 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Revisiting Proprioceptive Sensing for Articulated Object Manipulation
May 16, 2023
Robots that assist humans will need to interact with articulated objects such as cabinets or microwaves. Early work on creating systems for doing so used proprioceptive sensing to estimate joint mechanisms during contact. However, nowadays, almost all systems use only vision and no longer consider proprioceptive information during contact. We believe that proprioceptive information during contact is a valuable source of information and did not find clear motivation for not using it in the literature. Therefore, in this paper, we create a system that, starting from a given grasp, uses proprioceptive sensing to open cabinets with a position-controlled robot and a parallel gripper. We perform a qualitative evaluation of this system, where we find that slip between the gripper and handle limits the performance. Nonetheless, we find that the system already performs quite well. This poses the question: should we make more use of proprioceptive information during contact in articulated object manipulation systems, or is it not worth the added complexity, and can we manage with vision alone? We do not have an answer to this question, but we hope to spark some discussion on the matter. The codebase and videos of the system are available at https://tlpss.github.io/revisiting-proprioception-for-articulated-manipulation/.
SEGA: Structural Entropy Guided Anchor View for Graph Contrastive Learning
May 08, 2023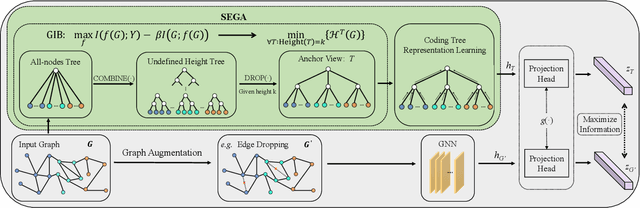
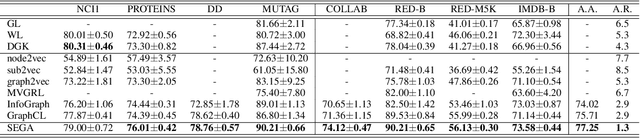

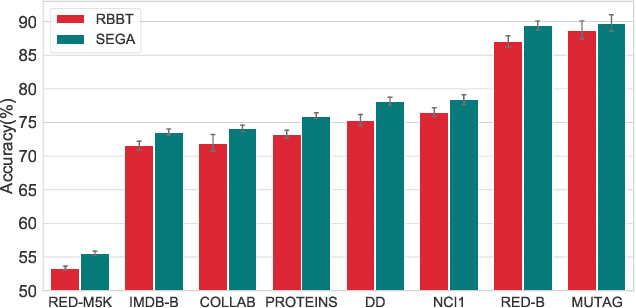
In contrastive learning, the choice of ``view'' controls the information that the representation captures and influences the performance of the model. However, leading graph contrastive learning methods generally produce views via random corruption or learning, which could lead to the loss of essential information and alteration of semantic information. An anchor view that maintains the essential information of input graphs for contrastive learning has been hardly investigated. In this paper, based on the theory of graph information bottleneck, we deduce the definition of this anchor view; put differently, \textit{the anchor view with essential information of input graph is supposed to have the minimal structural uncertainty}. Furthermore, guided by structural entropy, we implement the anchor view, termed \textbf{SEGA}, for graph contrastive learning. We extensively validate the proposed anchor view on various benchmarks regarding graph classification under unsupervised, semi-supervised, and transfer learning and achieve significant performance boosts compared to the state-of-the-art methods.
