 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised convolutional neural network fusion approach for change detection in remote sensing images
Nov 07, 2023
With the rapid development of deep learning, a variety of change detection methods based on deep learning have emerged in recent years. However, these methods usually require a large number of training samples to train the network model, so it is very expensive. In this paper, we introduce a completely unsupervised shallow convolutional neural network (USCNN) fusion approach for change detection. Firstly, the bi-temporal images are transformed into different feature spaces by using convolution kernels of different sizes to extract multi-scale information of the images. Secondly, the output features of bi-temporal images at the same convolution kernels are subtracted to obtain the corresponding difference images, and the difference feature images at the same scale are fused into one feature image by using 1 * 1 convolution layer. Finally, the output features of different scales are concatenated and a 1 * 1 convolution layer is used to fuse the multi-scale information of the image. The model parameters are obtained by a redesigned sparse function. Our model has three features: the entire training process is conducted in an unsupervised manner, the network architecture is shallow, and the objective function is sparse. Thus, it can be seen as a kind of lightweight network model. Experimental results on four real remote sensing datasets indicate the feasibility and effectiveness of the proposed approach.
FusionViT: Hierarchical 3D Object Detection via LiDAR-Camera Vision Transformer Fusion
Nov 07, 2023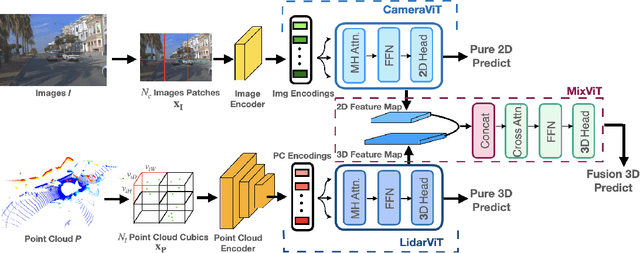
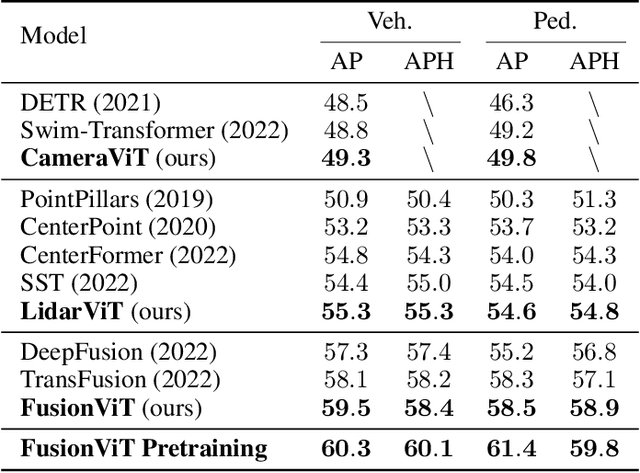
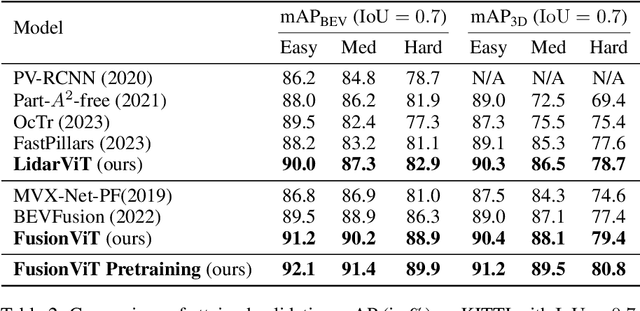

For 3D object detection, both camera and lidar have been demonstrated to be useful sensory devices for providing complementary information about the same scenery with data representations in different modalities, e.g., 2D RGB image vs 3D point cloud. An effective representation learning and fusion of such multi-modal sensor data is necessary and critical for better 3D object detection performance. To solve the problem, in this paper, we will introduce a novel vision transformer-based 3D object detection model, namely FusionViT. Different from the existing 3D object detection approaches, FusionViT is a pure-ViT based framework, which adopts a hierarchical architecture by extending the transformer model to embed both images and point clouds for effective representation learning. Such multi-modal data embedding