 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
Oct 16, 2023
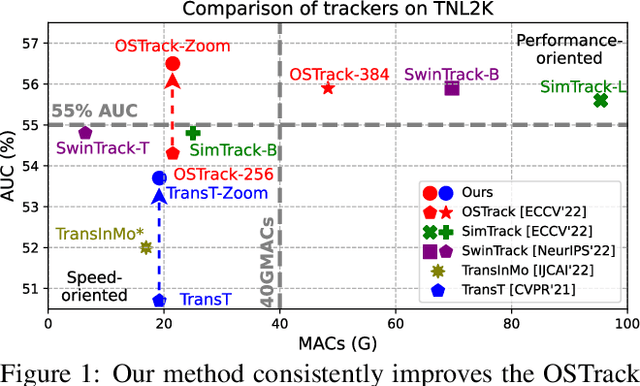
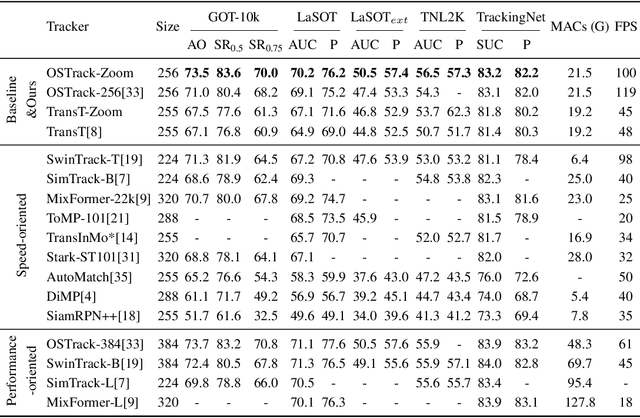
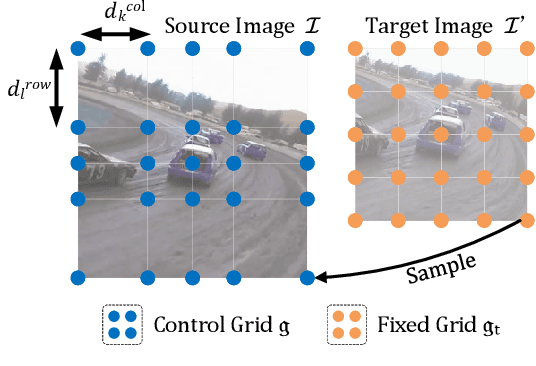
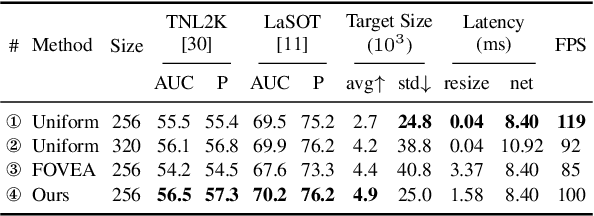
Recently, the transformer has enabled the speed-oriented trackers to approach state-of-the-art (SOTA) performance with high-speed thanks to the smaller input size or the lighter feature extraction backbone, though they still substantially lag behind their corresponding performance-oriented versions. In this paper, we demonstrate that it is possible to narrow or even close this gap while achieving high tracking speed based on the smaller input size. To this end, we non-uniformly resize the cropped image to have a smaller input size while the resolution of the area where the target is more likely to appear is higher and vice versa. This enables us to solve the dilemma of attending to a larger visual field while retaining more raw information for the target despite a smaller input size. Our formulation for the non-uniform resizing can be efficiently solved through quadratic programming (QP) and naturally integrated into most of the crop-based local trackers. Comprehensive experiments on five challenging datasets based on two kinds of transformer trackers, \ie, OSTrack and TransT, demonstrate consistent improvements over them. In particular, applying our method to the speed-oriented version of OSTrack even outperforms its performance-oriented counterpart by 0.6% AUC on TNL2K, while running 50% faster and saving over 55% MACs. Codes and models are available at https://github.com/Kou-99/ZoomTrack.