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
May 24, 2023
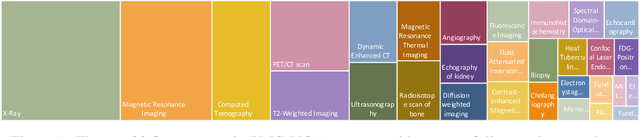
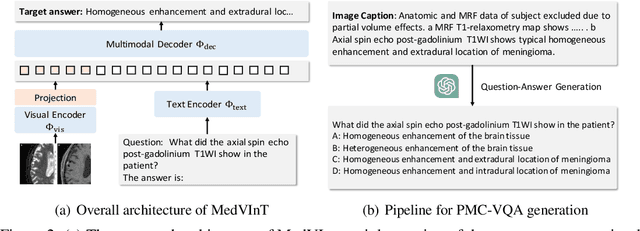
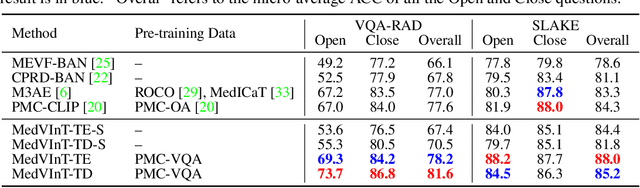
In this paper, we focus on the problem of Medical Visual Question Answering (MedVQA), which is crucial in efficiently interpreting medical images with vital clinic-relevant information. Firstly, we reframe the problem of MedVQA as a generation task that naturally follows the human-machine interaction, we propose a generative-based model for medical visual understanding by aligning visual information from a pre-trained vision encoder with a large language model. Secondly, we establish a scalable pipeline to construct a large-scale medical visual question-answering dataset, named PMC-VQA, which contains 227k VQA pairs of 149k images that cover various modalities or diseases. Thirdly, we pre-train our proposed model on PMC-VQA and then fine-tune it on multiple public benchmarks, e.g., VQA-RAD and SLAKE, outperforming existing work by a large margin. Additionally, we propose a test set that has undergone manual verification, which is significantly more challenging, even the best models struggle to solve.
BeamSearchQA: Large Language Models are Strong Zero-Shot QA Solver
May 24, 2023
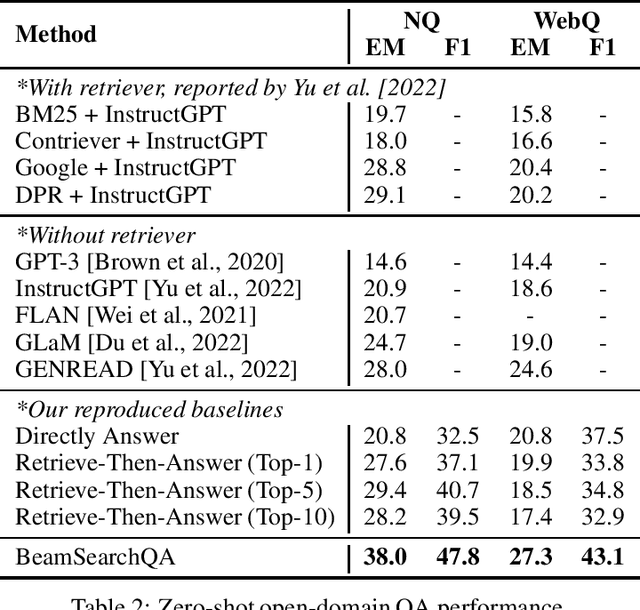

Open-domain question answering is a crucial task that often requires accessing external information. Existing methods typically adopt a single-turn retrieve-then-read approach, where relevant documents are first retrieved, and questions are then answered based on the retrieved information. However, there are cases where answering a question requires implicit knowledge that is not directly retrievable from the question itself. In this work, we propose a novel question-answering pipeline called eamSearchQA. Our approach leverages large language models(LLMs) to iteratively generate new questions about the original question, enabling an iterative reasoning process. By iteratively refining and expanding the scope of the question, our method aims to capture and utilize hidden knowledge that may not be directly obtainable through retrieval. We evaluate our approach on the widely-used open-domain NQ and WebQ datasets. The experimental results demonstrate that BeamSearchQA significantly outperforms other zero-shot baselines, indicating its effectiveness in tackling the challenges of open-domain question answering.