representations will be further fused together via a fusion vision transformer model prior to feeding the learned features to the object detection head for both detection and localization of the 3D objects in the input scenery. To demonstrate the effectiveness of FusionViT, extensive experiments have been done on real-world traffic object detection benchmark datasets KITTI and Waymo Open. Notably, our FusionViT model can achieve state-of-the-art performance and outperforms not only the existing baseline methods that merely rely on camera images or lidar point clouds, but also the latest multi-modal image-point cloud deep fusion approaches.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
Degradation Estimation Recurrent Neural Network with Local and Non-Local Priors for Compressive Spectral Imaging
Nov 15, 2023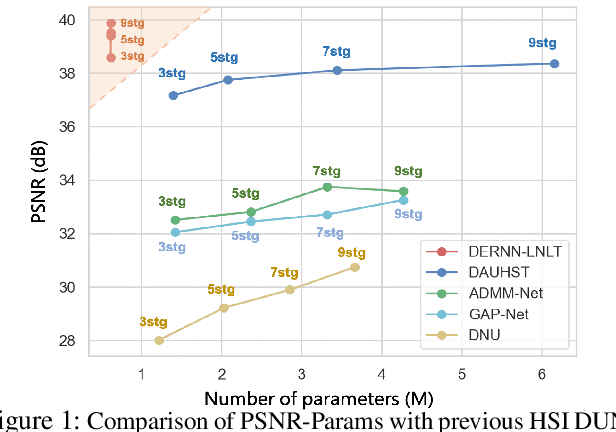
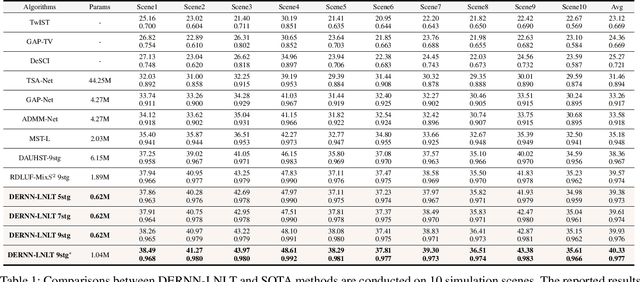
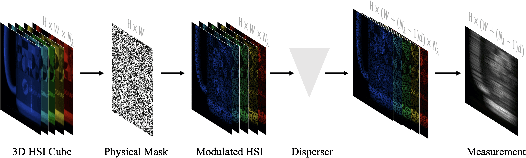
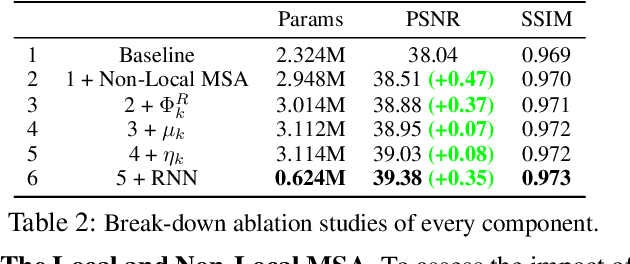
In coded aperture snapshot spectral imaging (CASSI) systems, a core problem is to recover the 3D hyperspectral image (HSI) from the 2D measurement. Current deep unfolding networks (DUNs) for the HSI reconstruction mainly suffered from three issues. Firstly, in previous DUNs, the DNNs across different stages were unable to share the feature representations learned from different stages, leading to parameter sparsity, which in turn limited their reconstruction potential. Secondly, previous DUNs fail to estimate degradation-related parameters within a unified framework, including the degradation matrix in the data subproblem and the noise level in the prior subproblem. Consequently, either the accuracy of solving the data or the prior subproblem is compromised. Thirdly, exploiting both local and non-local priors for the HSI reconstruction is crucial, and it remains a key issue to be addressed. In this paper, we first transform the DUN into a Recurrent Neural Network (RNN) by sharing parameters across stages, which allows the DNN in each stage could learn feature representation from different stages, enhancing the representativeness of the DUN. Secondly, we incorporate the Degradation Estimation Network into the RNN (DERNN), which simultaneously estimates the degradation matrix and the noise level by residual learning with reference to the sensing matrix. Thirdly, we propose a Local and Non-Local Transformer (LNLT) to effectively exploit both local and non-local priors in HSIs. By integrating the LNLT into the DERNN for solving the prior subproblem, we propose the DERNN-LNLT, which achieves state-of-the-art performance.
