 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M^2UNet: MetaFormer Multi-scale Upsampling Network for Polyp Segmentation
Jun 14, 2023
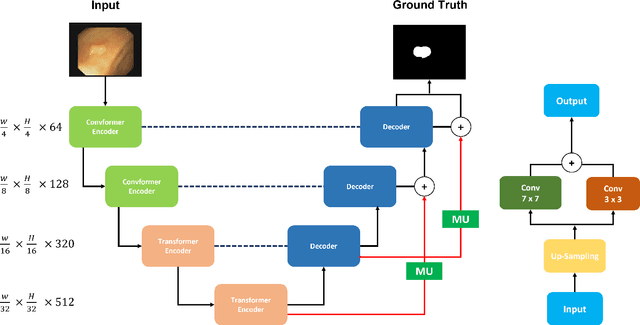
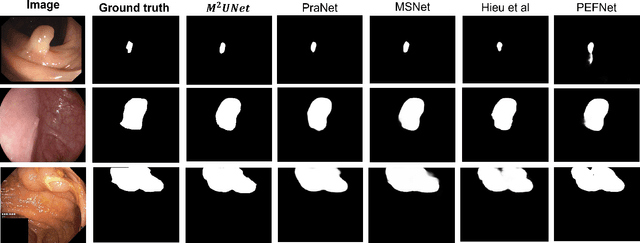
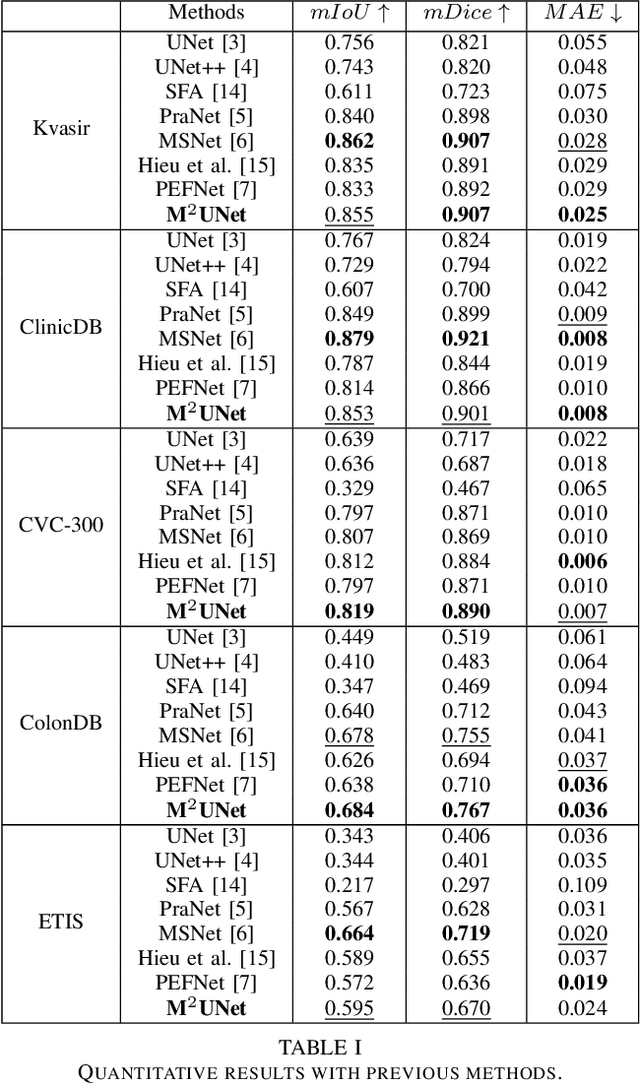
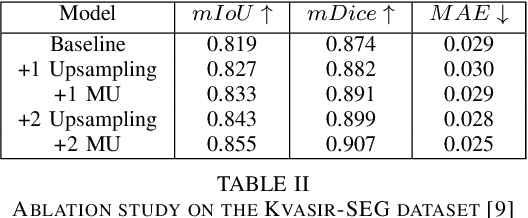
Polyp segmentation has recently garnered significant attention, and multiple methods have been formulated to achieve commendable outcomes. However, these techniques often confront difficulty when working with the complex polyp foreground and their surrounding regions because of the nature of convolution operation. Besides, most existing methods forget to exploit the potential information from multiple decoder stages. To address this challenge, we suggest combining MetaFormer, introduced as a baseline for integrating CNN and Transformer, with UNet framework and incorporating our Multi-scale Upsampling block (MU). This simple module makes it possible to combine multi-level information by exploring multiple receptive field paths of the shallow decoder stage and then adding with the higher stage to aggregate better feature representation, which is essential in medical image segmentation. Taken all together, we propose MetaFormer Multi-scale Upsampling Network (M$^2$UNet) for the polyp segmentation task. Extensive experiments on five benchmark datasets demonstrate that our method achieved competitive performance compared with several previous methods.
