 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trigger in the Haystack: Extracting and Reconstructing LLM Backdoor Triggers
Feb 03, 2026Detecting whether a model has been poisoned is a longstanding problem in AI security. In this work, we present a practical scanner for identifying sleeper agent-style backdoors in causal language models. Our approach relies on two key findings: first, sleeper agents tend to memorize poisoning data, making it possible to leak backdoor examples using memory extraction techniques. Second, poisoned LLMs exhibit distinctive patterns in their output distributions and attention heads when backdoor triggers are present in the input. Guided by these observations, we develop a scalable backdoor scanning methodology that assumes no prior knowledge of the trigger or target behavior and requires only inference operations. Our scanner integrates naturally into broader defensive strategies and does not alter model performance. We show that our method recovers working triggers across multiple backdoor scenarios and a broad range of models and fine-tuning methods.
Lessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System
Oct 01, 2024



Generative Artificial Intelligence (GenAI) is becoming ubiquitous in our daily lives. The increase in computational power and data availability has led to a proliferation of both single- and multi-modal models. As the GenAI ecosystem matures, the need for extensible and model-agnostic risk identification frameworks is growing. To meet this need, we introduce the Python Risk Identification Toolkit (PyRIT), an open-source framework designed to enhance red teaming efforts in GenAI systems. PyRIT is a model- and platform-agnostic tool that enables red teamers to probe for and identify novel harms, risks, and jailbreaks in multimodal generative AI models. Its composable architecture facilitates the reuse of core building blocks and allows for extensibility to future models and modalities. This paper details the challenges specific to red teaming generative AI systems, the development and features of PyRIT, and its practical applications in real-world scenarios.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024



Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.
The Human Factor in AI Red Teaming: Perspectives from Social and Collaborative Computing
Jul 10, 2024Rapid progress in general-purpose AI has sparked significant interest in "red teaming," a practice of adversarial testing originating in military and cybersecurity applications. AI red teaming raises many questions about the human factor, such as how red teamers are selected, biases and blindspots in how tests are conducted, and harmful content's psychological effects on red teamers. A growing body of HCI and CSCW literature examines related practices-including data labeling, content moderation, and algorithmic auditing. However, few, if any, have investigated red teaming itself. This workshop seeks to consider the conceptual and empirical challenges associated with this practice, often rendered opaque by non-disclosure agreements. Future studies may explore topics ranging from fairness to mental health and other areas of potential harm. We aim to facilitate a community of researchers and practitioners who can begin to meet these challenges with creativity, innovation, and thoughtful reflection.
Adversarial Machine Learning and Cybersecurity: Risks, Challenges, and Legal Implications
May 23, 2023In July 2022, the Center for Security and Emerging Technology (CSET) at Georgetown University and the Program on Geopolitics, Technology, and Governance at the Stanford Cyber Policy Center convened a workshop of experts to examine the relationship between vulnerabilities in artificial intelligence systems and more traditional types of software vulnerabilities. Topics discussed included the extent to which AI vulnerabilities can be handled under standard cybersecurity processes, the barriers currently preventing the accurate sharing of information about AI vulnerabilities, legal issues associated with adversarial attacks on AI systems, and potential areas where government support could improve AI vulnerability management and mitigation. This report is meant to accomplish two things. First, it provides a high-level discussion of AI vulnerabilities, including the ways in which they are disanalogous to other types of vulnerabilities, and the current state of affairs regarding information sharing and legal oversight of AI vulnerabilities. Second, it attempts to articulate broad recommendations as endorsed by the majority of participants at the workshop.
