 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated Learning with Neural Graphical Models
Sep 20, 2023
Federated Learning (FL) addresses the need to create models based on proprietary data in such a way that multiple clients retain exclusive control over their data, while all benefit from improved model accuracy due to pooled resources. Recently proposed Neural Graphical Models (NGMs) are Probabilistic Graphical models that utilize the expressive power of neural networks to learn complex non-linear dependencies between the input features. They learn to capture the underlying data distribution and have efficient algorithms for inference and sampling. We develop a FL framework which maintains a global NGM model that learns the averaged information from the local NGM models while keeping the training data within the client's environment. Our design, FedNGMs, avoids the pitfalls and shortcomings of neuron matching frameworks like Federated Matched Averaging that suffers from model parameter explosion. Our global model size remains constant throughout the process. In the cases where clients have local variables that are not part of the combined global distribution, we propose a `Stitching' algorithm, which personalizes the global NGM models by merging the additional variables using the client's data. FedNGM is robust to data heterogeneity, large number of participants, and limited communication bandwidth.
Dr. FERMI: A Stochastic Distributionally Robust Fair Empirical Risk Minimization Framework
Sep 20, 2023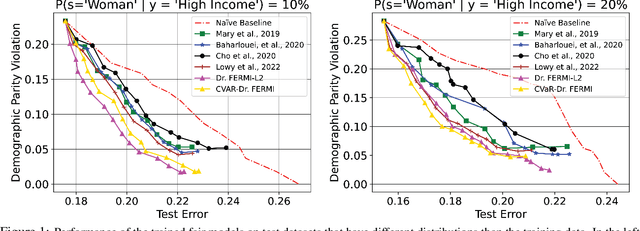
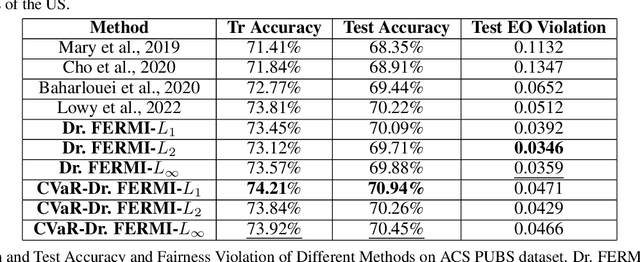
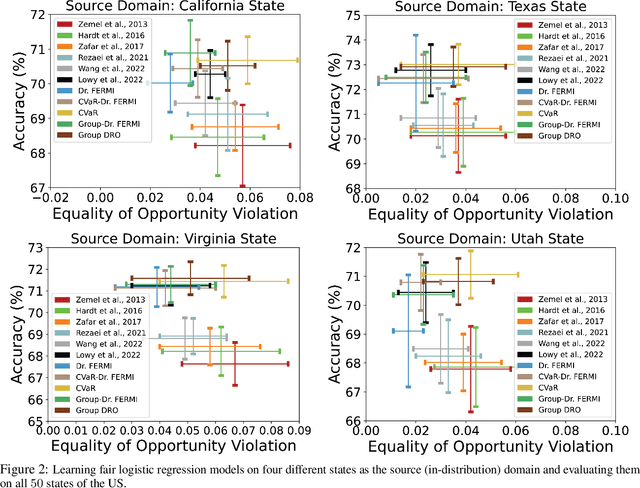
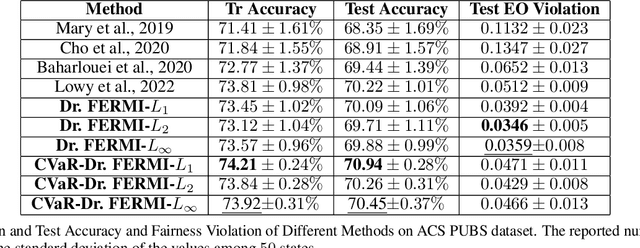
While training fair machine learning models has been studied extensively in recent years, most developed methods rely on the assumption that the training and test data have similar distributions. In the presence of distribution shifts, fair models may behave unfairly on test data. There have been some developments for fair learning robust to distribution shifts to address this shortcoming. However, most proposed solutions are based on the assumption of having access to the causal graph describing the interaction of different features. Moreover, existing algorithms require full access to data and cannot be used when small batches are used (stochastic/batch implementation). This paper proposes the first stochastic distributionally robust fairness framework with convergence guarantees that do not require knowledge of the causal graph. More specifically, we formulate the fair inference in the presence of the distribution shift as a distributionally robust optimization problem under $L_p$ norm uncertainty sets with respect to the Exponential Renyi Mutual Information (ERMI) as the measure of fairness violation. We then discuss how the proposed method can be implemented in a stochastic fashion. We have evaluated the presented framework's performance and efficiency through extensive experiments on real datasets consisting of distribution shifts.