A Weighted Autoencoder-Based Approach to Downlink NOMA Constellation Design
Jun 23, 2023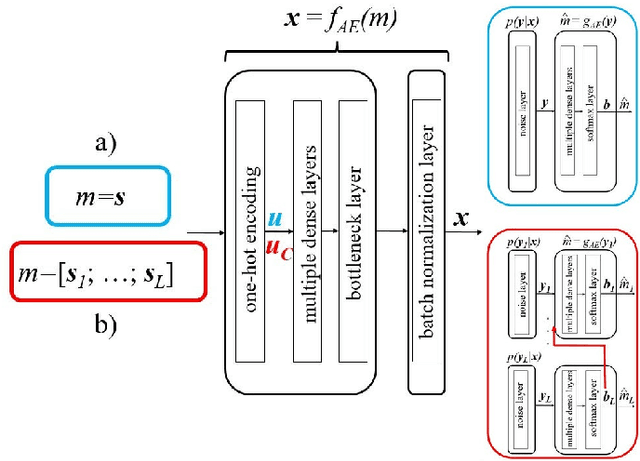
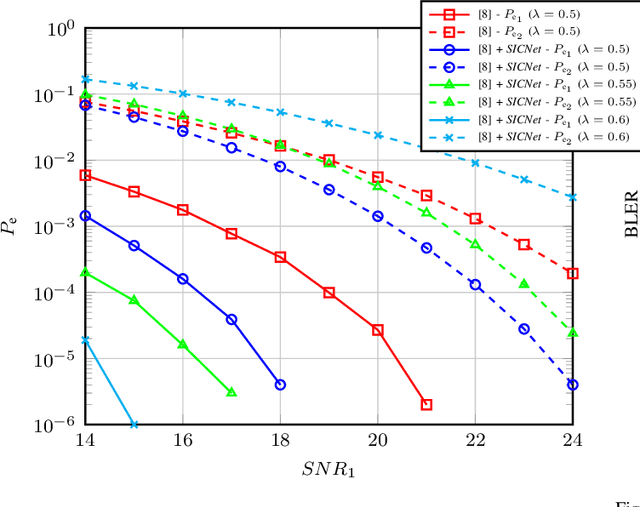
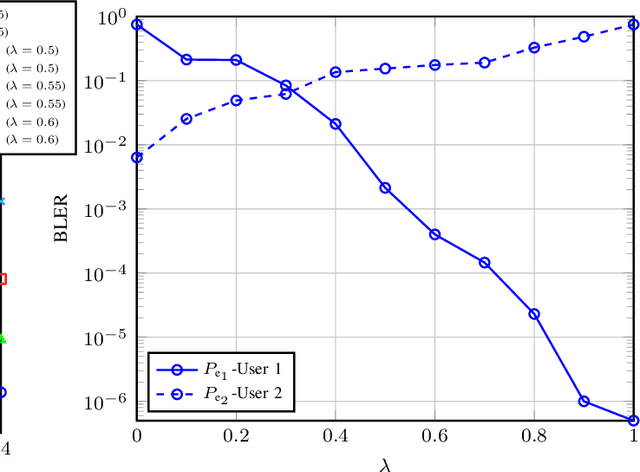
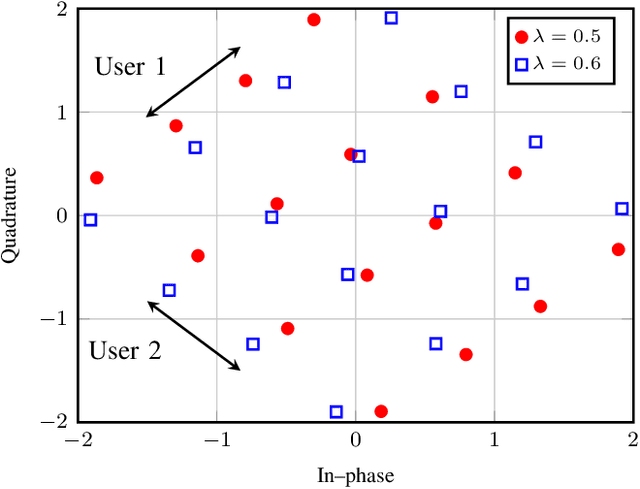
End-to-end design of communication systems using deep autoencoders (AEs) is gaining attention due to its flexibility and excellent performance. Besides single-user transmission, AE-based design is recently explored in multi-user setup, e.g., for designing constellations for non-orthogonal multiple access (NOMA). In this paper, we further advance the design of AE-based downlink NOMA by introducing weighted loss function in the AE training. By changing the weight coefficients, one can flexibly tune the constellation design to balance error probability of different users, without relying on explicit information about their channel quality. Combined with the SICNet decoder, we demonstrate a significant improvement in achievable levels and flexible control of error probability of different users using the proposed weighted AE-based framework.
