 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Relevant Documents: A Knowledge-Intensive Approach for Query-Focused Summarization using Large Language Models
Aug 19, 2024Query-focused summarization (QFS) is a fundamental task in natural language processing with broad applications, including search engines and report generation. However, traditional approaches assume the availability of relevant documents, which may not always hold in practical scenarios, especially in highly specialized topics. To address this limitation, we propose a novel knowledge-intensive approach that reframes QFS as a knowledge-intensive task setup. This approach comprises two main components: a retrieval module and a summarization controller. The retrieval module efficiently retrieves potentially relevant documents from a large-scale knowledge corpus based on the given textual query, eliminating the dependence on pre-existing document sets. The summarization controller seamlessly integrates a powerful large language model (LLM)-based summarizer with a carefully tailored prompt, ensuring the generated summary is comprehensive and relevant to the query. To assess the effectiveness of our approach, we create a new dataset, along with human-annotated relevance labels, to facilitate comprehensive evaluation covering both retrieval and summarization performance. Extensive experiments demonstrate the superior performance of our approach, particularly its ability to generate accurate summaries without relying on the availability of relevant documents initially. This underscores our method's versatility and practical applicability across diverse query scenarios.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Jul 19, 2024Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
Fine-Grained Natural Language Inference Based Faithfulness Evaluation for Diverse Summarisation Tasks
Feb 27, 2024We study existing approaches to leverage off-the-shelf Natural Language Inference (NLI) models for the evaluation of summary faithfulness and argue that these are sub-optimal due to the granularity level considered for premises and hypotheses. That is, the smaller content unit considered as hypothesis is a sentence and premises are made up of a fixed number of document sentences. We propose a novel approach, namely InFusE, that uses a variable premise size and simplifies summary sentences into shorter hypotheses. Departing from previous studies which focus on single short document summarisation, we analyse NLI based faithfulness evaluation for diverse summarisation tasks. We introduce DiverSumm, a new benchmark comprising long form summarisation (long documents and summaries) and diverse summarisation tasks (e.g., meeting and multi-document summarisation). In experiments, InFusE obtains superior performance across the different summarisation tasks. Our code and data are available at https://github.com/HJZnlp/infuse.
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023



People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.
Text Summarization with Oracle Expectation
Sep 26, 2022
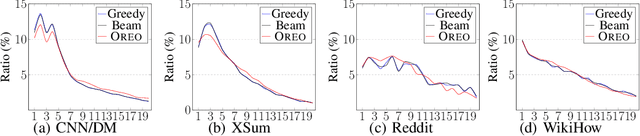
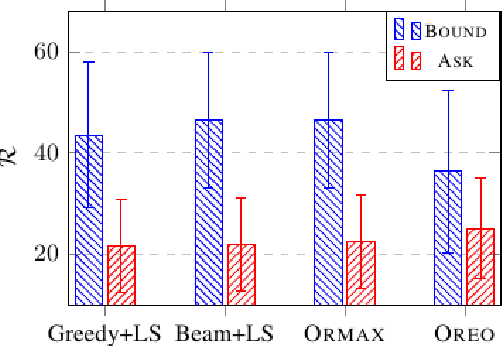
Extractive summarization produces summaries by identifying and concatenating the most important sentences in a document. Since most summarization datasets do not come with gold labels indicating whether document sentences are summary-worthy, different labeling algorithms have been proposed to extrapolate oracle extracts for model training. In this work, we identify two flaws with the widely used greedy labeling approach: it delivers suboptimal and deterministic oracles. To alleviate both issues, we propose a simple yet effective labeling algorithm that creates soft, expectation-based sentence labels. We define a new learning objective for extractive summarization which incorporates learning signals from multiple oracle summaries and prove it is equivalent to estimating the oracle expectation for each document sentence. Without any architectural modifications, the proposed labeling scheme achieves superior performance on a variety of summarization benchmarks across domains and languages, in both supervised and zero-shot settings.