Handheld Haptic Device with Coupled Bidirectional Input
May 30, 2023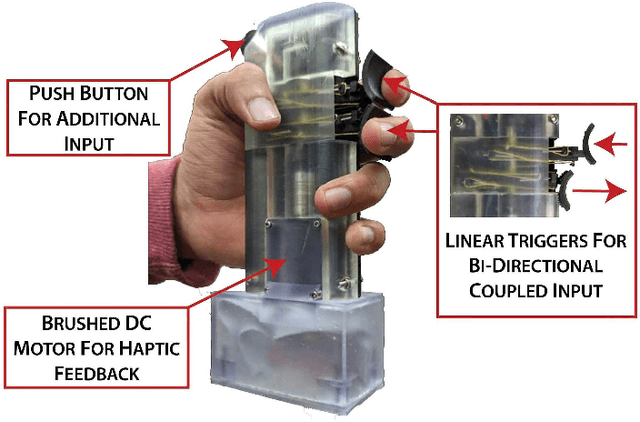
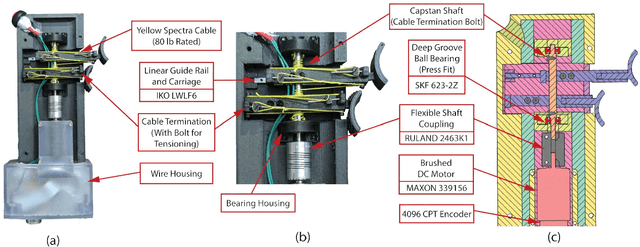
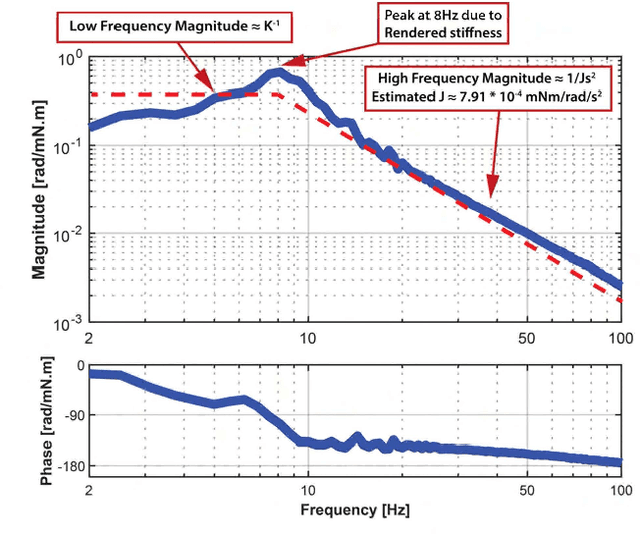

Handheld kinesthetic haptic interfaces can provide greater mobility and richer tactile information as compared to traditional grounded devices. In this paper, we introduce a new handheld haptic interface which takes input using bidirectional coupled finger flexion. We present the device design motivation and design details and experimentally evaluate its performance in terms of transparency and rendering bandwidth using a handheld prototype device. In addition, we assess the device's functional performance through a user study comparing the proposed device to a commonly used grounded input device in a set of targeting and tracking tasks.
Fine-Grained Property Value Assessment using Probabilistic Disaggregation
May 31, 2023
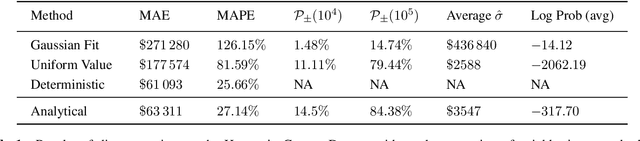
The monetary value of a given piece of real estate, a parcel, is often readily available from a geographic information system. However, for many applications, such as insurance and urban planning, it is useful to have estimates of property value at much higher spatial resolutions. We propose a method to estimate the distribution over property value at the pixel level from remote sensing imagery. We evaluate on a real-world dataset of a major urban area. Our results show that the proposed approaches are capable of generating fine-level estimates of property values, significantly improving upon a diverse collection of baseline approaches.
