 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CgT-GAN: CLIP-guided Text GAN for Image Captioning
Aug 23, 2023
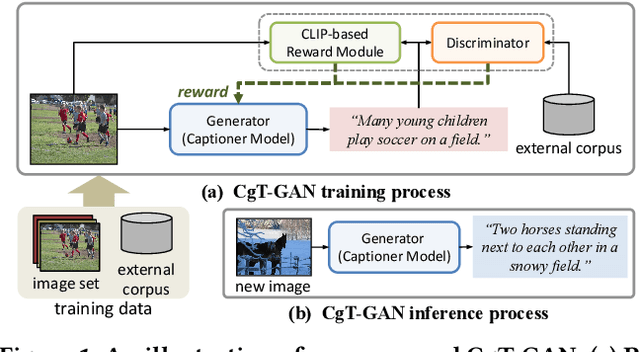
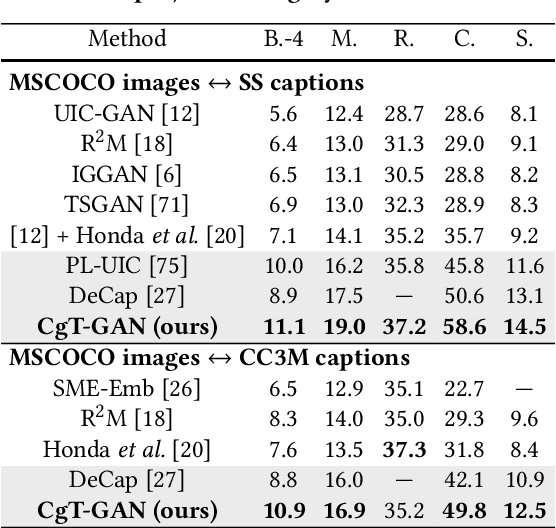
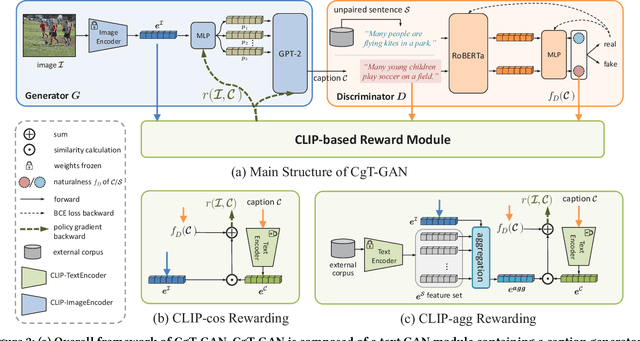
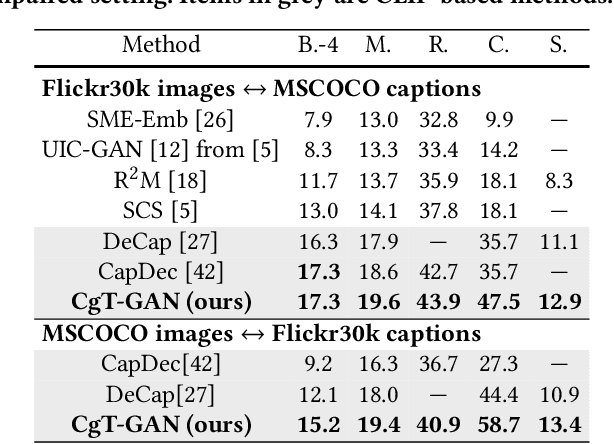
The large-scale visual-language pre-trained model, Contrastive Language-Image Pre-training (CLIP), has significantly improved image captioning for scenarios without human-annotated image-caption pairs. Recent advanced CLIP-based image captioning without human annotations follows a text-only training paradigm, i.e., reconstructing text from shared embedding space. Nevertheless, these approaches are limited by the training/inference gap or huge storage requirements for text embeddings. Given that it is trivial to obtain images in the real world, we propose CLIP-guided text GAN (CgT-GAN), which incorporates images into the training process to enable the model to "see" real visual modality. Particularly, we use adversarial training to teach CgT-GAN to mimic the phrases of an external text corpus and CLIP-based reward to provide semantic guidance. The caption generator is jointly rewarded based on the caption naturalness to human language calculated from the GAN's discriminator and the semantic guidance reward computed by the CLIP-based reward module. In addition to the cosine similarity as the semantic guidance reward (i.e., CLIP-cos), we further introduce a novel semantic guidance reward called CLIP-agg, which aligns the generated caption with a weighted text embedding by attentively aggregating the entire corpus. Experimental results on three subtasks (ZS-IC, In-UIC and Cross-UIC) show that CgT-GAN outperforms state-of-the-art methods significantly across all metrics. Code is available at https://github.com/Lihr747/CgtGAN.