Adversarial for Good? How the Adversarial ML Community's Values Impede Socially Beneficial Uses of Attacks
Jul 11, 2021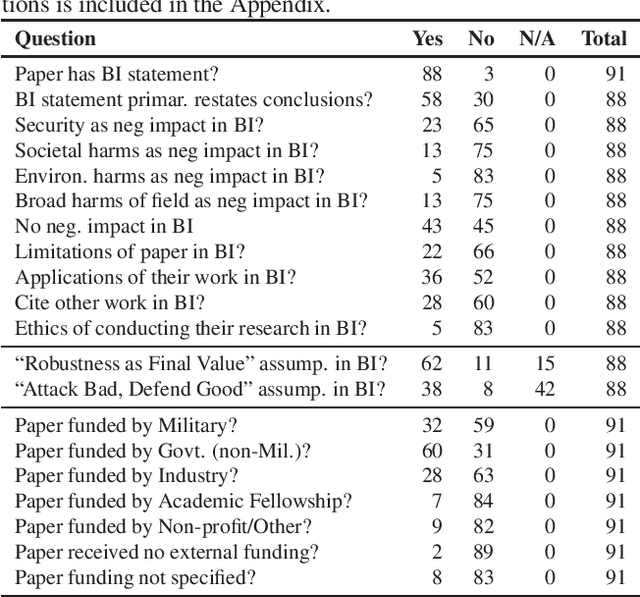
Attacks from adversarial machine learning (ML) have the potential to be used "for good": they can be used to run counter to the existing power structures within ML, creating breathing space for those who would otherwise be the targets of surveillance and control. But most research on adversarial ML has not engaged in developing tools for resistance against ML systems. Why? In this paper, we review the broader impact statements that adversarial ML researchers wrote as part of their NeurIPS 2020 papers and assess the assumptions that authors have about the goals of their work. We also collect information about how authors view their work's impact more generally. We find that most adversarial ML researchers at NeurIPS hold two fundamental assumptions that will make it difficult for them to consider socially beneficial uses of attacks: (1) it is desirable to make systems robust, independent of context, and (2) attackers of systems are normatively bad and defenders of systems are normatively good. That is, despite their expressed and supposed neutrality, most adversarial ML researchers believe that the goal of their work is to secure systems, making it difficult to conceptualize and build tools for disrupting the status quo.
Legal Risks of Adversarial Machine Learning Research
Jun 29, 2020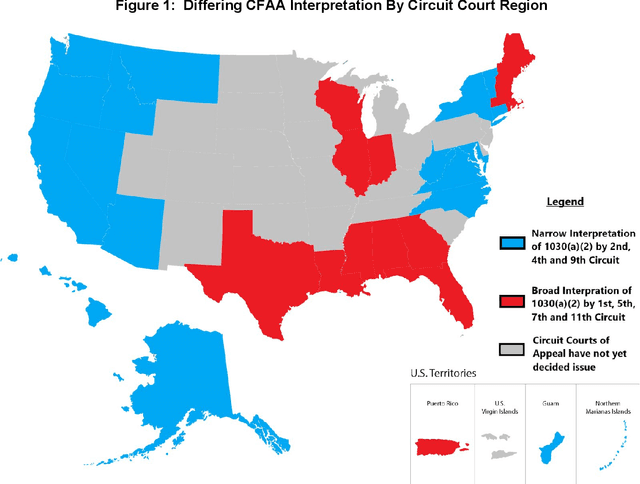
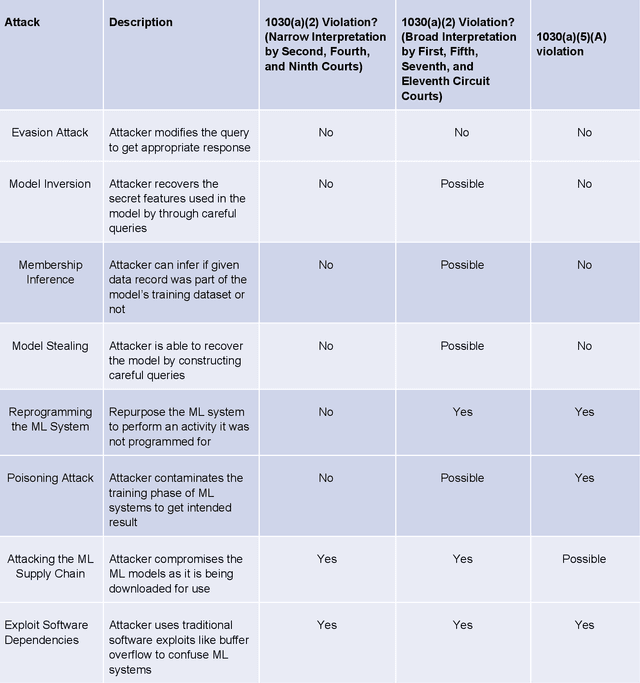
Adversarial Machine Learning is booming with ML researchers increasingly targeting commercial ML systems such as those used in Facebook, Tesla, Microsoft, IBM, Google to demonstrate vulnerabilities. In this paper, we ask, "What are the potential legal risks to adversarial ML researchers when they attack ML systems?" Studying or testing the security of any operational system potentially runs afoul the Computer Fraud and Abuse Act (CFAA), the primary United States federal statute that creates liability for hacking. We claim that Adversarial ML research is likely no different. Our analysis show that because there is a split in how CFAA is interpreted, aspects of adversarial ML attacks, such as model inversion, membership inference, model stealing, reprogramming the ML system and poisoning attacks, may be sanctioned in some jurisdictions and not penalized in others. We conclude with an analysis predicting how the US Supreme Court may resolve some present inconsistencies in the CFAA's application in Van Buren v. United States, an appeal expected to be decided in 2021. We argue that the court is likely to adopt a narrow construction of the CFAA, and that this will actually lead to better adversarial ML security outcomes in the long term.
