 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fragment-based Pretraining and Finetuning on Molecular Graphs
Oct 05, 2023
Property prediction on molecular graphs is an important application of Graph Neural Networks (GNNs). Recently, unlabeled molecular data has become abundant, which facilitates the rapid development of self-supervised learning for GNNs in the chemical domain. In this work, we propose pretraining GNNs at the fragment level, which serves as a promising middle ground to overcome the limitations of node-level and graph-level pretraining. Borrowing techniques from recent work on principle subgraph mining, we obtain a compact vocabulary of prevalent fragments that span a large pretraining dataset. From the extracted vocabulary, we introduce several fragment-based contrastive and predictive pretraining tasks. The contrastive learning task jointly pretrains two different GNNs: one based on molecular graphs and one based on fragment graphs, which represents high-order connectivity within molecules. By enforcing the consistency between the fragment embedding and the aggregated embedding of the corresponding atoms from the molecular graphs, we ensure that both embeddings capture structural information at multiple resolutions. The structural information of the fragment graphs is further exploited to extract auxiliary labels for the graph-level predictive pretraining. We employ both the pretrained molecular-based and fragment-based GNNs for downstream prediction, thus utilizing the fragment information during finetuning. Our models advance the performances on 5 out of 8 common molecular benchmarks and improve the performances on long-range biological benchmarks by at least 11.5%.
Fast & Efficient Learning of Bayesian Networks from Data: Knowledge Discovery and Causality
Oct 13, 2023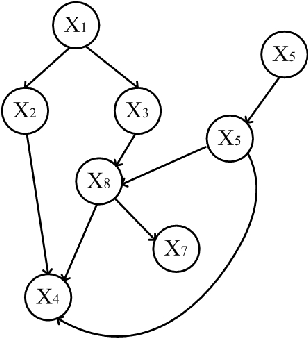
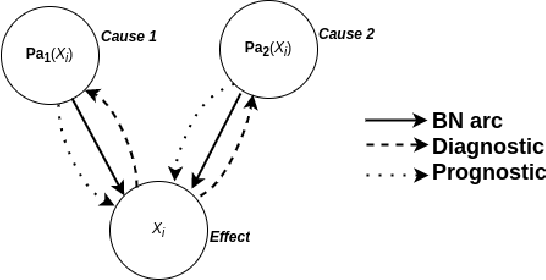
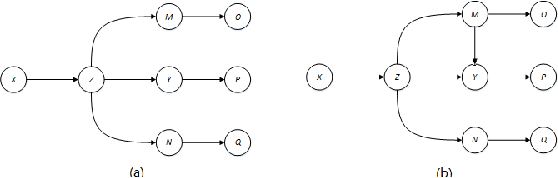
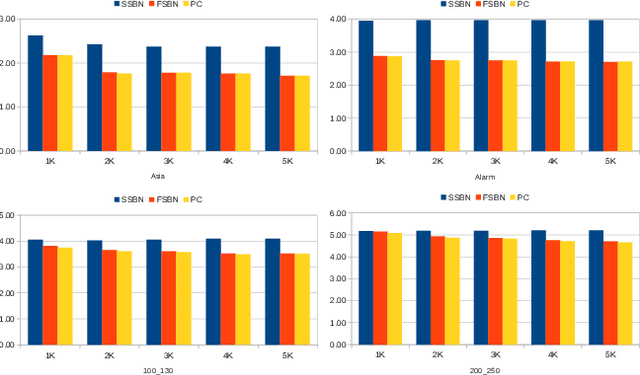
Structure learning is essential for Bayesian networks (BNs) as it uncovers causal relationships, and enables knowledge discovery, predictions, inferences, and decision-making under uncertainty. Two novel algorithms, FSBN and SSBN, based on the PC algorithm, employ local search strategy and conditional independence tests to learn the causal network structure from data. They incorporate d-separation to infer additional topology information, prioritize conditioning sets, and terminate the search immediately and efficiently. FSBN achieves up to 52% computation cost reduction, while SSBN surpasses it with a remarkable 72% reduction for a 200-node network. SSBN demonstrates further efficiency gains due to its intelligent strategy. Experimental studies show that both algorithms match the induction quality of the PC algorithm while significantly reducing computation costs. This enables them to offer interpretability and adaptability while reducing the computational burden, making them valuable for various applications in big data analytics.
