 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spinal nerve segmentation method and dataset construction in endoscopic surgical scenarios
Jul 20, 2023
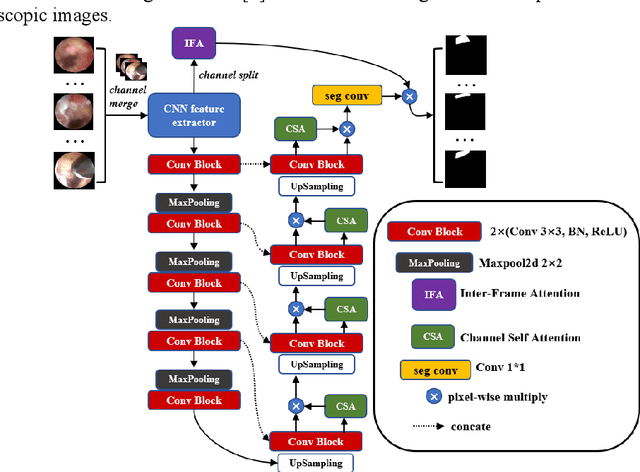
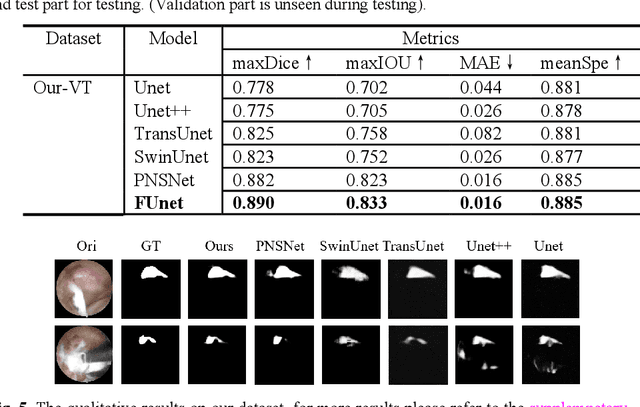
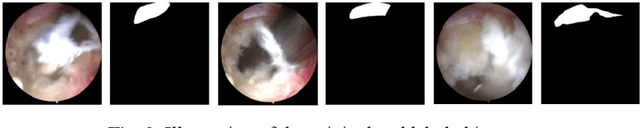

Endoscopic surgery is currently an important treatment method in the field of spinal surgery and avoiding damage to the spinal nerves through video guidance is a key challenge. This paper presents the first real-time segmentation method for spinal nerves in endoscopic surgery, which provides crucial navigational information for surgeons. A finely annotated segmentation dataset of approximately 10,000 consec-utive frames recorded during surgery is constructed for the first time for this field, addressing the problem of semantic segmentation. Based on this dataset, we propose FUnet (Frame-Unet), which achieves state-of-the-art performance by utilizing inter-frame information and self-attention mechanisms. We also conduct extended exper-iments on a similar polyp endoscopy video dataset and show that the model has good generalization ability with advantageous performance. The dataset and code of this work are presented at: https://github.com/zzzzzzpc/FUnet .
