 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffusionMat: Alpha Matting as Sequential Refinement Learning
Nov 22, 2023
In this paper, we introduce DiffusionMat, a novel image matting framework that employs a diffusion model for the transition from coarse to refined alpha mattes. Diverging from conventional methods that utilize trimaps merely as loose guidance for alpha matte prediction, our approach treats image matting as a sequential refinement learning process. This process begins with the addition of noise to trimaps and iteratively denoises them using a pre-trained diffusion model, which incrementally guides the prediction towards a clean alpha matte. The key innovation of our framework is a correction module that adjusts the output at each denoising step, ensuring that the final result is consistent with the input image's structures. We also introduce the Alpha Reliability Propagation, a novel technique designed to maximize the utility of available guidance by selectively enhancing the trimap regions with confident alpha information, thus simplifying the correction task. To train the correction module, we devise specialized loss functions that target the accuracy of the alpha matte's edges and the consistency of its opaque and transparent regions. We evaluate our model across several image matting benchmarks, and the results indicate that DiffusionMat consistently outperforms existing methods. Project page at~\url{https://cnnlstm.github.io/DiffusionMat
Align before Adapt: Leveraging Entity-to-Region Alignments for Generalizable Video Action Recognition
Nov 27, 2023Large-scale visual-language pre-trained models have achieved significant success in various video tasks. However, most existing methods follow an "adapt then align" paradigm, which adapts pre-trained image encoders to model video-level representations and utilizes one-hot or text embedding of the action labels for supervision. This paradigm overlooks the challenge of mapping from static images to complicated activity concepts. In this paper, we propose a novel "Align before Adapt" (ALT) paradigm. Prior to adapting to video representation learning, we exploit the entity-to-region alignments for each frame. The alignments are fulfilled by matching the region-aware image embeddings to an offline-constructed text corpus. With the aligned entities, we feed their text embeddings to a transformer-based video adapter as the queries, which can help extract the semantics of the most important entities from a video to a vector. This paradigm reuses the visual-language alignment of VLP during adaptation and tries to explain an action by the underlying entities. This helps understand actions by bridging the gap with complex activity semantics, particularly when facing unfamiliar or unseen categories. ALT achieves competitive performance and superior generalizability while requiring significantly low computational costs. In fully supervised scenarios, it achieves 88.1% top-1 accuracy on Kinetics-400 with only 4947 GFLOPs. In 2-shot experiments, ALT outperforms the previous state-of-the-art by 7.1% and 9.2% on HMDB-51 and UCF-101, respectively.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
Nov 30, 2023Diffusion models have achieved significant success in image and video generation. This motivates a growing interest in video editing tasks, where videos are edited according to provided text descriptions. However, most existing approaches only focus on video editing for short clips and rely on time-consuming tuning or inference. We are the first to propose Video Instruction Diffusion (VIDiff), a unified foundation model designed for a wide range of video tasks. These tasks encompass both understanding tasks (such as language-guided video object segmentation) and generative tasks (video editing and enhancement). Our model can edit and translate the desired results within seconds based on user instructions. Moreover, we design an iterative auto-regressive method to ensure consistency in editing and enhancing long videos. We provide convincing generative results for diverse input videos and written instructions, both qualitatively and quantitatively. More examples can be found at our website https://ChenHsing.github.io/VIDiff.
On the Adversarial Robustness of Graph Contrastive Learning Methods
Nov 30, 2023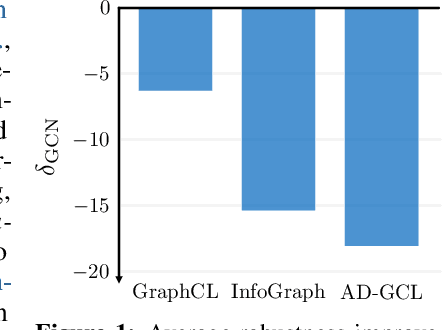
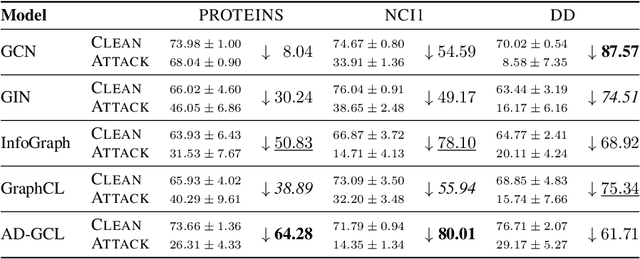
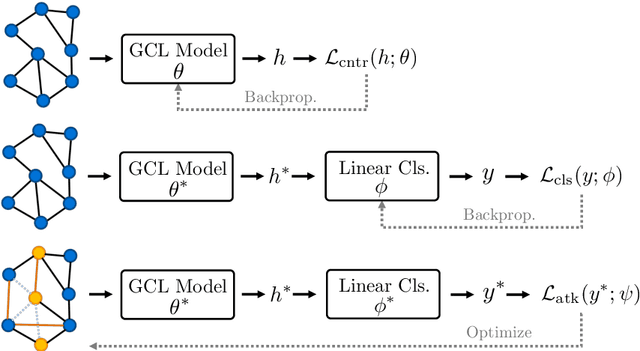
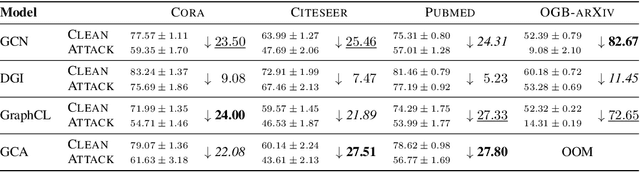
Contrastive learning (CL) has emerged as a powerful framework for learning representations of images and text in a self-supervised manner while enhancing model robustness against adversarial attacks. More recently, researchers have extended the principles of contrastive learning to graph-structured data, giving birth to the field of graph contrastive learning (GCL). However, whether GCL methods can deliver the same advantages in adversarial robustness as their counterparts in the image and text domains remains an open question. In this paper, we introduce a comprehensive robustness evaluation protocol tailored to assess the robustness of GCL models. We subject these models to adaptive adversarial attacks targeting the graph structure, specifically in the evasion scenario. We evaluate node and graph classification tasks using diverse real-world datasets and attack strategies. With our work, we aim to offer insights into the robustness of GCL methods and hope to open avenues for potential future research directions.