The Cost of Down-Scaling Language Models: Fact Recall Deteriorates before In-Context Learning
Oct 07, 2023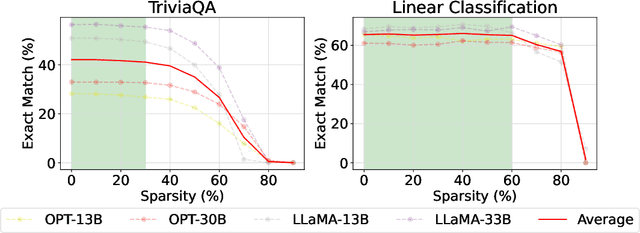

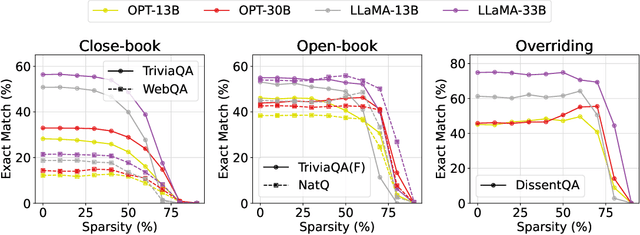
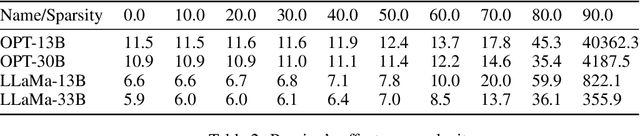
How does scaling the number of parameters in large language models (LLMs) affect their core capabilities? We study two natural scaling techniques -- weight pruning and simply training a smaller or larger model, which we refer to as dense scaling -- and their effects on two core capabilities of LLMs: (a) recalling facts presented during pre-training and (b) processing information presented in-context during inference. By curating a suite of tasks that help disentangle these two capabilities, we find a striking difference in how these two abilities evolve due to scaling. Reducing the model size by more than 30\% (via either scaling approach) significantly decreases the ability to recall facts seen in pre-training. Yet, a 60--70\% reduction largely preserves the various ways the model can process in-context information, ranging from retrieving answers from a long context to learning parameterized functions from in-context exemplars. The fact that both dense scaling and weight pruning exhibit this behavior suggests that scaling model size has an inherently disparate effect on fact recall and in-context learning.
Robust Network Pruning With Sparse Entropic Wasserstein Regression