Efficient Dataset Distillation through Alignment with Smooth and High-Quality Expert Trajectories
Oct 16, 2023Training a large and state-of-the-art machine learning model typically necessitates the use of large-scale datasets, which, in turn, makes the training and parameter-tuning process expensive and time-consuming. Some researchers opt to distil information from real-world datasets into tiny and compact synthetic datasets while maintaining their ability to train a well-performing model, hence proposing a data-efficient method known as Dataset Distillation (DD). Despite recent progress in this field, existing methods still underperform and cannot effectively replace large datasets. In this paper, unlike previous methods that focus solely on improving the efficacy of student distillation, we are the first to recognize the important interplay between expert and student. We argue the significant impact of expert smoothness when employing more potent expert trajectories in subsequent dataset distillation. Based on this, we introduce the integration of clipping loss and gradient penalty to regulate the rate of parameter changes in expert trajectories. Furthermore, in response to the sensitivity exhibited towards randomly initialized variables during distillation, we propose representative initialization for synthetic dataset and balanced inner-loop loss. Finally, we present two enhancement strategies, namely intermediate matching loss and weight perturbation, to mitigate the potential occurrence of cumulative errors. We conduct extensive experiments on datasets of different scales, sizes, and resolutions. The results demonstrate that the proposed method significantly outperforms prior methods.
From Continuous Dynamics to Graph Neural Networks: Neural Diffusion and Beyond
Oct 16, 2023Graph neural networks (GNNs) have demonstrated significant promise in modelling relational data and have been widely applied in various fields of interest. The key mechanism behind GNNs is the so-called message passing where information is being iteratively aggregated to central nodes from their neighbourhood. Such a scheme has been found to be intrinsically linked to a physical process known as heat diffusion, where the propagation of GNNs naturally corresponds to the evolution of heat density. Analogizing the process of message passing to the heat dynamics allows to fundamentally understand the power and pitfalls of GNNs and consequently informs better model design. Recently, there emerges a plethora of works that proposes GNNs inspired from the continuous dynamics formulation, in an attempt to mitigate the known limitations of GNNs, such as oversmoothing and oversquashing. In this survey, we provide the first systematic and comprehensive review of studies that leverage the continuous perspective of GNNs. To this end, we introduce foundational ingredients for adapting continuous dynamics to GNNs, along with a general framework for the design of graph neural dynamics. We then review and categorize existing works based on their driven mechanisms and underlying dynamics. We also summarize how the limitations of classic GNNs can be addressed under the continuous framework. We conclude by identifying multiple open research directions.
Deep Conditional Shape Models for 3D cardiac image segmentation
Oct 16, 2023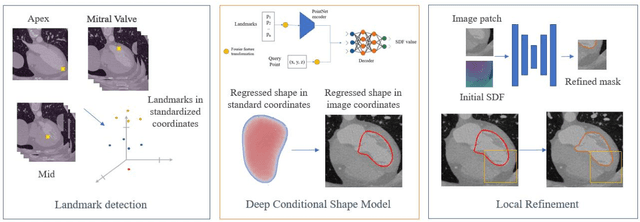

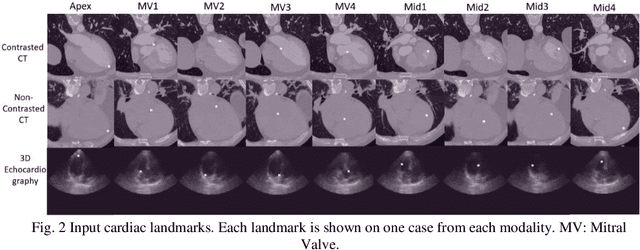

Delineation of anatomical structures is often the first step of many medical image analysis workflows. While convolutional neural networks achieve high performance, these do not incorporate anatomical shape information. We introduce a novel segmentation algorithm that uses Deep Conditional Shape models (DCSMs) as a core component. Using deep implicit shape representations, the algorithm learns a modality-agnostic shape model that can generate the signed distance functions for any anatomy of interest. To fit the generated shape to the image, the shape model is conditioned on anatomic landmarks that can be automatically detected or provided by the user. Finally, we add a modality-dependent, lightweight refinement network to capture any fine details not represented by the implicit function. The proposed DCSM framework is evaluated on the problem of cardiac left ventricle (LV) segmentation from multiple 3D modalities (contrast-enhanced CT, non-contrasted CT, 3D echocardiography-3DE). We demonstrate that the automatic DCSM outperforms the baseline for non-contrasted CT without the local refinement, and with the refinement for contrasted CT and 3DE, especially with significant improvement in the Hausdorff distance. The semi-automatic DCSM with user-input landmarks, while only trained on contrasted CT, achieves greater than 92% Dice for all modalities. Both automatic DCSM with refinement and semi-automatic DCSM achieve equivalent or better performance compared to inter-user variability for these modalities.
