 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Schwarz-type Non-overlapping Domain Decomposition Method using Physics-constrained Neural Networks
Jul 23, 2023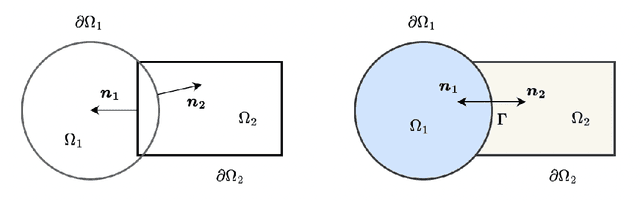

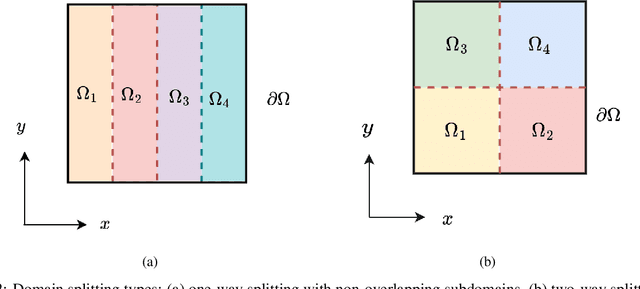
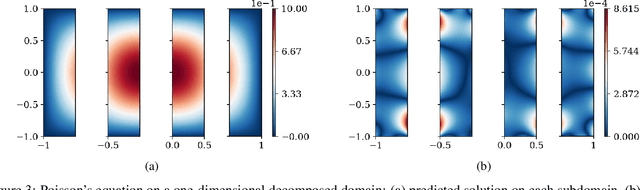
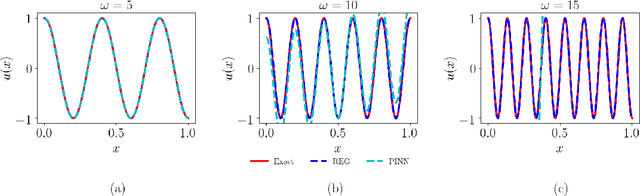
We present a meshless Schwarz-type non-overlapping domain decomposition method based on artificial neural networks for solving forward and inverse problems involving partial differential equations (PDEs). To ensure the consistency of solutions across neighboring subdomains, we adopt a generalized Robin-type interface condition, assigning unique Robin parameters to each subdomain. These subdomain-specific Robin parameters are learned to minimize the mismatch on the Robin interface condition, facilitating efficient information exchange during training. Our method is applicable to both the Laplace's and Helmholtz equations. It represents local solutions by an independent neural network model which is trained to minimize the loss on the governing PDE while strictly enforcing boundary and interface conditions through an augmented Lagrangian formalism. A key strength of our method lies in its ability to learn a Robin parameter for each subdomain, thereby enhancing information exchange with its neighboring subdomains. We observe that the learned Robin parameters adapt to the local behavior of the solution, domain partitioning and subdomain location relative to the overall domain. Extensive experiments on forward and inverse problems, including one-way and two-way decompositions with crosspoints, demonstrate the versatility and performance of our proposed approach.
An adaptive augmented Lagrangian method for training physics and equality constrained artificial neural networks
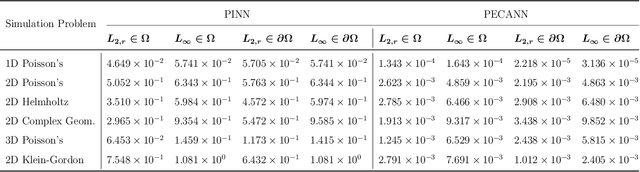
Jun 08, 2023Physics and equality constrained artificial neural networks (PECANN) are grounded in methods of constrained optimization to properly constrain the solution of partial differential equations (PDEs) with their boundary and initial conditions and any high-fidelity data that may be available. To this end, adoption of the augmented Lagrangian method within the PECANN framework is paramount for learning the solution of PDEs without manually balancing the individual loss terms in the objective function used for determining the parameters of the neural network. Generally speaking, ALM combines the merits of the penalty and Lagrange multiplier methods while avoiding the ill conditioning and convergence issues associated singly with these methods . In the present work, we apply our PECANN framework to solve forward and inverse problems that have an expanded and diverse set of constraints. We show that ALM with its conventional formulation to update its penalty parameter and Lagrange multipliers stalls for such challenging problems. To address this issue, we propose an adaptive ALM in which each constraint is assigned a unique penalty parameter that evolve adaptively according to a rule inspired by the adaptive subgradient method. Additionally, we revise our PECANN formulation for improved computational efficiency and savings which allows for mini-batch training. We demonstrate the efficacy of our proposed approach by solving several forward and PDE-constrained inverse problems with noisy data, including simulation of incompressible fluid flows with a primitive-variables formulation of the Navier-Stokes equations up to a Reynolds number of 1000.