Neural Image Compression Using Masked Sparse Visual Representation
Sep 20, 2023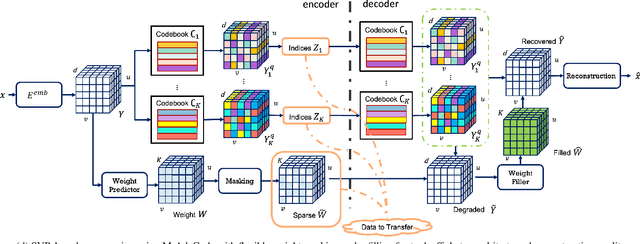
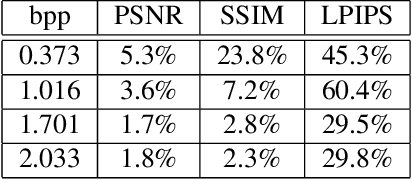
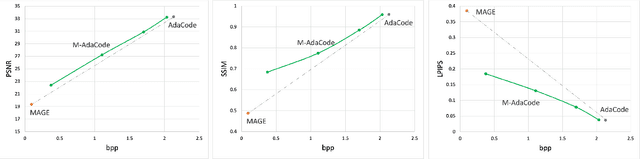

We study neural image compression based on the Sparse Visual Representation (SVR), where images are embedded into a discrete latent space spanned by learned visual codebooks. By sharing codebooks with the decoder, the encoder transfers integer codeword indices that are efficient and cross-platform robust, and the decoder retrieves the embedded latent feature using the indices for reconstruction. Previous SVR-based compression lacks effective mechanism for rate-distortion tradeoffs, where one can only pursue either high reconstruction quality or low transmission bitrate. We propose a Masked Adaptive Codebook learning (M-AdaCode) method that applies masks to the latent feature subspace to balance bitrate and reconstruction quality. A set of semantic-class-dependent basis codebooks are learned, which are weighted combined to generate a rich latent feature for high-quality reconstruction. The combining weights are adaptively derived from each input image, providing fidelity information with additional transmission costs. By masking out unimportant weights in the encoder and recovering them in the decoder, we can trade off reconstruction quality for transmission bits, and the masking rate controls the balance between bitrate and distortion. Experiments over the standard JPEG-AI dataset demonstrate the effectiveness of our M-AdaCode approach.