Loci-Segmented: Improving Scene Segmentation Learning
Oct 16, 2023Slot-oriented processing approaches for compositional scene representation have recently undergone a tremendous development. We present Loci-Segmented (Loci-s), an advanced scene segmentation neural network that extends the slot-based location and identity tracking architecture Loci (Traub et al., ICLR 2023). The main advancements are (i) the addition of a pre-trained dynamic background module; (ii) a hyper-convolution encoder module, which enables object-focused bottom-up processing; and (iii) a cascaded decoder module, which successively generates object masks, masked depth maps, and masked, depth-map-informed RGB reconstructions. The background module features the learning of both a foreground identifying module and a background re-generator. We further improve performance via (a) the integration of depth information as well as improved slot assignments via (b) slot-location-entity regularization and (b) a prior segmentation network. Even without these latter improvements, the results reveal superior segmentation performance in the MOVi datasets and in another established dataset collection. With all improvements, Loci-s achieves a 32% better intersection over union (IoU) score in MOVi-E than the previous best. We furthermore show that Loci-s generates well-interpretable latent representations. We believe that these representations may serve as a foundation-model-like interpretable basis for solving downstream tasks, such as grounding language and context- and goal-conditioned event processing.
Exploiting User Comments for Early Detection of Fake News Prior to Users' Commenting
Oct 16, 2023Both accuracy and timeliness are key factors in detecting fake news on social media. However, most existing methods encounter an accuracy-timeliness dilemma: Content-only methods guarantee timeliness but perform moderately because of limited available information, while social context-based ones generally perform better but inevitably lead to latency because of social context accumulation needs. To break such a dilemma, a feasible but not well-studied solution is to leverage social contexts (e.g., comments) from historical news for training a detection model and apply it to newly emerging news without social contexts. This requires the model to (1) sufficiently learn helpful knowledge from social contexts, and (2) be well compatible with situations that social contexts are available or not. To achieve this goal, we propose to absorb and parameterize useful knowledge from comments in historical news and then inject it into a content-only detection model. Specifically, we design the Comments Assisted Fake News Detection method (CAS-FEND), which transfers useful knowledge from a comments-aware teacher model to a content-only student model during training. The student model is further used to detect newly emerging fake news. Experiments show that the CAS-FEND student model outperforms all content-only methods and even those with 1/4 comments as inputs, demonstrating its superiority for early detection.
CoBEV: Elevating Roadside 3D Object Detection with Depth and Height Complementarity
Oct 18, 2023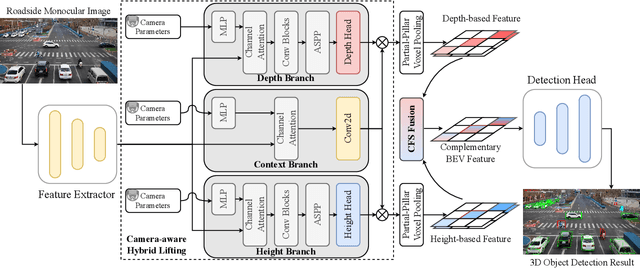
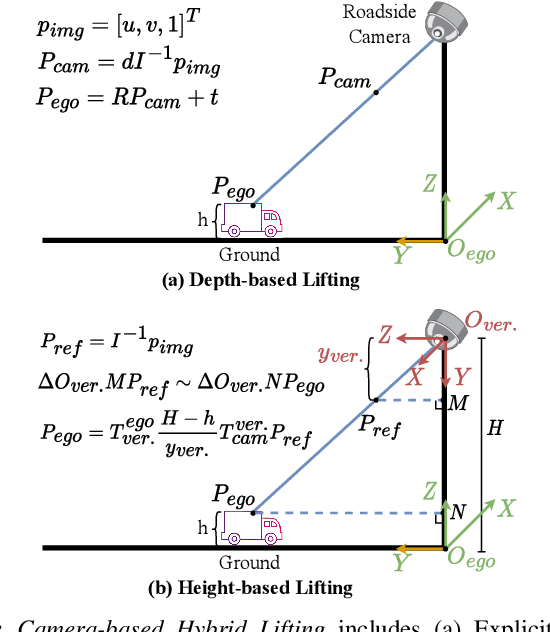

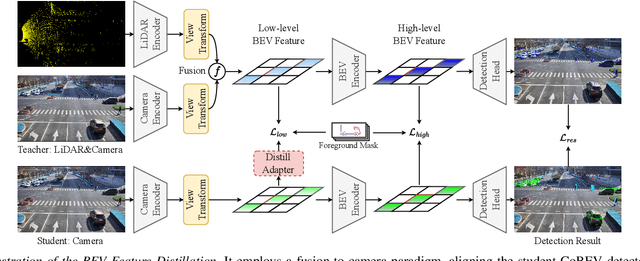