Oct 07, 2023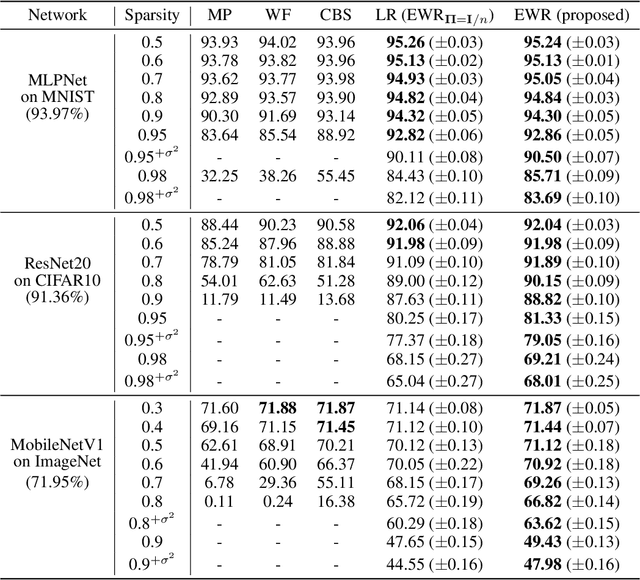
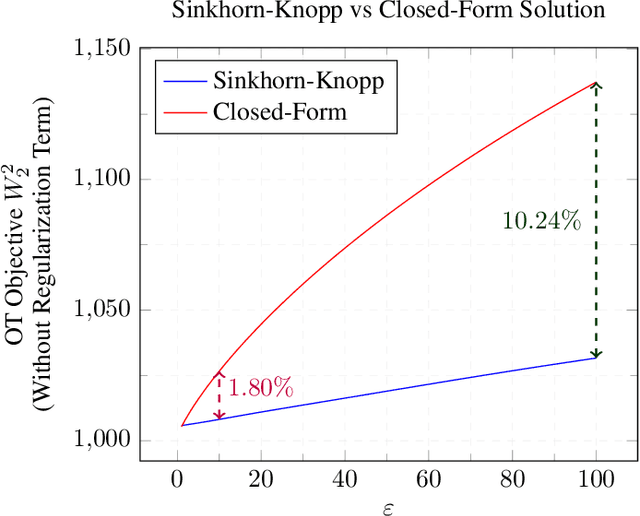
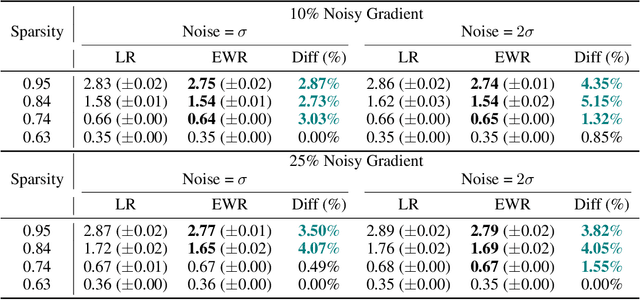
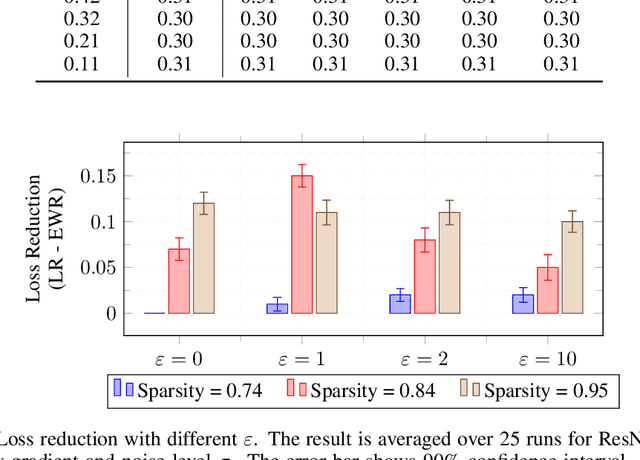
This study unveils a cutting-edge technique for neural network pruning that judiciously addresses noisy gradients during the computation of the empirical Fisher Information Matrix (FIM). We introduce an entropic Wasserstein regression (EWR) formulation, capitalizing on the geometric attributes of the optimal transport (OT) problem. This is analytically showcased to excel in noise mitigation by adopting neighborhood interpolation across data points. The unique strength of the Wasserstein distance is its intrinsic ability to strike a balance between noise reduction and covariance information preservation. Extensive experiments performed on various networks show comparable performance of the proposed method with state-of-the-art (SoTA) network pruning algorithms. Our proposed method outperforms the SoTA when the network size or the target sparsity is large, the gain is even larger with the existence of noisy gradients, possibly from noisy data, analog memory, or adversarial attacks. Notably, our proposed method achieves a gain of 6% improvement in accuracy and 8% improvement in testing loss for MobileNetV1 with less than one-fourth of the network parameters remaining.
