 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscape-Sketch-Step: An AI/ML-Based Metaheuristic for Surrogate Optimization Problems
Oct 02, 2023In this paper, we introduce a new heuristics for global optimization in scenarios where extensive evaluations of the cost function are expensive, inaccessible, or even prohibitive. The method, which we call Landscape-Sketch-and-Step (LSS), combines Machine Learning, Stochastic Optimization, and Reinforcement Learning techniques, relying on historical information from previously sampled points to make judicious choices of parameter values where the cost function should be evaluated at. Unlike optimization by Replica Exchange Monte Carlo methods, the number of evaluations of the cost function required in this approach is comparable to that used by Simulated Annealing, quality that is especially important in contexts like high-throughput computing or high-performance computing tasks, where evaluations are either computationally expensive or take a long time to be performed. The method also differs from standard Surrogate Optimization techniques, for it does not construct a surrogate model that aims at approximating or reconstructing the objective function. We illustrate our method by applying it to low dimensional optimization problems (dimensions 1, 2, 4, and 8) that mimick known difficulties of minimization on rugged energy landscapes often seen in Condensed Matter Physics, where cost functions are rugged and plagued with local minima. When compared to classical Simulated Annealing, the LSS shows an effective acceleration of the optimization process.
Binary Classification as a Phase Separation Process
Sep 17, 2020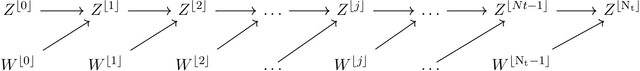

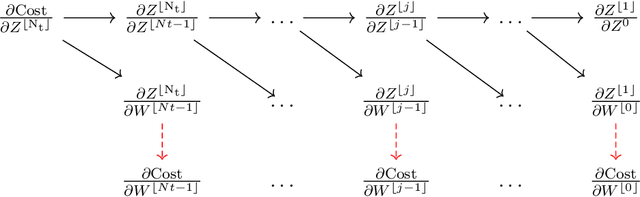

We propose a new binary classification model called Phase Separation Binary Classifier (PSBC). It consists of a discretization of a nonlinear reaction-diffusion equation coupled with an ODE, and is inspired by fluid behavior, namely, on how binary fluids phase separate. Hence, parameters and hyperparameters have physical meaning, whose effects are carefully studied in several different scenarios. PSBC's coefficients are trainable weights, chosen according to a minimization problem using Gradient Descent; optimization relies on a classical Backpropagation with weight sharing. The model can be seen under the framework of feedforward networks, and is endowed with a nonlinear activation function that is linear in trainable weights but polynomial in other variables, yielding a cost function that is also polynomial. In view of the model's connection with ODEs and parabolic PDEs, forward propagation amounts to an initial value problem. Thus, stability conditions are established using the concept of Invariant regions. Interesting model compression properties are thoroughly discussed. We illustrate the classifier's qualities by applying it to the subset of numbers "0" and "1" of the classical MNIST database, where we are able to discern individuals with more than 94\% accuracy, sometimes using less only about 10\% of variables.