 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CT-Net: Arbitrary-Shaped Text Detection via Contour Transformer
Jul 25, 2023
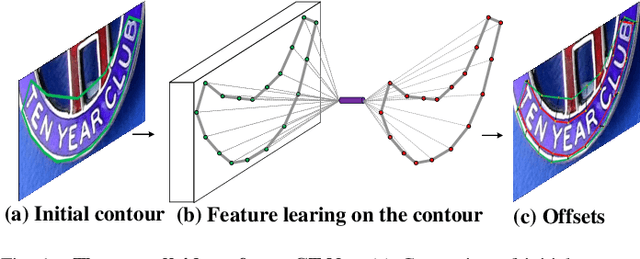
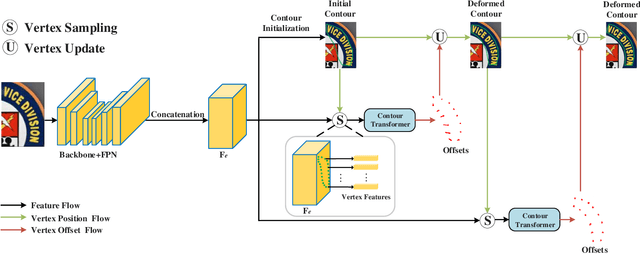

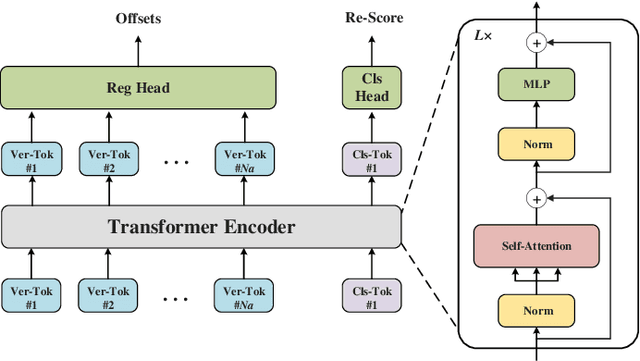
Contour based scene text detection methods have rapidly developed recently, but still suffer from inaccurate frontend contour initialization, multi-stage error accumulation, or deficient local information aggregation. To tackle these limitations, we propose a novel arbitrary-shaped scene text detection framework named CT-Net by progressive contour regression with contour transformers. Specifically, we first employ a contour initialization module that generates coarse text contours without any post-processing. Then, we adopt contour refinement modules to adaptively refine text contours in an iterative manner, which are beneficial for context information capturing and progressive global contour deformation. Besides, we propose an adaptive training strategy to enable the contour transformers to learn more potential deformation paths, and introduce a re-score mechanism that can effectively suppress false positives. Extensive experiments are conducted on four challenging datasets, which demonstrate the accuracy and efficiency of our CT-Net over state-of-the-art methods. Particularly, CT-Net achieves F-measure of 86.1 at 11.2 frames per second (FPS) and F-measure of 87.8 at 10.1 FPS for CTW1500 and Total-Text datasets, respectively.