Politics of Adversarial Machine Learning
Feb 19, 2020In addition to their security properties, adversarial machine-learning attacks and defenses have political dimensions. They enable or foreclose certain options for both the subjects of the machine learning systems and for those who deploy them, creating risks for civil liberties and human rights. In this paper, we draw on insights from science and technology studies, anthropology, and human rights literature, to inform how defenses against adversarial attacks can be used to suppress dissent and limit attempts to investigate machine learning systems. To make this concrete, we use real-world examples of how attacks such as perturbation, model inversion, or membership inference can be used for socially desirable ends. Although the predictions of this analysis may seem dire, there is hope. Efforts to address human rights concerns in the commercial spyware industry provide guidance for similar measures to ensure ML systems serve democratic, not authoritarian ends
Adversarial Machine Learning -- Industry Perspectives
Feb 04, 2020
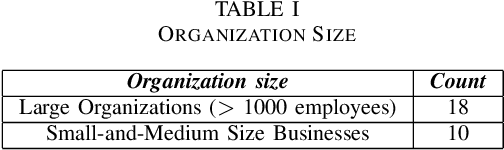
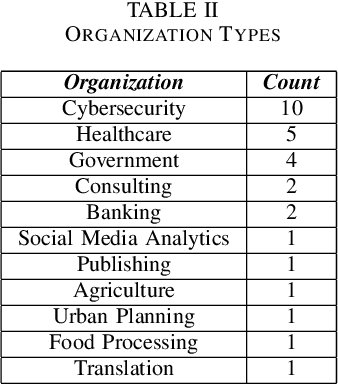

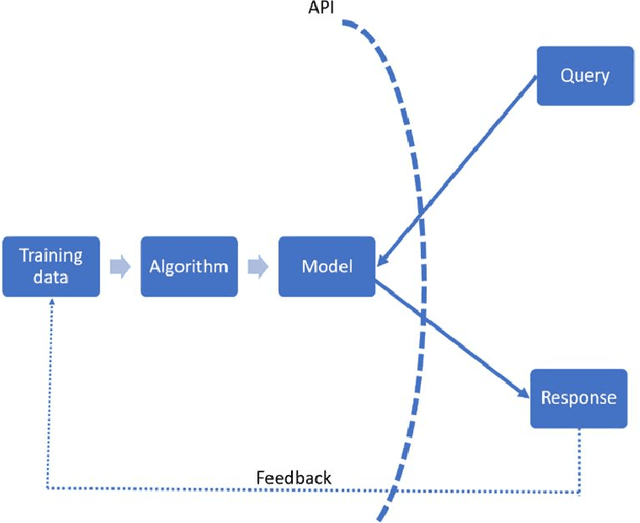
Based on interviews with 28 organizations, we found that industry practitioners are not equipped with tactical and strategic tools to protect, detect and respond to attacks on their Machine Learning (ML) systems. We leverage the insights from the interviews and we enumerate the gaps in perspective in securing machine learning systems when viewed in the context of traditional software security development. We write this paper from the perspective of two personas: developers/ML engineers and security incident responders who are tasked with securing ML systems as they are designed, developed and deployed ML systems. The goal of this paper is to engage researchers to revise and amend the Security Development Lifecycle for industrial-grade software in the adversarial ML era.