Investigating and Mitigating Failure Modes in Physics-informed Neural Networks (PINNs)
Sep 20, 2022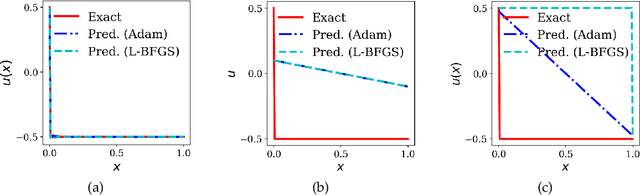

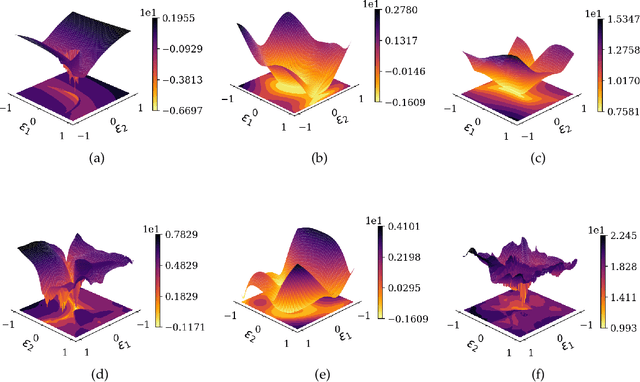
In this paper, we demonstrate and investigate several challenges that stand in the way of tackling complex problems using physics-informed neural networks. In particular, we visualize the loss landscapes of trained models and perform sensitivity analysis of backpropagated gradients in the presence of physics. Our findings suggest that existing methods produce highly non-convex loss landscapes that are difficult to navigate. Furthermore, high-order PDEs contaminate the backpropagated gradients that may impede or prevent convergence. We then propose a novel method that bypasses the calculation of high-order PDE operators and mitigates the contamination of backpropagating gradients. In doing so, we reduce the dimension of the search space of our solution and facilitate learning problems with non-smooth solutions. Our formulation also provides a feedback mechanism that helps our model adaptively focus on complex regions of the domain that are difficult to learn. We then formulate an unconstrained dual problem by adapting the Lagrange multiplier method. We apply our method to solve several challenging benchmark problems governed by linear and non-linear PDEs.
