 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Latent Graph Powered Semi-Supervised Learning on Biomedical Tabular Data
Sep 28, 2023
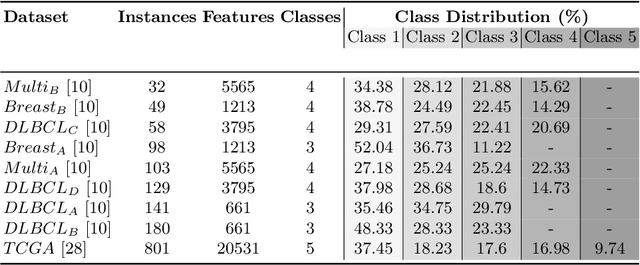

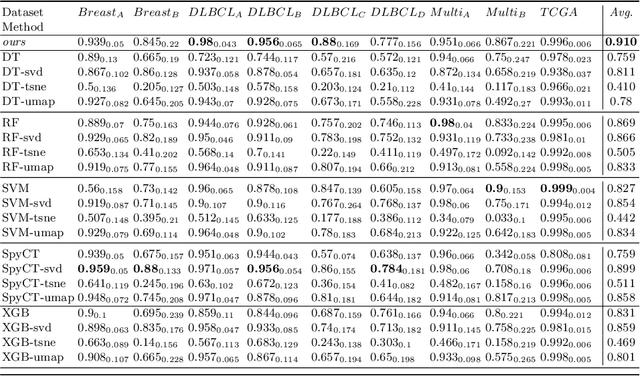

In the domain of semi-supervised learning, the current approaches insufficiently exploit the potential of considering inter-instance relationships among (un)labeled data. In this work, we address this limitation by providing an approach for inferring latent graphs that capture the intrinsic data relationships. By leveraging graph-based representations, our approach facilitates the seamless propagation of information throughout the graph, enabling the effective incorporation of global and local knowledge. Through evaluations on biomedical tabular datasets, we compare the capabilities of our approach to other contemporary methods. Our work demonstrates the significance of inter-instance relationship discovery as practical means for constructing robust latent graphs to enhance semi-supervised learning techniques. Our method achieves state-of-the-art results on three biomedical datasets.
Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization
Sep 20, 2023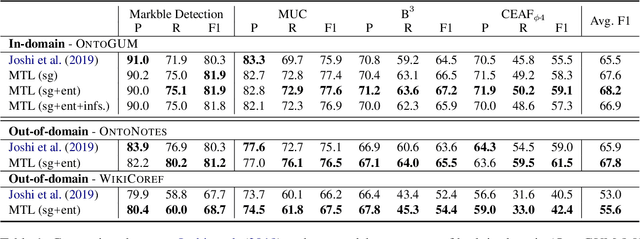
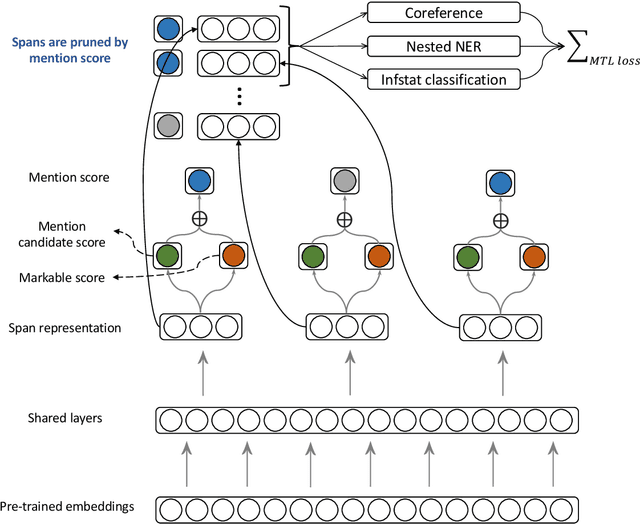


Previous attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new state-of-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
Oct 02, 2023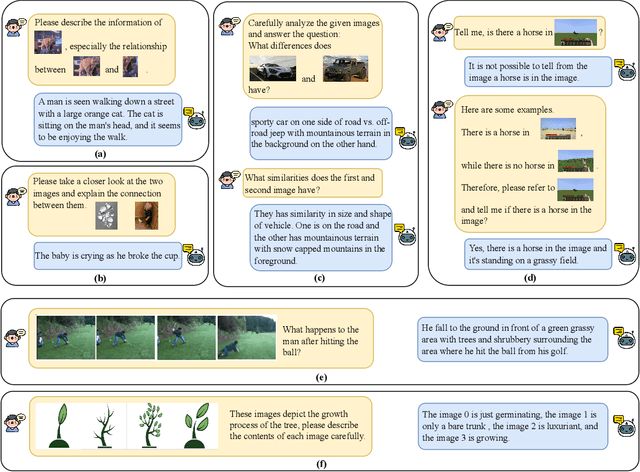