Prompt-based Extraction of Social Determinants of Health Using Few-shot Learning
Jun 12, 2023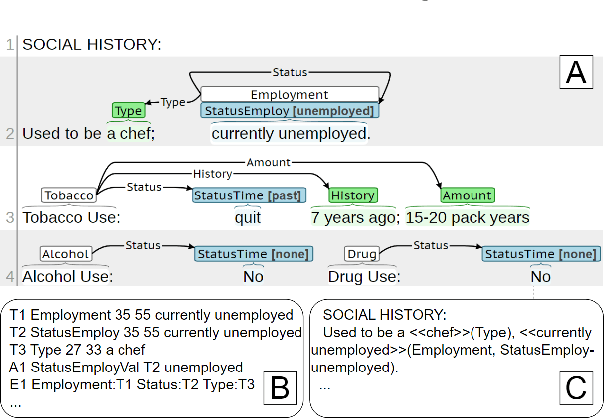
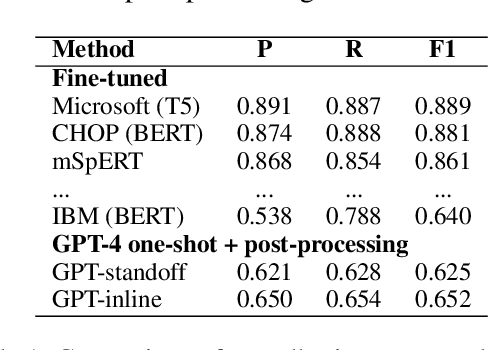
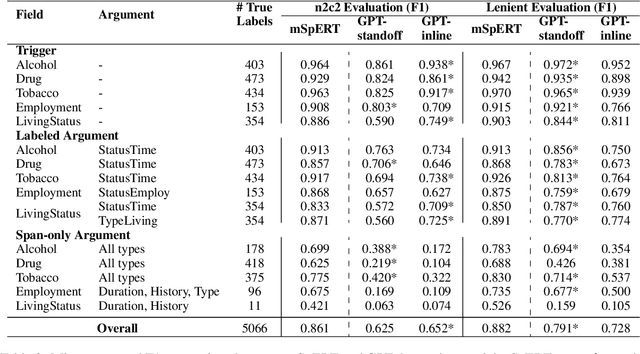
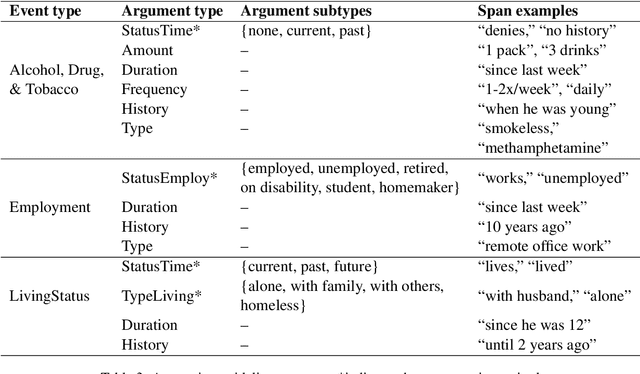
Social determinants of health (SDOH) documented in the electronic health record through unstructured text are increasingly being studied to understand how SDOH impacts patient health outcomes. In this work, we utilize the Social History Annotation Corpus (SHAC), a multi-institutional corpus of de-identified social history sections annotated for SDOH, including substance use, employment, and living status information. We explore the automatic extraction of SDOH information with SHAC in both standoff and inline annotation formats using GPT-4 in a one-shot prompting setting. We compare GPT-4 extraction performance with a high-performing supervised approach and perform thorough error analyses. Our prompt-based GPT-4 method achieved an overall 0.652 F1 on the SHAC test set, similar to the 7th best-performing system among all teams in the n2c2 challenge with SHAC.
