 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
YOLOR-Based Multi-Task Learning
Sep 29, 2023

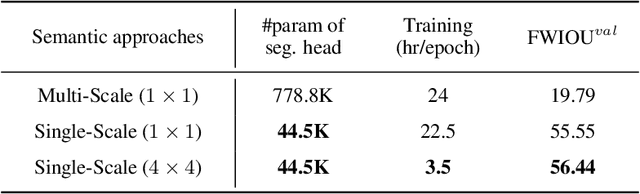
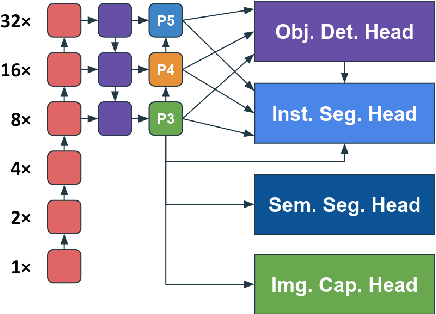
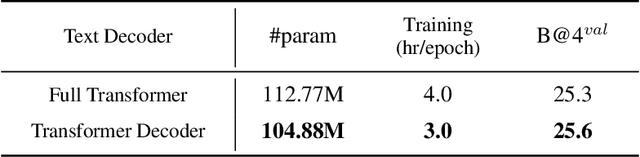
Multi-task learning (MTL) aims to learn multiple tasks using a single model and jointly improve all of them assuming generalization and shared semantics. Reducing conflicts between tasks during joint learning is difficult and generally requires careful network design and extremely large models. We propose building on You Only Learn One Representation (YOLOR), a network architecture specifically designed for multitasking. YOLOR leverages both explicit and implicit knowledge, from data observations and learned latents, respectively, to improve a shared representation while minimizing the number of training parameters. However, YOLOR and its follow-up, YOLOv7, only trained two tasks at once. In this paper, we jointly train object detection, instance segmentation, semantic segmentation, and image captioning. We analyze tradeoffs and attempt to maximize sharing of semantic information. Through our architecture and training strategies, we find that our method achieves competitive performance on all tasks while maintaining a low parameter count and without any pre-training. We will release code soon.
Building Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation Models
Sep 29, 2023In recent years we have seen substantial advances in foundation models for artificial intelligence, including language, vision, and multimodal models. Recent studies have highlighted the potential of using foundation models in geospatial artificial intelligence, known as GeoAI Foundation Models or Geo-Foundation Models, for geographic question answering, remote sensing image understanding, map generation, and location-based services, among others. However, the development and application of GeoAI foundation models can pose serious privacy and security risks, which have not been fully discussed or addressed to date. This paper introduces the potential privacy and security risks throughout the lifecycle of GeoAI foundation models and proposes a comprehensive blueprint for preventative and control strategies. Through this vision paper, we hope to draw the attention of researchers and policymakers in geospatial domains to these privacy and security risks inherent in GeoAI foundation models and advocate for the development of privacy-preserving and secure GeoAI foundation models.
* 1 figure
APNet: Urban-level Scene Segmentation of Aerial Images and Point Clouds
Sep 29, 2023In this paper, we focus on semantic segmentation method for point clouds of urban scenes. Our fundamental concept revolves around the collaborative utilization of diverse scene representations to benefit from different context information and network architectures. To this end, the proposed network architecture, called APNet, is split into two branches: a point cloud branch and an aerial image branch which input is generated from a point cloud. To leverage the different properties of each branch, we employ a geometry-aware fusion module that is learned to combine the results of each branch. Additional separate losses for each branch avoid that one branch dominates the results, ensure the best performance for each branch individually and explicitly define the input domain of the fusion network assuring it only performs data fusion. Our experiments demonstrate that the fusion output consistently outperforms the individual network branches and that APNet achieves state-of-the-art performance of 65.2 mIoU on the SensatUrban dataset. Upon acceptance, the source code will be made accessible.