Critical Investigation of Failure Modes in Physics-informed Neural Networks
Jun 28, 2022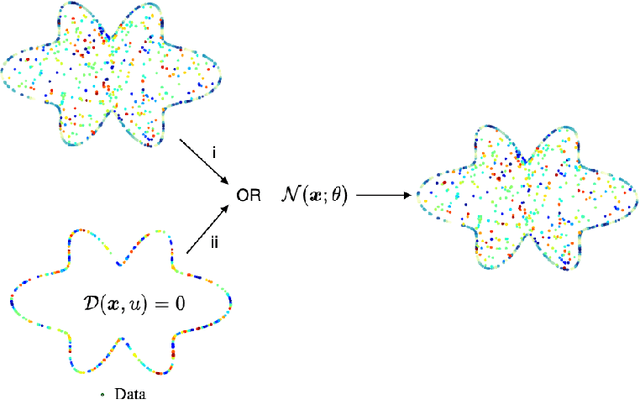
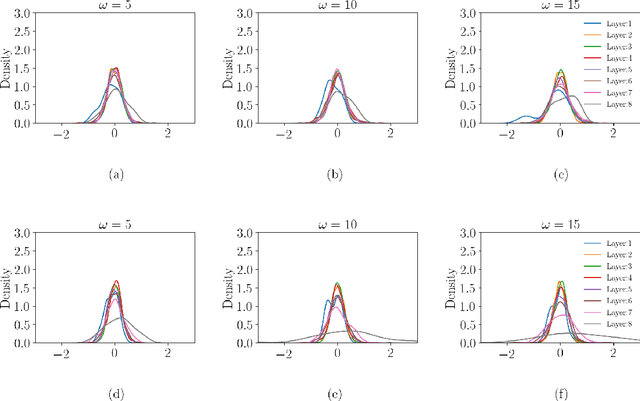
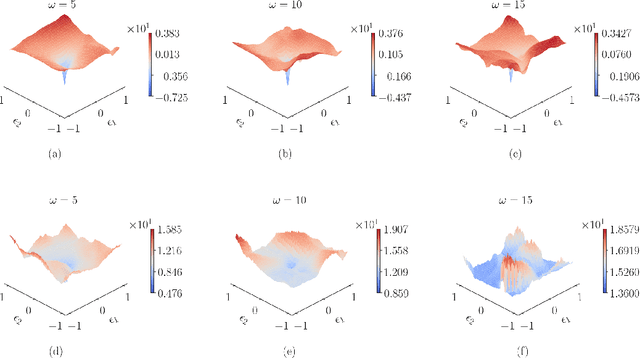
Several recent works in scientific machine learning have revived interest in the application of neural networks to partial differential equations (PDEs). A popular approach is to aggregate the residual form of the governing PDE and its boundary conditions as soft penalties into a composite objective/loss function for training neural networks, which is commonly referred to as physics-informed neural networks (PINNs). In the present study, we visualize the loss landscapes and distributions of learned parameters and explain the ways this particular formulation of the objective function may hinder or even prevent convergence when dealing with challenging target solutions. We construct a purely data-driven loss function composed of both the boundary loss and the domain loss. Using this data-driven loss function and, separately, a physics-informed loss function, we then train two neural network models with the same architecture. We show that incomparable scales between boundary and domain loss terms are the culprit behind the poor performance. Additionally, we assess the performance of both approaches on two elliptic problems with increasingly complex target solutions. Based on our analysis of their loss landscapes and learned parameter distributions, we observe that a physics-informed neural network with a composite objective function formulation produces highly non-convex loss surfaces that are difficult to optimize and are more prone to the problem of vanishing gradients.
Mitigating Learning Complexity in Physics and Equality Constrained Artificial Neural Networks
Jun 19, 2022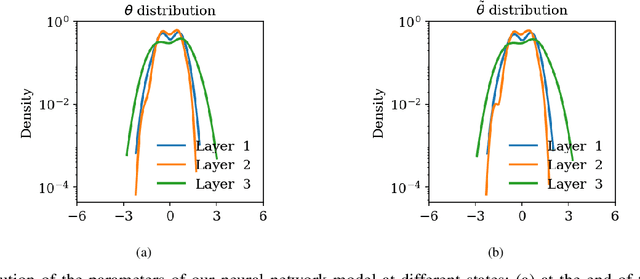
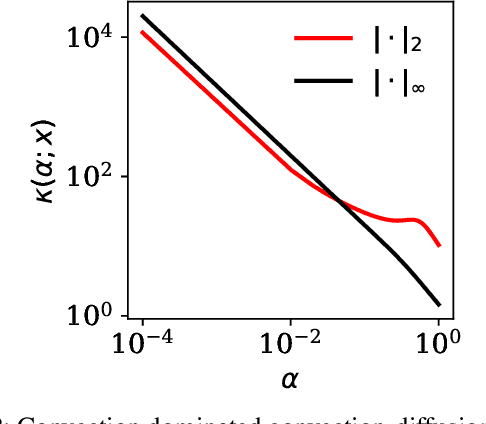
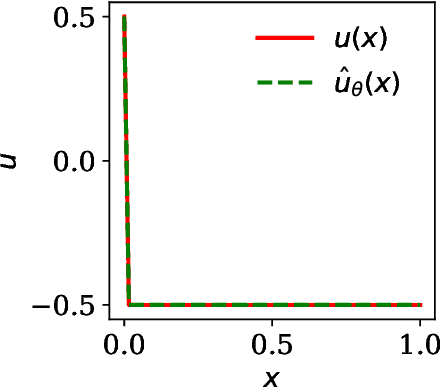
Physics-informed neural networks (PINNs) have been proposed to learn the solution of partial differential equations (PDE). In PINNs, the residual form of the PDE of interest and its boundary conditions are lumped into a composite objective function as soft penalties. Here, we show that this specific way of formulating the objective function is the source of severe limitations in the PINN approach when applied to different kinds of PDEs. To address these limitations, we propose a versatile framework based on a constrained optimization problem formulation, where we use the augmented Lagrangian method (ALM) to constrain the solution