ETHER: Aligning Emergent Communication for Hindsight Experience Replay
Jul 28, 2023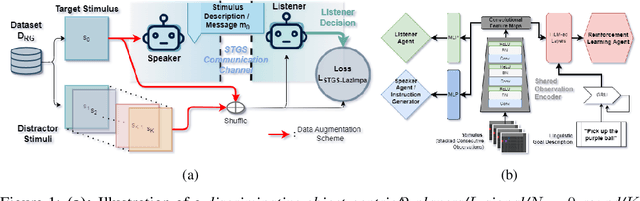
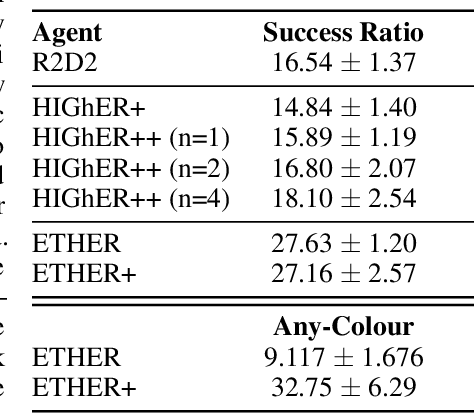
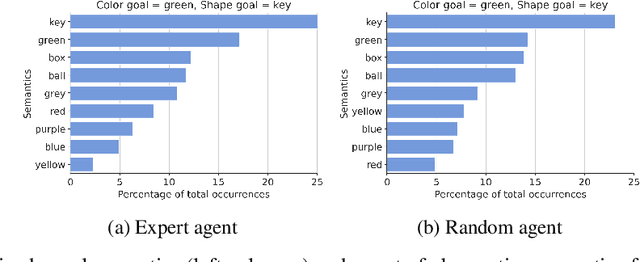

Natural language instruction following is paramount to enable collaboration between artificial agents and human beings. Natural language-conditioned reinforcement learning (RL) agents have shown how natural languages' properties, such as compositionality, can provide a strong inductive bias to learn complex policies. Previous architectures like HIGhER combine the benefit of language-conditioning with Hindsight Experience Replay (HER) to deal with sparse rewards environments. Yet, like HER, HIGhER relies on an oracle predicate function to provide a feedback signal highlighting which linguistic description is valid for which state. This reliance on an oracle limits its application. Additionally, HIGhER only leverages the linguistic information contained in successful RL trajectories, thus hurting its final performance and data-efficiency. Without early successful trajectories, HIGhER is no better than DQN upon which it is built. In this paper, we propose the Emergent Textual Hindsight Experience Replay (ETHER) agent, which builds on HIGhER and addresses both of its limitations by means of (i) a discriminative visual referential game, commonly studied in the subfield of Emergent Communication (EC), used here as an unsupervised auxiliary task and (ii) a semantic grounding scheme to align the emergent language with the natural language of the instruction-following benchmark. We show that the referential game's agents make an artificial language emerge that is aligned with the natural-like language used to describe goals in the BabyAI benchmark and that it is expressive enough so as to