Answering Unseen Questions With Smaller Language\\Models Using Rationale Generation and Dense Retrieval
Aug 09, 2023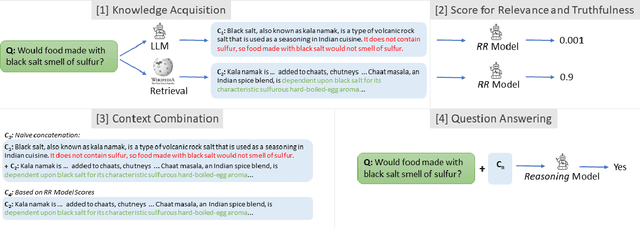
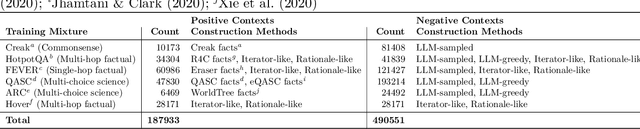
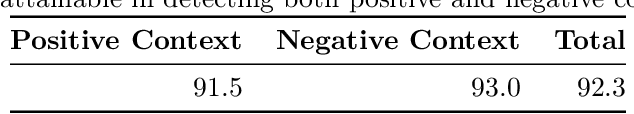
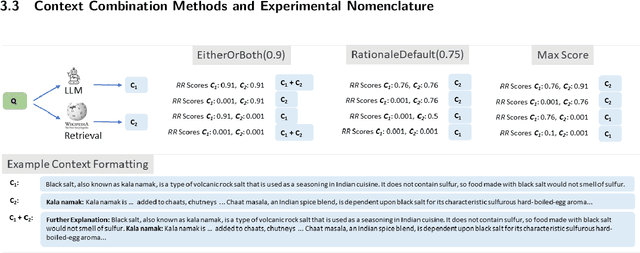
When provided with sufficient explanatory context, smaller Language Models have been shown to exhibit strong reasoning ability on challenging short-answer question-answering tasks where the questions are unseen in training. We evaluate two methods for further improvement in this setting. Both methods focus on combining rationales generated by a larger Language Model with longer contexts created from a multi-hop dense retrieval system. The first method ($\textit{RR}$) involves training a Rationale Ranking model to score both generated rationales and retrieved contexts with respect to relevance and truthfulness. We then use the scores to derive combined contexts from both knowledge sources using a number of combinatory strategies. For the second method ($\textit{RATD}$) we train a smaller Reasoning model using retrieval-augmented training datasets such that it becomes proficient at utilising relevant information from longer text sequences that may be only partially evidential and frequently contain many irrelevant sentences. Generally we find that both methods are effective but that the $\textit{RATD}$ method is more straightforward to apply and produces the strongest results in the unseen setting on which we focus. Our single best Reasoning model using only 440 million parameters materially improves upon strong comparable prior baselines for unseen evaluation datasets (StrategyQA 58.9 $\rightarrow$ 61.7 acc., CommonsenseQA 63.6 $\rightarrow$ 72.7 acc., ARC-DA 31.6 $\rightarrow$ 52.1 F1, IIRC 25.5 $\rightarrow$ 27.3 F1) and a version utilising our prior knowledge of each type of question in selecting a context combination strategy does even better. Our proposed models also generally outperform direct prompts against much larger models (BLOOM 175B and StableVicuna 13B) in both few-shot chain-of-thought and few-shot answer-only settings.
Non-equilibrium physics: from spin glasses to machine and neural learning
Aug 03, 2023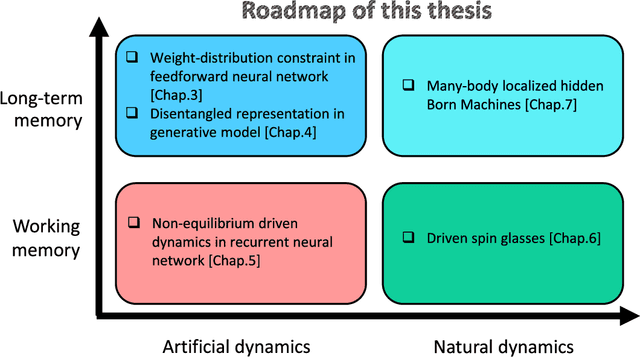
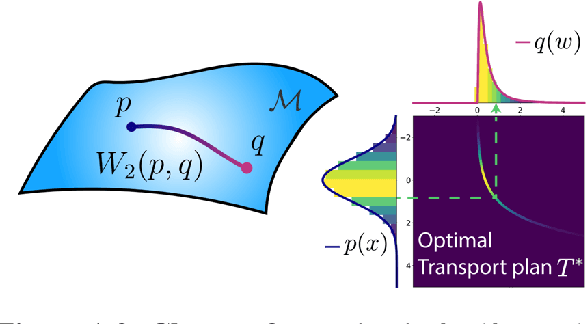
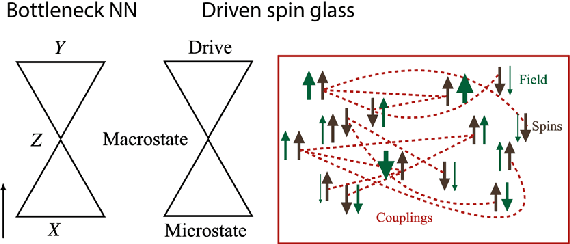
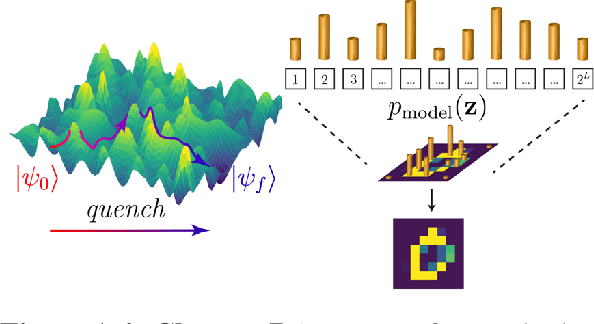