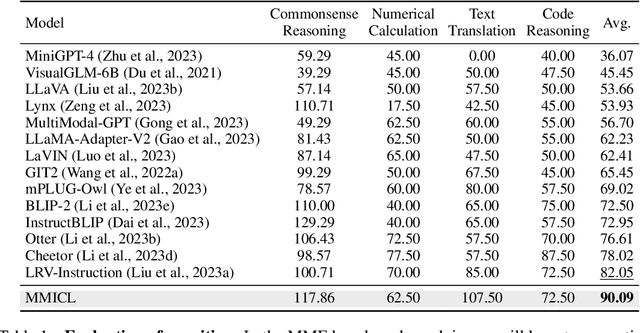
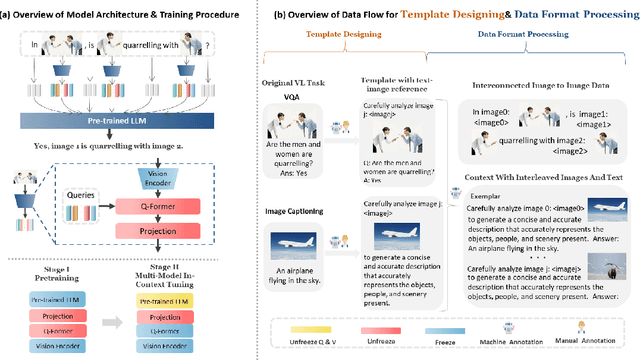
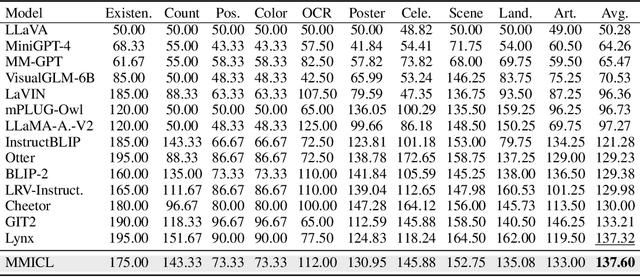
Since the resurgence of deep learning, vision-language models (VLMs) enhanced by large language models (LLMs) have grown exponentially in popularity. However, while LLMs can utilize extensive background knowledge and task information with in-context learning, most VLMs still struggle with understanding complex multi-modal prompts with multiple images, making VLMs less effective in downstream vision-language tasks. In this paper, we address the limitation above by 1) introducing MMICL, a new approach to allow the VLM to deal with multi-modal inputs efficiently; 2) proposing a novel context scheme to augment the in-context learning ability of the VLM; 3) constructing the Multi-modal In-Context Learning (MIC) dataset, designed to enhance the VLM's ability to understand complex multi-modal prompts. Our experiments confirm that MMICL achieves new state-of-the-art zero-shot performance on a wide range of general vision-language tasks, especially for complex benchmarks, including MME and MMBench. Our analysis demonstrates that MMICL effectively tackles the challenge of complex multi-modal prompt understanding and emerges the impressive ICL ability. Furthermore, we observe that MMICL successfully alleviates language bias in VLMs, a common issue for VLMs that often leads to hallucination when faced with extensive textual context.