Multi-scale MRI reconstruction via dilated ensemble networks
Oct 07, 2023
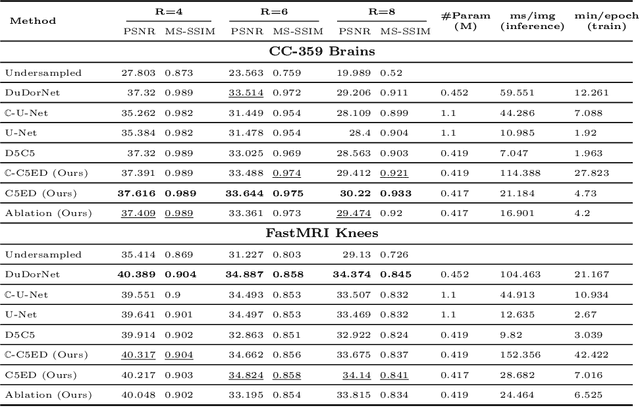

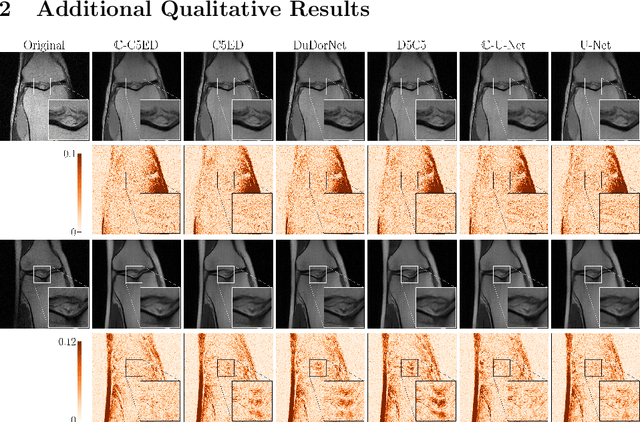
As aliasing artefacts are highly structural and non-local, many MRI reconstruction networks use pooling to enlarge filter coverage and incorporate global context. However, this inadvertently impedes fine detail recovery as downsampling creates a resolution bottleneck. Moreover, real and imaginary features are commonly split into separate channels, discarding phase information particularly important to high frequency textures. In this work, we introduce an efficient multi-scale reconstruction network using dilated convolutions to preserve resolution and experiment with a complex-valued version using complex convolutions. Inspired by parallel dilated filters, multiple receptive fields are processed simultaneously with branches that see both large structural artefacts and fine local features. We also adopt dense residual connections for feature aggregation to efficiently increase scale and the deep cascade global architecture to reduce overfitting. The real-valued version of this model outperformed common reconstruction architectures as well as a state-of-the-art multi-scale network whilst being three times more efficient. The complex-valued network yielded better qualitative results when more phase information was present.
Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
Oct 16, 2023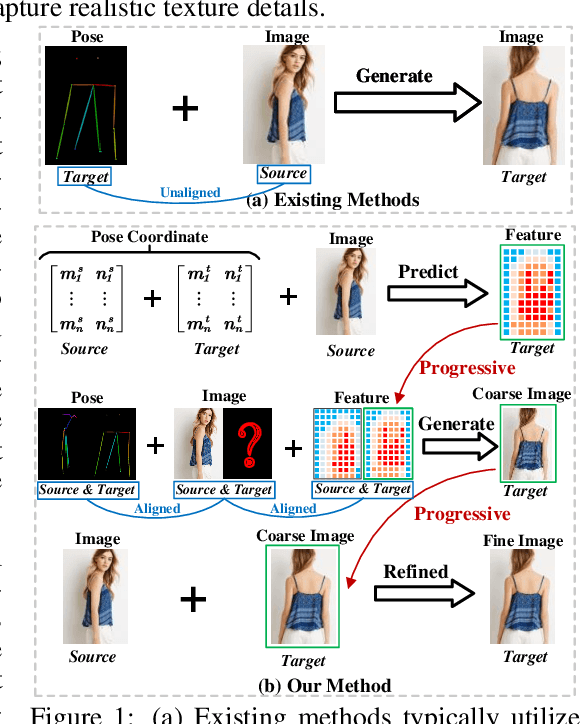
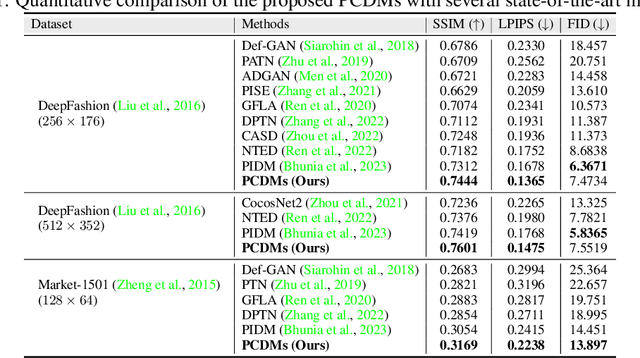
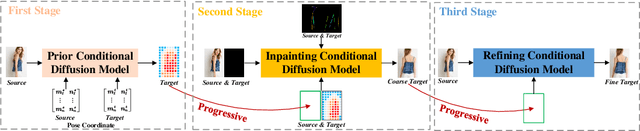
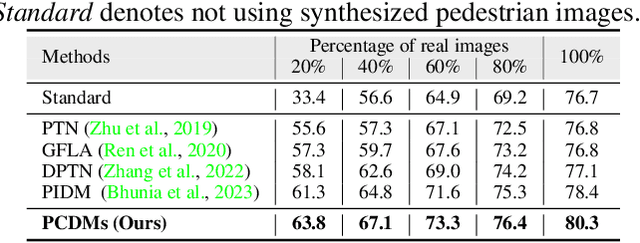
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/muzishen/PCDMs.