Enhancing Diffusion Models with 3D Perspective Geometry Constraints
Dec 01, 2023While perspective is a well-studied topic in art, it is generally taken for granted in images. However, for the recent wave of high-quality image synthesis methods such as latent diffusion models, perspective accuracy is not an explicit requirement. Since these methods are capable of outputting a wide gamut of possible images, it is difficult for these synthesized images to adhere to the principles of linear perspective. We introduce a novel geometric constraint in the training process of generative models to enforce perspective accuracy. We show that outputs of models trained with this constraint both appear more realistic and improve performance of downstream models trained on generated images. Subjective human trials show that images generated with latent diffusion models trained with our constraint are preferred over images from the Stable Diffusion V2 model 70% of the time. SOTA monocular depth estimation models such as DPT and PixelFormer, fine-tuned on our images, outperform the original models trained on real images by up to 7.03% in RMSE and 19.3% in SqRel on the KITTI test set for zero-shot transfer.
Student Activity Recognition in Classroom Environments using Transfer Learning
Dec 01, 2023The recent advances in artificial intelligence and deep learning facilitate automation in various applications including home automation, smart surveillance systems, and healthcare among others. Human Activity Recognition is one of its emerging applications, which can be implemented in a classroom environment to enhance safety, efficiency, and overall educational quality. This paper proposes a system for detecting and recognizing the activities of students in a classroom environment. The dataset has been structured and recorded by the authors since a standard dataset for this task was not available at the time of this study. Transfer learning, a widely adopted method within the field of deep learning, has proven to be helpful in complex tasks like image and video processing. Pretrained models including VGG-16, ResNet-50, InceptionV3, and Xception are used for feature extraction and classification tasks. Xception achieved an accuracy of 93%, on the novel classroom dataset, outperforming the other three models in consideration. The system proposed in this study aims to introduce a safer and more productive learning environment for students and educators.
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 01, 2023The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. can watermark Llama2-7B-chat with no perceivable loss in quality in under 100 tokens, and with good tamper-resistance to simple attacks, regardless of temperature. We argue that watermark indistinguishability is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark.
Leveraging healthy population variability in deep learning unsupervised anomaly detection in brain FDG PET
Nov 20, 2023Unsupervised anomaly detection is a popular approach for the analysis of neuroimaging data as it allows to identify a wide variety of anomalies from unlabelled data. It relies on building a subject-specific model of healthy appearance to which a subject's image can be compared to detect anomalies. In the literature, it is common for anomaly detection to rely on analysing the residual image between the subject's image and its pseudo-healthy reconstruction. This approach however has limitations partly due to the pseudo-healthy reconstructions being imperfect and to the lack of natural thresholding mechanism. Our proposed method, inspired by Z-scores, leverages the healthy population variability to overcome these limitations. Our experiments conducted on FDG PET scans from the ADNI database demonstrate the effectiveness of our approach in accurately identifying Alzheimer's disease related anomalies.
Syn3DWound: A Synthetic Dataset for 3D Wound Bed Analysis
Nov 27, 2023Wound management poses a significant challenge, particularly for bedridden patients and the elderly. Accurate diagnostic and healing monitoring can significantly benefit from modern image analysis, providing accurate and precise measurements of wounds. Despite several existing techniques, the shortage of expansive and diverse training datasets remains a significant obstacle to constructing machine learning-based frameworks. This paper introduces Syn3DWound, an open-source dataset of high-fidelity simulated wounds with 2D and 3D annotations. We propose baseline methods and a benchmarking framework for automated 3D morphometry analysis and 2D/3D wound segmentation.