Landscape-Sketch-Step: An AI/ML-Based Metaheuristic for Surrogate Optimization Problems
Oct 02, 2023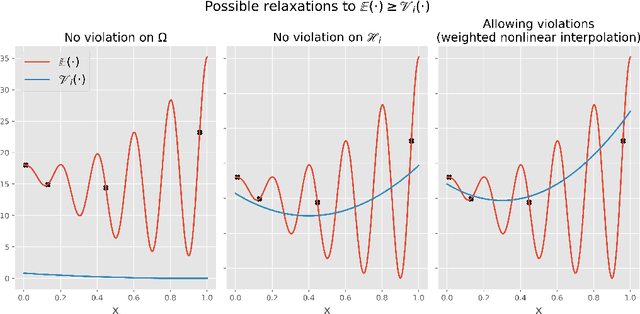

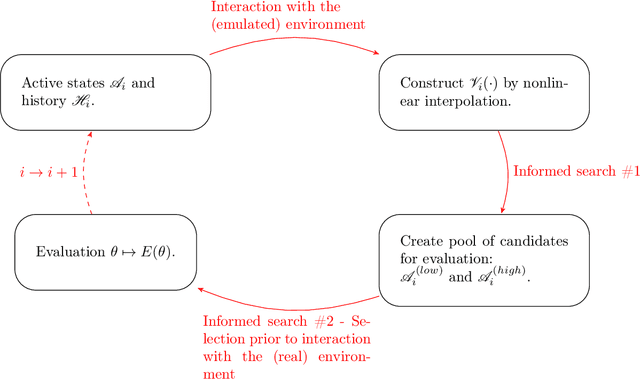
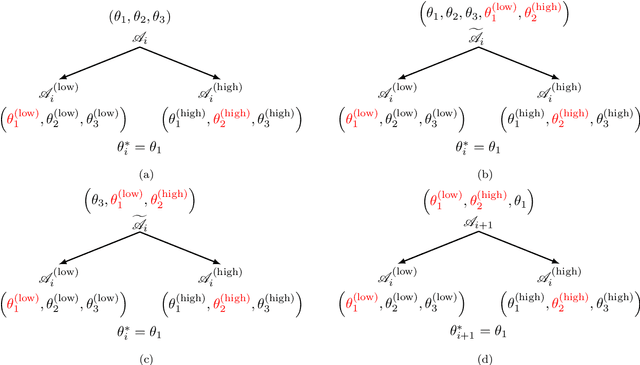
In this paper, we introduce a new heuristics for global optimization in scenarios where extensive evaluations of the cost function are expensive, inaccessible, or even prohibitive. The method, which we call Landscape-Sketch-and-Step (LSS), combines Machine Learning, Stochastic Optimization, and Reinforcement Learning techniques, relying on historical information from previously sampled points to make judicious choices of parameter values where the cost function should be evaluated at. Unlike optimization by Replica Exchange Monte Carlo methods, the number of evaluations of the cost function required in this approach is comparable to that used by Simulated Annealing, quality that is especially important in contexts like high-throughput computing or high-performance computing tasks, where evaluations are either computationally expensive or take a long time to be performed. The method also differs from standard Surrogate Optimization techniques, for it does not construct a surrogate model that aims at approximating or reconstructing the objective function. We illustrate our method by applying it to low dimensional optimization problems (dimensions 1, 2, 4, and 8) that mimick known difficulties of minimization on rugged energy landscapes often seen in Condensed Matter Physics, where cost functions are rugged and plagued with local minima. When compared to classical Simulated Annealing, the LSS shows an effective acceleration of the optimization process.
Variance-Aware Regret Bounds for Stochastic Contextual Dueling Bandits
Oct 02, 2023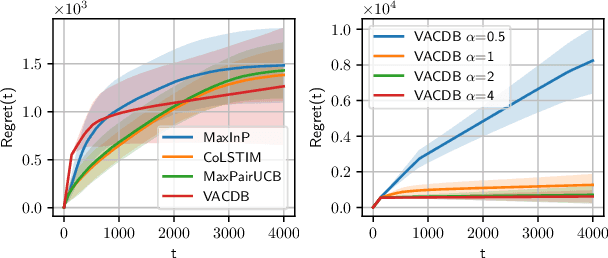
Dueling bandits is a prominent framework for decision-making involving preferential feedback, a valuable feature that fits various applications involving human interaction, such as ranking, information retrieval, and recommendation systems. While substantial efforts have been made to minimize the cumulative regret in dueling bandits, a notable gap in the current research is the absence of regret bounds that account for the inherent uncertainty in pairwise comparisons between the dueling arms. Intuitively, greater uncertainty suggests a higher level of difficulty in the problem. To bridge this gap, this paper studies the problem of contextual dueling bandits, where the binary comparison of dueling arms is generated from a generalized linear model (GLM). We propose a new SupLinUCB-type algorithm that enjoys computational efficiency and a variance-aware regret bound $\tilde O\big(d\sqrt{\sum_{t=1}^T\sigma_t^2} + d\big)$, where $\sigma_t$ is the variance of the pairwise comparison in round $t$, $d$ is the dimension of the context vectors, and $T$ is the time horizon. Our regret bound naturally aligns with the intuitive expectation in scenarios where the comparison is deterministic, the algorithm only suffers from an $\tilde O(d)$ regret. We perform empirical experiments on synthetic data to confirm the advantage of our method over previous variance-agnostic algorithms.