EriBERTa: A Bilingual Pre-Trained Language Model for Clinical Natural Language Processing
Jun 12, 2023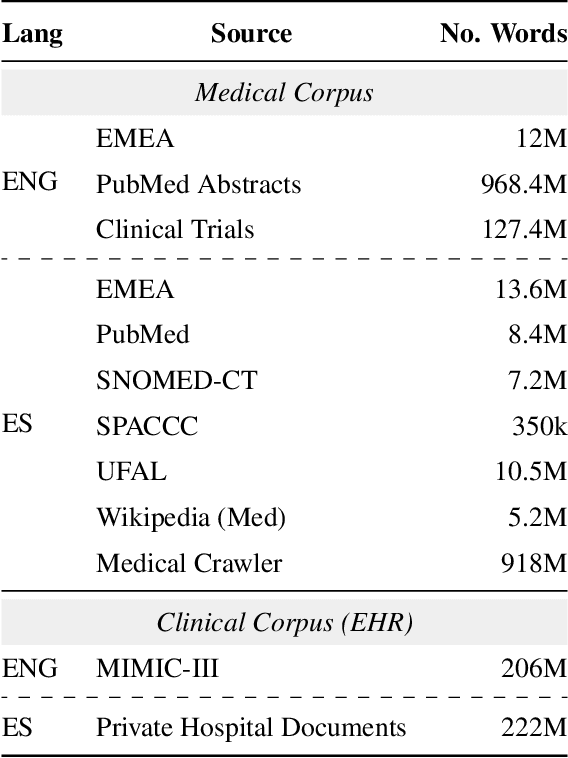
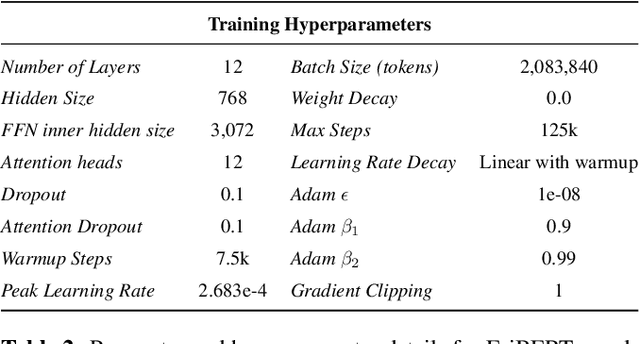
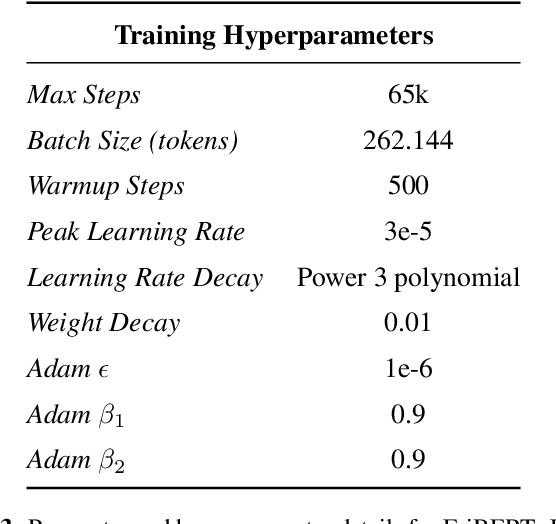
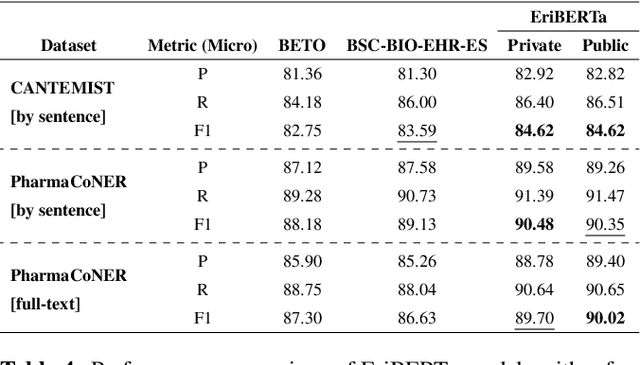
The utilization of clinical reports for various secondary purposes, including health research and treatment monitoring, is crucial for enhancing patient care. Natural Language Processing (NLP) tools have emerged as valuable assets for extracting and processing relevant information from these reports. However, the availability of specialized language models for the clinical domain in Spanish has been limited. In this paper, we introduce EriBERTa, a bilingual domain-specific language model pre-trained on extensive medical and clinical corpora. We demonstrate that EriBERTa outperforms previous Spanish language models in the clinical domain, showcasing its superior capabilities in understanding medical texts and extracting meaningful information. Moreover, EriBERTa exhibits promising transfer learning abilities, allowing for knowledge transfer from one language to another. This aspect is particularly beneficial given the scarcity of Spanish clinical data.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023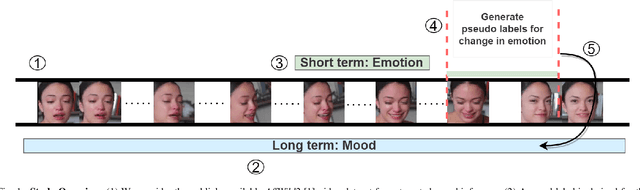
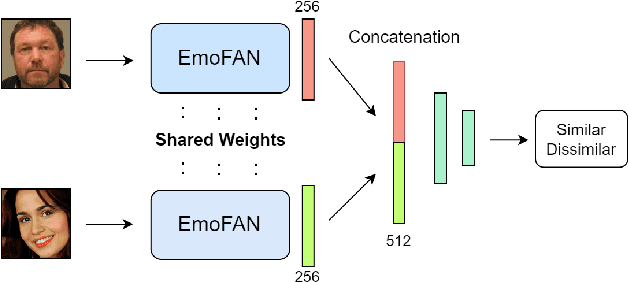
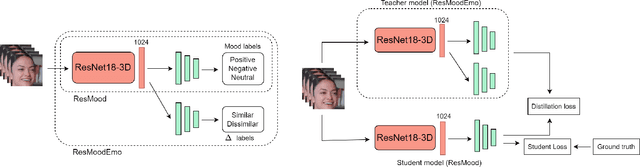
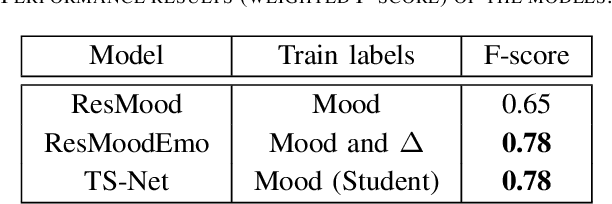
Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.
Data-Free Quantization via Mixed-Precision Compensation without Fine-Tuning
Jul 02, 2023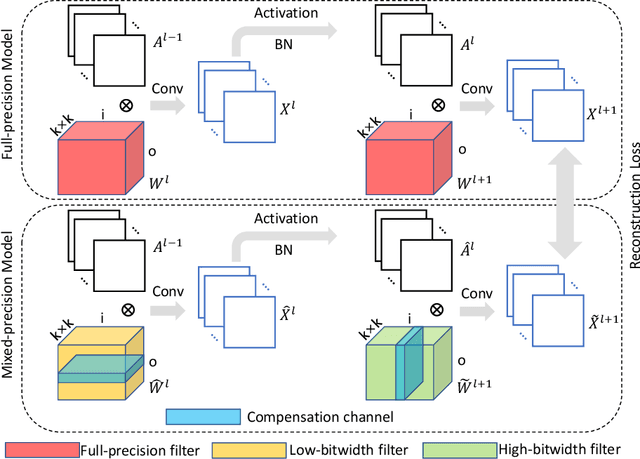