An Efficient Machine Learning-based Channel Prediction Technique for OFDM Sub-Bands
May 31, 2023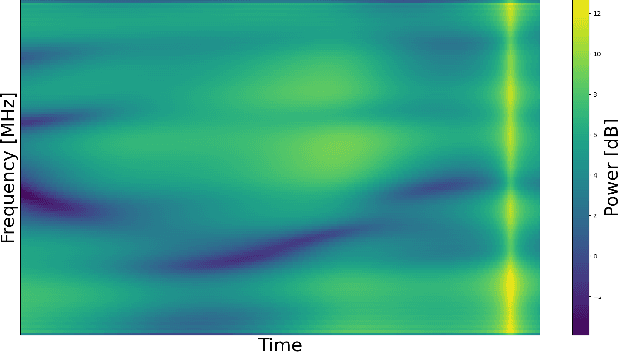
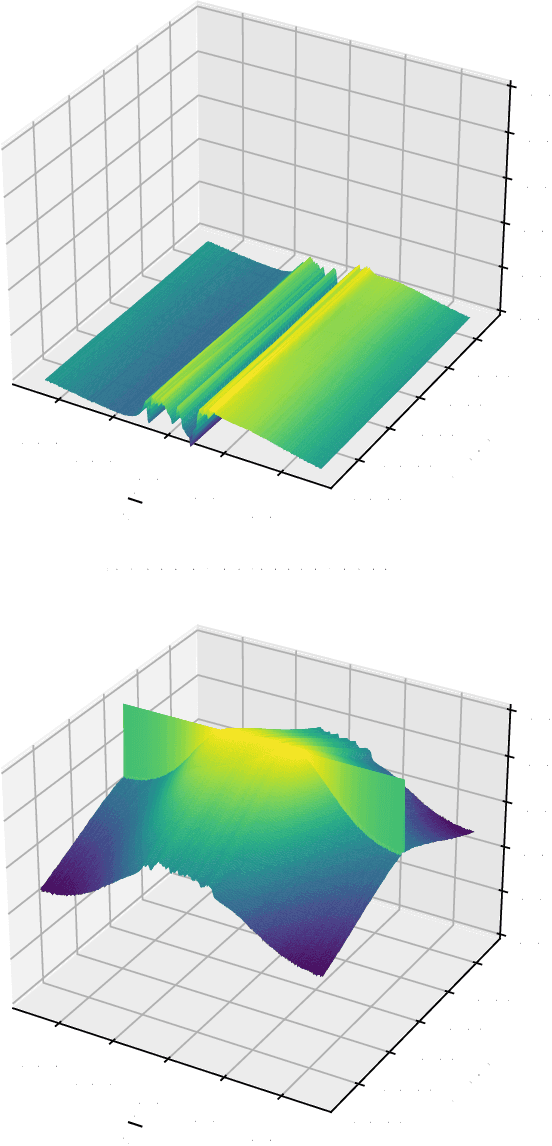
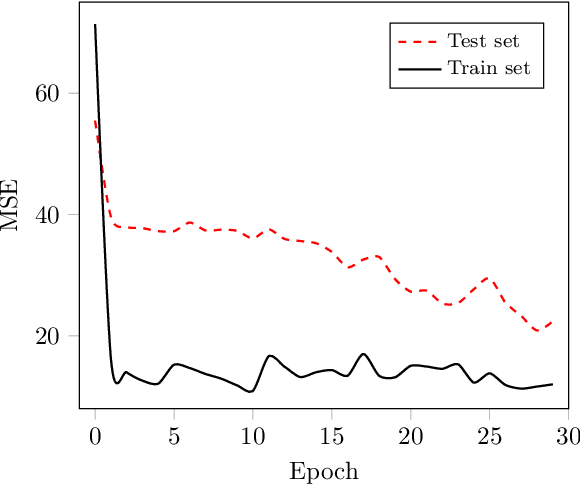
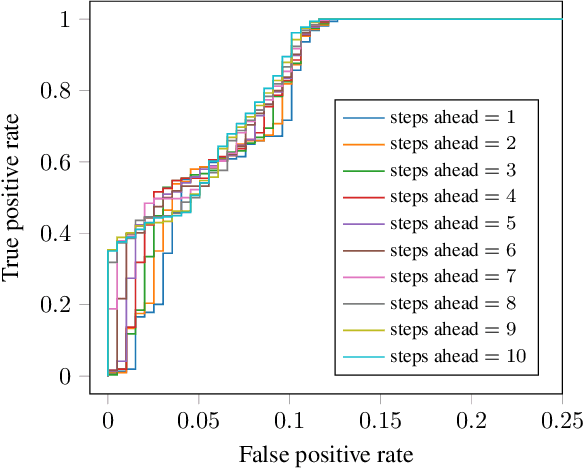
The acquisition of accurate channel state information (CSI) is of utmost importance since it provides performance improvement of wireless communication systems. However, acquiring accurate CSI, which can be done through channel estimation or channel prediction, is an intricate task due to the complexity of the time-varying and frequency selectivity of the wireless environment. To this end, we propose an efficient machine learning (ML)-based technique for channel prediction in orthogonal frequency-division multiplexing (OFDM) sub-bands. The novelty of the proposed approach lies in the training of channel fading samples used to estimate future channel behaviour in selective fading.
Incorporating L2 Phonemes Using Articulatory Features for Robust Speech Recognition
