 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning multi-modal generative models with permutation-invariant encoders and tighter variational bounds
Sep 01, 2023
Devising deep latent variable models for multi-modal data has been a long-standing theme in machine learning research. Multi-modal Variational Autoencoders (VAEs) have been a popular generative model class that learns latent representations which jointly explain multiple modalities. Various objective functions for such models have been suggested, often motivated as lower bounds on the multi-modal data log-likelihood or from information-theoretic considerations. In order to encode latent variables from different modality subsets, Product-of-Experts (PoE) or Mixture-of-Experts (MoE) aggregation schemes have been routinely used and shown to yield different trade-offs, for instance, regarding their generative quality or consistency across multiple modalities. In this work, we consider a variational bound that can tightly lower bound the data log-likelihood. We develop more flexible aggregation schemes that generalise PoE or MoE approaches by combining encoded features from different modalities based on permutation-invariant neural networks. Our numerical experiments illustrate trade-offs for multi-modal variational bounds and various aggregation schemes. We show that tighter variational bounds and more flexible aggregation models can become beneficial when one wants to approximate the true joint distribution over observed modalities and latent variables in identifiable models.
Geodesic Mode Connectivity
Aug 24, 2023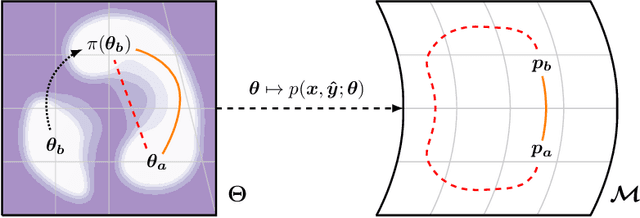
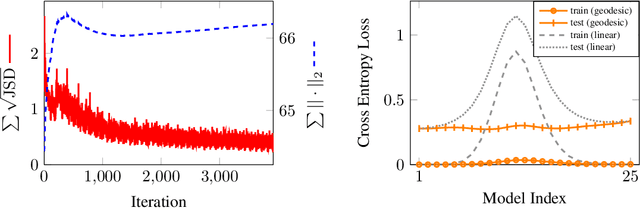
Mode connectivity is a phenomenon where trained models are connected by a path of low loss. We reframe this in the context of Information Geometry, where neural networks are studied as spaces of parameterized distributions with curved geometry. We hypothesize that shortest paths in these spaces, known as geodesics, correspond to mode-connecting paths in the loss landscape. We propose an algorithm to approximate geodesics and demonstrate that they achieve mode connectivity.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023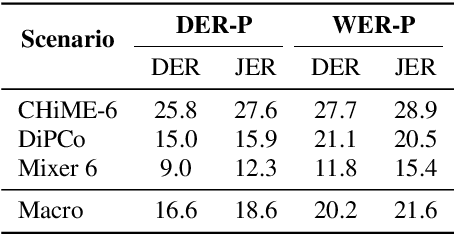

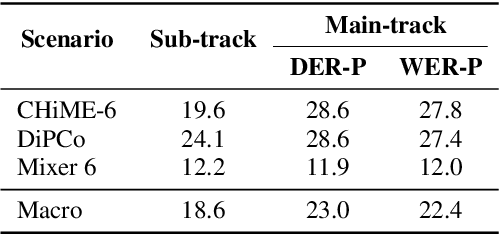
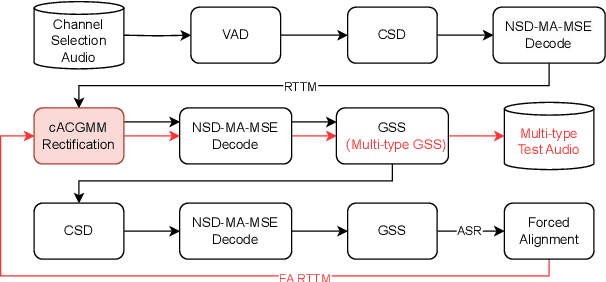
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
MUSIC Algorithm for IRS-Assisted AOA Estimation