Single Stage Warped Cloth Learning and Semantic-Contextual Attention Feature Fusion for Virtual TryOn
Oct 08, 2023
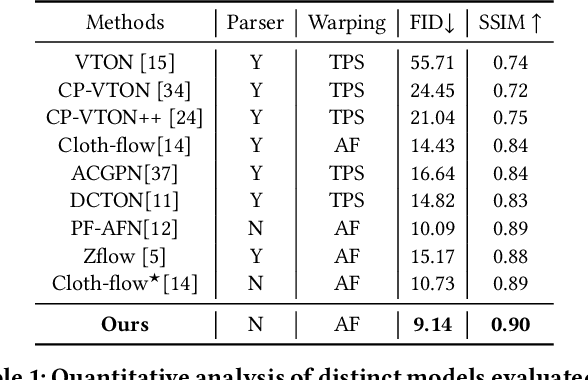
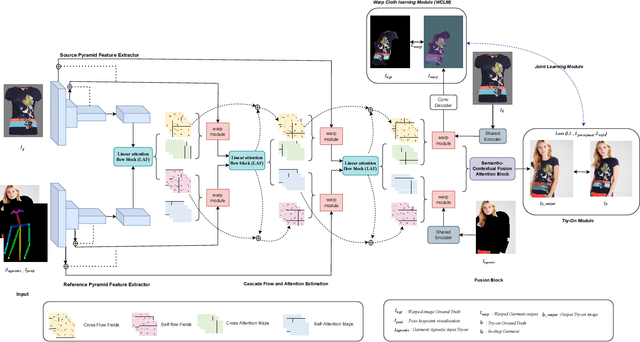

Image-based virtual try-on aims to fit an in-shop garment onto a clothed person image. Garment warping, which aligns the target garment with the corresponding body parts in the person image, is a crucial step in achieving this goal. Existing methods often use multi-stage frameworks to handle clothes warping, person body synthesis and tryon generation separately or rely on noisy intermediate parser-based labels. We propose a novel single-stage framework that implicitly learns the same without explicit multi-stage learning. Our approach utilizes a novel semantic-contextual fusion attention module for garment-person feature fusion, enabling efficient and realistic cloth warping and body synthesis from target pose keypoints. By introducing a lightweight linear attention framework that attends to garment regions and fuses multiple sampled flow fields, we also address misalignment and artifacts present in previous methods. To achieve simultaneous learning of warped garment and try-on results, we introduce a Warped Cloth Learning Module. WCLM uses segmented warped garments as ground truth, operating within a single-stage paradigm. Our proposed approach significantly improves the quality and efficiency of virtual try-on methods, providing users with a more reliable and realistic virtual try-on experience. We evaluate our method on the VITON dataset and demonstrate its state-of-the-art performance in terms of both qualitative and quantitative metrics.