of a PDE with its boundary conditions and any high-fidelity data that may be available. Our approach is adept at forward and inverse problems with multi-fidelity data fusion. We demonstrate the efficacy and versatility of our physics- and equality-constrained deep-learning framework by applying it to several forward and inverse problems involving multi-dimensional PDEs.Our framework achieves orders of magnitude improvements in accuracy levels in comparison with state-of-the-art physics-informed neural networks.
Physics and Equality Constrained Artificial Neural Networks: Application to Partial Differential Equations
Sep 30, 2021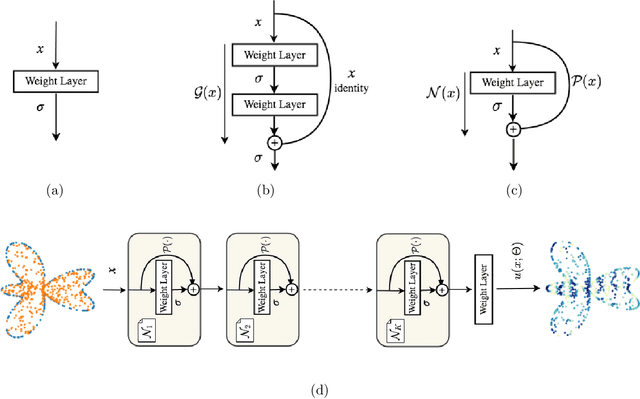
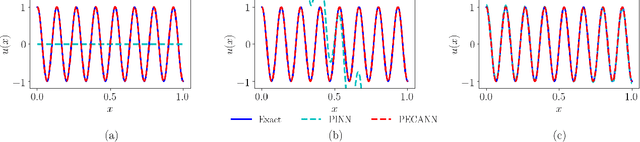

Physics-informed neural networks (PINNs) have been proposed to learn the solution of partial differential equations (PDE). In PINNs, the residual form of the PDE of interest and its boundary conditions are lumped into a composite objective function as an unconstrained optimization problem, which is then used to train a deep feed-forward neural network. Here, we show that this specific way of formulating the objective function is the source of severe limitations in the PINN approach when applied to different kinds of PDEs. To address these limitations, we propose a versatile framework that can tackle both inverse and forward problems. The framework is adept at multi-fidelity data fusion and can seamlessly constrain the governing physics equations with proper initial and boundary conditions. The backbone of the proposed framework is a nonlinear, equality-constrained optimization problem formulation aimed at minimizing a loss functional, where an augmented Lagrangian method (ALM) is used to formally convert a constrained-optimization problem into an unconstrained-optimization problem. We implement the ALM within a stochastic, gradient-descent type training algorithm in a way that scrupulously focuses on meeting the constraints without sacrificing other loss terms. Additionally, as a modification of the original residual layers, we propose lean residual layers in our neural network architecture to address the so-called vanishing-gradient problem. We demonstrate the efficacy and versatility of our physics- and equality-constrained deep-learning framework by applying it to learn the solutions of various multi-dimensional PDEs, including a nonlinear inverse problem from the hydrology field with multi-fidelity data fusion. The results produced with our proposed model match exact solutions very closely for all the cases considered.