Disordered many-body systems exhibit a wide range of emergent phenomena across different scales. These complex behaviors can be utilized for various information processing tasks such as error correction, learning, and optimization. Despite the empirical success of utilizing these systems for intelligent tasks, the underlying principles that govern their emergent intelligent behaviors remain largely unknown. In this thesis, we aim to characterize such emergent intelligence in disordered systems through statistical physics. We chart a roadmap for our efforts in this thesis based on two axes: learning mechanisms (long-term memory vs. working memory) and learning dynamics (artificial vs. natural). Throughout our journey, we uncover relationships between learning mechanisms and physical dynamics that could serve as guiding principles for designing intelligent systems. We hope that our investigation into the emergent intelligence of seemingly disparate learning systems can expand our current understanding of intelligence beyond neural systems and uncover a wider range of computational substrates suitable for AI applications.
Federated Representation Learning for Automatic Speech Recognition
Aug 03, 2023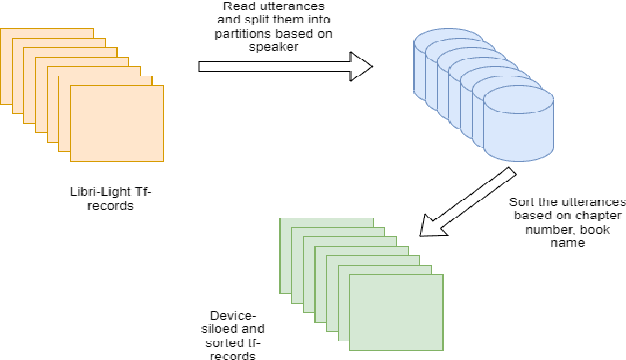
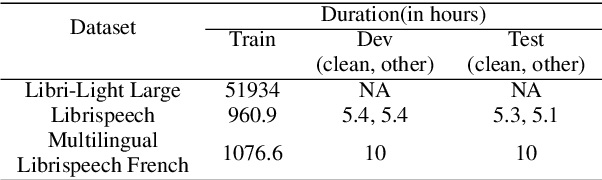
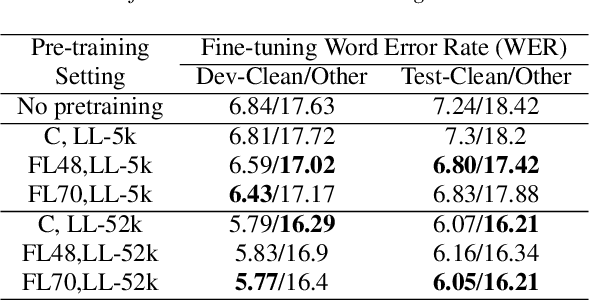
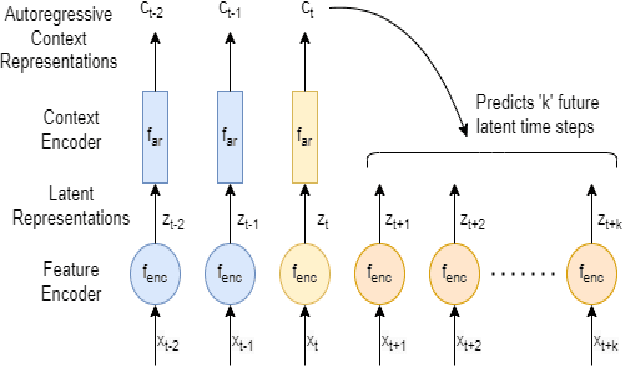
Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Online Multi-Task Learning with Recursive Least Squares and Recursive Kernel Methods
Aug 03, 2023This paper introduces two novel approaches for Online Multi-Task Learning (MTL) Regression Problems. We employ a high performance graph-based MTL formulation and develop its recursive versions based on the Weighted Recursive Least Squares (WRLS) and the Online Sparse Least Squares Support Vector Regression (OSLSSVR). Adopting task-stacking transformations, we demonstrate the existence of a single matrix incorporating the relationship of multiple tasks and providing structural information to be embodied by the MT-WRLS method in its initialization procedure and by the MT-OSLSSVR in its multi-task kernel function. Contrasting the existing literature, which is mostly based on Online Gradient Descent (OGD) or cubic inexact approaches, we achieve exact and approximate recursions with quadratic per-instance cost on the dimension of the input space (MT-WRLS) or on the size of the dictionary of instances (MT-OSLSSVR). We compare our online MTL methods to other contenders in a real-world wind speed forecasting case study, evidencing the significant gain in performance of both proposed approaches.