also describe unsuccessful RL trajectories and thus provide feedback to the RL agent to leverage the linguistic, structured information contained in all trajectories. Our work shows that EC is a viable unsupervised auxiliary task for RL and provides missing pieces to make HER more widely applicable.
Label Information Bottleneck for Label Enhancement
Mar 14, 2023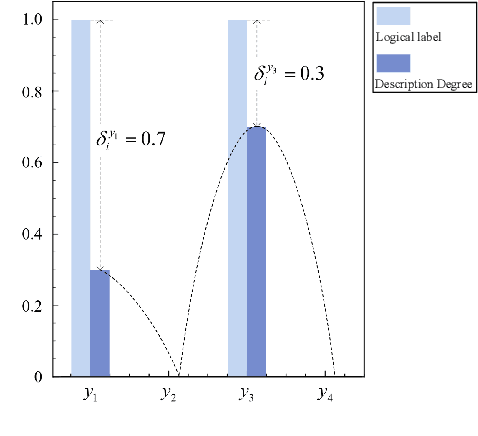
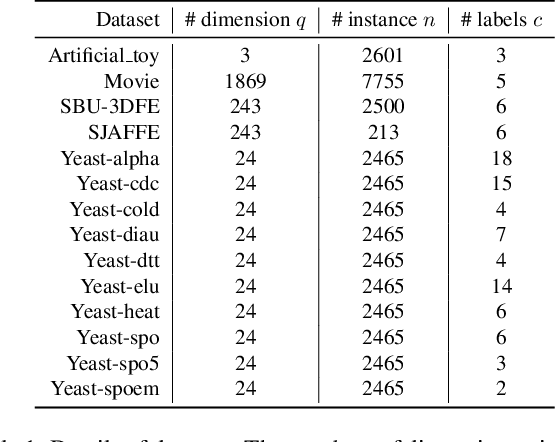
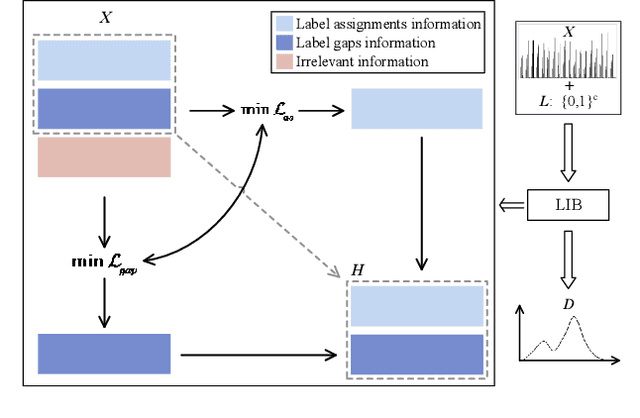
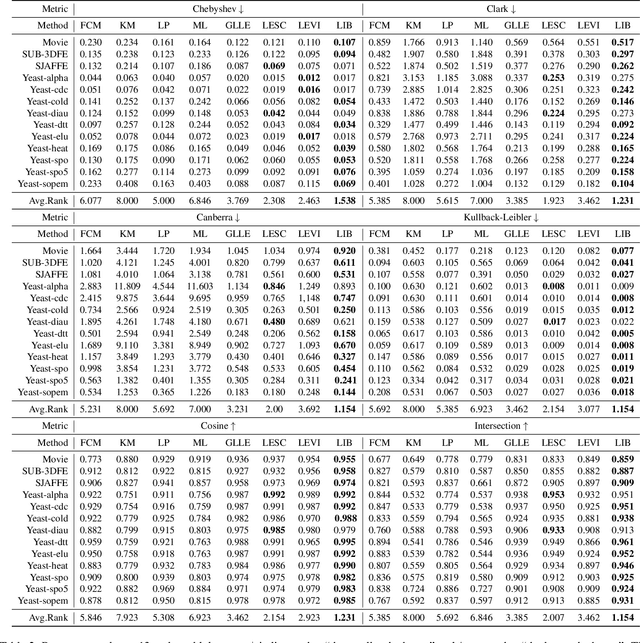
In this work, we focus on the challenging problem of Label Enhancement (LE), which aims to exactly recover label distributions from logical labels, and present a novel Label Information Bottleneck (LIB) method for LE. For the recovery process of label distributions, the label irrelevant information contained in the dataset may lead to unsatisfactory recovery performance. To address this limitation, we make efforts to excavate the essential label relevant information to improve the recovery performance. Our method formulates the LE problem as the following two joint processes: 1) learning the representation with the essential label relevant information, 2) recovering label distributions based on the learned representation. The label relevant information can be excavated based on the "bottleneck" formed by the learned representation. Significantly, both the label relevant information about the label assignments and the label relevant information about the label gaps can be explored in our method. Evaluation experiments conducted on several benchmark label distribution learning datasets verify the effectiveness and competitiveness of LIB. Our source codes are available https://github.com/qinghai-zheng/LIBLE
Learning Resource Allocation Policy: Vertex-GNN or Edge-GNN?