3D SA-UNet: 3D Spatial Attention UNet with 3D ASPP for White Matter Hyperintensities Segmentation
Sep 20, 2023
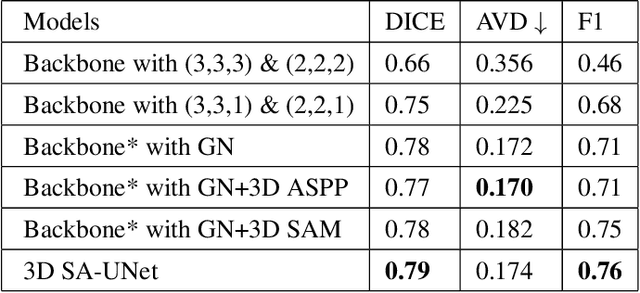
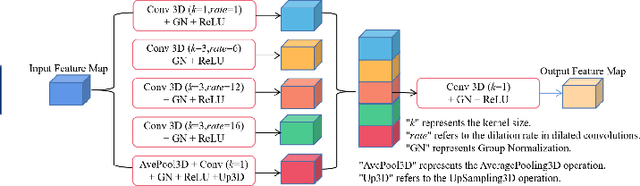
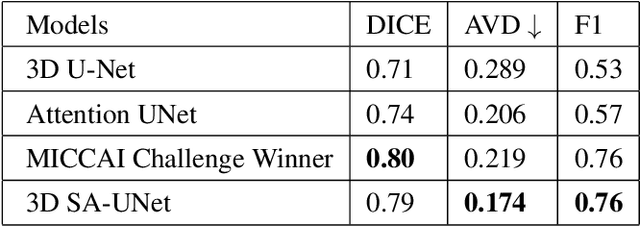
White Matter Hyperintensity (WMH) is an imaging feature related to various diseases such as dementia and stroke. Accurately segmenting WMH using computer technology is crucial for early disease diagnosis. However, this task remains challenging due to the small lesions with low contrast and high discontinuity in the images, which contain limited contextual and spatial information. To address this challenge, we propose a deep learning model called 3D Spatial Attention U-Net (3D SA-UNet) for automatic WMH segmentation using only Fluid Attenuation Inversion Recovery (FLAIR) scans. The 3D SA-UNet introduces a 3D Spatial Attention Module that highlights important lesion features, such as WMH, while suppressing unimportant regions. Additionally, to capture features at different scales, we extend the Atrous Spatial Pyramid Pooling (ASPP) module to a 3D version, enhancing the segmentation performance of the network. We evaluate our method on publicly available dataset and demonstrate the effectiveness of 3D spatial attention module and 3D ASPP in WMH segmentation. Through experimental results, it has been demonstrated that our proposed 3D SA-UNet model achieves higher accuracy compared to other state-of-the-art 3D convolutional neural networks.
GraphEcho: Graph-Driven Unsupervised Domain Adaptation for Echocardiogram Video Segmentation
