 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrain Where? Investigating How Pretraining Data Diversity Impacts Geospatial Foundation Model Performance
Apr 22, 2026New geospatial foundation models introduce a new model architecture and pretraining dataset, often sampled using different notions of data diversity. Performance differences are largely attributed to the model architecture or input modalities, while the role of the pretraining dataset is rarely studied. To address this research gap, we conducted a systematic study on how the geographic composition of pretraining data affects a model's downstream performance. We created global and per-continent pretraining datasets and evaluated them on global and per-continent downstream datasets. We found that the pretraining dataset from Europe outperformed global and continent-specific pretraining datasets on both global and local downstream evaluations. To investigate the factors influencing a pretraining dataset's downstream performance, we analysed 10 pretraining datasets using diversity across continents, biomes, landcover and spectral values. We found that only spectral diversity was strongly correlated with performance, while others were weakly correlated. This finding establishes a new dimension of diversity to be accounted for when creating a high-performing pretraining dataset. We open-sourced 7 new pretraining datasets, pretrained models, and our experimental framework at https://github.com/kerner-lab/pretrain-where.
MOMO: Mars Orbital Model Foundation Model for Mars Orbital Applications
Apr 03, 2026We introduce MOMO, the first multi-sensor foundation model for Mars remote sensing. MOMO uses model merge to integrate representations learned independently from three key Martian sensors (HiRISE, CTX, and THEMIS), spanning resolutions from 0.25 m/pixel to 100 m/pixel. Central to our method is our novel Equal Validation Loss (EVL) strategy, which aligns checkpoints across sensors based on validation loss similarity before fusion via task arithmetic. This ensures models are merged at compatible convergence stages, leading to improved stability and generalization. We train MOMO on a large-scale, high-quality corpus of $\sim 12$ million samples curated from Mars orbital data and evaluate it on 9 downstream tasks from Mars-Bench. MOMO achieves better overall performance compared to ImageNet pre-trained, earth observation foundation model, sensor-specific pre-training, and fully-supervised baselines. Particularly on segmentation tasks, MOMO shows consistent and significant performance improvement. Our results demonstrate that model merging through an optimal checkpoint selection strategy provides an effective approach for building foundation models for multi-resolution data. The model weights, pretraining code, pretraining data, and evaluation code are available at: https://github.com/kerner-lab/MOMO.
ConeQuest: A Benchmark for Cone Segmentation on Mars
Nov 15, 2023
Over the years, space scientists have collected terabytes of Mars data from satellites and rovers. One important set of features identified in Mars orbital images is pitted cones, which are interpreted to be mud volcanoes believed to form in regions that were once saturated in water (i.e., a lake or ocean). Identifying pitted cones globally on Mars would be of great importance, but expert geologists are unable to sort through the massive orbital image archives to identify all examples. However, this task is well suited for computer vision. Although several computer vision datasets exist for various Mars-related tasks, there is currently no open-source dataset available for cone detection/segmentation. Furthermore, previous studies trained models using data from a single region, which limits their applicability for global detection and mapping. Motivated by this, we introduce ConeQuest, the first expert-annotated public dataset to identify cones on Mars. ConeQuest consists of >13k samples from 3 different regions of Mars. We propose two benchmark tasks using ConeQuest: (i) Spatial Generalization and (ii) Cone-size Generalization. We finetune and evaluate widely-used segmentation models on both benchmark tasks. Results indicate that cone segmentation is a challenging open problem not solved by existing segmentation models, which achieve an average IoU of 52.52% and 42.55% on in-distribution data for tasks (i) and (ii), respectively. We believe this new benchmark dataset will facilitate the development of more accurate and robust models for cone segmentation. Data and code are available at https://github.com/kerner-lab/ConeQuest.