Dense Random Texture Detection using Beta Distribution Statistics
Oct 06, 2023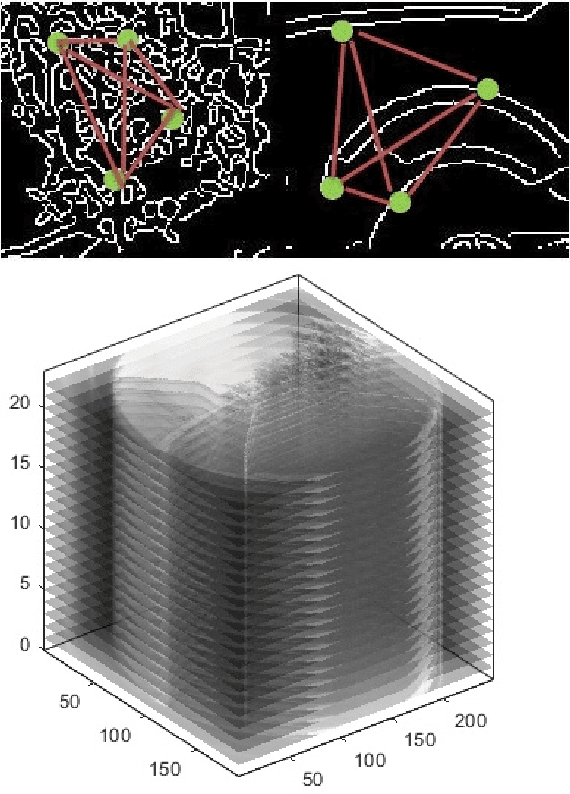

This note describes a method for detecting dense random texture using fully connected points sampled on image edges. An edge image is randomly sampled with points, the standard L2 distance is calculated between all connected points in a neighbourhood. For each point, a check is made if the point intersects with an image edge. If this is the case, a unity value is added to the distance, otherwise zero. From this an edge excess index is calculated for the fully connected edge graph in the range [1.0..2.0], where 1.0 indicate no edges. The ratio can be interpreted as a sampled Bernoulli process with unknown probability. The Bayesian posterior estimate of the probability can be associated with its conjugate prior which is a Beta($\alpha$, $\beta$) distribution, with hyper parameters $\alpha$ and $\beta$ related to the number of edge crossings. Low values of $\beta$ indicate a texture rich area, higher values less rich. The method has been applied to real-time SLAM-based moving object detection, where points are confined to tracked boxes (rois).
Rapid Non-cartesian Reconstruction Using an Implicit Representation of GROG Kernels
Oct 16, 2023MRI data is acquired in Fourier space. Data acquisition is typically performed on a Cartesian grid in this space to enable the use of a fast Fourier transform algorithm to achieve fast and efficient reconstruction. However, it has been shown that for multiple applications, non-Cartesian data acquisition can improve the performance of MR imaging by providing fast and more efficient data acquisition, and improving motion robustness. Nonetheless, the image reconstruction process of non-Cartesian data is more involved and can be time-consuming, even through the use of efficient algorithms such as non-uniform FFT (NUFFT). This work provides an efficient approach (iGROG) to transform the non-Cartesian data into Cartesian data, to achieve simpler and faster reconstruction which should help enable non-Cartesian data sampling to be performed more widely in MRI.
KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo
A Non-monotonic Smooth Activation Function
Oct 16, 2023Activation functions are crucial in deep learning models since they introduce non-linearity into the networks, allowing them to learn from errors and make adjustments, which is essential for learning complex patterns. The essential purpose of activation functions is to transform unprocessed input signals into significant output activations, promoting information transmission throughout the neural network. In this study, we propose a new activation function called Sqish, which is a non-monotonic and smooth function and an alternative to existing ones. We showed its superiority in classification, object detection, segmentation tasks, and adversarial robustness experiments. We got an 8.21% improvement over ReLU on the CIFAR100 dataset with the ShuffleNet V2 model in the FGSM adversarial attack. We also got a 5.87% improvement over ReLU on image classification on the CIFAR100 dataset with the ShuffleNet V2 model.
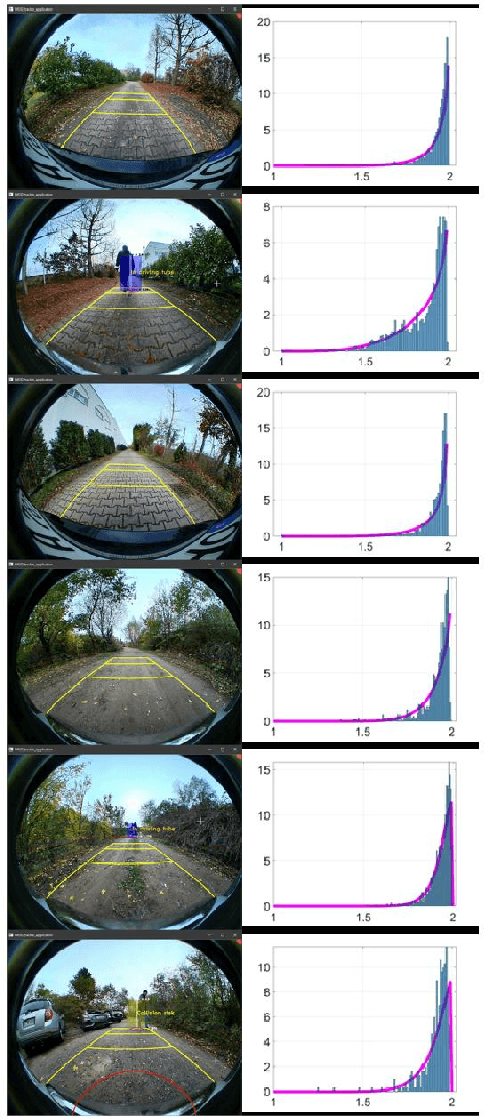
COIN-LIO: Complementary Intensity-Augmented LiDAR Inertial Odometry
Oct 02, 2023
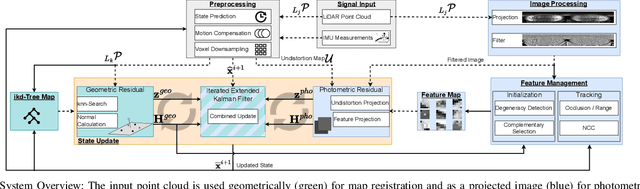