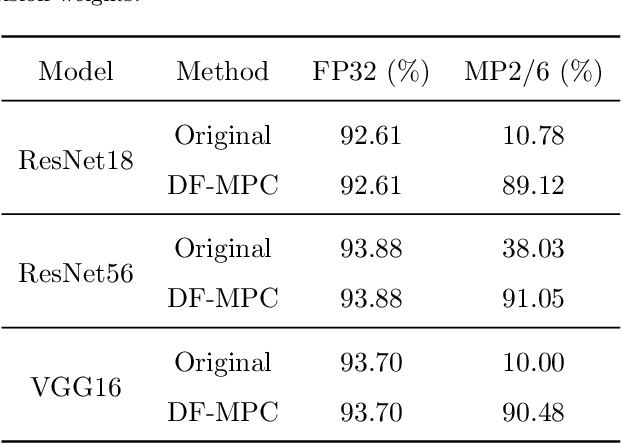
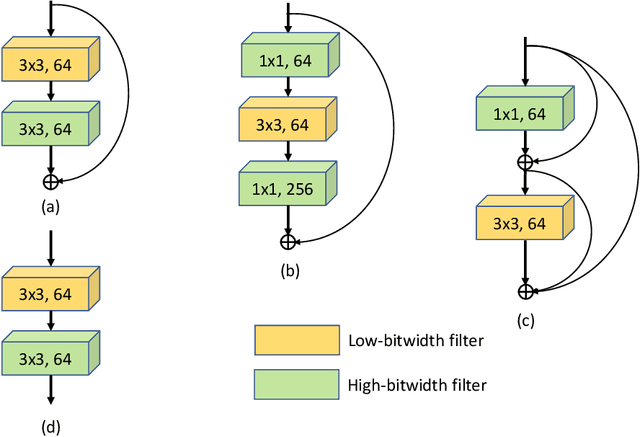
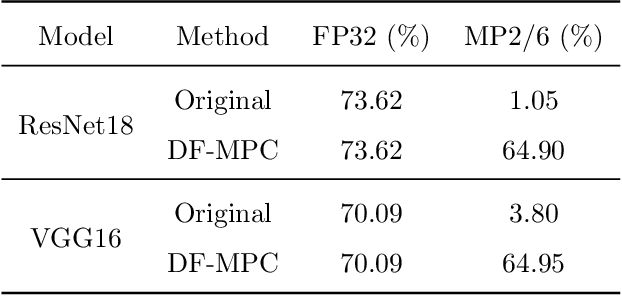
Neural network quantization is a very promising solution in the field of model compression, but its resulting accuracy highly depends on a training/fine-tuning process and requires the original data. This not only brings heavy computation and time costs but also is not conducive to privacy and sensitive information protection. Therefore, a few recent works are starting to focus on data-free quantization. However, data-free quantization does not perform well while dealing with ultra-low precision quantization. Although researchers utilize generative methods of synthetic data to address this problem partially, data synthesis needs to take a lot of computation and time. In this paper, we propose a data-free mixed-precision compensation (DF-MPC) method to recover the performance of an ultra-low precision quantized model without any data and fine-tuning process. By assuming the quantized error caused by a low-precision quantized layer can be restored via the reconstruction of a high-precision quantized layer, we mathematically formulate the reconstruction loss between the pre-trained full-precision model and its layer-wise mixed-precision quantized model. Based on our formulation, we theoretically deduce the closed-form solution by minimizing the reconstruction loss of the feature maps. Since DF-MPC does not require any original/synthetic data, it is a more efficient method to approximate the full-precision model. Experimentally, our DF-MPC is able to achieve higher accuracy for an ultra-low precision quantized model compared to the recent methods without any data and fine-tuning process.