ConeQuest: A Benchmark for Cone Segmentation on Mars
Nov 15, 2023Over the years, space scientists have collected terabytes of Mars data from satellites and rovers. One important set of features identified in Mars orbital images is pitted cones, which are interpreted to be mud volcanoes believed to form in regions that were once saturated in water (i.e., a lake or ocean). Identifying pitted cones globally on Mars would be of great importance, but expert geologists are unable to sort through the massive orbital image archives to identify all examples. However, this task is well suited for computer vision. Although several computer vision datasets exist for various Mars-related tasks, there is currently no open-source dataset available for cone detection/segmentation. Furthermore, previous studies trained models using data from a single region, which limits their applicability for global detection and mapping. Motivated by this, we introduce ConeQuest, the first expert-annotated public dataset to identify cones on Mars. ConeQuest consists of >13k samples from 3 different regions of Mars. We propose two benchmark tasks using ConeQuest: (i) Spatial Generalization and (ii) Cone-size Generalization. We finetune and evaluate widely-used segmentation models on both benchmark tasks. Results indicate that cone segmentation is a challenging open problem not solved by existing segmentation models, which achieve an average IoU of 52.52% and 42.55% on in-distribution data for tasks (i) and (ii), respectively. We believe this new benchmark dataset will facilitate the development of more accurate and robust models for cone segmentation. Data and code are available at https://github.com/kerner-lab/ConeQuest.
Language Guided Visual Question Answering: Elevate Your Multimodal Language Model Using Knowledge-Enriched Prompts
Oct 31, 2023
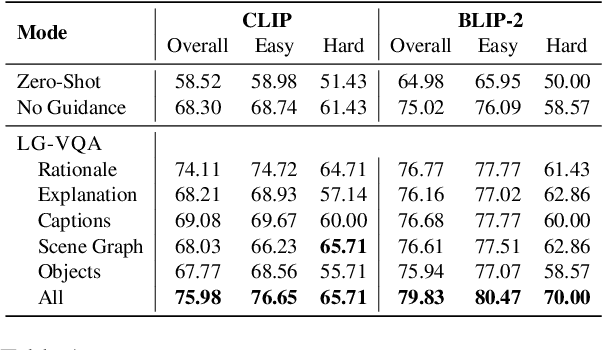
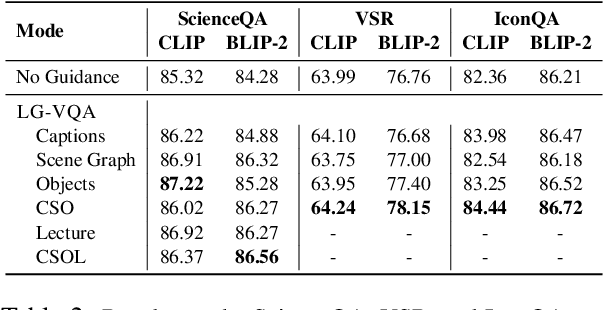
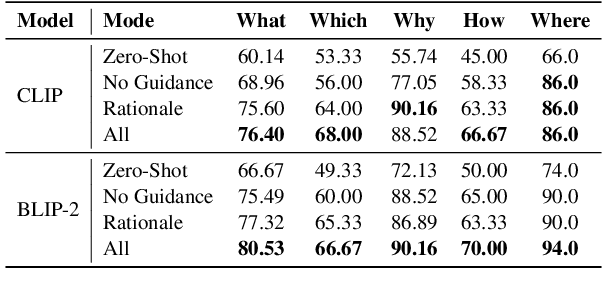
Visual question answering (VQA) is the task of answering questions about an image. The task assumes an understanding of both the image and the question to provide a natural language answer. VQA has gained popularity in recent years due to its potential applications in a wide range of fields, including robotics, education, and healthcare. In this paper, we focus on knowledge-augmented VQA, where answering the question requires commonsense knowledge, world knowledge, and reasoning about ideas and concepts not present in the image. We propose a multimodal framework that uses language guidance (LG) in the form of rationales, image captions, scene graphs, etc to answer questions more accurately. We benchmark our method on the multi-choice question-answering task of the A-OKVQA, Science-QA, VSR, and IconQA datasets using CLIP and BLIP models. We show that the use of language guidance is a simple but powerful and effective strategy for visual question answering. Our language guidance improves the performance of CLIP by 7.6% and BLIP-2 by 4.8% in the challenging A-OKVQA dataset. We also observe consistent improvement in performance on the Science-QA, VSR, and IconQA datasets when using the proposed language guidances. The implementation of LG-VQA is publicly available at https:// github.com/declare-lab/LG-VQA.