We present COIN-LIO, a LiDAR Inertial Odometry pipeline that tightly couples information from LiDAR intensity with geometry-based point cloud registration. The focus of our work is to improve the robustness of LiDAR-inertial odometry in geometrically degenerate scenarios, like tunnels or flat fields. We project LiDAR intensity returns into an intensity image, and propose an image processing pipeline that produces filtered images with improved brightness consistency within the image as well as across different scenes. To effectively leverage intensity as an additional modality, we present a novel feature selection scheme that detects uninformative directions in the point cloud registration and explicitly selects patches with complementary image information. Photometric error minimization in the image patches is then fused with inertial measurements and point-to-plane registration in an iterated Extended Kalman Filter. The proposed approach improves accuracy and robustness on a public dataset. We additionally publish a new dataset, that captures five real-world environments in challenging, geometrically degenerate scenes. By using the additional photometric information, our approach shows drastically improved robustness against geometric degeneracy in environments where all compared baseline approaches fail.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
SYRAC: Synthesize, Rank, and Count
Oct 11, 2023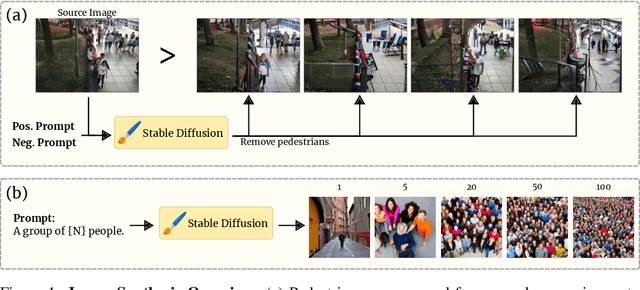
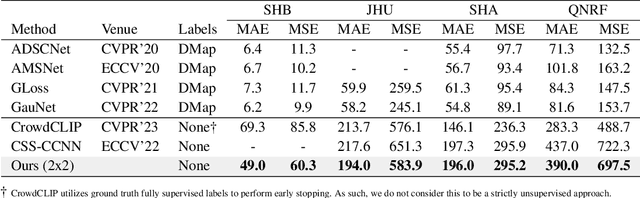


Crowd counting is a critical task in computer vision, with several important applications. However, existing counting methods rely on labor-intensive density map annotations, necessitating the manual localization of each individual pedestrian. While recent efforts have attempted to alleviate the annotation burden through weakly or semi-supervised learning, these approaches fall short of significantly reducing the workload. We propose a novel approach to eliminate the annotation burden by leveraging latent diffusion models to generate synthetic data. However, these models struggle to reliably understand object quantities, leading to noisy annotations when prompted to produce images with a specific quantity of objects. To address this, we use latent diffusion models to create two types of synthetic data: one by removing pedestrians from real images, which generates ranked image pairs with a weak but reliable object quantity signal, and the other by generating synthetic images with a predetermined number of objects, offering a strong but noisy counting signal. Our method utilizes the ranking image pairs for pre-training and then fits a linear layer to the noisy synthetic images using these crowd quantity features. We report state-of-the-art results for unsupervised crowd counting.
Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
Oct 05, 2023Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it carefully divides the data into safe and risky subsets. SAFECLIP trains on the risky data by applying unimodal CL to image and text modalities separately, and trains on the safe data using the CLIP loss. By gradually increasing the size of the safe subset during the training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments show that SAFECLIP decrease the attack success rate of targeted data poisoning attacks from 93.75% to 0% and that of the backdoor attacks from 100% to 0%, without harming the CLIP performance on various datasets.