Text Summarization with Latent Queries
May 31, 2021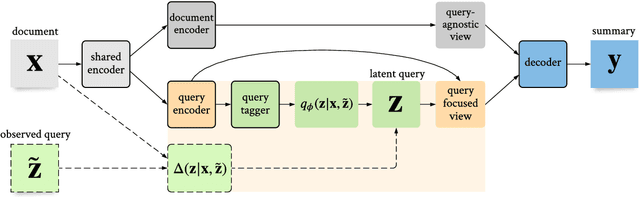


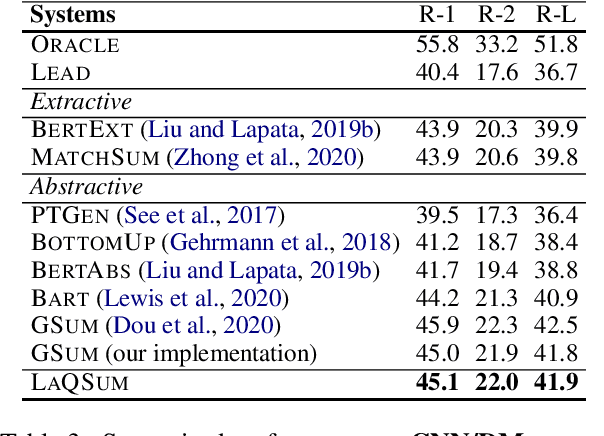
The availability of large-scale datasets has driven the development of neural models that create summaries from single documents, for generic purposes. When using a summarization system, users often have specific intents with various language realizations, which, depending on the information need, can range from a single keyword to a long narrative composed of multiple questions. Existing summarization systems, however, often either fail to support or act robustly on this query focused summarization task. We introduce LaQSum, the first unified text summarization system that learns Latent Queries from documents for abstractive summarization with any existing query forms. Under a deep generative framework, our system jointly optimizes a latent query model and a conditional language model, allowing users to plug-and-play queries of any type at test time. Despite learning from only generic summarization data and requiring no further optimization for downstream summarization tasks, our system robustly outperforms strong comparison systems across summarization benchmarks with different query types, document settings, and target domains.
Abstractive Query Focused Summarization with Query-Free Resources
Dec 29, 2020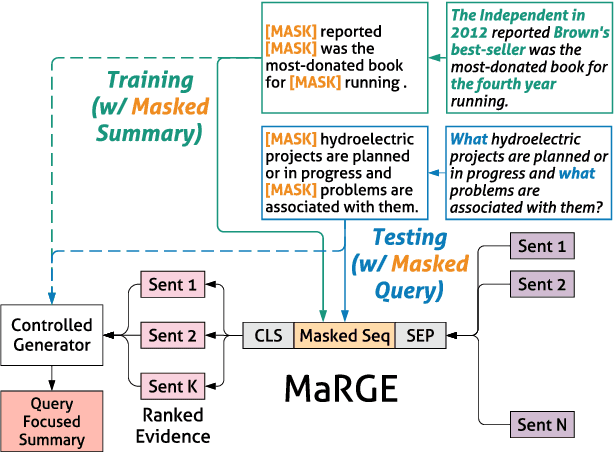
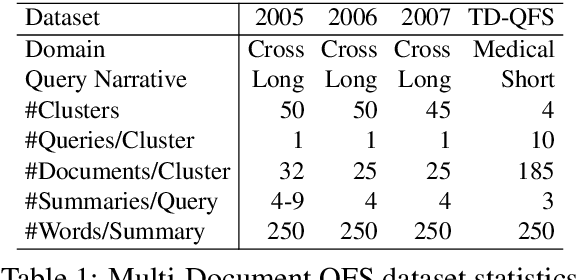
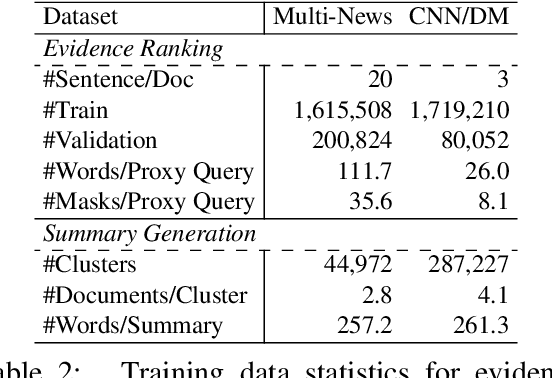
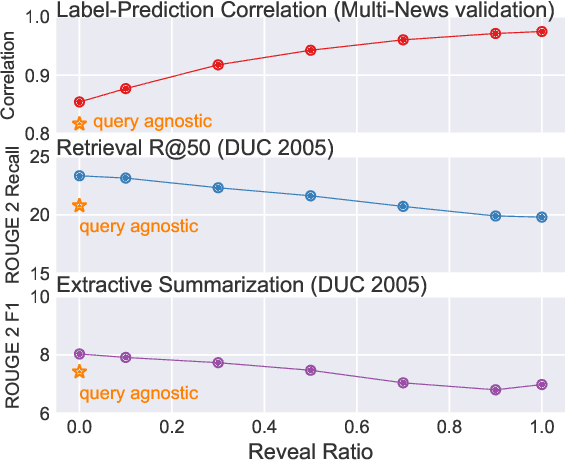
The availability of large-scale datasets has driven the development of neural sequence-to-sequence models to generate generic summaries, i.e., summaries which do not correspond to any pre-specified queries. However, due to the lack of training data, query focused summarization (QFS) has