Jul 24, 2023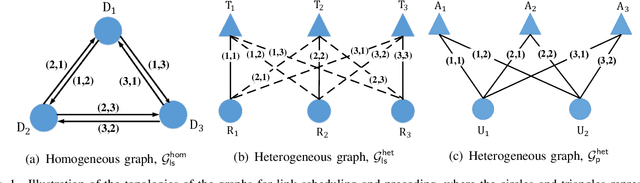
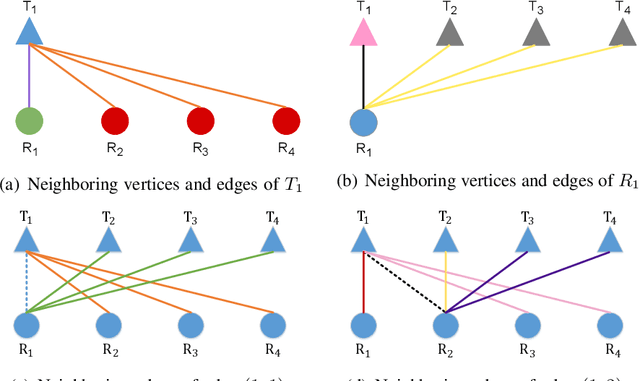
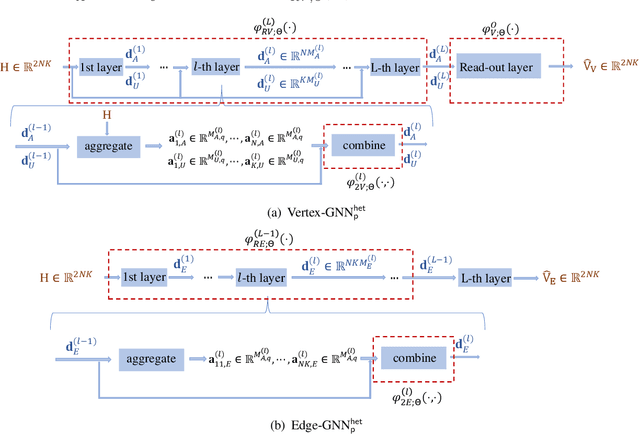
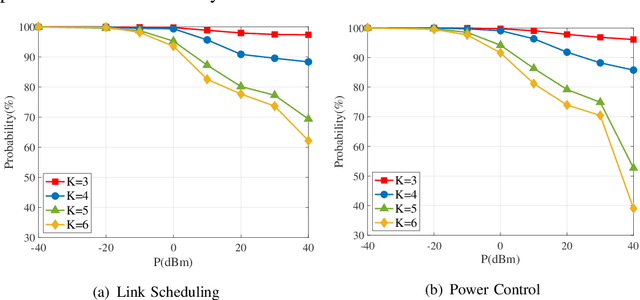
Graph neural networks (GNNs) update the hidden representations of vertices (called Vertex-GNNs) or hidden representations of edges (called Edge-GNNs) by processing and pooling the information of neighboring vertices and edges and combining to incorporate graph topology. When learning resource allocation policies, GNNs cannot perform well if their expressive power are weak, i.e., if they cannot differentiate all input features such as channel matrices. In this paper, we analyze the expressive power of the Vertex-GNNs and Edge-GNNs for learning three representative wireless policies: link scheduling, power control, and precoding policies. We find that the expressive power of the GNNs depend on the linearity and output dimensions of the processing and combination functions. When linear processors are used, the Vertex-GNNs cannot differentiate all channel matrices due to the loss of channel information, while the Edge-GNNs can. When learning the precoding policy, even the Vertex-GNNs with non-linear processors may not be with strong expressive ability due to the dimension compression. We proceed to provide necessary conditions for the GNNs to well learn the precoding policy. Simulation results validate the analyses and show that the Edge-GNNs can achieve the same performance as the Vertex-GNNs with much lower training and inference time.
InvVis: Large-Scale Data Embedding for Invertible Visualization
Jul 30, 2023
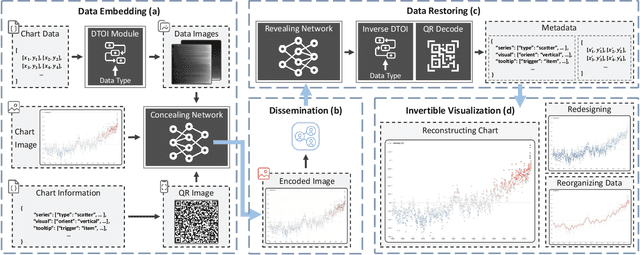
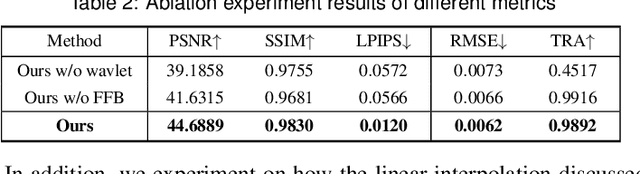
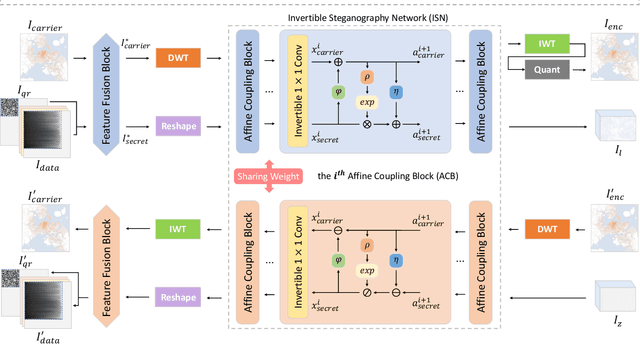
We present InvVis, a new approach for invertible visualization, which is reconstructing or further modifying a visualization from an image. InvVis allows the embedding of a significant amount of data, such as chart data, chart information, source code, etc., into visualization images. The encoded image is perceptually indistinguishable from the original one. We propose a new method