Reinforcement Learning for Financial Index Tracking
Aug 05, 2023We propose the first discrete-time infinite-horizon dynamic formulation of the financial index tracking problem under both return-based tracking error and value-based tracking error. The formulation overcomes the limitations of existing models by incorporating the intertemporal dynamics of market information variables not limited to prices, allowing exact calculation of transaction costs, accounting for the tradeoff between overall tracking error and transaction costs, allowing effective use of data in a long time period, etc. The formulation also allows novel decision variables of cash injection or withdraw. We propose to solve the portfolio rebalancing equation using a Banach fixed point iteration, which allows to accurately calculate the transaction costs specified as nonlinear functions of trading volumes in practice. We propose an extension of deep reinforcement learning (RL) method to solve the dynamic formulation. Our RL method resolves the issue of data limitation resulting from the availability of a single sample path of financial data by a novel training scheme. A comprehensive empirical study based on a 17-year-long testing set demonstrates that the proposed method outperforms a benchmark method in terms of tracking accuracy and has the potential for earning extra profit through cash withdraw strategy.
Where and How: Mitigating Confusion in Neural Radiance Fields from Sparse Inputs
Aug 05, 2023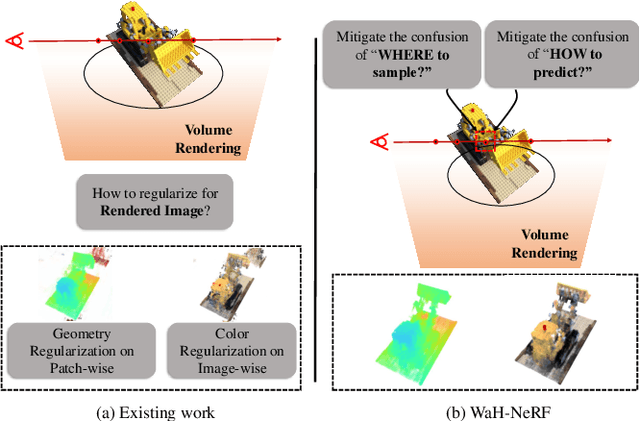
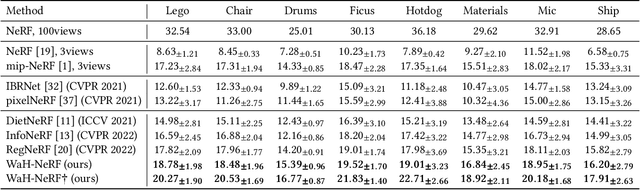
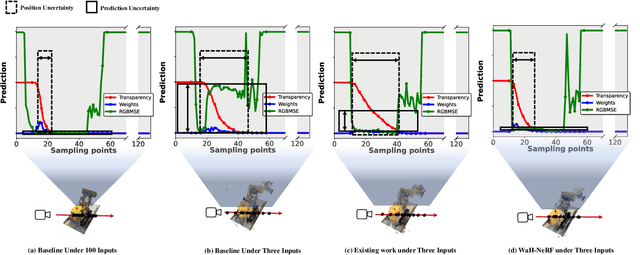
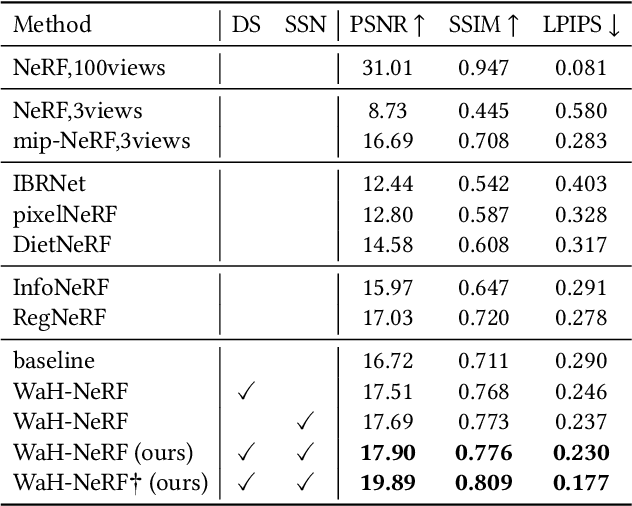
Neural Radiance Fields from Sparse input} (NeRF-S) have shown great potential in synthesizing novel views with a limited number of observed viewpoints. However, due to the inherent limitations of sparse inputs and the gap between non-adjacent views, rendering results often suffer from over-fitting and foggy surfaces, a phenomenon we refer to as "CONFUSION" during volume rendering. In this paper, we analyze the root cause of this confusion and attribute it to two fundamental questions: "WHERE" and "HOW". To this end, we present a