* This paper has been accepted for publication in the Pattern Recognition
What Makes ImageNet Look Unlike LAION
Jun 27, 2023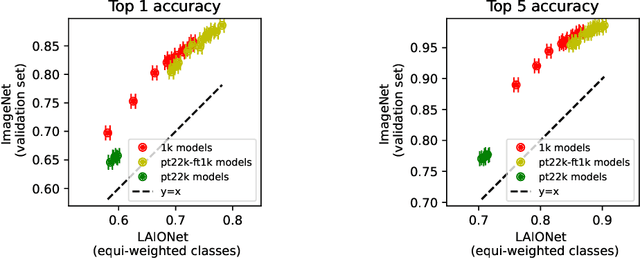
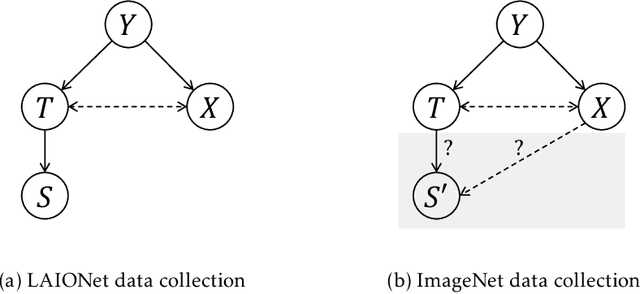
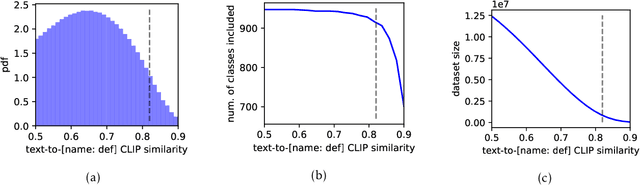
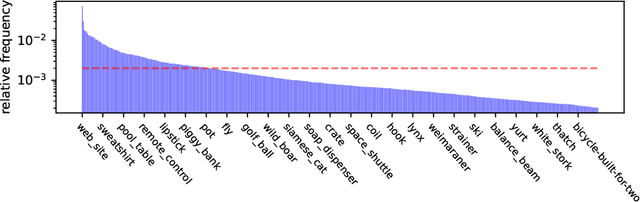
ImageNet was famously created from Flickr image search results. What if we recreated ImageNet instead by searching the massive LAION dataset based on image captions alone? In this work, we carry out this counterfactual investigation. We find that the resulting ImageNet recreation, which we call LAIONet, looks distinctly unlike the original. Specifically, the intra-class similarity of images in the original ImageNet is dramatically higher than it is for LAIONet. Consequently, models trained on ImageNet perform significantly worse on LAIONet. We propose a rigorous explanation for the discrepancy in terms of a subtle, yet important, difference in two plausible causal data-generating processes for the respective datasets, that we support with systematic experimentation. In a nutshell, searching based on an image caption alone creates an information bottleneck that mitigates the selection bias otherwise present in image-based filtering. Our explanation formalizes a long-held intuition in the community that ImageNet images are stereotypical, unnatural, and overly simple representations of the class category. At the same time, it provides a simple and actionable takeaway for future dataset creation efforts.
