 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Image Reconstruction Game: Drawing Common Ground Through Iterative Multimodal Dialogue
Jun 01, 2026We introduce the Image Reconstruction Game, a fully automated benchmark in which a vision-language model issues corrective instructions to an image generator across multiple turns, making accumulated common ground directly observable as a rendered image. Benchmarking two Describer models crossed with two Generator models across seven image categories, we find that the describer is the dominant factor in reconstruction quality, while the generator determines whether iterative refinement helps or hurts. Mathematical and geometric images pose the greatest challenge. The describer's token budget strongly affects convergence: shorter budgets yield sparser first renderings with more room for visible improvement, while longer budgets raise absolute quality but leave less to fix. Stronger describers use a richer correction vocabulary spanning spatial, numeric, and structural categories, while weaker describers concentrate on surface properties and tend to stop after a few turns. Human validation shows that the best automated judge reaches only slight-to-fair agreement with human preferences, and automated scores require human recalibration to be used reliably.
Multi-Turn Multi-Agent Dialogue for Collaborative Reconstruction Improves VLM Performance on Spatial Reasoning, But Only Barely
May 29, 2026Robots operating in diverse environments rely on visual input to interpret objects and spatial layouts. In human-collaborative tasks, they are expected to communicate this understanding through language. Vision-language models (VLMs) support robotic tasks involving visual interpretation, question answering, and instruction following, but their capabilities in collaborative dialogue tasks requiring spatial reasoning remain underexplored. We study this gap through a collaborative structure-building task that combines visual interpretation, grounding, language-guided interaction, and action generation. We develop a framework in which VLMs use dialogue to reconstruct a target structure from visual and textual inputs. We evaluate open-weight and closed VLMs across interaction settings, input modalities, and image representations. Results show that spatial reasoning over visual representations remains difficult for the evaluated VLMs. Detailed text representations of the target yield higher reconstruction success across modality conditions, while decomposed image representations improve performance. These findings reveal limits in visual spatial grounding and grounded instruction generation for collaborative VLM agents.
Order in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
Could the Road to Grounded, Neuro-symbolic AI be Paved with Words-as-Classifiers?
Jul 08, 2025Formal, Distributional, and Grounded theories of computational semantics each have their uses and their drawbacks. There has been a shift to ground models of language by adding visual knowledge, and there has been a call to enrich models of language with symbolic methods to gain the benefits from formal, distributional, and grounded theories. In this paper, we attempt to make the case that one potential path forward in unifying all three semantic fields is paved with the words-as-classifier model, a model of word-level grounded semantics that has been incorporated into formalisms and distributional language models in the literature, and it has been well-tested within interactive dialogue settings. We review that literature, motivate the words-as-classifiers model with an appeal to recent work in cognitive science, and describe a small experiment. Finally, we sketch a model of semantics unified through words-as-classifiers.
From Templates to Natural Language: Generalization Challenges in Instruction-Tuned LLMs for Spatial Reasoning
May 20, 2025
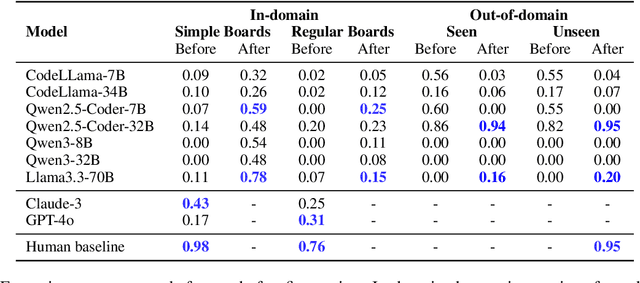


Instruction-tuned large language models (LLMs) have shown strong performance on a variety of tasks; however, generalizing from synthetic to human-authored instructions in grounded environments remains a challenge for them. In this work, we study generalization challenges in spatial grounding tasks where models interpret and translate instructions for building object arrangements on a $2.5$D grid. We fine-tune LLMs using only synthetic instructions and evaluate their performance on a benchmark dataset containing both synthetic and human-written instructions. Our results reveal that while models generalize well on simple tasks, their performance degrades significantly on more complex tasks. We present a detailed error analysis of the gaps in instruction generalization.
clem:todd: A Framework for the Systematic Benchmarking of LLM-Based Task-Oriented Dialogue System Realisations
May 08, 2025The emergence of instruction-tuned large language models (LLMs) has advanced the field of dialogue systems, enabling both realistic user simulations and robust multi-turn conversational agents. However, existing research often evaluates these components in isolation-either focusing on a single user simulator or a specific system design-limiting the generalisability of insights across architectures and configurations. In this work, we propose clem todd (chat-optimized LLMs for task-oriented dialogue systems development), a flexible framework for systematically evaluating dialogue systems under consistent conditions. clem todd enables detailed benchmarking across combinations of user simulators and dialogue systems, whether existing models from literature or newly developed ones. It supports plug-and-play integration and ensures uniform datasets, evaluation metrics, and computational constraints. We showcase clem todd's flexibility by re-evaluating existing task-oriented dialogue systems within this unified setup and integrating three newly proposed dialogue systems into the same evaluation pipeline. Our results provide actionable insights into how architecture, scale, and prompting strategies affect dialogue performance, offering practical guidance for building efficient and effective conversational AI systems.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025



Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025



We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
Plant in Cupboard, Orange on Table, Book on Shelf. Benchmarking Practical Reasoning and Situation Modelling in a Text-Simulated Situated Environment
Feb 17, 2025



Large language models (LLMs) have risen to prominence as 'chatbots' for users to interact via natural language. However, their abilities to capture common-sense knowledge make them seem promising as language-based planners of situated or embodied action as well. We have implemented a simple text-based environment -- similar to others that have before been used for reinforcement-learning of agents -- that simulates, very abstractly, a household setting. We use this environment and the detailed error-tracking capabilities we implemented for targeted benchmarking of LLMs on the problem of practical reasoning: Going from goals and observations to actions. Our findings show that environmental complexity and game restrictions hamper performance, and concise action planning is demanding for current LLMs.
Ad-hoc Concept Forming in the Game Codenames as a Means for Evaluating Large Language Models
Feb 17, 2025



This study utilizes the game Codenames as a benchmarking tool to evaluate large language models (LLMs) with respect to specific linguistic and cognitive skills. LLMs play each side of the game, where one side generates a clue word covering several target words and the other guesses those target words. We designed various experiments by controlling the choice of words (abstract vs. concrete words, ambiguous vs. monosemic) or the opponent (programmed to be faster or slower in revealing words). Recent commercial and open-weight models were compared side-by-side to find out factors affecting their performance. The evaluation reveals details about their strategies, challenging cases, and limitations of LLMs.