Sep 06, 2023Based on the signals received across its antennas, a multi-antenna base station (BS) can apply the classic multiple signal classification (MUSIC) algorithm for estimating the angle of arrivals (AOAs) of its incident signals. This method can be leveraged to localize the users if their line-of-sight (LOS) paths to the BS are available. In this paper, we consider a more challenging AOA estimation setup in the intelligent reflecting surface (IRS) assisted integrated sensing and communication (ISAC) system, where LOS paths do not exist between the BS and the users, while the users' signals can be transmitted to the BS merely via their LOS paths to the IRS as well as the LOS path from the IRS to the BS. Specifically, we treat the IRS as the anchor and are interested in estimating the AOAs of the incident signals from the users to the IRS. Note that we have to achieve the above goal based on the signals received by the BS, because the passive IRS cannot process its received signals. However, the signals received across different antennas of the BS only contain AOA information of its incident signals via the LOS path from the IRS to the BS. To tackle this challenge arising from the spatial-domain received signals, we propose an innovative approach to create temporal-domain multi-dimension received signals for estimating the AOAs of the paths from the users to the IRS. Specifically, via a proper design of the user message pattern and the IRS reflecting pattern, we manage to show that our designed temporal-domain multi-dimension signals can be surprisingly expressed as a function of the virtual steering vectors of the IRS towards the users. This amazing result implies that the classic MUSIC algorithm can be applied to our designed temporal-domain multi-dimension signals for accurately estimating the AOAs of the signals from the users to the IRS.
TAI-GAN: Temporally and Anatomically Informed GAN for early-to-late frame conversion in dynamic cardiac PET motion correction
Aug 23, 2023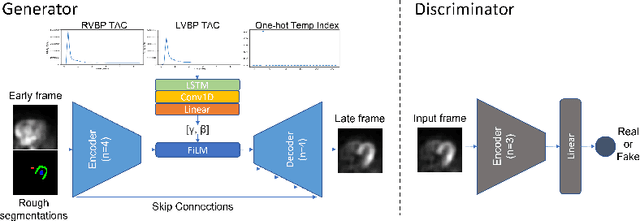
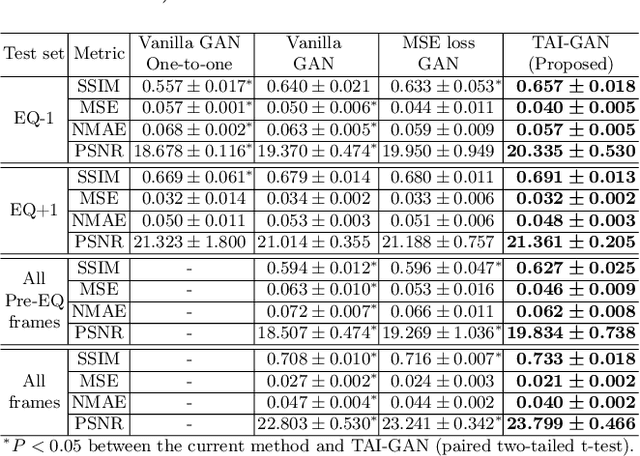
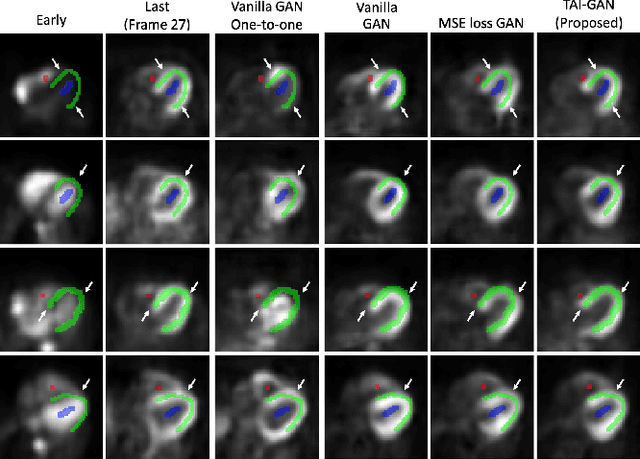
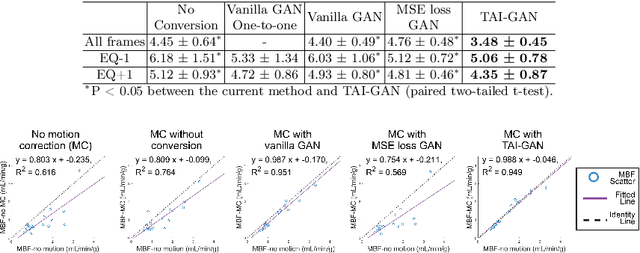