to efficiently express chart data in the form of images, enabling large-capacity data embedding. We also outline a model based on the invertible neural network to achieve high-quality data concealing and revealing. We explore and implement a variety of application scenarios of InvVis. Additionally, we conduct a series of evaluation experiments to assess our method from multiple perspectives, including data embedding quality, data restoration accuracy, data encoding capacity, etc. The result of our experiments demonstrates the great potential of InvVis in invertible visualization.
Model Provenance via Model DNA
Aug 04, 2023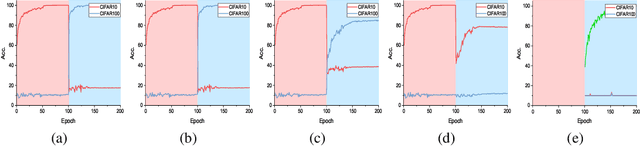

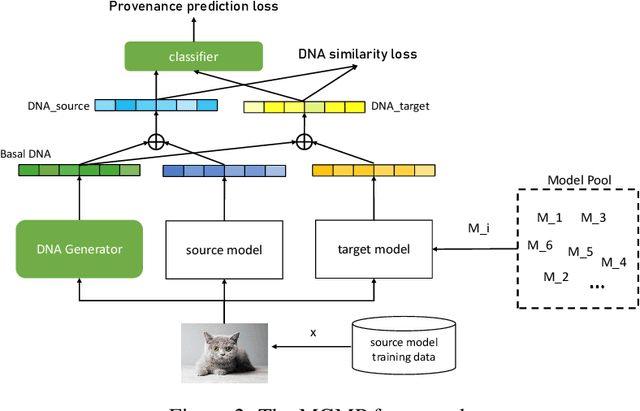
Understanding the life cycle of the machine learning (ML) model is an intriguing area of research (e.g., understanding where the model comes from, how it is trained, and how it is used). This paper focuses on a novel problem within this field, namely Model Provenance (MP), which concerns the relationship between a target model and its pre-training model and aims to determine whether a source model serves as the provenance for a target model. This is an important problem that has significant implications for ensuring the security and intellectual property of machine learning models but has not received much attention in the literature. To fill in this gap, we introduce a novel concept of Model DNA which represents the unique characteristics of a machine learning model. We utilize a data-driven and model-driven representation learning method to encode the model's training data and input-output information as a compact and comprehensive representation (i.e., DNA) of the model. Using this model DNA, we develop an efficient framework for model provenance identification, which enables us to identify whether a source model is a pre-training model of a target model. We conduct evaluations on both computer vision and natural language processing tasks using various models, datasets, and scenarios to demonstrate the effectiveness of our approach in accurately identifying model provenance.