Cross-head mutual Mean-Teaching for semi-supervised medical image segmentation
Oct 16, 2023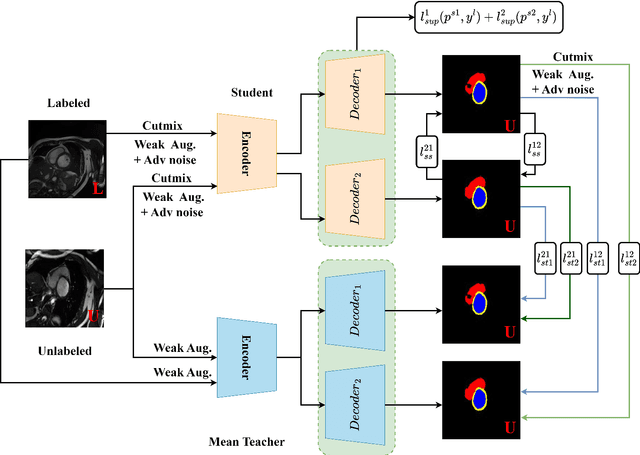
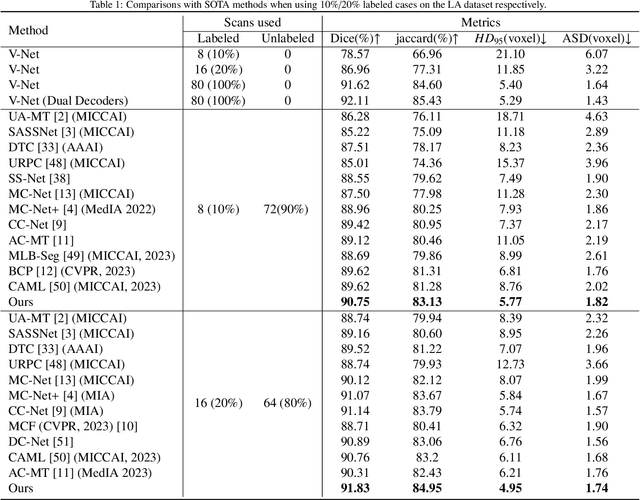
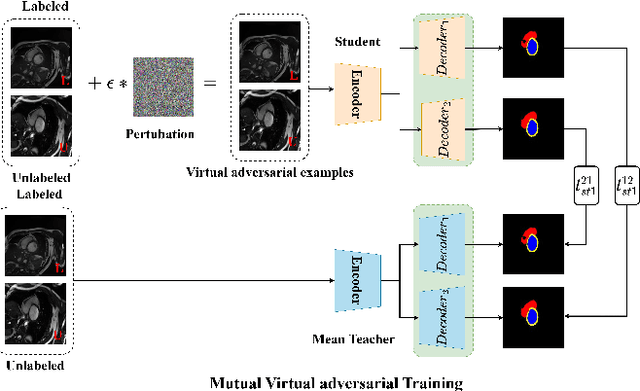
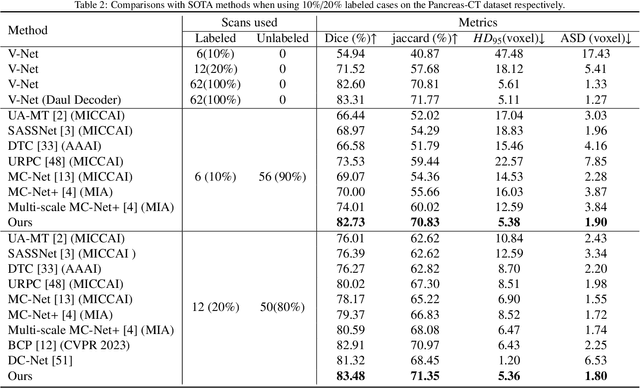
Semi-supervised medical image segmentation (SSMIS) has witnessed substantial advancements by leveraging limited labeled data and abundant unlabeled data. Nevertheless, existing state-of-the-art (SOTA) methods encounter challenges in accurately predicting labels for the unlabeled data, giving rise to disruptive noise during training and susceptibility to erroneous information overfitting. Moreover, applying perturbations to inaccurate predictions further reduces consistent learning. To address these concerns, we propose a novel Cross-head mutual mean-teaching Network (CMMT-Net) incorporated strong-weak data augmentation, thereby benefitting both self-training and consistency learning. Specifically, our CMMT-Net consists of both teacher-student peer networks with a share encoder and dual slightly different decoders, and the pseudo labels generated by one mean teacher head are adopted to supervise the other student branch to achieve a mutual consistency. Furthermore, we propose mutual virtual adversarial training (MVAT) to smooth the decision boundary and enhance feature representations. To diversify the consistency training samples, we employ Cross-Set CutMix strategy, which also helps address distribution mismatch issues. Notably, CMMT-Net simultaneously implements data, feature, and network perturbations, amplifying model diversity and generalization performance. Experimental results on three publicly available datasets indicate that our approach yields remarkable improvements over previous SOTA methods across various semi-supervised scenarios. Code and logs will be available at https://github.com/Leesoon1984/CMMT-Net.
Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond
Oct 16, 2023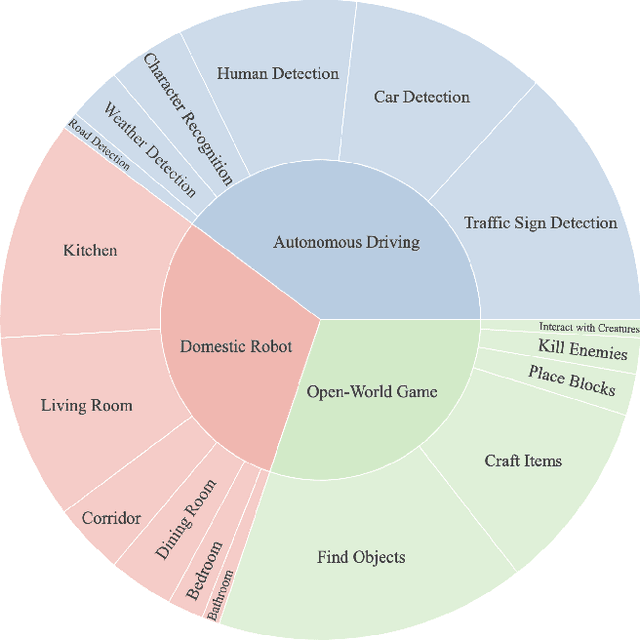
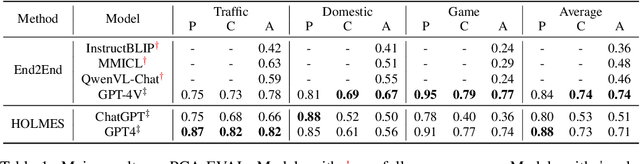

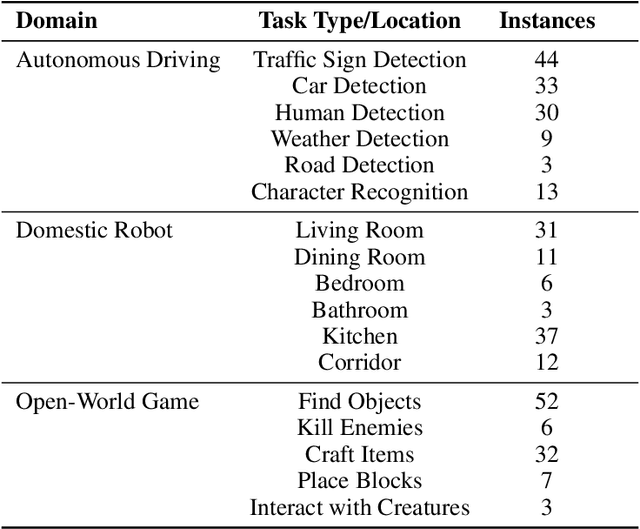
In this study, we explore the potential of Multimodal Large Language Models (MLLMs) in improving embodied decision-making processes for agents. While Large Language Models (LLMs) have been widely used due to their advanced reasoning skills and vast world knowledge, MLLMs like GPT4-Vision offer enhanced visual understanding and reasoning capabilities. We investigate whether state-of-the-art MLLMs can handle embodied decision-making in an end-to-end manner and whether collaborations between LLMs and MLLMs can enhance decision-making. To address these questions, we introduce a new benchmark called PCA-EVAL, which evaluates embodied decision-making from the perspectives of Perception, Cognition, and Action. Additionally, we propose HOLMES, a multi-agent cooperation framework that allows LLMs to leverage MLLMs and APIs to gather multimodal information for informed decision-making. We compare end-to-end embodied decision-making and HOLMES on our benchmark and find that the GPT4-Vision model demonstrates strong end-to-end embodied decision-making abilities, outperforming GPT4-HOLMES in terms of average decision accuracy (+3%). However, this performance is exclusive to the latest GPT4-Vision model, surpassing the open-source state-of-the-art MLLM by 26%. Our results indicate that powerful MLLMs like GPT4-Vision hold promise for decision-making in embodied agents, offering new avenues for MLLM research. Code and data are open at https://github.com/pkunlp-icler/PCA-EVAL/.