Quantitative Evaluation of a Multi-Modal Camera Setup for Fusing Event Data with RGB Images
Nov 03, 2023Event-based cameras, also called silicon retinas, potentially revolutionize computer vision by detecting and reporting significant changes in intensity asynchronous events, offering extended dynamic range, low latency, and low power consumption, enabling a wide range of applications from autonomous driving to longtime surveillance. As an emerging technology, there is a notable scarcity of publicly available datasets for event-based systems that also feature frame-based cameras, in order to exploit the benefits of both technologies. This work quantitatively evaluates a multi-modal camera setup for fusing high-resolution DVS data with RGB image data by static camera alignment. The proposed setup, which is intended for semi-automatic DVS data labeling, combines two recently released Prophesee EVK4 DVS cameras and one global shutter XIMEA MQ022CG-CM RGB camera. After alignment, state-of-the-art object detection or segmentation networks label the image data by mapping boundary boxes or labeled pixels directly to the aligned events. To facilitate this process, various time-based synchronization methods for DVS data are analyzed, and calibration accuracy, camera alignment, and lens impact are evaluated. Experimental results demonstrate the benefits of the proposed system: the best synchronization method yields an image calibration error of less than 0.90px and a pixel cross-correlation deviation of1.6px, while a lens with 8mm focal length enables detection of objects with size 30cm at a distance of 350m against homogeneous background.
Neural Collage Transfer: Artistic Reconstruction via Material Manipulation
Nov 03, 2023Collage is a creative art form that uses diverse material scraps as a base unit to compose a single image. Although pixel-wise generation techniques can reproduce a target image in collage style, it is not a suitable method due to the solid stroke-by-stroke nature of the collage form. While some previous works for stroke-based rendering produced decent sketches and paintings, collages have received much less attention in research despite their popularity as a style. In this paper, we propose a method for learning to make collages via reinforcement learning without the need for demonstrations or collage artwork data. We design the collage Markov Decision Process (MDP), which allows the agent to handle various materials and propose a model-based soft actor-critic to mitigate the agent's training burden derived from the sophisticated dynamics of collage. Moreover, we devise additional techniques such as active material selection and complexity-based multi-scale collage to handle target images at any size and enhance the results' aesthetics by placing relatively more scraps in areas of high complexity. Experimental results show that the trained agent appropriately selected and pasted materials to regenerate the target image into a collage and obtained a higher evaluation score on content and style than pixel-wise generation methods. Code is available at https://github.com/northadventure/CollageRL.
From Trojan Horses to Castle Walls: Unveiling Bilateral Backdoor Effects in Diffusion Models
Nov 04, 2023While state-of-the-art diffusion models (DMs) excel in image generation, concerns regarding their security persist. Earlier research highlighted DMs' vulnerability to backdoor attacks, but these studies placed stricter requirements than conventional methods like 'BadNets' in image classification. This is because the former necessitates modifications to the diffusion sampling and training procedures. Unlike the prior work, we investigate whether generating backdoor attacks in DMs can be as simple as BadNets, i.e., by only contaminating the training dataset without tampering the original diffusion process. In this more realistic backdoor setting, we uncover bilateral backdoor effects that not only serve an adversarial purpose (compromising the functionality of DMs) but also offer a defensive advantage (which can be leveraged for backdoor defense). Specifically, we find that a BadNets-like backdoor attack remains effective in DMs for producing incorrect images (misaligned with the intended text conditions), and thereby yielding incorrect predictions when DMs are used as classifiers. Meanwhile, backdoored DMs exhibit an increased ratio of backdoor triggers, a phenomenon we refer to as `trigger amplification', among the generated images. We show that this latter insight can be used to enhance the detection of backdoor-poisoned training data. Even under a low backdoor poisoning ratio, studying the backdoor effects of DMs is also valuable for designing anti-backdoor image classifiers. Last but not least, we establish a meaningful linkage between backdoor attacks and the phenomenon of data replications by exploring DMs' inherent data memorization tendencies. The codes of our work are available at https://github.com/OPTML-Group/BiBadDiff.