DIVERSIFY: A General Framework for Time Series Out-of-distribution Detection and Generalization
Aug 04, 2023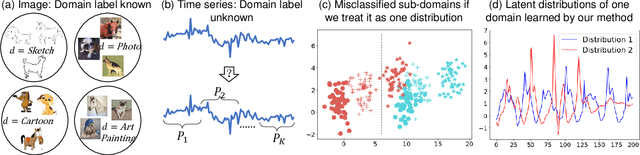
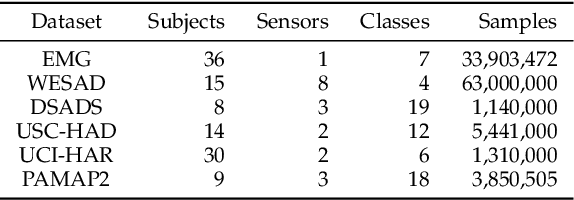

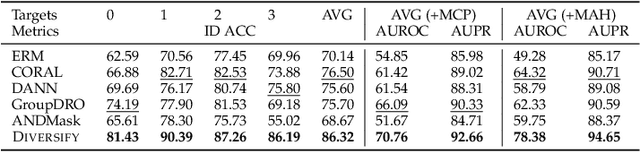
Time series remains one of the most challenging modalities in machine learning research. The out-of-distribution (OOD) detection and generalization on time series tend to suffer due to its non-stationary property, i.e., the distribution changes over time. The dynamic distributions inside time series pose great challenges to existing algorithms to identify invariant distributions since they mainly focus on the scenario where the domain information is given as prior knowledge. In this paper, we attempt to exploit subdomains within a whole dataset to counteract issues induced by non-stationary for generalized representation learning. We propose DIVERSIFY, a general framework, for OOD detection and generalization on dynamic distributions of time series. DIVERSIFY takes an iterative process: it first obtains the "worst-case" latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We implement DIVERSIFY via combining existing OOD detection methods according to either extracted features or outputs of models for detection while we also directly utilize outputs for classification. In addition, theoretical insights illustrate that DIVERSIFY is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY learns more generalized features and significantly outperforms other baselines.
Erasing, Transforming, and Noising Defense Network for Occluded Person Re-Identification
Jul 14, 2023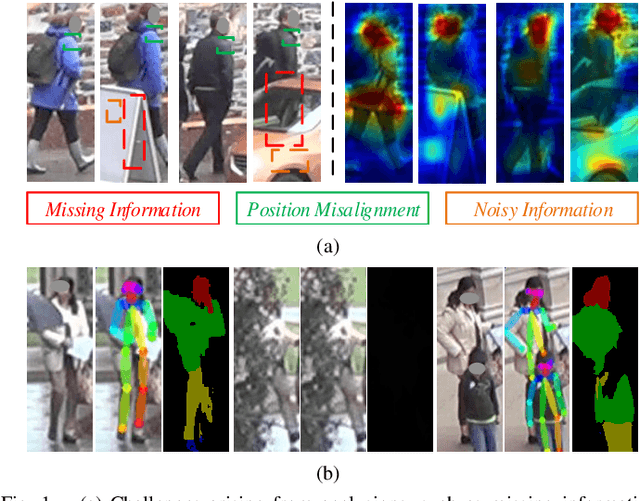
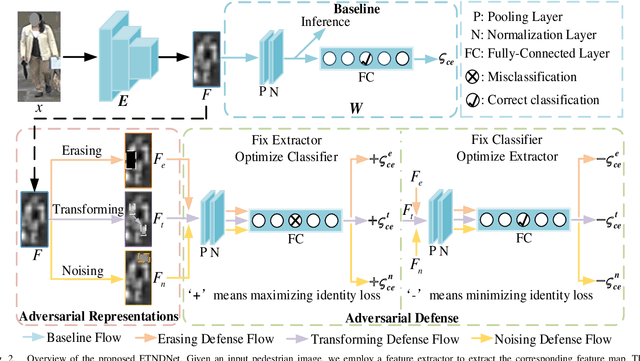
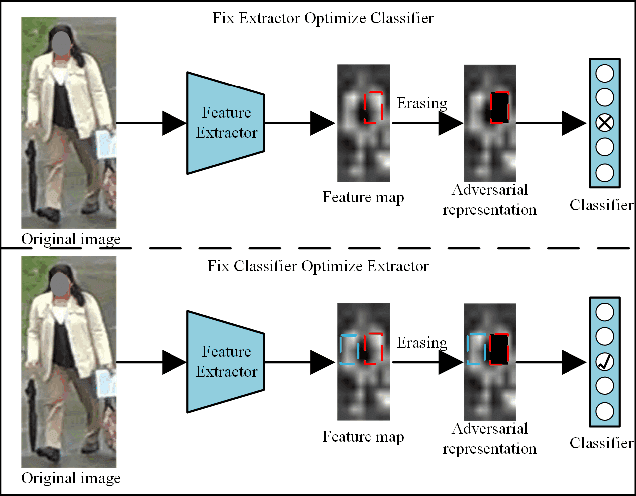
Occlusion perturbation presents a significant challenge in person re-identification (re-ID), and existing methods that rely on external visual cues require additional computational resources and only consider the issue of missing information caused by occlusion. In this paper, we propose a simple yet effective framework, termed Erasing, Transforming, and Noising Defense Network (ETNDNet), which treats occlusion as a noise disturbance and solves occluded