Roadside camera-driven 3D object detection is a crucial task in intelligent transportation systems, which extends the perception range beyond the limitations of vision-centric vehicles and enhances road safety. While previous studies have limitations in using only depth or height information, we find both depth and height matter and they are in fact complementary. The depth feature encompasses precise geometric cues, whereas the height feature is primarily focused on distinguishing between various categories of height intervals, essentially providing semantic context. This insight motivates the development of Complementary-BEV (CoBEV), a novel end-to-end monocular 3D object detection framework that integrates depth and height to construct robust BEV representations. In essence, CoBEV estimates each pixel's depth and height distribution and lifts the camera features into 3D space for lateral fusion using the newly proposed two-stage complementary feature selection (CFS) module. A BEV feature distillation framework is also seamlessly integrated to further enhance the detection accuracy from the prior knowledge of the fusion-modal CoBEV teacher. We conduct extensive experiments on the public 3D detection benchmarks of roadside camera-based DAIR-V2X-I and Rope3D, as well as the private Supremind-Road dataset, demonstrating that CoBEV not only achieves the accuracy of the new state-of-the-art, but also significantly advances the robustness of previous methods in challenging long-distance scenarios and noisy camera disturbance, and enhances generalization by a large margin in heterologous settings with drastic changes in scene and camera parameters. For the first time, the vehicle AP score of a camera model reaches 80% on DAIR-V2X-I in terms of easy mode. The source code will be made publicly available at https://github.com/MasterHow/CoBEV.
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Oct 18, 2023Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
What Makes for Robust Multi-Modal Models in the Face of Missing Modalities?
Oct 10, 2023
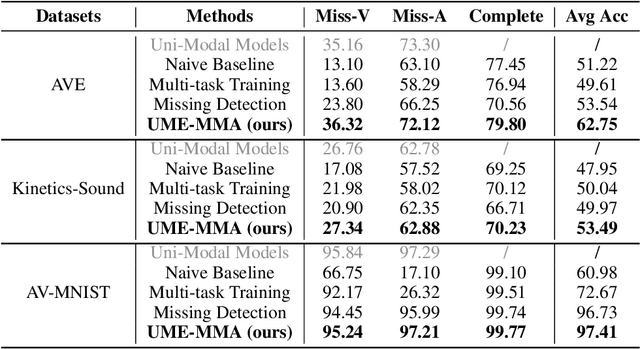
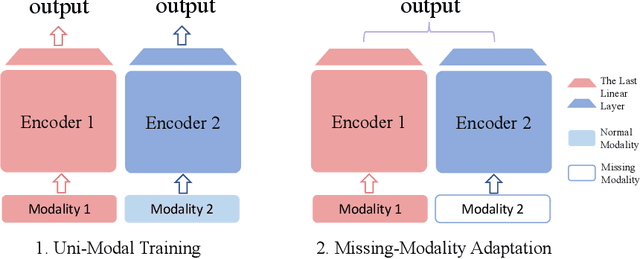
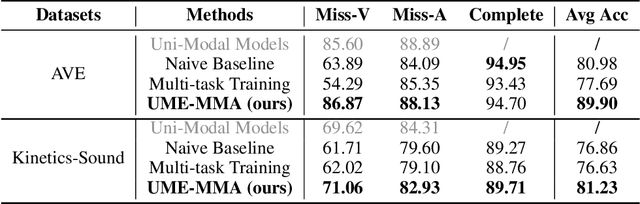
With the growing success of multi-modal learning, research on the robustness of multi-modal models, especially when facing situations with missing modalities, is receiving increased attention. Nevertheless, previous studies in this domain exhibit certain limitations, as they often lack theoretical insights or their methodologies are tied to specific network architectures or modalities. We model the scenarios of multi-modal models encountering missing modalities from an information-theoretic perspective and illustrate that the performance ceiling in such scenarios can be approached by efficiently utilizing the information inherent in non-missing modalities. In practice, there are two key aspects: (1) The encoder should be able to extract sufficiently good features from the non-missing modality; (2) The extracted features should be robust enough not to be influenced by noise during the fusion process across modalities. To this end, we introduce Uni-Modal Ensemble with Missing Modality Adaptation (UME-MMA). UME-MMA employs uni-modal pre-trained weights for the multi-modal model to enhance feature extraction and utilizes missing modality data augmentation techniques to better adapt to situations with missing modalities. Apart from that, UME-MMA, built on a late-fusion learning framework, allows for the plug-and-play use of various encoders, making it suitable for a wide range of modalities and enabling seamless integration of large-scale pre-trained encoders to further enhance performance. And we demonstrate UME-MMA's effectiveness in audio-visual datasets~(e.g., AV-MNIST, Kinetics-Sound, AVE) and vision-language datasets~(e.g., MM-IMDB, UPMC Food101).
