 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Incentive Noise Predictor for Adversarial Purification in Speaker Verification
Jul 01, 2026Modern automatic speaker verification (ASV) systems are vulnerable to adversarial perturbations. Diffusion-based purification has recently shown strong effectiveness against such perturbations, but its reverse denoising process requires iterative sampling and leads to high inference latency. We find that the forward noising process provides most of the robustness gain. Motivated by this observation, we reformulate adversarial purification as a learnable noising problem, and propose the Positive-Incentive Noise Predictor (PnP), the first framework that explicitly introduces positive-incentive noise (π-noise) into the purification task. PnP learns input-adaptive π-noise and mixes it with the input to improve the robustness of downstream ASV systems. Experiments on four advanced ASV backbones show that PnP effectively defends against adversarial attacks while preserving performance on natural speech. Compared with representative purification baselines, the proposed framework provides a competitive balance among defense effectiveness, impact on genuine utterances, and inference efficiency under white-box, black-box, and defender-aware adaptive attacks, with a real-time factor as low as 0.014. Moreover, PnP can be cascaded with a diffusion denoiser to further improve the perceptual quality of purified utterances. Code and purified audio examples are available at https://eurecom-asp.github.io/pnp/
Identity leakage through accent cues in voice anonymisation
Mar 27, 2026Voice anonymisation is used to conceal voice identity while preserving linguistic content. Even if anonymisation seems strong, non-timbral cues such as accent that remain post-anonymisation can help re-identification and reveal sensitive socio-demographic traits. We report a study of residual accent information involving multiple anonymisation systems. We highlight the role of accent using speaker verification, accent verification, and accent classification using a set of embeddings focusing on timbral, non-timbral and accent-related information and show the extent to which related cues facilitate reidentification post anonymisation. Results show that, while some systems are robust to reidentification attempts using accent cues, others leave residual, speaker-dependent, accentrelated cues which can be used to reveal the voice identity. We also highlight accent-dependent variation in anonymisation performance, raising fairness concerns, and show that a system with characterlevel conditioning can help obfuscate identity-revealing accent cues, reducing accent-identification accuracy by 68% on average and improving overall anonymisation performance by 11% relative.
The Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
MDD: a Mask Diffusion Detector to Protect Speaker Verification Systems from Adversarial Perturbations
Aug 26, 2025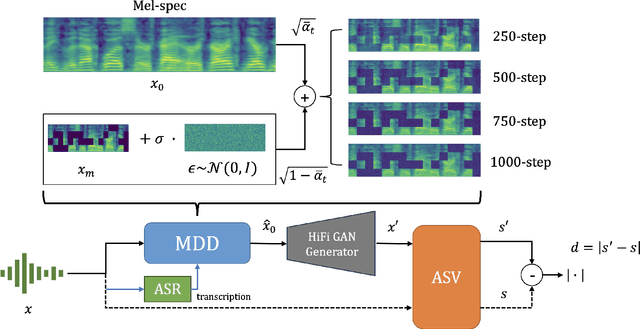



Speaker verification systems are increasingly deployed in security-sensitive applications but remain highly vulnerable to adversarial perturbations. In this work, we propose the Mask Diffusion Detector (MDD), a novel adversarial detection and purification framework based on a \textit{text-conditioned masked diffusion model}. During training, MDD applies partial masking to Mel-spectrograms and progressively adds noise through a forward diffusion process, simulating the degradation of clean speech features. A reverse process then reconstructs the clean representation conditioned on the input transcription. Unlike prior approaches, MDD does not require adversarial examples or large-scale pretraining. Experimental results show that MDD achieves strong adversarial detection performance and outperforms prior state-of-the-art methods, including both diffusion-based and neural codec-based approaches. Furthermore, MDD effectively purifies adversarially-manipulated speech, restoring speaker verification performance to levels close to those observed under clean conditions. These findings demonstrate the potential of diffusion-based masking strategies for secure and reliable speaker verification systems.
The Risks and Detection of Overestimated Privacy Protection in Voice Anonymisation
Jul 30, 2025Voice anonymisation aims to conceal the voice identity of speakers in speech recordings. Privacy protection is usually estimated from the difficulty of using a speaker verification system to re-identify the speaker post-anonymisation. Performance assessments are therefore dependent on the verification model as well as the anonymisation system. There is hence potential for privacy protection to be overestimated when the verification system is poorly trained, perhaps with mismatched data. In this paper, we demonstrate the insidious risk of overestimating anonymisation performance and show examples of exaggerated performance reported in the literature. For the worst case we identified, performance is overestimated by 74% relative. We then introduce a means to detect when performance assessment might be untrustworthy and show that it can identify all overestimation scenarios presented in the paper. Our solution is openly available as a fork of the 2024 VoicePrivacy Challenge evaluation toolkit.
2D-Malafide: Adversarial Attacks Against Face Deepfake Detection Systems
Aug 26, 2024