novel learning framework, WaH-NeRF, which effectively mitigates confusion by tackling the following challenges: (i)"WHERE" to Sample? in NeRF-S -- we introduce a Deformable Sampling strategy and a Weight-based Mutual Information Loss to address sample-position confusion arising from the limited number of viewpoints; and (ii) "HOW" to Predict? in NeRF-S -- we propose a Semi-Supervised NeRF learning Paradigm based on pose perturbation and a Pixel-Patch Correspondence Loss to alleviate prediction confusion caused by the disparity between training and testing viewpoints. By integrating our proposed modules and loss functions, WaH-NeRF outperforms previous methods under the NeRF-S setting. Code is available https://github.com/bbbbby-99/WaH-NeRF.
General Image-to-Image Translation with One-Shot Image Guidance
Aug 05, 2023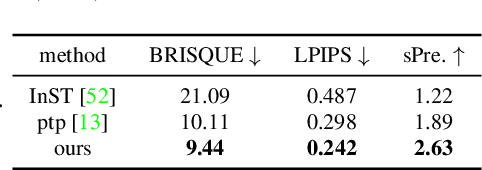
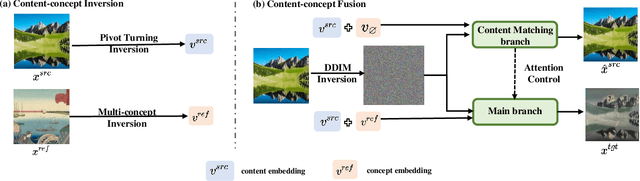
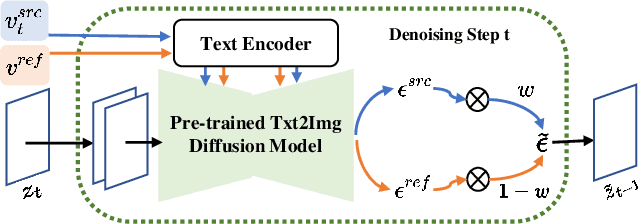
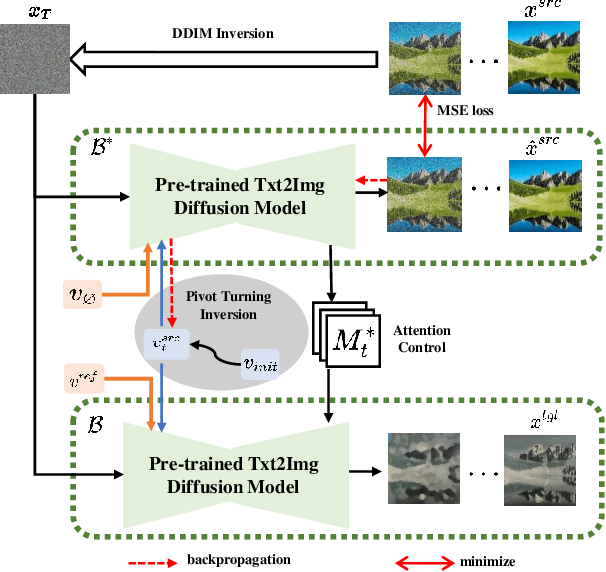
Large-scale text-to-image models pre-trained on massive text-image pairs show excellent performance in image synthesis recently. However, image can provide more intuitive visual concepts than plain text. People may ask: how can we integrate the desired visual concept into an existing image, such as our portrait? Current methods are inadequate in meeting this demand as they lack the ability to preserve content or translate visual concepts effectively. Inspired by this, we propose a novel framework named visual concept translator (VCT) with the ability to preserve content in the source image and translate the visual concepts guided by a single reference image. The proposed VCT contains a content-concept inversion (CCI) process to extract contents and concepts, and a content-concept fusion (CCF) process to gather the extracted information to obtain the target image. Given only one reference image, the proposed VCT can complete a wide range of general image-to-image translation tasks with excellent results. Extensive experiments are conducted to prove the superiority and effectiveness of the proposed methods. Codes are available at https://github.com/CrystalNeuro/visual-concept-translator.