The rapid tracer kinetics of rubidium-82 ($^{82}$Rb) and high variation of cross-frame distribution in dynamic cardiac positron emission tomography (PET) raise significant challenges for inter-frame motion correction, particularly for the early frames where conventional intensity-based image registration techniques are not applicable. Alternatively, a promising approach utilizes generative methods to handle the tracer distribution changes to assist existing registration methods. To improve frame-wise registration and parametric quantification, we propose a Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) to transform the early frames into the late reference frame using an all-to-one mapping. Specifically, a feature-wise linear modulation layer encodes channel-wise parameters generated from temporal tracer kinetics information, and rough cardiac segmentations with local shifts serve as the anatomical information. We validated our proposed method on a clinical $^{82}$Rb PET dataset and found that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, motion estimation accuracy and clinical myocardial blood flow (MBF) quantification were improved compared to using the original frames. Our code is published at https://github.com/gxq1998/TAI-GAN.
Overcoming General Knowledge Loss with Selective Parameter Finetuning
Aug 23, 2023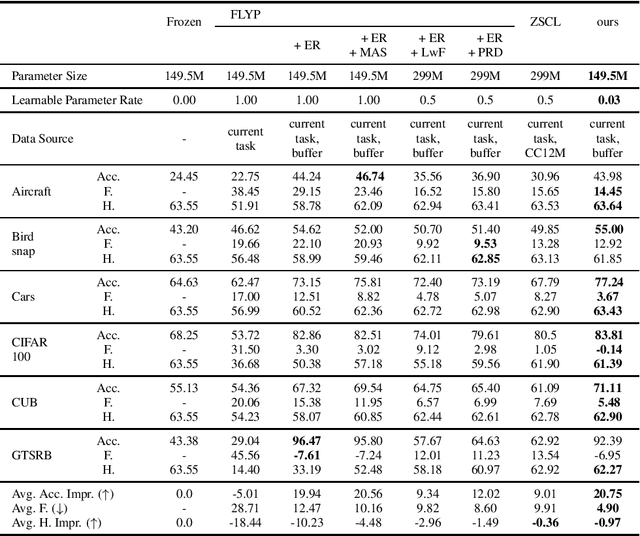

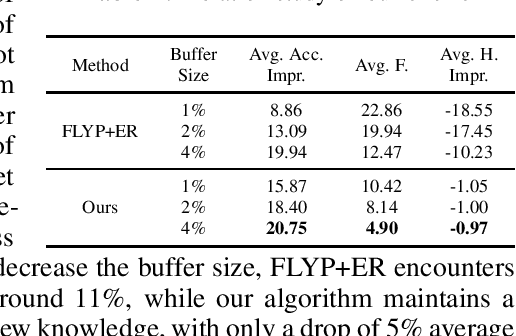

Foundation models encompass an extensive knowledge base and offer remarkable transferability. However, this knowledge becomes outdated or insufficient over time. The challenge lies in updating foundation models to accommodate novel information while retaining their original ability. In this paper, we present a novel approach to achieving continual model updates by effecting localized modifications to a small subset of parameters. Guided by insights gleaned from prior analyses of foundational models, we first localize a specific layer for model refinement and then introduce an importance scoring mechanism designed to update only the most crucial weights. Our method is exhaustively evaluated on foundational vision-language models, measuring its efficacy in both learning new information and preserving pre-established knowledge across a diverse spectrum of continual learning tasks, including Aircraft, Birdsnap CIFAR-100, CUB, Cars, and GTSRB. The results show that our method improves the existing continual learning methods by 0.5\% - 10\% on average, and reduces the loss of pre-trained knowledge from around 5\% to 0.97\%. Comprehensive ablation studies substantiate our method design, shedding light on the contributions of each component to controllably learning new knowledge and mitigating the forgetting of pre-trained knowledge.