Cross-Language Speech Emotion Recognition Using Multimodal Dual Attention Transformers
Jun 27, 2023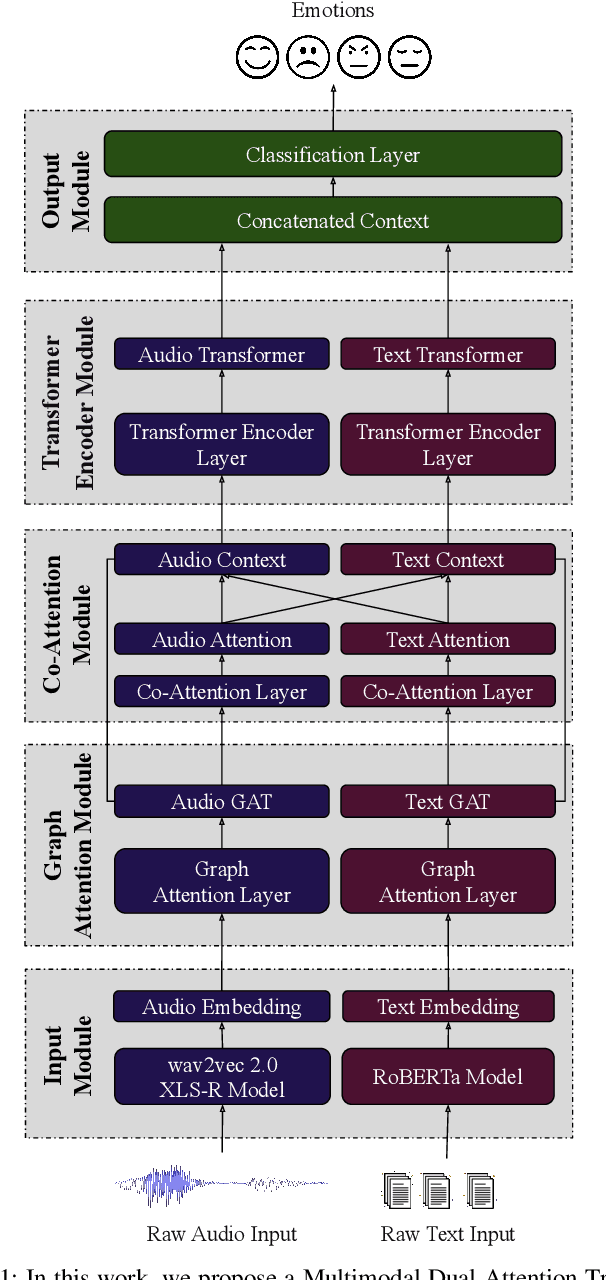
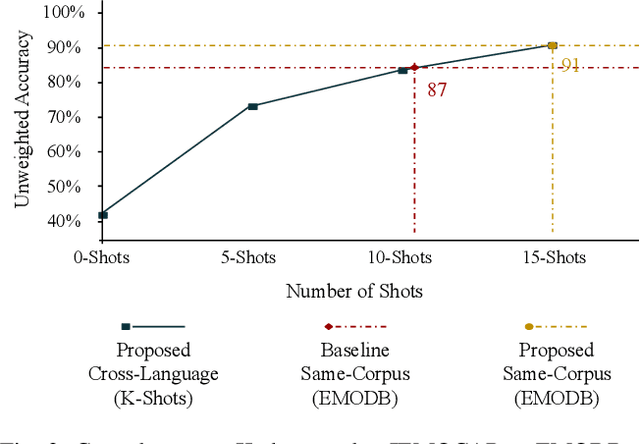
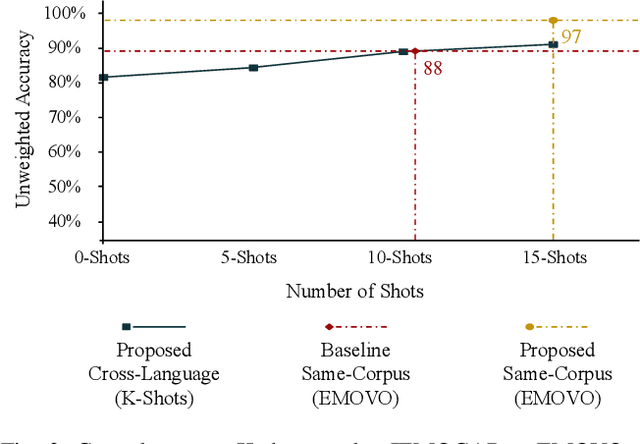
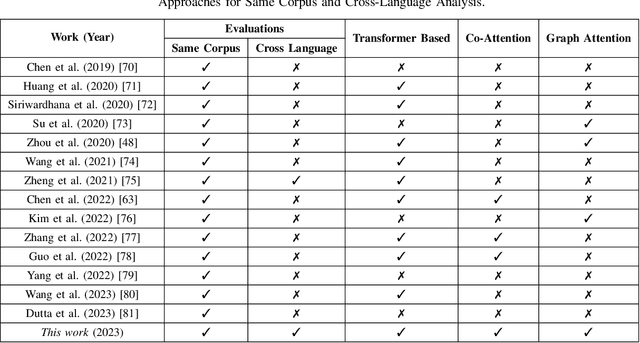
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems are unable to achieve improved performance in cross-language settings. In this paper, we propose a Multimodal Dual Attention Transformer (MDAT) model to improve cross-language SER. Our model utilises pre-trained models for multimodal feature extraction and is equipped with a dual attention mechanism including graph attention and co-attention to capture complex dependencies across different modalities and achieve improved cross-language SER results using minimal target language data. In addition, our model also exploits a transformer encoder layer for high-level feature representation to improve emotion classification accuracy. In this way, MDAT performs refinement of feature representation at various stages and provides emotional salient features to the classification layer. This novel approach also ensures the preservation of modality-specific emotional information while enhancing cross-modality and cross-language interactions. We assess our model's performance on four publicly available SER datasets and establish its superior effectiveness compared to recent approaches and baseline models.
Rethinking Closed-loop Training for Autonomous Driving
Jun 27, 2023Recent advances in high-fidelity simulators have enabled closed-loop training of autonomous driving agents, potentially solving the distribution shift in training v.s. deployment and allowing training to be scaled both safely and cheaply. However, there is a lack of understanding of how to build effective training benchmarks for closed-loop training. In this work, we present the