 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSplat: Fast and Memory-Efficient Open-Vocabulary 3D Scene Understanding in Five Seconds
Mar 25, 2026Open-vocabulary 3D scene understanding enables users to segment novel objects in complex 3D environments through natural language. However, existing approaches remain slow, memory-intensive, and overly complex due to iterative optimization and dense per-Gaussian feature assignments. To address this, we propose LightSplat, a fast and memory-efficient training-free framework that injects compact 2-byte semantic indices into 3D representations from multi-view images. By assigning semantic indices only to salient regions and managing them with a lightweight index-feature mapping, LightSplat eliminates costly feature optimization and storage overhead. We further ensure semantic consistency and efficient inference via single-step clustering that links geometrically and semantically related masks in 3D. We evaluate our method on LERF-OVS, ScanNet, and DL3DV-OVS across complex indoor-outdoor scenes. As a result, LightSplat achieves state-of-the-art performance with up to 50-400x speedup and 64x lower memory, enabling scalable language-driven 3D understanding. For more details, visit our project page https://vision3d-lab.github.io/lightsplat/.
REFINE-DP: Diffusion Policy Fine-tuning for Humanoid Loco-manipulation via Reinforcement Learning
Mar 14, 2026Humanoid loco-manipulation requires coordinated high-level motion plans with stable, low-level whole-body execution under complex robot-environment dynamics and long-horizon tasks. While diffusion policies (DPs) show promise for learning from demonstrations, deploying them on humanoids poses critical challenges: the motion planner trained offline is decoupled from the low-level controller, leading to poor command tracking, compounding distribution shift, and task failures. The common approach of scaling demonstration data is prohibitively expensive for high-dimensional humanoid systems. To address this challenge, we present REFINE-DP (REinforcement learning FINE-tuning of Diffusion Policy), a hierarchical framework that jointly optimizes a DP high-level planner and an RL-based low-level loco-manipulation controller. The DP is fine-tuned via a PPO-based diffusion policy gradient to improve task success rate, while the controller is simultaneously updated to accurately track the planner's evolving command distribution, reducing the distributional mismatch that degrades motion quality. We validate REFINE-DP on a humanoid robot performing loco-manipulation tasks, including door traversal and long-horizon object transport. REFINE-DP achieves an over $90\%$ success rate in simulation, even in out-of-distribution cases not seen in the pre-trained data, and enables smooth autonomous task execution in real-world dynamic environments. Our proposed method substantially outperforms pre-trained DP baselines and demonstrates that RL fine-tuning is key to reliable humanoid loco-manipulation. https://refine-dp.github.io/REFINE-DP/
ReVision: A Dataset and Baseline VLM for Privacy-Preserving Task-Oriented Visual Instruction Rewriting
Feb 20, 2025



Efficient and privacy-preserving multimodal interaction is essential as AR, VR, and modern smartphones with powerful cameras become primary interfaces for human-computer communication. Existing powerful large vision-language models (VLMs) enabling multimodal interaction often rely on cloud-based processing, raising significant concerns about (1) visual privacy by transmitting sensitive vision data to servers, and (2) their limited real-time, on-device usability. This paper explores Visual Instruction Rewriting, a novel approach that transforms multimodal instructions into text-only commands, allowing seamless integration of lightweight on-device instruction rewriter VLMs (250M parameters) with existing conversational AI systems, enhancing vision data privacy. To achieve this, we present a dataset of over 39,000 examples across 14 domains and develop a compact VLM, pretrained on image captioning datasets and fine-tuned for instruction rewriting. Experimental results, evaluated through NLG metrics such as BLEU, METEOR, and ROUGE, along with semantic parsing analysis, demonstrate that even a quantized version of the model (<500MB storage footprint) can achieve effective instruction rewriting, thus enabling privacy-focused, multimodal AI applications.
Rule-based autocorrection of Piping and Instrumentation Diagrams (P&IDs) on graphs
Feb 18, 2025A piping and instrumentation diagram (P&ID) is a central reference document in chemical process engineering. Currently, chemical engineers manually review P&IDs through visual inspection to find and rectify errors. However, engineering projects can involve hundreds to thousands of P&ID pages, creating a significant revision workload. This study proposes a rule-based method to support engineers with error detection and correction in P&IDs. The method is based on a graph representation of P&IDs, enabling automated error detection and correction, i.e., autocorrection, through rule graphs. We use our pyDEXPI Python package to generate P&ID graphs from DEXPI-standard P&IDs. In this study, we developed 33 rules based on chemical engineering knowledge and heuristics, with five selected rules demonstrated as examples. A case study on an illustrative P&ID validates the reliability and effectiveness of the rule-based autocorrection method in revising P&IDs.
Physics-informed reduced order model with conditional neural fields
Dec 06, 2024

This study presents the conditional neural fields for reduced-order modeling (CNF-ROM) framework to approximate solutions of parametrized partial differential equations (PDEs). The approach combines a parametric neural ODE (PNODE) for modeling latent dynamics over time with a decoder that reconstructs PDE solutions from the corresponding latent states. We introduce a physics-informed learning objective for CNF-ROM, which includes two key components. First, the framework uses coordinate-based neural networks to calculate and minimize PDE residuals by computing spatial derivatives via automatic differentiation and applying the chain rule for time derivatives. Second, exact initial and boundary conditions (IC/BC) are imposed using approximate distance functions (ADFs) [Sukumar and Srivastava, CMAME, 2022]. However, ADFs introduce a trade-off as their second- or higher-order derivatives become unstable at the joining points of boundaries. To address this, we introduce an auxiliary network inspired by [Gladstone et al., NeurIPS ML4PS workshop, 2022]. Our method is validated through parameter extrapolation and interpolation, temporal extrapolation, and comparisons with analytical solutions.
Leveraging Temporal Contextualization for Video Action Recognition
Apr 15, 2024