Randomized Dimension Reduction with Statistical Guarantees
Oct 03, 2023Large models and enormous data are essential driving forces of the unprecedented successes achieved by modern algorithms, especially in scientific computing and machine learning. Nevertheless, the growing dimensionality and model complexity, as well as the non-negligible workload of data pre-processing, also bring formidable costs to such successes in both computation and data aggregation. As the deceleration of Moore's Law slackens the cost reduction of computation from the hardware level, fast heuristics for expensive classical routines and efficient algorithms for exploiting limited data are increasingly indispensable for pushing the limit of algorithm potency. This thesis explores some of such algorithms for fast execution and efficient data utilization. From the computational efficiency perspective, we design and analyze fast randomized low-rank decomposition algorithms for large matrices based on "matrix sketching", which can be regarded as a dimension reduction strategy in the data space. These include the randomized pivoting-based interpolative and CUR decomposition discussed in Chapter 2 and the randomized subspace approximations discussed in Chapter 3. From the sample efficiency perspective, we focus on learning algorithms with various incorporations of data augmentation that improve generalization and distributional robustness provably. Specifically, Chapter 4 presents a sample complexity analysis for data augmentation consistency regularization where we view sample efficiency from the lens of dimension reduction in the function space. Then in Chapter 5, we introduce an adaptively weighted data augmentation consistency regularization algorithm for distributionally robust optimization with applications in medical image segmentation.
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Oct 03, 2023Although Large Language Models (LLMs) and Large Multimodal Models (LMMs) exhibit impressive skills in various domains, their ability for mathematical reasoning within visual contexts has not been formally examined. Equipping LLMs and LMMs with this capability is vital for general-purpose AI assistants and showcases promising potential in education, data analysis, and scientific discovery. To bridge this gap, we present MathVista, a benchmark designed to amalgamate challenges from diverse mathematical and visual tasks. We first taxonomize the key task types, reasoning skills, and visual contexts from the literature to guide our selection from 28 existing math-focused and visual question answering datasets. Then, we construct three new datasets, IQTest, FunctionQA, and PaperQA, to accommodate for missing types of visual contexts. The problems featured often require deep visual understanding beyond OCR or image captioning, and compositional reasoning with rich domain-specific tools, thus posing a notable challenge to existing models. We conduct a comprehensive evaluation of 11 prominent open-source and proprietary foundation models (LLMs, LLMs augmented with tools, and LMMs), and early experiments with GPT-4V. The best-performing model, Multimodal Bard, achieves only 58% of human performance (34.8% vs 60.3%), indicating ample room for further improvement. Given this significant gap, MathVista fuels future research in the development of general-purpose AI agents capable of tackling mathematically intensive and visually rich real-world tasks. Preliminary tests show that MathVista also presents challenges to GPT-4V, underscoring the benchmark's importance. The project is available at https://mathvista.github.io/.
GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature
Oct 03, 2023Generating diverse objects (e.g., images) using generative models (such as GAN or VAE) has achieved impressive results in the recent years, to help solve many design problems that are traditionally done by humans. Going beyond image generation, we aim to find solutions to more general design problems, in which both the diversity of the design and conformity of constraints are important. Such a setting has applications in computer graphics, animation, industrial design, material science, etc, in which we may want the output of the generator to follow discrete/combinatorial constraints and penalize any deviation, which is non-trivial with existing generative models and optimization solvers. To address this, we propose GenCO, a novel framework that conducts end-to-end training of deep generative models integrated with embedded combinatorial solvers, aiming to uncover high-quality solutions aligned with nonlinear objectives. While structurally akin to conventional generative models, GenCO diverges in its role - it focuses on generating instances of combinatorial optimization problems rather than final objects (e.g., images). This shift allows finer control over the generated outputs, enabling assessments of their feasibility and introducing an additional combinatorial loss component. We demonstrate the effectiveness of our approach on a variety of generative tasks characterized by combinatorial intricacies, including game level generation and map creation for path planning, consistently demonstrating its capability to yield diverse, high-quality solutions that reliably adhere to user-specified combinatorial properties.
