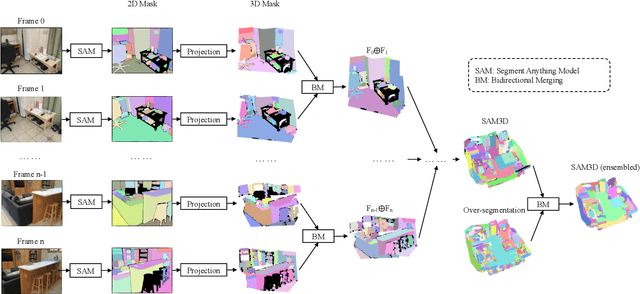
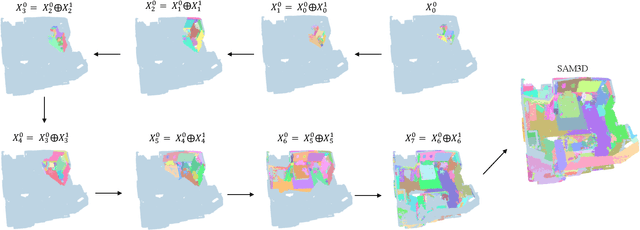
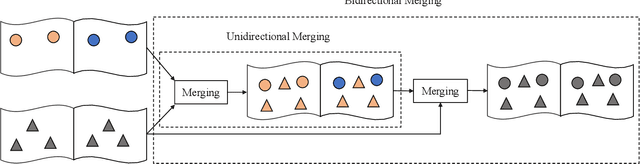
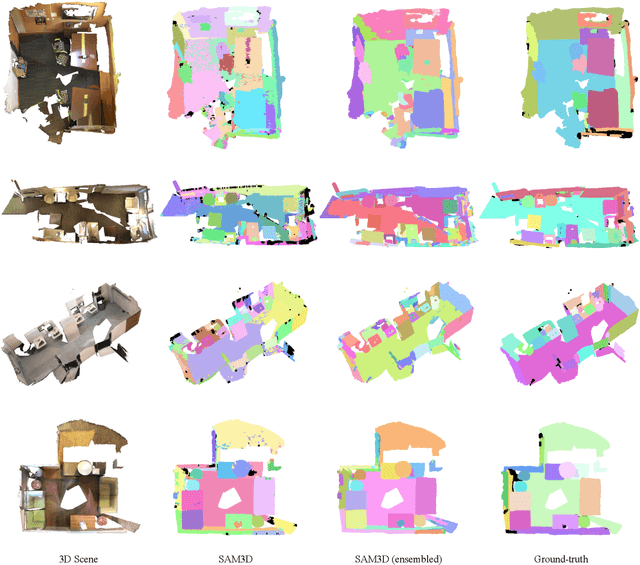
In this work, we propose SAM3D, a novel framework that is able to predict masks in 3D point clouds by leveraging the Segment-Anything Model (SAM) in RGB images without further training or finetuning. For a point cloud of a 3D scene with posed RGB images, we first predict segmentation masks of RGB images with SAM, and then project the 2D masks into the 3D points. Later, we merge the 3D masks iteratively with a bottom-up merging approach. At each step, we merge the point cloud masks of two adjacent frames with the bidirectional merging approach. In this way, the 3D masks predicted from different frames are gradually merged into the 3D masks of the whole 3D scene. Finally, we can optionally ensemble the result from our SAM3D with the over-segmentation results based on the geometric information of the 3D scenes. Our approach is experimented with ScanNet dataset and qualitative results demonstrate that our SAM3D achieves reasonable and fine-grained 3D segmentation results without any training or finetuning of SAM.