Jun 05, 2023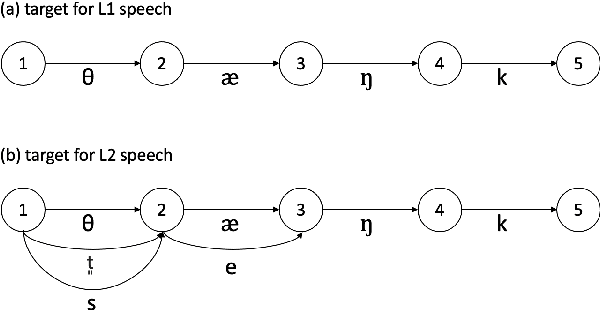



The limited availability of non-native speech datasets presents a major challenge in automatic speech recognition (ASR) to narrow the performance gap between native and non-native speakers. To address this, the focus of this study is on the efficient incorporation of the L2 phonemes, which in this work refer to Korean phonemes, through articulatory feature analysis. This not only enables accurate modeling of pronunciation variants but also allows for the utilization of both native Korean and English speech datasets. We employ the lattice-free maximum mutual information (LF-MMI) objective in an end-to-end manner, to train the acoustic model to align and predict one of multiple pronunciation candidates. Experimental results show that the proposed method improves ASR accuracy for Korean L2 speech by training solely on L1 speech data. Furthermore, fine-tuning on L2 speech improves recognition accuracy for both L1 and L2 speech without performance trade-offs.
