 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: A Semantic-Geometric Terrain Abstraction for Large-Scale Unstructured Environments
Jan 19, 2026Long-horizon navigation in unstructured environments demands terrain abstractions that scale to tens of km$^2$ while preserving semantic and geometric structure, a combination existing methods fail to achieve. Grids scale poorly; quadtrees misalign with terrain boundaries; neither encodes landcover semantics essential for traversability-aware planning. This yields infeasible or unreliable paths for autonomous ground vehicles operating over 10+ km$^2$ under real-time constraints. CLEAR (Connected Landcover Elevation Abstract Representation) couples boundary-aware spatial decomposition with recursive plane fitting to produce convex, semantically aligned regions encoded as a terrain-aware graph. Evaluated on maps spanning 9-100~km$^2$ using a physics-based simulator, CLEAR achieves up to 10x faster planning than raw grids with only 6.7% cost overhead and delivers 6-9% shorter, more reliable paths than other abstraction baselines. These results highlight CLEAR's scalability and utility for long-range navigation in applications such as disaster response, defense, and planetary exploration.
Detailed Evaluation of Modern Machine Learning Approaches for Optic Plastics Sorting
May 22, 2025According to the EPA, only 25% of waste is recycled, and just 60% of U.S. municipalities offer curbside recycling. Plastics fare worse, with a recycling rate of only 8%; an additional 16% is incinerated, while the remaining 76% ends up in landfills. The low plastic recycling rate stems from contamination, poor economic incentives, and technical difficulties, making efficient recycling a challenge. To improve recovery, automated sorting plays a critical role. Companies like AMP Robotics and Greyparrot utilize optical systems for sorting, while Materials Recovery Facilities (MRFs) employ Near-Infrared (NIR) sensors to detect plastic types. Modern optical sorting uses advances in computer vision such as object recognition and instance segmentation, powered by machine learning. Two-stage detectors like Mask R-CNN use region proposals and classification with deep backbones like ResNet. Single-stage detectors like YOLO handle detection in one pass, trading some accuracy for speed. While such methods excel under ideal conditions with a large volume of labeled training data, challenges arise in realistic scenarios, emphasizing the need to further examine the efficacy of optic detection for automated sorting. In this study, we compiled novel datasets totaling 20,000+ images from varied sources. Using both public and custom machine learning pipelines, we assessed the capabilities and limitations of optical recognition for sorting. Grad-CAM, saliency maps, and confusion matrices were employed to interpret model behavior. We perform this analysis on our custom trained models from the compiled datasets. To conclude, our findings are that optic recognition methods have limited success in accurate sorting of real-world plastics at MRFs, primarily because they rely on physical properties such as color and shape.
PQM: A Point Quality Evaluation Metric for Dense Maps
Jun 06, 2023



LiDAR-based mapping/reconstruction are important for various applications, but evaluating the quality of the dense maps they produce is challenging. The current methods have limitations, including the inability to capture completeness, structural information, and local variations in error. In this paper, we propose a novel point quality evaluation metric (PQM) that consists of four sub-metrics to provide a more comprehensive evaluation of point cloud quality. The completeness sub-metric evaluates the proportion of missing data, the artifact score sub-metric recognizes and characterizes artifacts, the accuracy sub-metric measures registration accuracy, and the resolution sub-metric quantifies point cloud density. Through an ablation study using a prototype dataset, we demonstrate the effectiveness of each of the sub-metrics and compare them to popular point cloud distance measures. Using three LiDAR SLAM systems to generate maps, we evaluate their output map quality and demonstrate the metrics robustness to noise and artifacts. Our implementation of PQM, datasets and detailed documentation on how to integrate with your custom dense mapping pipeline can be found at github.com/droneslab/pqm
Augmenting Visual SLAM with Wi-Fi Sensing For Indoor Applications
Mar 15, 2019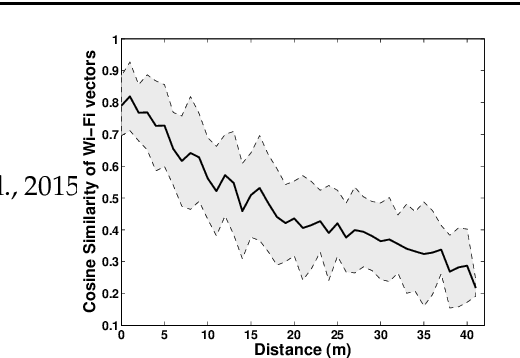
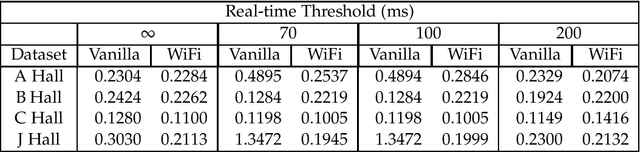
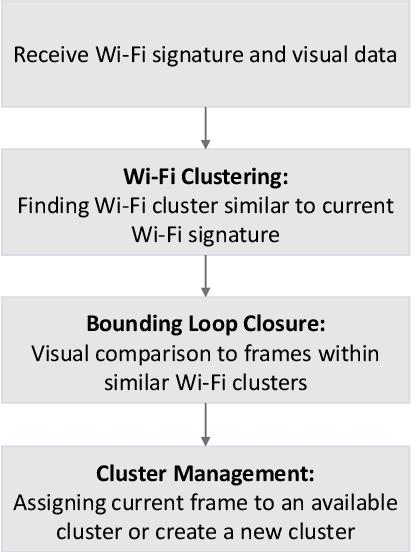
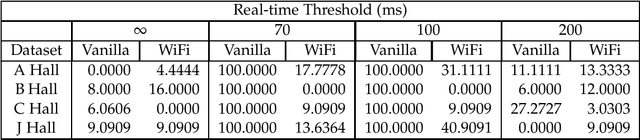
Recent trends have accelerated the development of spatial applications on mobile devices and robots. These include navigation, augmented reality, human-robot interaction, and others. A key enabling technology for such applications is the understanding of the device's location and the map of the surrounding environment. This generic problem, referred to as Simultaneous Localization and Mapping (SLAM), is an extensively researched topic in robotics. However, visual SLAM algorithms face several challenges including perceptual aliasing and high computational cost. These challenges affect the accuracy, efficiency, and viability of visual SLAM algorithms, especially for long-term SLAM, and their use in resource-constrained mobile devices. A parallel trend is the ubiquity of Wi-Fi routers for quick Internet access in most urban environments. Most robots and mobile devices are equipped with a Wi-Fi radio as well. We propose a method to utilize Wi-Fi received signal strength to alleviate the challenges faced by visual SLAM algorithms. To demonstrate the utility of this idea, this work makes the following contributions: (i) We propose a generic way to integrate Wi-Fi sensing into visual SLAM algorithms, (ii) We integrate such sensing into three well-known SLAM algorithms, (iii) Using four distinct datasets, we demonstrate the performance of such augmentation in comparison to the original visual algorithms and (iv) We compare our work to Wi-Fi augmented FABMAP algorithm. Overall, we show that our approach can improve the accuracy of visual SLAM algorithms by 11% on average and reduce computation time on average by 15% to 25%.