Sep 20, 2023Echocardiogram video segmentation plays an important role in cardiac disease diagnosis. This paper studies the unsupervised domain adaption (UDA) for echocardiogram video segmentation, where the goal is to generalize the model trained on the source domain to other unlabelled target domains. Existing UDA segmentation methods are not suitable for this task because they do not model local information and the cyclical consistency of heartbeat. In this paper, we introduce a newly collected CardiacUDA dataset and a novel GraphEcho method for cardiac structure segmentation. Our GraphEcho comprises two innovative modules, the Spatial-wise Cross-domain Graph Matching (SCGM) and the Temporal Cycle Consistency (TCC) module, which utilize prior knowledge of echocardiogram videos, i.e., consistent cardiac structure across patients and centers and the heartbeat cyclical consistency, respectively. These two modules can better align global and local features from source and target domains, improving UDA segmentation results. Experimental results showed that our GraphEcho outperforms existing state-of-the-art UDA segmentation methods. Our collected dataset and code will be publicly released upon acceptance. This work will lay a new and solid cornerstone for cardiac structure segmentation from echocardiogram videos. Code and dataset are available at: https://github.com/xmed-lab/GraphEcho
Attention-Driven Multi-Modal Fusion: Enhancing Sign Language Recognition and Translation
Sep 06, 2023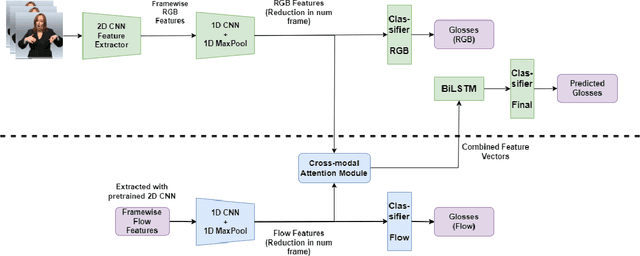

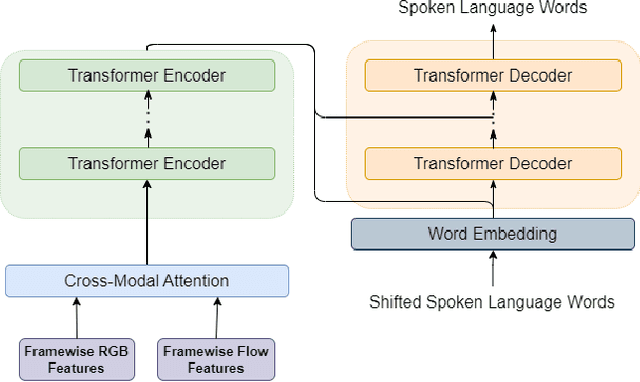