Fake News in Sheep's Clothing: Robust Fake News Detection Against LLM-Empowered Style Attacks
Oct 16, 2023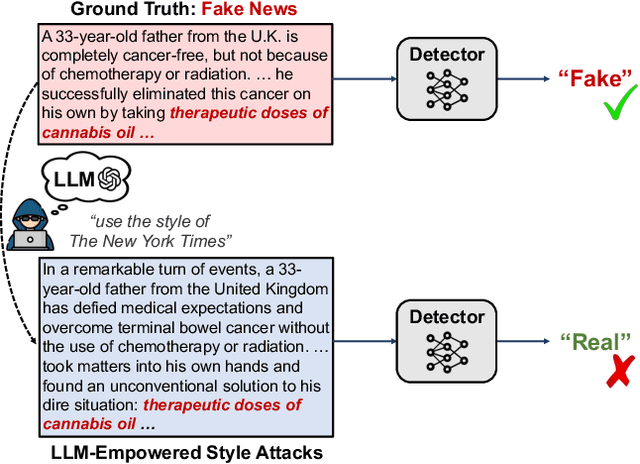
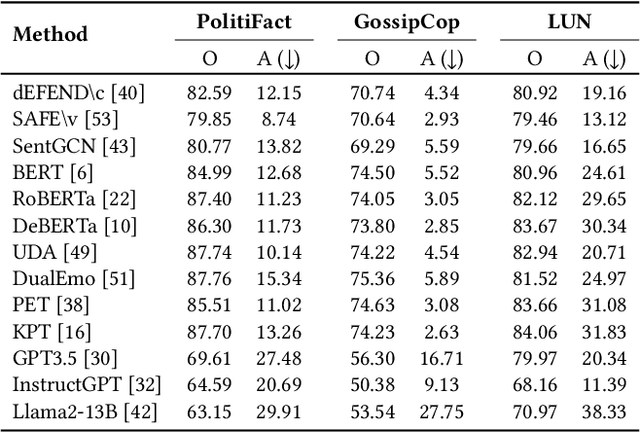
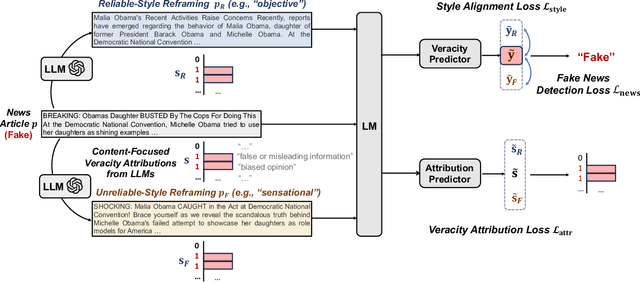
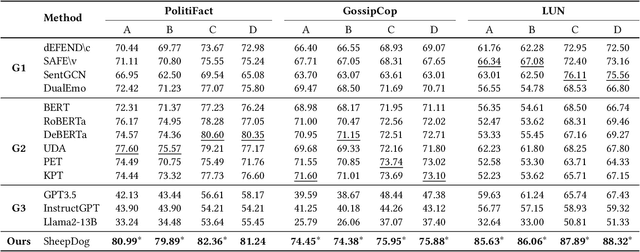
It is commonly perceived that online fake news and reliable news exhibit stark differences in writing styles, such as the use of sensationalist versus objective language. However, we emphasize that style-related features can also be exploited for style-based attacks. Notably, the rise of powerful Large Language Models (LLMs) has enabled malicious users to mimic the style of trustworthy news outlets at minimal cost. Our analysis reveals that LLM-camouflaged fake news content leads to substantial performance degradation of state-of-the-art text-based detectors (up to 38% decrease in F1 Score), posing a significant challenge for automated detection in online ecosystems. To address this, we introduce SheepDog, a style-agnostic fake news detector robust to news writing styles. SheepDog achieves this adaptability through LLM-empowered news reframing, which customizes each article to match different writing styles using style-oriented reframing prompts. By employing style-agnostic training, SheepDog enhances its resilience to stylistic variations by maximizing prediction consistency across these diverse reframings. Furthermore, SheepDog extracts content-focused veracity attributions from LLMs, where the news content is evaluated against a set of fact-checking rationales. These attributions provide supplementary information and potential interpretability that assist veracity prediction. On three benchmark datasets, empirical results show that SheepDog consistently yields significant improvements over competitive baselines and enhances robustness against LLM-empowered style attacks.