person re-ID from the perspective of adversarial defense. In the proposed ETNDNet, we introduce three strategies: Firstly, we randomly erase the feature map to create an adversarial representation with incomplete information, enabling adversarial learning of identity loss to protect the re-ID system from the disturbance of missing information. Secondly, we introduce random transformations to simulate the position misalignment caused by occlusion, training the extractor and classifier adversarially to learn robust representations immune to misaligned information. Thirdly, we perturb the feature map with random values to address noisy information introduced by obstacles and non-target pedestrians, and employ adversarial gaming in the re-ID system to enhance its resistance to occlusion noise. Without bells and whistles, ETNDNet has three key highlights: (i) it does not require any external modules with parameters, (ii) it effectively handles various issues caused by occlusion from obstacles and non-target pedestrians, and (iii) it designs the first GAN-based adversarial defense paradigm for occluded person re-ID. Extensive experiments on five public datasets fully demonstrate the effectiveness, superiority, and practicality of the proposed ETNDNet. The code will be released at \url{https://github.com/nengdong96/ETNDNet}.
FDCT: Fast Depth Completion for Transparent Objects
Jul 23, 2023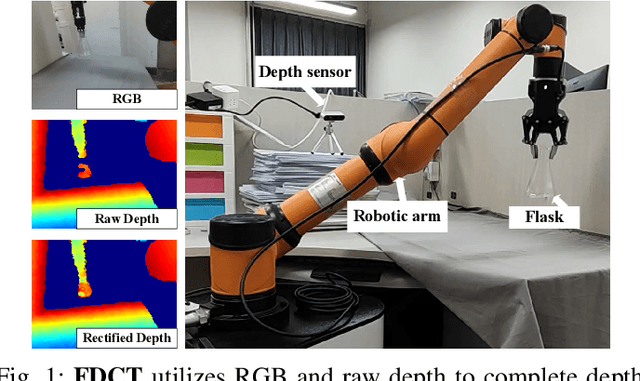
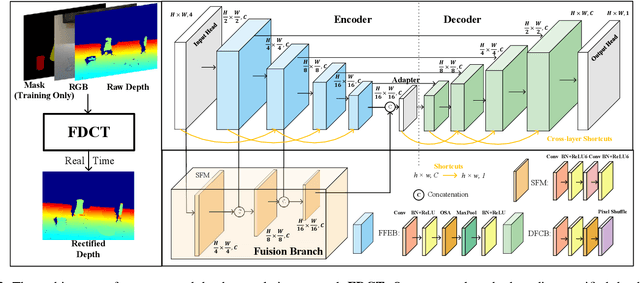
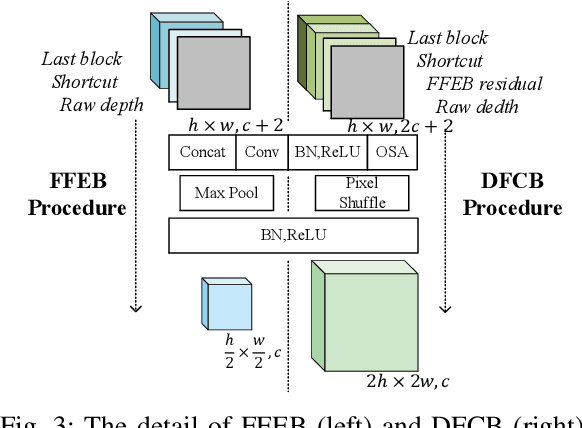
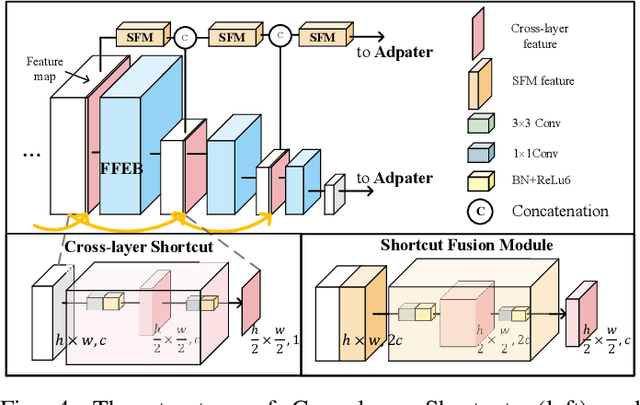
Depth completion is crucial for many robotic tasks such as autonomous driving, 3-D reconstruction, and manipulation. Despite the significant progress, existing methods remain computationally intensive and often fail to meet the real-time requirements of low-power robotic platforms. Additionally, most methods are designed for opaque objects and struggle with transparent objects due to the special properties of reflection and refraction. To address these challenges, we propose a Fast Depth Completion framework for Transparent objects (FDCT), which also benefits downstream tasks like object pose estimation. To leverage local