ETDock: A Novel Equivariant Transformer for Protein-Ligand Docking
Oct 12, 2023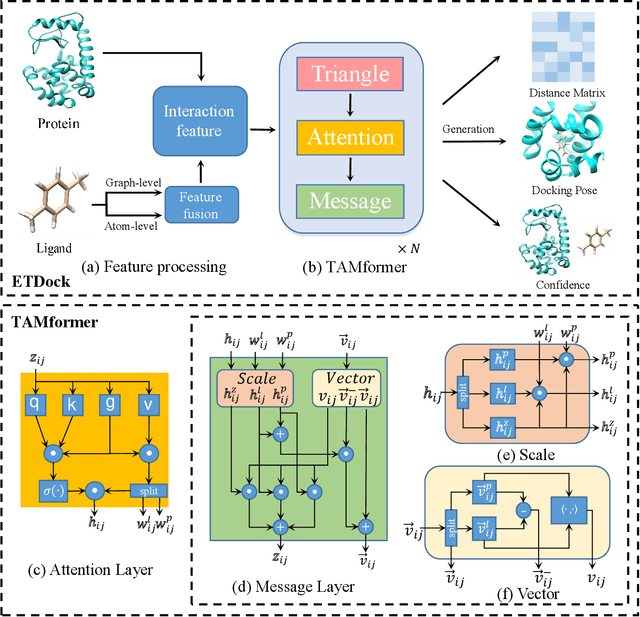
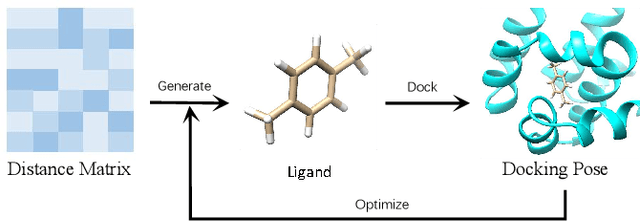
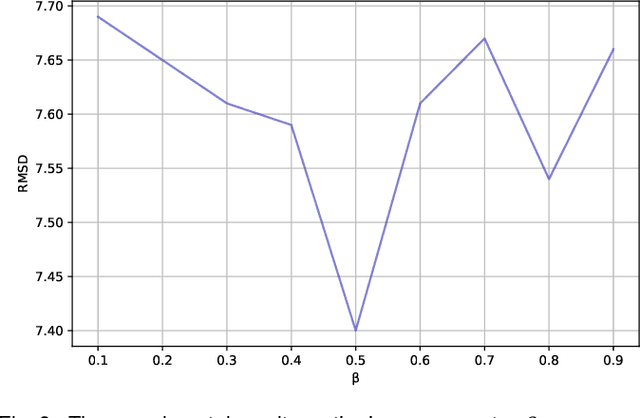
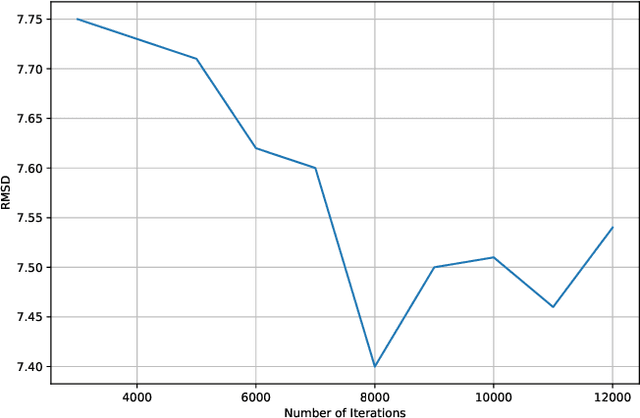
Predicting the docking between proteins and ligands is a crucial and challenging task for drug discovery. However, traditional docking methods mainly rely on scoring functions, and deep learning-based docking approaches usually neglect the 3D spatial information of proteins and ligands, as well as the graph-level features of ligands, which limits their performance. To address these limitations, we propose an equivariant transformer neural network for protein-ligand docking pose prediction. Our approach involves the fusion of ligand graph-level features by feature processing, followed by the learning of ligand and protein representations using our proposed TAMformer module. Additionally, we employ an iterative optimization approach based on the predicted distance matrix to generate refined ligand poses. The experimental results on real datasets show that our model can achieve state-of-the-art performance.