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Oct 02, 2023Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning
Oct 02, 2023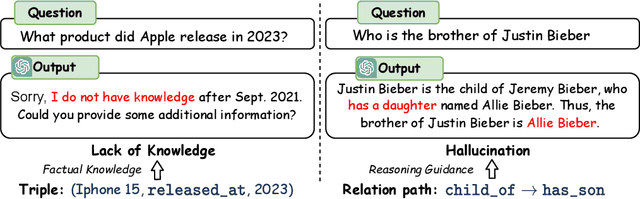
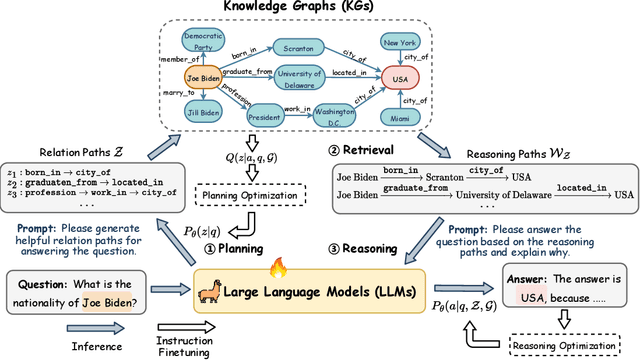
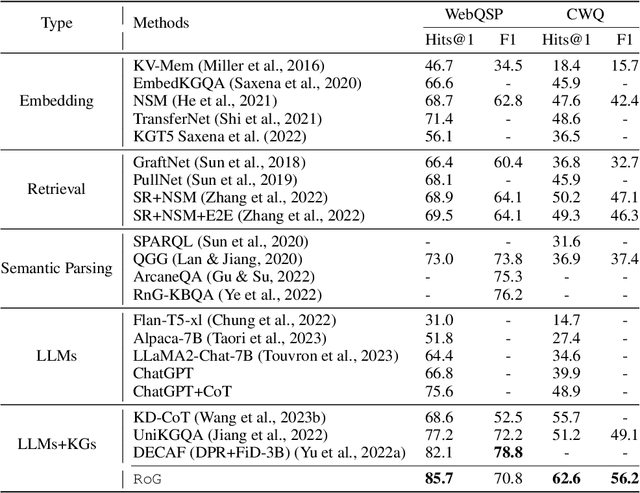
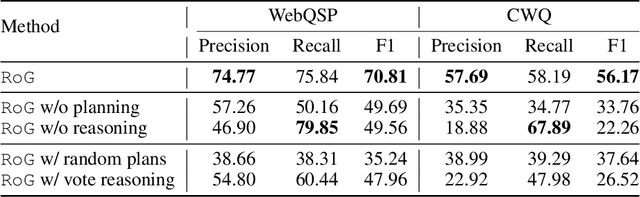
Large language models (LLMs) have demonstrated impressive reasoning abilities in complex tasks. However, they lack up-to-date knowledge and experience hallucinations during reasoning, which can lead to incorrect reasoning processes and diminish their performance and trustworthiness. Knowledge graphs (KGs), which capture vast amounts of facts in a structured format, offer a reliable source of knowledge for reasoning. Nevertheless, existing KG-based LLM reasoning methods only treat KGs as factual knowledge bases and overlook the importance of their structural information for reasoning. In this paper, we propose a novel method called reasoning on graphs (RoG) that synergizes LLMs with KGs to enable faithful and interpretable reasoning. Specifically, we present a planning-retrieval-reasoning framework, where RoG first generates relation paths grounded by KGs as faithful plans. These plans are then used to retrieve valid reasoning paths from the KGs for LLMs to conduct faithful reasoning. Furthermore, RoG not only distills knowledge from KGs to improve the reasoning ability of LLMs through training but also allows seamless integration with any arbitrary LLMs during inference. Extensive experiments on two benchmark KGQA datasets demonstrate that RoG achieves state-of-the-art performance on KG reasoning tasks and generates faithful and interpretable reasoning results.