MolGrapher: Graph-based Visual Recognition of Chemical Structures
Aug 23, 2023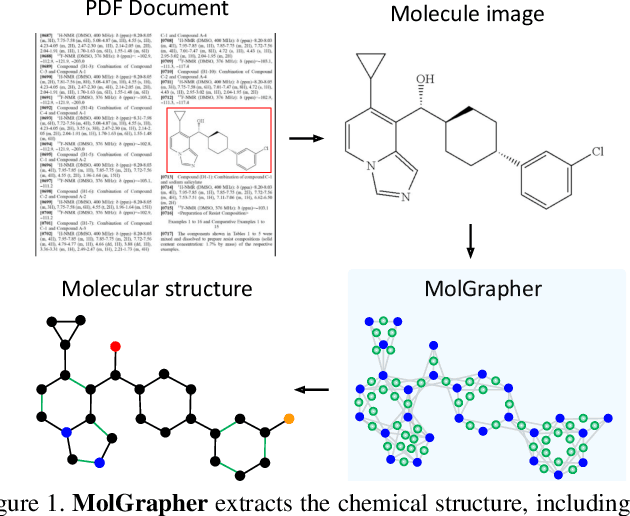
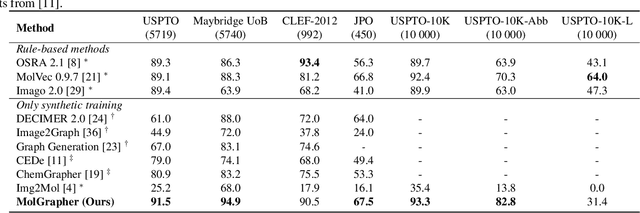
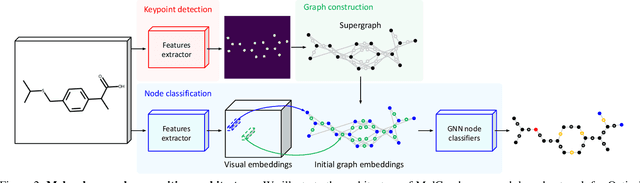
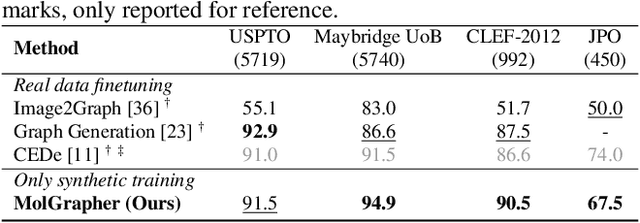
The automatic analysis of chemical literature has immense potential to accelerate the discovery of new materials and drugs. Much of the critical information in patent documents and scientific articles is contained in figures, depicting the molecule structures. However, automatically parsing the exact chemical structure is a formidable challenge, due to the amount of detailed information, the diversity of drawing styles, and the need for training data. In this work, we introduce MolGrapher to recognize chemical structures visually. First, a deep keypoint detector detects the atoms. Second, we treat all candidate atoms and bonds as nodes and put them in a graph. This construct allows a natural graph representation of the molecule. Last, we classify atom and bond nodes in the graph with a Graph Neural Network. To address the lack of real training data, we propose a synthetic data generation pipeline producing diverse and realistic results. In addition, we introduce a large-scale benchmark of annotated real molecule images, USPTO-30K, to spur research on this critical topic. Extensive experiments on five datasets show that our approach significantly outperforms classical and learning-based methods in most settings. Code, models, and datasets are available.
A Heuristic Informative-Path-Planning Algorithm for Autonomous Mapping of Unknown Areas
Aug 23, 2023Informative path planning algorithms are of paramount importance in applications like disaster management to efficiently gather information through a priori unknown environments. This is, however, a complex problem that involves finding a globally optimal path that gathers the maximum amount of information (e.g., the largest map with a minimum travelling distance) while using partial and uncertain local measurements. This paper addresses this problem by proposing a novel heuristic algorithm that continuously estimates the potential mapping gain for different sub-areas across the partially created map, and then uses these estimations to locally navigate the robot. Furthermore, this paper presents a novel algorithm to calculate a benchmark solution, where the map is a priori known to the planar, to evaluate the efficacy of the developed heuristic algorithm over different test scenarios. The findings indicate that the efficiency of the proposed algorithm, measured in terms of the mapped area per unit of travelling distance, ranges from 70% to 80% of the benchmark solution in various test scenarios. In essence, the algorithm demonstrates the capability to generate paths that come close to the globally optimal path provided by the benchmark solution.