Lightweight, Pre-trained Transformers for Remote Sensing Timeseries
Apr 27, 2023



Machine learning algorithms for parsing remote sensing data have a wide range of societally relevant applications, but labels used to train these algorithms can be difficult or impossible to acquire. This challenge has spurred research into self-supervised learning for remote sensing data aiming to unlock the use of machine learning in geographies or application domains where labelled datasets are small. Current self-supervised learning approaches for remote sensing data draw significant inspiration from techniques applied to natural images. However, remote sensing data has important differences from natural images -- for example, the temporal dimension is critical for many tasks and data is collected from many complementary sensors. We show that designing models and self-supervised training techniques specifically for remote sensing data results in both smaller and more performant models. We introduce the Pretrained Remote Sensing Transformer (Presto), a transformer-based model pre-trained on remote sensing pixel-timeseries data. Presto excels at a wide variety of globally distributed remote sensing tasks and outperforms much larger models. Presto can be used for transfer learning or as a feature extractor for simple models, enabling efficient deployment at scale.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

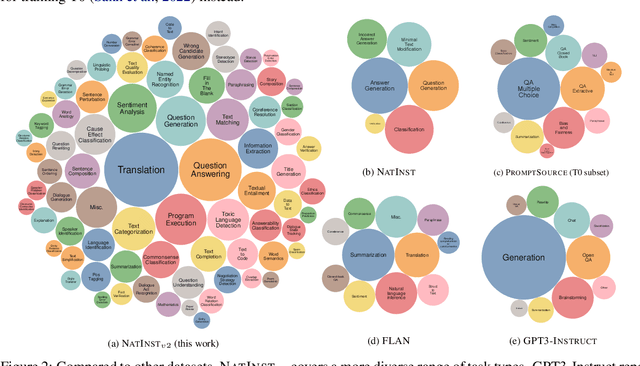
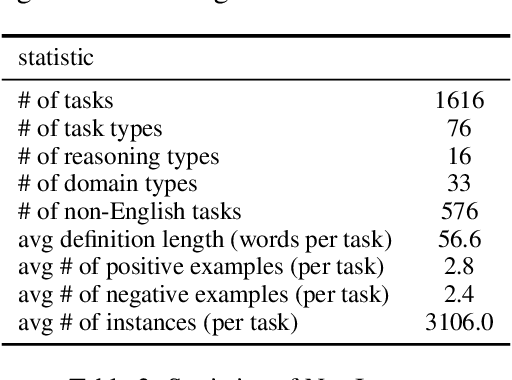
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
In-BoXBART: Get Instructions into Biomedical Multi-Task Learning
Apr 15, 2022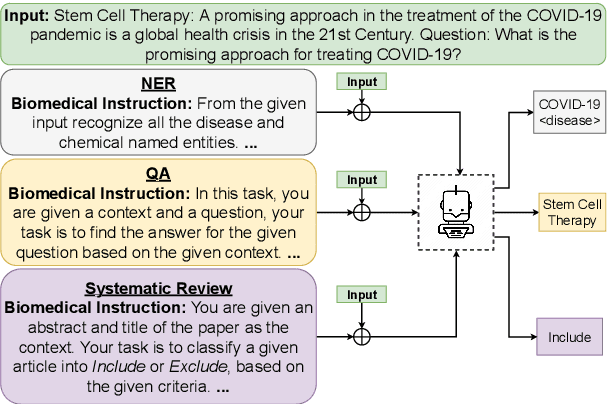
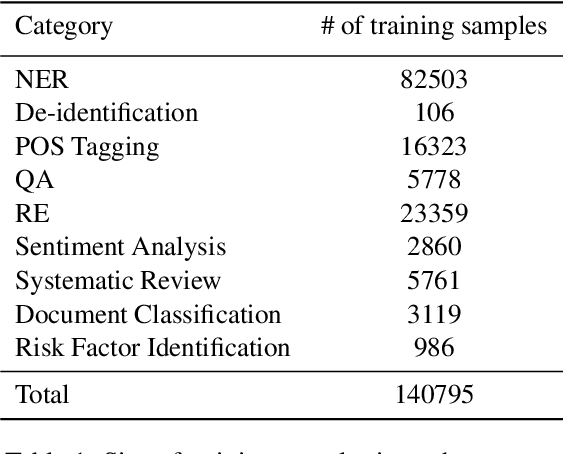
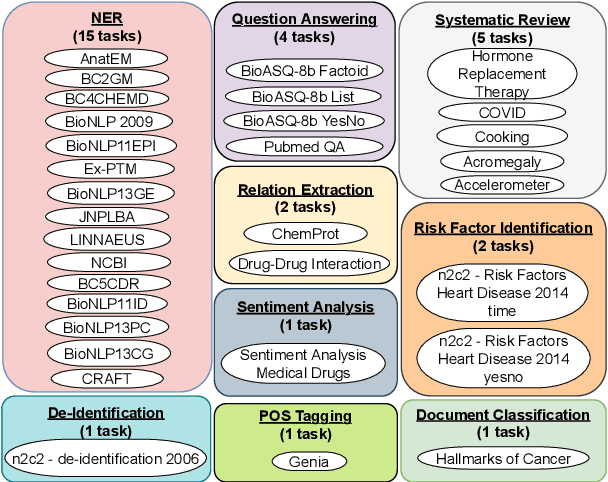
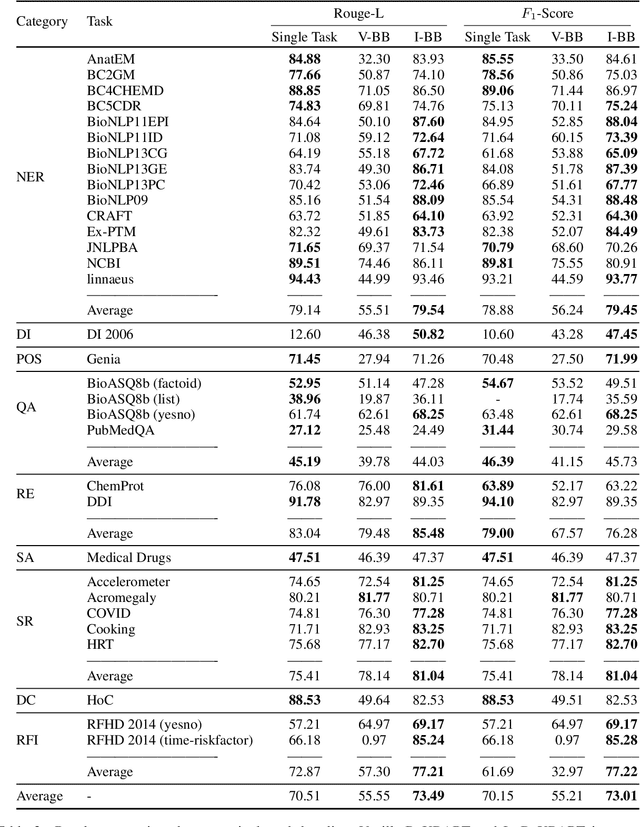
Single-task models have proven pivotal in solving specific tasks; however, they have limitations in real-world applications where multi-tasking is necessary and domain shifts are exhibited. Recently, instructional prompts have shown significant improvement towards multi-task generalization; however, the effect of instructional prompts and Multi-Task Learning (MTL) has not been systematically studied in the biomedical domain. Motivated by this, this paper explores the impact of instructional prompts for biomedical MTL. We introduce