been studied mainly with extractive methods. In this work, we consider the problem of leveraging only generic summarization resources to build an abstractive QFS system. We propose Marge, a Masked ROUGE Regression framework composed of a novel unified representation for summaries and queries, and a distantly supervised training task for answer evidence estimation. To further utilize generic data for generation, three attributes are incorporated during training and inference to control the shape of the final summary: evidence rank, query guidance, and summary length. Despite learning from minimal supervision, our system achieves state-of-the-art results in the distantly supervised setting across domains and query types.
Meta Dialogue Policy Learning
Jun 03, 2020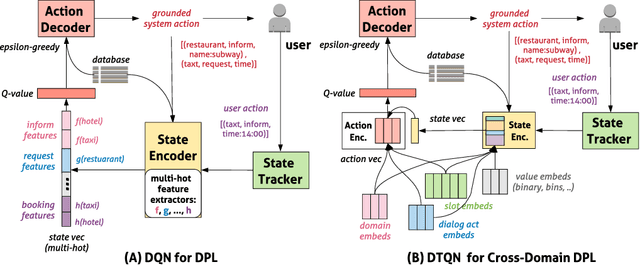
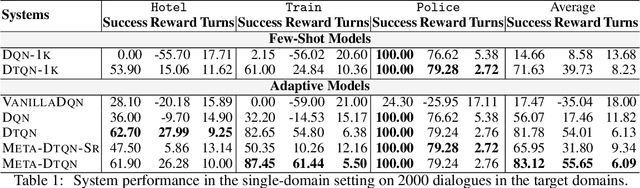
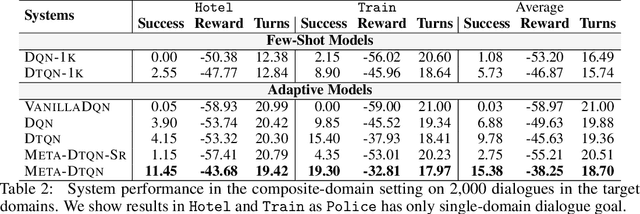
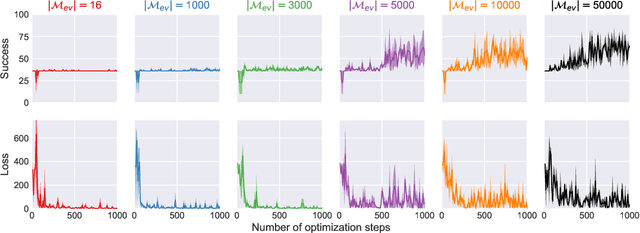
Dialog policy determines the next-step actions for agents and hence is central to a dialogue system. However, when migrated to novel domains with little data, a policy model can fail to adapt due to insufficient interactions with the new environment. We propose Deep Transferable Q-Network (DTQN) to utilize shareable low-level signals between domains, such as dialogue acts and slots. We decompose the state and action representation space into feature subspaces corresponding to these low-level components to facilitate cross-domain knowledge transfer. Furthermore, we embed DTQN in a meta-learning framework and introduce Meta-DTQN with a dual-replay mechanism to enable effective off-policy training and adaptation. In experiments, our model outperforms baseline models in terms of both success rate and dialogue efficiency on the multi-domain dialogue dataset MultiWOZ 2.0.