Image Denoising and the Generative Accumulation of Photons
Aug 01, 2023
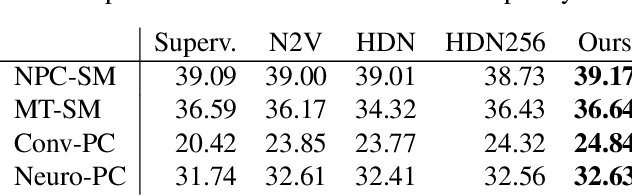
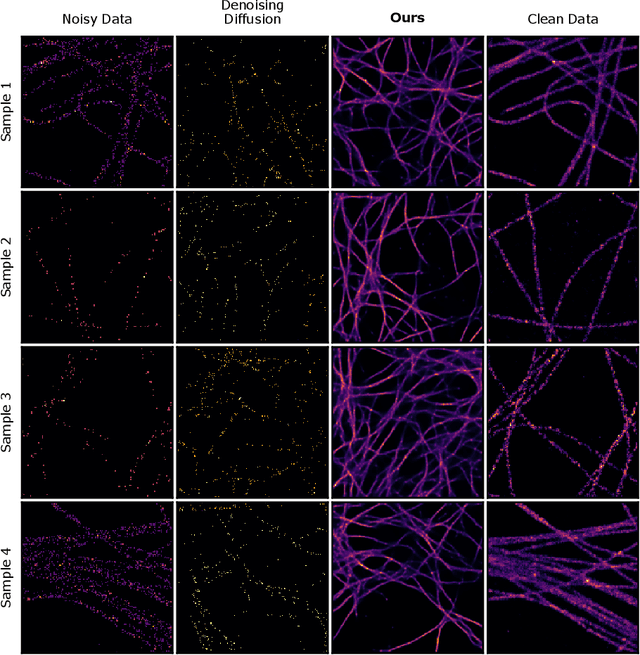

We present a fresh perspective on shot noise corrupted images and noise removal. By viewing image formation as the sequential accumulation of photons on a detector grid, we show that a network trained to predict where the next photon could arrive is in fact solving the minimum mean square error (MMSE) denoising task. This new perspective allows us to make three contributions: We present a new strategy for self-supervised denoising, We present a new method for sampling from the posterior of possible solutions by iteratively sampling and adding small numbers of photons to the image. We derive a full generative model by starting this process from an empty canvas. We call this approach generative accumulation of photons (GAP). We evaluate our method quantitatively and qualitatively on 4 new fluorescence microscopy datasets, which will be made available to the community. We find that it outperforms supervised, self-supervised and unsupervised baselines or performs on-par.
Space Debris: Are Deep Learning-based Image Enhancements part of the Solution?
Aug 01, 2023

The volume of space debris currently orbiting the Earth is reaching an unsustainable level at an accelerated pace. The detection, tracking, identification, and differentiation between orbit-defined, registered spacecraft, and rogue/inactive space ``objects'', is critical to asset protection. The primary objective of this work is to investigate the validity of Deep Neural Network (DNN) solutions to overcome the limitations and image artefacts most prevalent when captured with monocular cameras in the visible light spectrum. In this work, a hybrid UNet-ResNet34 Deep Learning (DL) architecture pre-trained on the ImageNet dataset, is developed. Image degradations addressed include blurring, exposure issues, poor contrast, and noise. The shortage of space-generated data suitable for supervised DL is also addressed. A visual comparison between the URes34P model developed in this work and the existing state of the art in deep learning image enhancement methods, relevant to images captured in space, is presented. Based upon visual inspection, it is determined that our UNet model is capable of correcting for space-related image degradations and merits further investigation to reduce its computational complexity.