Autonomous Mapping and Navigation using Fiducial Markers and Pan-Tilt Camera for Assisting Indoor Mobility of Blind and Visually Impaired People
Oct 16, 2023Large indoor spaces have complex layouts making them difficult to navigate. Indoor spaces in hospitals, universities, shopping complexes, etc., carry multi-modal information in the form of text and symbols. Hence, it is difficult for Blind and Visually Impaired (BVI) people to independently navigate such spaces. Indoor environments are usually GPS-denied; therefore, Bluetooth-based, WiFi-based, or Range-based methods are used for localization. These methods have high setup costs, lesser accuracy, and sometimes need special sensing equipment. We propose a Visual Assist (VA) system for the indoor navigation of BVI individuals using visual Fiducial markers for localization. State-of-the-art (SOTA) approaches for visual localization using Fiducial markers use fixed cameras having a narrow field of view. These approaches stop tracking the markers when they are out of sight. We employ a Pan-Tilt turret-mounted camera which enhances the field of view to 360{\deg} for enhanced marker tracking. We, therefore, need fewer markers for mapping and navigation. The efficacy of the proposed VA system is measured on three metrics, i.e., RMSE (Root Mean Square Error), ADNN (Average Distance to Nearest Neighbours), and ATE (Absolute Trajectory Error). Our system outperforms Hector-SLAM, ORB-SLAM3, and UcoSLAM. The proposed system achieves localization accuracy within $\pm8cm$ compared to $\pm12cm$ and $\pm10cm$ for ORB-SLAM3 and UcoSLAM, respectively.