Pretrained vision-language models have shown effectiveness in video understanding. However, recent studies have not sufficiently leveraged essential temporal information from videos, simply averaging frame-wise representations or referencing consecutive frames. We introduce Temporally Contextualized CLIP (TC-CLIP), a pioneering framework for video understanding that effectively and efficiently leverages comprehensive video information. We propose Temporal Contextualization (TC), a novel layer-wise temporal information infusion mechanism for video that extracts core information from each frame, interconnects relevant information across the video to summarize into context tokens, and ultimately leverages the context tokens during the feature encoding process. Furthermore, our Video-conditional Prompting (VP) module manufactures context tokens to generate informative prompts in text modality. We conduct extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition to validate the superiority of our TC-CLIP. Ablation studies for TC and VP guarantee our design choices. Code is available at https://github.com/naver-ai/tc-clip
Neural Collage Transfer: Artistic Reconstruction via Material Manipulation
Nov 03, 2023



Collage is a creative art form that uses diverse material scraps as a base unit to compose a single image. Although pixel-wise generation techniques can reproduce a target image in collage style, it is not a suitable method due to the solid stroke-by-stroke nature of the collage form. While some previous works for stroke-based rendering produced decent sketches and paintings, collages have received much less attention in research despite their popularity as a style. In this paper, we propose a method for learning to make collages via reinforcement learning without the need for demonstrations or collage artwork data. We design the collage Markov Decision Process (MDP), which allows the agent to handle various materials and propose a model-based soft actor-critic to mitigate the agent's training burden derived from the sophisticated dynamics of collage. Moreover, we devise additional techniques such as active material selection and complexity-based multi-scale collage to handle target images at any size and enhance the results' aesthetics by placing relatively more scraps in areas of high complexity. Experimental results show that the trained agent appropriately selected and pasted materials to regenerate the target image into a collage and obtained a higher evaluation score on content and style than pixel-wise generation methods. Code is available at https://github.com/northadventure/CollageRL.
Addressing Distribution Shift in RTB Markets via Exponential Tilting
Aug 14, 2023


Distribution shift in machine learning models can be a primary cause of performance degradation. This paper delves into the characteristics of these shifts, primarily motivated by Real-Time Bidding (RTB) market models. We emphasize the challenges posed by class imbalance and sample selection bias, both potent instigators of distribution shifts. This paper introduces the Exponential Tilt Reweighting Alignment (ExTRA) algorithm, as proposed by Marty et al. (2023), to address distribution shifts in data. The ExTRA method is designed to determine the importance weights on the source data, aiming to minimize the KL divergence between the weighted source and target datasets. A notable advantage of this method is its ability to operate using labeled source data and unlabeled target data. Through simulated real-world data, we investigate the nature of distribution shift and evaluate the applicacy of the proposed model.
EXOT: Exit-aware Object Tracker for Safe Robotic Manipulation of Moving Object
Jun 08, 2023Current robotic hand manipulation narrowly operates with objects in predictable positions in limited environments. Thus, when the location of the target object deviates severely from the expected location, a robot sometimes responds in an unexpected way, especially when it operates with a human. For safe robot operation, we propose the EXit-aware Object Tracker (EXOT) on a robot hand camera that recognizes an object's absence during manipulation. The robot decides whether to proceed by examining the tracker's bounding box output containing the target object. We adopt an out-of-distribution classifier for more accurate object recognition since trackers can mistrack a background as a target object. To the best of our knowledge, our method is the first approach of applying an out-of-distribution classification technique to a tracker output. We evaluate our method on the first-person video benchmark dataset, TREK-150, and on the custom dataset, RMOT-223, that we collect from the UR5e robot. Then we test our tracker on the UR5e robot in real-time with a conveyor-belt sushi task, to examine the tracker's ability to track target dishes and to determine the exit status. Our tracker shows 38% higher exit-aware performance than a baseline method. The dataset and the code will be released at https://github.com/hskAlena/EXOT.
Towards Sequence-Level Training for Visual Tracking
Aug 11, 2022
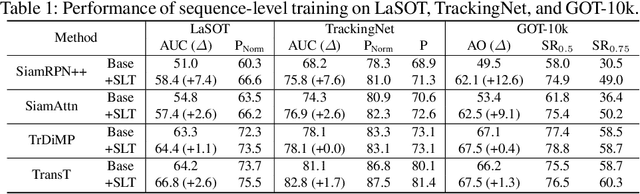
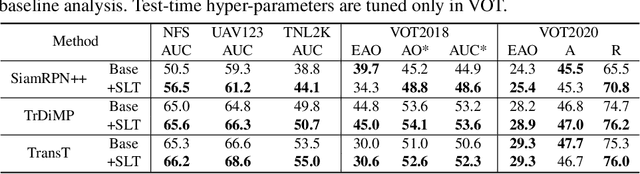

Despite the extensive adoption of machine learning on the task of visual object tracking, recent learning-based approaches have largely overlooked the fact that visual tracking is a sequence-level task in its nature; they rely heavily on frame-level training, which inevitably induces inconsistency between training and testing in terms of both data distributions and task objectives. This work introduces a sequence-level training strategy for visual tracking based on reinforcement learning and discusses how a sequence-level design of data sampling, learning objectives, and data augmentation can improve the accuracy and robustness of tracking algorithms. Our experiments on standard benchmarks including LaSOT, TrackingNet, and GOT-10k demonstrate that four representative tracking models, SiamRPN++, SiamAttn, TransT, and TrDiMP, consistently improve by incorporating the proposed methods in training without modifying architectures.