first empirical study which analyzes the effects of different training benchmark designs on the success of learning agents, such as how to design traffic scenarios and scale training environments. Furthermore, we show that many popular RL algorithms cannot achieve satisfactory performance in the context of autonomous driving, as they lack long-term planning and take an extremely long time to train. To address these issues, we propose trajectory value learning (TRAVL), an RL-based driving agent that performs planning with multistep look-ahead and exploits cheaply generated imagined data for efficient learning. Our experiments show that TRAVL can learn much faster and produce safer maneuvers compared to all the baselines. For more information, visit the project website: https://waabi.ai/research/travl
Effective resistance in metric spaces
Jun 27, 2023Effective resistance (ER) is an attractive way to interrogate the structure of graphs. It is an alternative to computing the eigenvectors of the graph Laplacian. One attractive application of ER is to point clouds, i.e. graphs whose vertices correspond to IID samples from a distribution over a metric space. Unfortunately, it was shown that the ER between any two points converges to a trivial quantity that holds no information about the graph's structure as the size of the sample increases to infinity. In this study, we show that this trivial solution can be circumvented by considering a region-based ER between pairs of small regions rather than pairs of points and by scaling the edge weights appropriately with respect to the underlying density in each region. By keeping the regions fixed, we show analytically that the region-based ER converges to a non-trivial limit as the number of points increases to infinity. Namely the ER on a metric space. We support our theoretical findings with numerical experiments.