We introduce 2D-Malafide, a novel and lightweight adversarial attack designed to deceive face deepfake detection systems. Building upon the concept of 1D convolutional perturbations explored in the speech domain, our method leverages 2D convolutional filters to craft perturbations which significantly degrade the performance of state-of-the-art face deepfake detectors. Unlike traditional additive noise approaches, 2D-Malafide optimises a small number of filter coefficients to generate robust adversarial perturbations which are transferable across different face images. Experiments, conducted using the FaceForensics++ dataset, demonstrate that 2D-Malafide substantially degrades detection performance in both white-box and black-box settings, with larger filter sizes having the greatest impact. Additionally, we report an explainability analysis using GradCAM which illustrates how 2D-Malafide misleads detection systems by altering the image areas used most for classification. Our findings highlight the vulnerability of current deepfake detection systems to convolutional adversarial attacks as well as the need for future work to enhance detection robustness through improved image fidelity constraints.
Malacopula: adversarial automatic speaker verification attacks using a neural-based generalised Hammerstein model
Aug 17, 2024We present Malacopula, a neural-based generalised Hammerstein model designed to introduce adversarial perturbations to spoofed speech utterances so that they better deceive automatic speaker verification (ASV) systems. Using non-linear processes to modify speech utterances, Malacopula enhances the effectiveness of spoofing attacks. The model comprises parallel branches of polynomial functions followed by linear time-invariant filters. The adversarial optimisation procedure acts to minimise the cosine distance between speaker embeddings extracted from spoofed and bona fide utterances. Experiments, performed using three recent ASV systems and the ASVspoof 2019 dataset, show that Malacopula increases vulnerabilities by a substantial margin. However, speech quality is reduced and attacks can be detected effectively under controlled conditions. The findings emphasise the need to identify new vulnerabilities and design defences to protect ASV systems from adversarial attacks in the wild.
Preserving spoken content in voice anonymisation with character-level vocoder conditioning
Aug 08, 2024


Voice anonymisation can be used to help protect speaker privacy when speech data is shared with untrusted others. In most practical applications, while the voice identity should be sanitised, other attributes such as the spoken content should be preserved. There is always a trade-off; all approaches reported thus far sacrifice spoken content for anonymisation performance. We report what is, to the best of our knowledge, the first attempt to actively preserve spoken content in voice anonymisation. We show how the output of an auxiliary automatic speech recognition model can be used to condition the vocoder module of an anonymisation system using a set of learnable embedding dictionaries in order to preserve spoken content. Relative to a baseline approach, and for only a modest cost in anonymisation performance, the technique is successful in decreasing the word error rate computed from anonymised utterances by almost 60%.
The VoicePrivacy 2022 Challenge: Progress and Perspectives in Voice Anonymisation
Jul 16, 2024



The VoicePrivacy Challenge promotes the development of voice anonymisation solutions for speech technology. In this paper we present a systematic overview and analysis of the second edition held in 2022. We describe the voice anonymisation task and datasets used for system development and evaluation, present the different attack models used for evaluation, and the associated objective and subjective metrics. We describe three anonymisation baselines, provide a summary description of the anonymisation systems developed by challenge participants, and report objective and subjective evaluation results for all. In addition, we describe post-evaluation analyses and a summary of related work reported in the open literature. Results show that solutions based on voice conversion better preserve utility, that an alternative which combines automatic speech recognition with synthesis achieves greater privacy, and that a privacy-utility trade-off remains inherent to current anonymisation solutions. Finally, we present our ideas and priorities for future VoicePrivacy Challenge editions.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024



The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.