An Evaluation of Forensic Facial Recognition
Nov 10, 2023

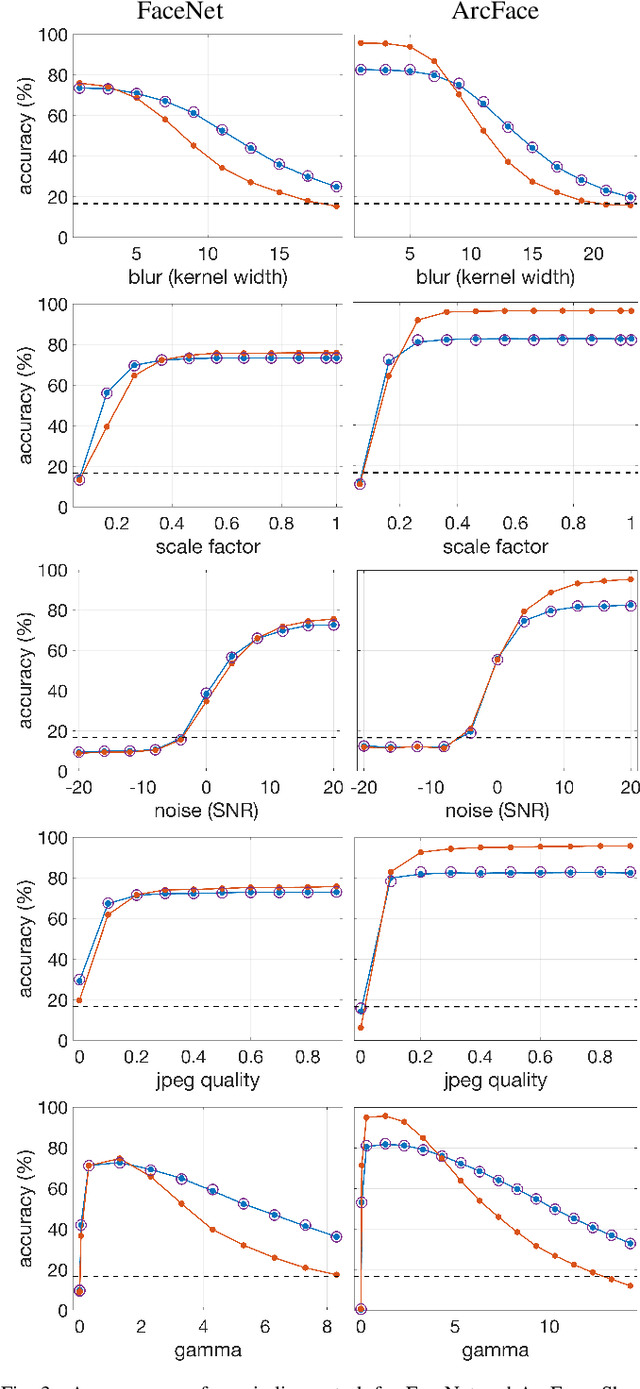
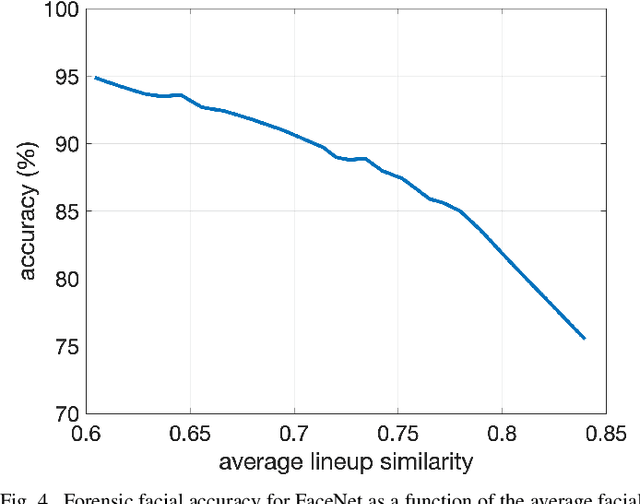
Recent advances in machine learning and computer vision have led to reported facial recognition accuracies surpassing human performance. We question if these systems will translate to real-world forensic scenarios in which a potentially low-resolution, low-quality, partially-occluded image is compared against a standard facial database. We describe the construction of a large-scale synthetic facial dataset along with a controlled facial forensic lineup, the combination of which allows for a controlled evaluation of facial recognition under a range of real-world conditions. Using this synthetic dataset, and a popular dataset of real faces, we evaluate the accuracy of two popular neural-based recognition systems. We find that previously reported face recognition accuracies of more than 95% drop to as low as 65% in this more challenging forensic scenario.