Co-Salient Object Detection with Semantic-Level Consensus Extraction and Dispersion
Sep 14, 2023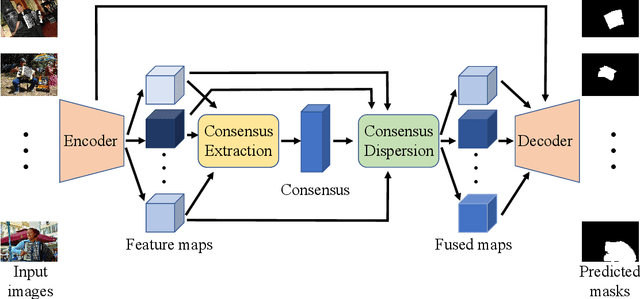
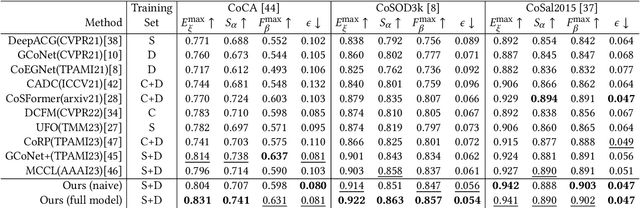

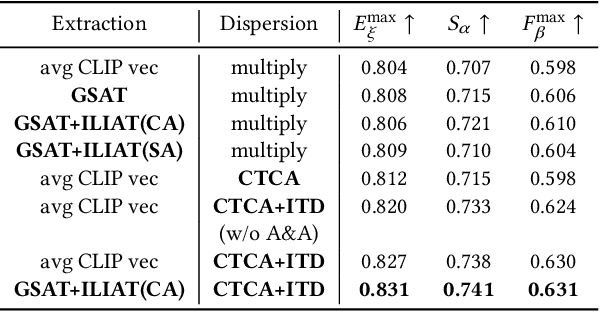
Given a group of images, co-salient object detection (CoSOD) aims to highlight the common salient object in each image. There are two factors closely related to the success of this task, namely consensus extraction, and the dispersion of consensus to each image. Most previous works represent the group consensus using local features, while we instead utilize a hierarchical Transformer module for extracting semantic-level consensus. Therefore, it can obtain a more comprehensive representation of the common object category, and exclude interference from other objects that share local similarities with the target object. In addition, we propose a Transformer-based dispersion module that takes into account the variation of the co-salient object in different scenes. It distributes the consensus to the image feature maps in an image-specific way while making full use of interactions within the group. These two modules are integrated with a ViT encoder and an FPN-like decoder to form an end-to-end trainable network, without additional branch and auxiliary loss. The proposed method is evaluated on three commonly used CoSOD datasets and achieves state-of-the-art performance.
Recurrent Spike-based Image Restoration under General Illumination
Aug 06, 2023Spike camera is a new type of bio-inspired vision sensor that records light intensity in the form of a spike array with high temporal resolution (20,000 Hz). This new paradigm of vision sensor offers significant advantages for many vision tasks such as high speed image reconstruction. However, existing spike-based approaches typically assume that the scenes are with sufficient light intensity, which is usually unavailable in many real-world scenarios such as rainy days or dusk scenes. To unlock more spike-based application scenarios, we propose a Recurrent Spike-based Image Restoration (RSIR) network, which is the first work towards restoring clear images from spike arrays under general illumination. Specifically, to accurately describe the noise distribution under different illuminations, we build a physical-based spike noise model according to the sampling process of the spike camera. Based on the noise model, we design our RSIR network which consists of an adaptive spike transformation module, a recurrent temporal feature fusion module, and a frequency-based spike denoising module. Our RSIR can process the spike array in a recursive manner to ensure that the spike temporal information is well utilized. In the training process, we generate the simulated spike data based on our noise model to train our network. Extensive experiments on real-world datasets with different illuminations demonstrate the effectiveness of the proposed network. The code and dataset are released at https://github.com/BIT-Vision/RSIR.