information and avoid overfitting issues when integrating it with global information, we design a new fusion branch and shortcuts to exploit low-level features and a loss function to suppress overfitting. This results in an accurate and user-friendly depth rectification framework which can recover dense depth estimation from RGB-D images alone. Extensive experiments demonstrate that FDCT can run about 70 FPS with a higher accuracy than the state-of-the-art methods. We also demonstrate that FDCT can improve pose estimation in object grasping tasks. The source code is available at https://github.com/Nonmy/FDCT
A Generalized Schwarz-type Non-overlapping Domain Decomposition Method using Physics-constrained Neural Networks
Jul 23, 2023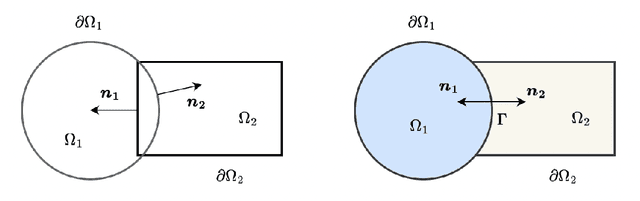

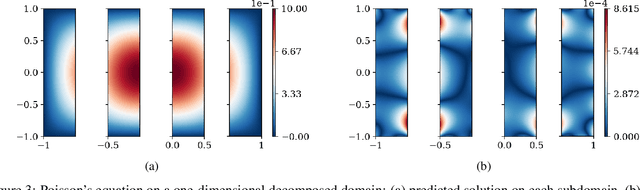
We present a meshless Schwarz-type non-overlapping domain decomposition method based on artificial neural networks for solving forward and inverse problems involving partial differential equations (PDEs). To ensure the consistency of solutions across neighboring subdomains, we adopt a generalized Robin-type interface condition, assigning unique Robin parameters to each subdomain. These subdomain-specific Robin parameters are learned to minimize the mismatch on the Robin interface condition, facilitating efficient information exchange during training. Our method is applicable to both the Laplace's and Helmholtz equations. It represents local solutions by an independent neural network model which is trained to minimize the loss on the governing PDE while strictly enforcing boundary and interface conditions through an augmented Lagrangian formalism. A key strength of our method lies in its ability to learn a Robin parameter for each subdomain, thereby enhancing information exchange with its neighboring subdomains. We observe that the learned Robin parameters adapt to the local behavior of the solution, domain partitioning and subdomain location relative to the overall domain. Extensive experiments on forward and inverse problems, including one-way and two-way decompositions with crosspoints, demonstrate the versatility and performance of our proposed approach.