Bootstrapping a Crosslingual Semantic Parser
Apr 16, 2020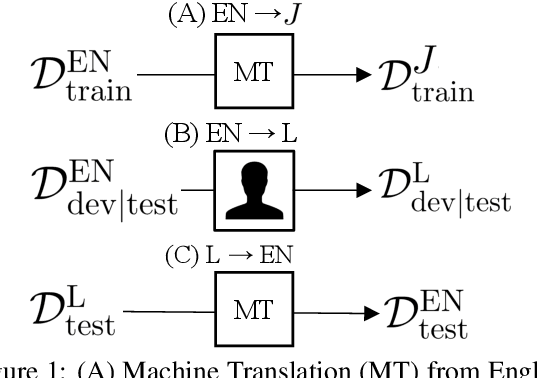
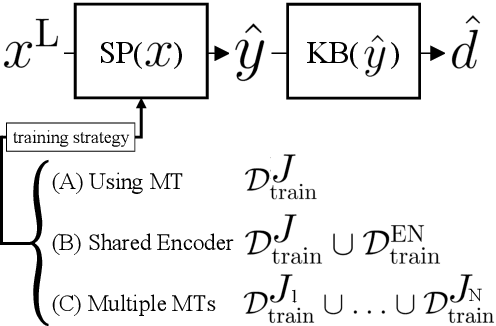
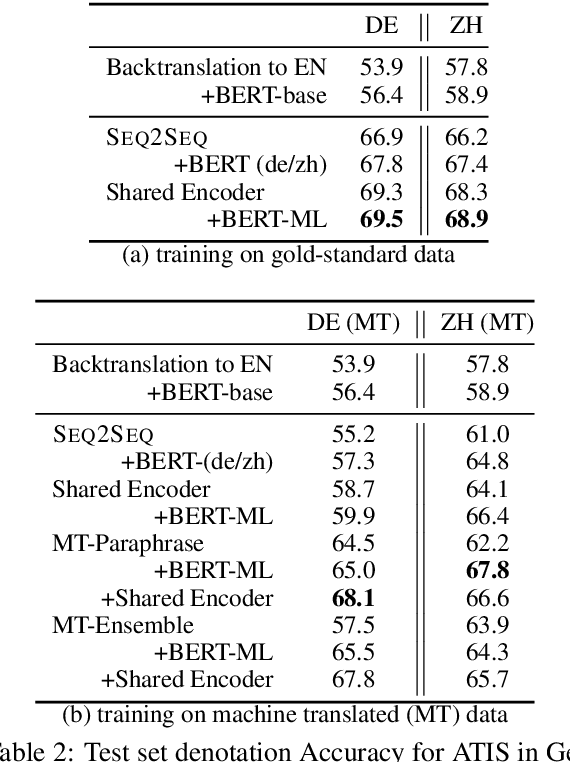
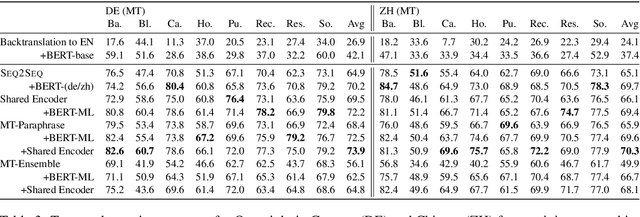
Datasets for semantic parsing scarcely consider languages other than English and professional translation can be prohibitively expensive. In this work, we propose to adapt a semantic parser trained on a single language, such as English, to new languages and multiple domains with minimal annotation. We evaluate if machine translation is an adequate substitute for training data, and extend this to investigate bootstrapping using joint training with English, paraphrasing, and resources such as multilingual BERT. Experimental results on a new version of ATIS and Overnight in German and Chinese indicate that MT can approximate training data in a new language for accurate parsing when augmented with paraphrasing through multiple MT engines.