Task-guided Domain Gap Reduction for Monocular Depth Prediction in Endoscopy
Oct 02, 2023Colorectal cancer remains one of the deadliest cancers in the world. In recent years computer-aided methods have aimed to enhance cancer screening and improve the quality and availability of colonoscopies by automatizing sub-tasks. One such task is predicting depth from monocular video frames, which can assist endoscopic navigation. As ground truth depth from standard in-vivo colonoscopy remains unobtainable due to hardware constraints, two approaches have aimed to circumvent the need for real training data: supervised methods trained on labeled synthetic data and self-supervised models trained on unlabeled real data. However, self-supervised methods depend on unreliable loss functions that struggle with edges, self-occlusion, and lighting inconsistency. Methods trained on synthetic data can provide accurate depth for synthetic geometries but do not use any geometric supervisory signal from real data and overfit to synthetic anatomies and properties. This work proposes a novel approach to leverage labeled synthetic and unlabeled real data. While previous domain adaptation methods indiscriminately enforce the distributions of both input data modalities to coincide, we focus on the end task, depth prediction, and translate only essential information between the input domains. Our approach results in more resilient and accurate depth maps of real colonoscopy sequences.
* First Data Engineering in Medical Imaging Workshop at MICCAI 2023
Mirror Diffusion Models for Constrained and Watermarked Generation
Oct 02, 2023Modern successes of diffusion models in learning complex, high-dimensional data distributions are attributed, in part, to their capability to construct diffusion processes with analytic transition kernels and score functions. The tractability results in a simulation-free framework with stable regression losses, from which reversed, generative processes can be learned at scale. However, when data is confined to a constrained set as opposed to a standard Euclidean space, these desirable characteristics appear to be lost based on prior attempts. In this work, we propose Mirror Diffusion Models (MDM), a new class of diffusion models that generate data on convex constrained sets without losing any tractability. This is achieved by learning diffusion processes in a dual space constructed from a mirror map, which, crucially, is a standard Euclidean space. We derive efficient computation of mirror maps for popular constrained sets, such as simplices and $\ell_2$-balls, showing significantly improved performance of MDM over existing methods. For safety and privacy purposes, we also explore constrained sets as a new mechanism to embed invisible but quantitative information (i.e., watermarks) in generated data, for which MDM serves as a compelling approach. Our work brings new algorithmic opportunities for learning tractable diffusion on complex domains.
Analyzing the Efficacy of an LLM-Only Approach for Image-based Document Question Answering
Sep 25, 2023
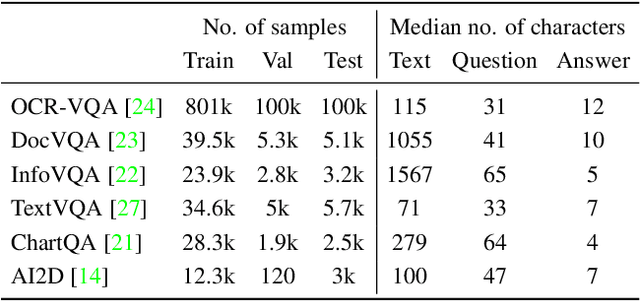
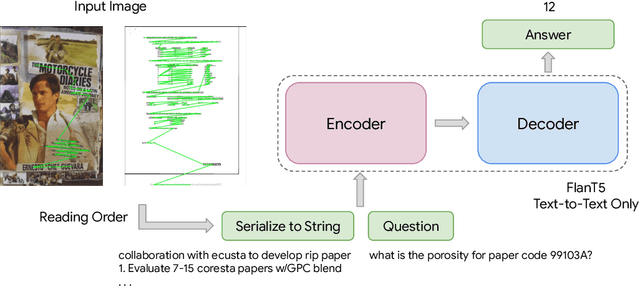

Recent document question answering models consist of two key components: the vision encoder, which captures layout and visual elements in images, and a Large Language Model (LLM) that helps contextualize questions to the image and supplements them with external world knowledge to generate accurate answers. However, the relative contributions of the vision encoder and the language model in these tasks remain unclear. This is especially interesting given the effectiveness of instruction-tuned LLMs, which exhibit remarkable adaptability to new tasks. To this end, we explore the following aspects in this work: (1) The efficacy of an LLM-only approach on document question answering tasks (2) strategies for serializing textual information within document images and feeding it directly to an instruction-tuned LLM, thus bypassing the need for an explicit vision encoder (3) thorough quantitative analysis on the feasibility of such an approach. Our comprehensive analysis encompasses six diverse benchmark datasets, utilizing LLMs of varying scales. Our findings reveal that a strategy exclusively reliant on the LLM yields results that are on par with or closely approach state-of-the-art performance across a range of datasets. We posit that this evaluation framework will serve as a guiding resource for selecting appropriate datasets for future research endeavors that emphasize the fundamental importance of layout and image content information.