EditSum: A Retrieve-and-Edit Framework for Source Code Summarization
Aug 26, 2023
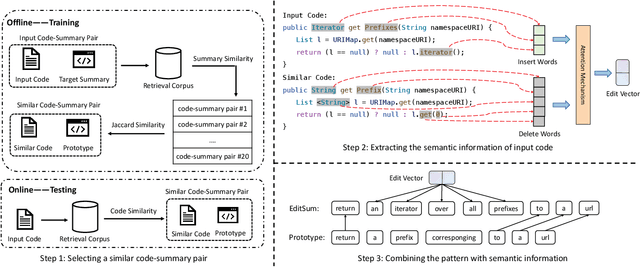
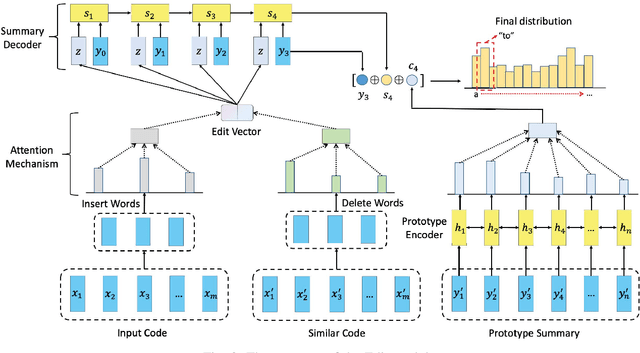
Existing studies show that code summaries help developers understand and maintain source code. Unfortunately, these summaries are often missing or outdated in software projects. Code summarization aims to generate natural language descriptions automatically for source code. Code summaries are highly structured and have repetitive patterns. Besides the patternized words, a code summary also contains important keywords, which are the key to reflecting the functionality of the code. However, the state-of-the-art approaches perform poorly on predicting the keywords, which leads to the generated summaries suffering a loss in informativeness. To alleviate this problem, this paper proposes a novel retrieve-and-edit approach named EditSum for code summarization. Specifically, EditSum first retrieves a similar code snippet from a pre-defined corpus and treats its summary as a prototype summary to learn the pattern. Then, EditSum edits the prototype automatically to combine the pattern in the prototype with the semantic information of input code. Our motivation is that the retrieved prototype provides a good start-point for post-generation because the summaries of similar code snippets often have the same pattern. The post-editing process further reuses the patternized words in the prototype and generates keywords based on the semantic information of input code. We conduct experiments on a large-scale Java corpus and experimental results demonstrate that EditSum outperforms the state-of-the-art approaches by a substantial margin. The human evaluation also proves the summaries generated by EditSum are more informative and useful. We also verify that EditSum performs well on predicting the patternized words and keywords.
Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models
Aug 31, 2023Zero-shot referring image segmentation is a challenging task because it aims to find an instance segmentation mask based on the given referring descriptions, without training on this type of paired data. Current zero-shot methods mainly focus on using pre-trained discriminative models (e.g., CLIP). However, we have observed that generative models (e.g., Stable Diffusion) have potentially understood the relationships between various visual elements and text descriptions, which are rarely investigated in this task. In this work, we introduce a novel Referring Diffusional segmentor (Ref-Diff) for this task, which leverages the fine-grained multi-modal information from generative models. We demonstrate that without a proposal generator, a generative model alone can achieve comparable performance to existing SOTA weakly-supervised models. When we combine both generative and discriminative models, our Ref-Diff outperforms these competing methods by a significant margin. This indicates that generative models are also beneficial for this task and can complement discriminative models for better referring segmentation. Our code is publicly available at https://github.com/kodenii/Ref-Diff.