Vocoder drift in x-vector-based speaker anonymization
Jun 05, 2023
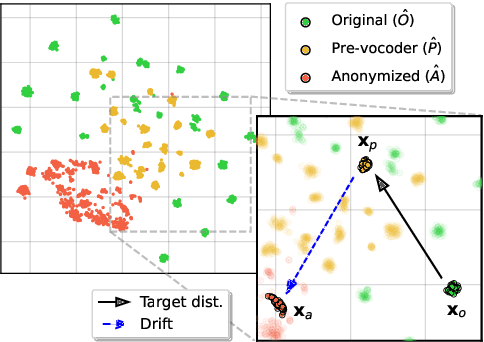
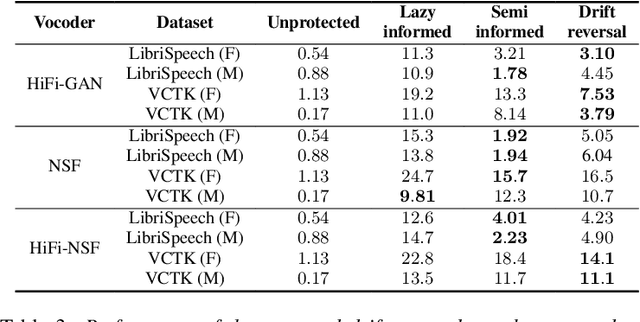
State-of-the-art approaches to speaker anonymization typically employ some form of perturbation function to conceal speaker information contained within an x-vector embedding, then resynthesize utterances in the voice of a new pseudo-speaker using a vocoder. Strategies to improve the x-vector anonymization function have attracted considerable research effort, whereas vocoder impacts are generally neglected. In this paper, we show that the impact of the vocoder is substantial and sometimes dominant. The vocoder drift, namely the difference between the x-vector vocoder input and that which can be extracted subsequently from the output, is learnable and can hence be reversed by an attacker; anonymization can be undone and the level of privacy protection provided by such approaches might be weaker than previously thought. The findings call into question the focus upon x-vector anonymization, prompting the need for greater attention to vocoder impacts and stronger attack models alike.
BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023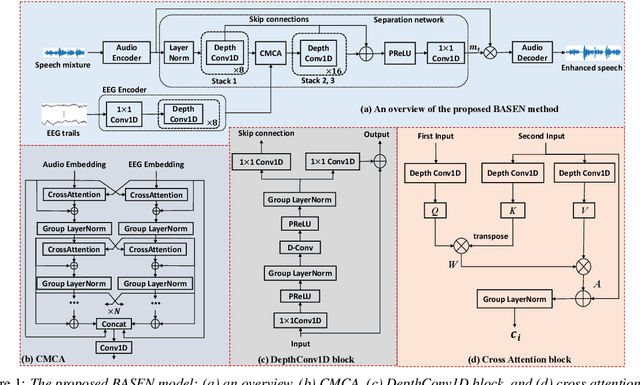
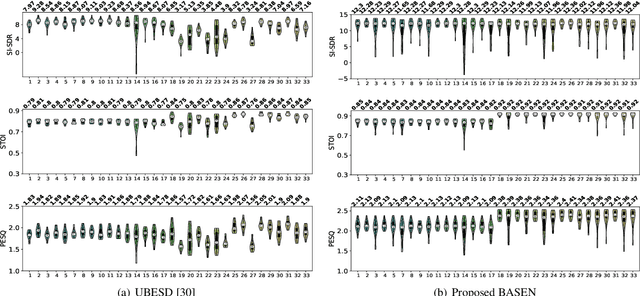
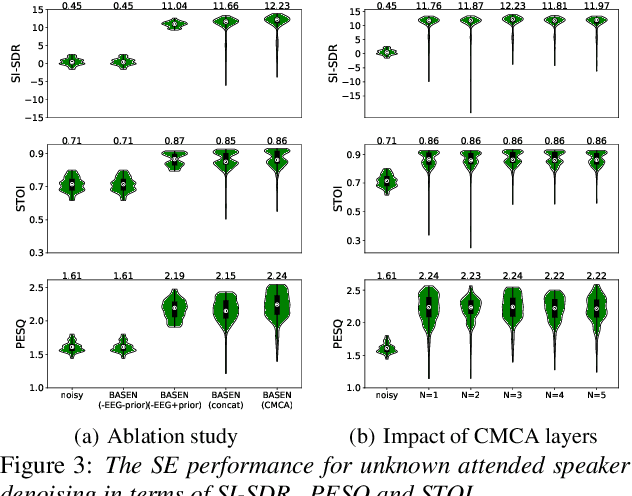
Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.