the BoX, a collection of 32 instruction tasks for Biomedical NLP across (X) various categories. Using this meta-dataset, we propose a unified model termed In-BoXBART, that can jointly learn all tasks of the BoX without any task-specific modules. To the best of our knowledge, this is the first attempt to propose a unified model in the biomedical domain and use instructions to achieve generalization across several biomedical tasks. Experimental results indicate that the proposed model: 1) outperforms the single-task baseline by ~3% and multi-task (without instruction) baseline by ~18% on an average, and 2) shows ~23% improvement compared to the single-task baseline in few-shot learning (i.e., 32 instances per task) on an average. Our analysis indicates that there is significant room for improvement across tasks in the BoX, implying the scope for future research direction.
CinC-GAN for Effective F0 prediction for Whisper-to-Normal Speech Conversion
Aug 18, 2020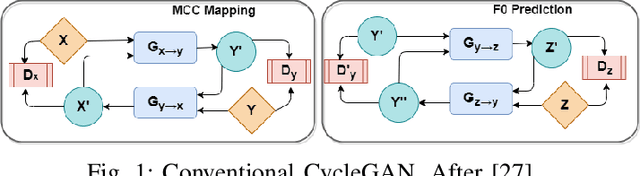
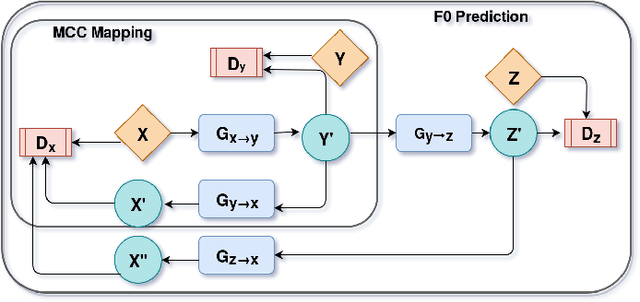
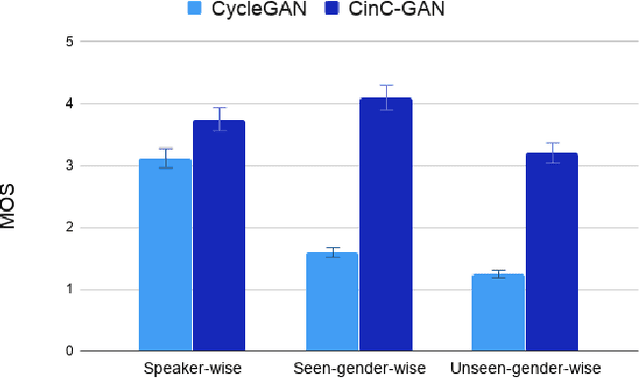
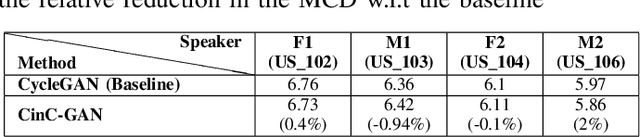
Recently, Generative Adversarial Networks (GAN)-based methods have shown remarkable performance for the Voice Conversion and WHiSPer-to-normal SPeeCH (WHSP2SPCH) conversion. One of the key challenges in WHSP2SPCH conversion is the prediction of fundamental frequency (F0). Recently, authors have proposed state-of-the-art method Cycle-Consistent Generative Adversarial Networks (CycleGAN) for WHSP2SPCH conversion. The CycleGAN-based method uses two different models, one for Mel Cepstral Coefficients (MCC) mapping, and another for F0 prediction, where F0 is highly dependent on the pre-trained model of MCC mapping. This leads to additional non-linear noise in predicted F0. To suppress this noise, we propose Cycle-in-Cycle GAN (i.e., CinC-GAN). It is specially designed to increase the effectiveness in F0 prediction without losing the accuracy of MCC mapping. We evaluated the proposed method on a non-parallel setting and analyzed on speaker-specific, and gender-specific tasks. The objective and subjective tests show that CinC-GAN significantly outperforms the CycleGAN. In addition, we analyze the CycleGAN and CinC-GAN for unseen speakers and the results show the clear superiority of CinC-GAN.