Eva: A General Vectorized Approximation Framework for Second-order Optimization
Aug 04, 2023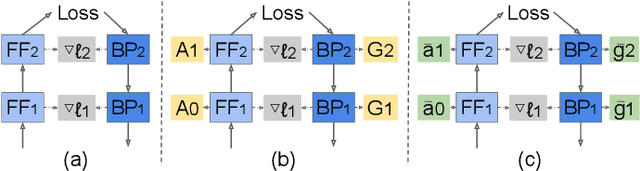

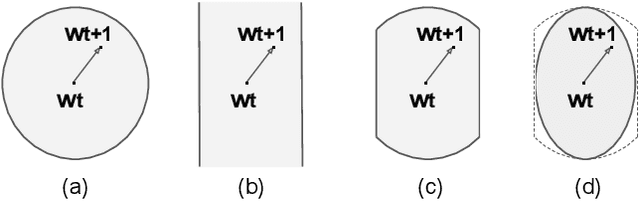
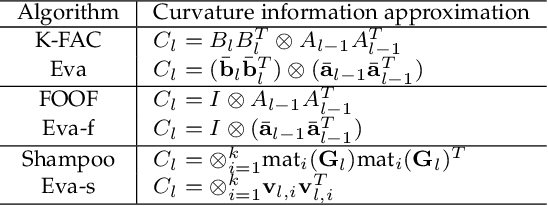
Second-order optimization algorithms exhibit excellent convergence properties for training deep learning models, but often incur significant computation and memory overheads. This can result in lower training efficiency than the first-order counterparts such as stochastic gradient descent (SGD). In this work, we present a memory- and time-efficient second-order algorithm named Eva with two novel techniques: 1) we construct the second-order information with the Kronecker factorization of small stochastic vectors over a mini-batch of training data to reduce memory consumption, and 2) we derive an efficient update formula without explicitly computing the inverse of matrices using the Sherman-Morrison formula. We further extend Eva to a general vectorized approximation framework to improve the compute and memory efficiency of two existing second-order algorithms (FOOF and Shampoo) without affecting their convergence performance. Extensive experimental results on different models and datasets show that Eva reduces the end-to-end training time up to 2.05x and 2.42x compared to first-order SGD and second-order algorithms (K-FAC and Shampoo), respectively.
Transformer-Based Denoising of Mechanical Vibration Signals
Aug 04, 2023Mechanical vibration signal denoising is a pivotal task in various industrial applications, including system health monitoring and failure prediction. This paper introduces a novel deep learning transformer-based architecture specifically tailored for denoising mechanical vibration signals. The model leverages a Multi-Head Attention layer with 8 heads, processing input sequences of length 128, embedded into a 64-dimensional space. The architecture also incorporates Feed-Forward Neural Networks, Layer Normalization, and Residual Connections, resulting in enhanced recognition and extraction of essential features. Through a training process guided by the Mean Squared Error loss function and optimized using the Adam optimizer, the model demonstrates remarkable effectiveness in filtering out noise while preserving critical information related to mechanical vibrations. The specific design and choice of parameters offer a robust method adaptable to the complex nature of mechanical systems, with promising applications in industrial monitoring and maintenance. This work lays the groundwork for future exploration and optimization in the field of mechanical signal analysis and presents a significant step towards advanced and intelligent mechanical system diagnostics.