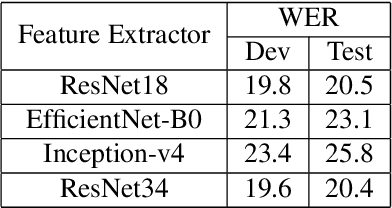
In this paper, we devise a mechanism for the addition of multi-modal information with an existing pipeline for continuous sign language recognition and translation. In our procedure, we have incorporated optical flow information with RGB images to enrich the features with movement-related information. This work studies the feasibility of such modality inclusion using a cross-modal encoder. The plugin we have used is very lightweight and doesn't need to include a separate feature extractor for the new modality in an end-to-end manner. We have applied the changes in both sign language recognition and translation, improving the result in each case. We have evaluated the performance on the RWTH-PHOENIX-2014 dataset for sign language recognition and the RWTH-PHOENIX-2014T dataset for translation. On the recognition task, our approach reduced the WER by 0.9, and on the translation task, our approach increased most of the BLEU scores by ~0.6 on the test set.
Global Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
Sep 22, 2023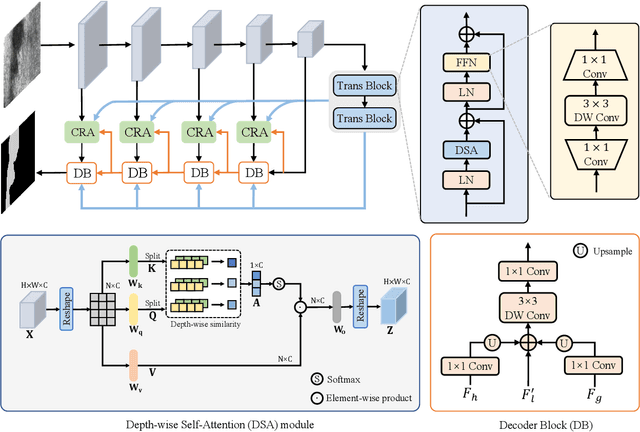
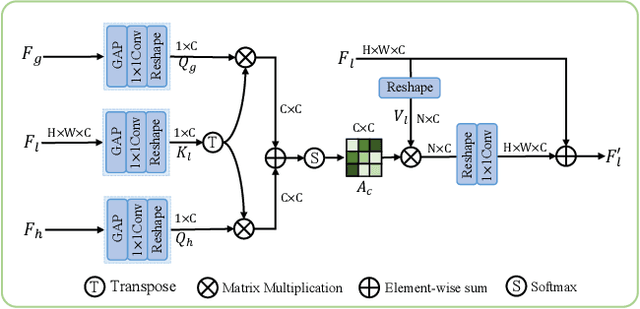
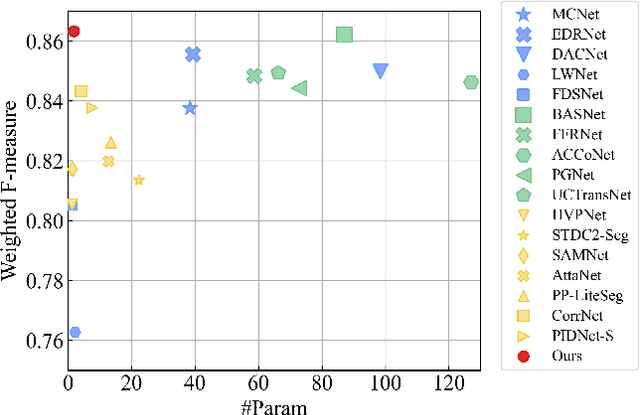
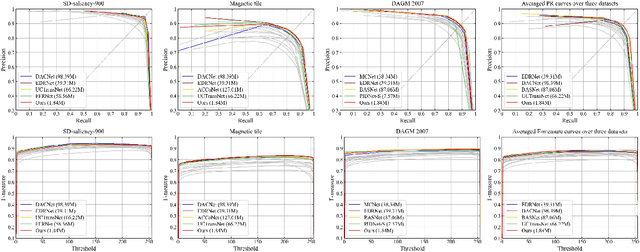
Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
S3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
Sep 22, 2023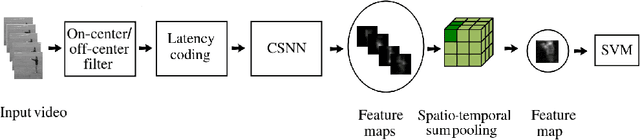
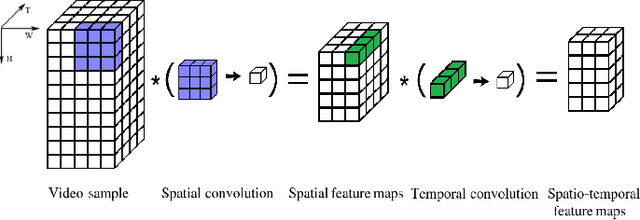
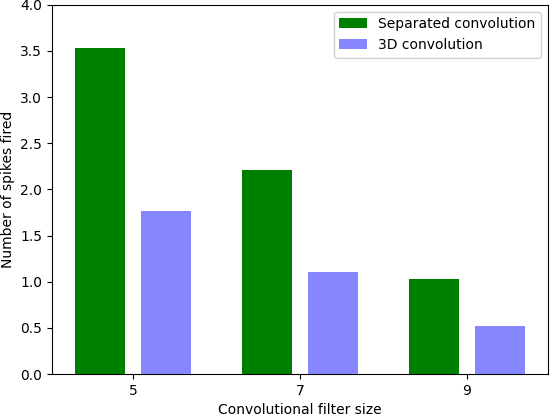
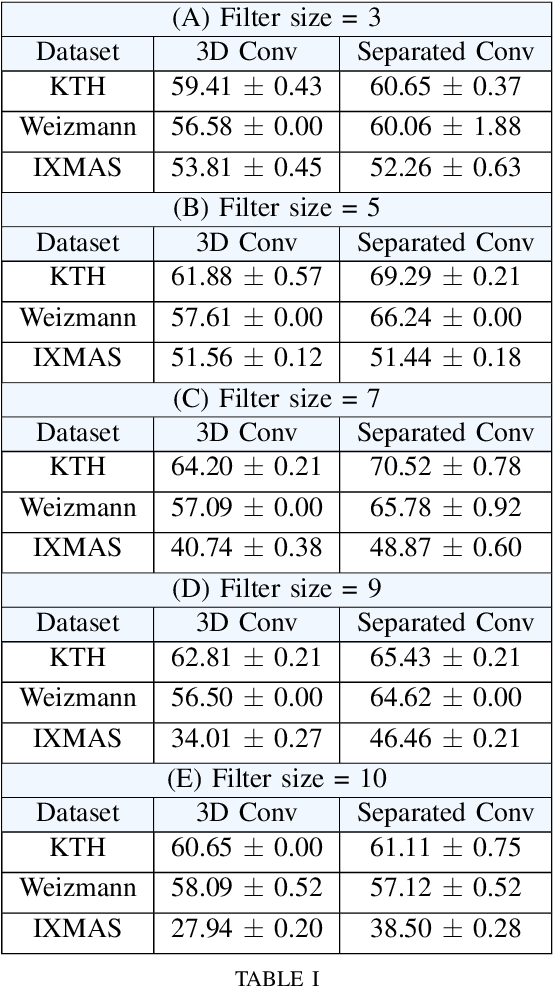
Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023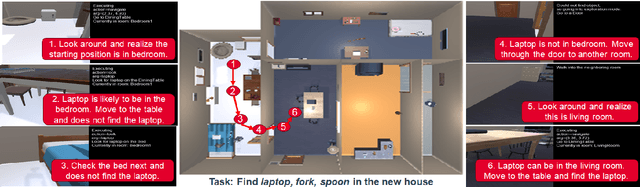
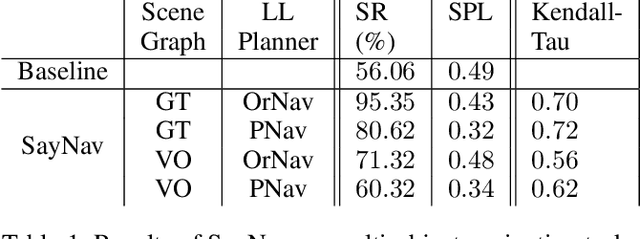
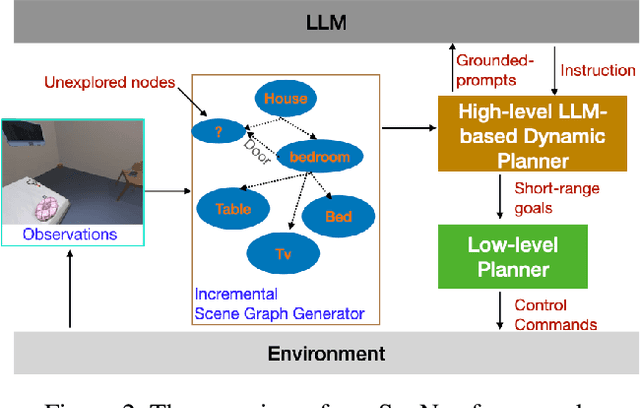
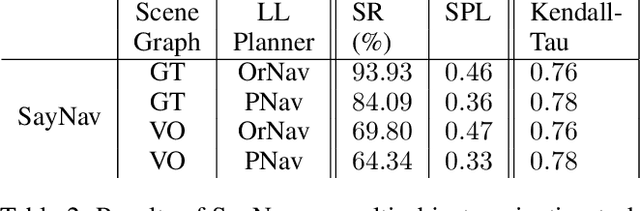
Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
A Novel Catastrophic Condition for Periodically Time-varying Convolutional Encoders Based on Time-varying Equivalent Convolutional Encoders
Sep 11, 2023A convolutional encoder is said to be catastrophic if it maps an information sequence of infinite weight into a code sequence of finite weight. As a consequence of this mapping, a finite number of channel errors may cause an infinite number of information bit errors when decoding. This situation should be avoided. A catastrophic condition to determine if a time-invariant convolutional encoder is catastrophic or not is stated in \cite{Massey:LSC}. Palazzo developed this condition for periodically time-varying convolutional encoders in \cite{Palazzo:Analysis}. Since Palazzo's condition is based on the state transition table of the constituent encoders, its complexity increases exponentially with the number of memory elements in the encoders. A novel catastrophic condition making use of time-varying equivalent convolutional encoders is presented in this letter. A technique to convert a catastrophic periodically time-varying convolutional encoder into a non-catastrophic one can also be developed based on these encoders. Since they do not involve the state transitions of the convolutional encoder, the time complexity of these methods grows linearly with the encoder memory.