 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text and Click inputs for unambiguous open vocabulary instance segmentation
Nov 24, 2023
Segmentation localizes objects in an image on a fine-grained per-pixel scale. Segmentation benefits by humans-in-the-loop to provide additional input of objects to segment using a combination of foreground or background clicks. Tasks include photoediting or novel dataset annotation, where human annotators leverage an existing segmentation model instead of drawing raw pixel level annotations. We propose a new segmentation process, Text + Click segmentation, where a model takes as input an image, a text phrase describing a class to segment, and a single foreground click specifying the instance to segment. Compared to previous approaches, we leverage open-vocabulary image-text models to support a wide-range of text prompts. Conditioning segmentations on text prompts improves the accuracy of segmentations on novel or unseen classes. We demonstrate that the combination of a single user-specified foreground click and a text prompt allows a model to better disambiguate overlapping or co-occurring semantic categories, such as "tie", "suit", and "person". We study these results across common segmentation datasets such as refCOCO, COCO, VOC, and OpenImages. Source code available here.
Calibrated Uncertainties for Neural Radiance Fields
Dec 04, 2023Neural Radiance Fields have achieved remarkable results for novel view synthesis but still lack a crucial component: precise measurement of uncertainty in their predictions. Probabilistic NeRF methods have tried to address this, but their output probabilities are not typically accurately calibrated, and therefore do not capture the true confidence levels of the model. Calibration is a particularly challenging problem in the sparse-view setting, where additional held-out data is unavailable for fitting a calibrator that generalizes to the test distribution. In this paper, we introduce the first method for obtaining calibrated uncertainties from NeRF models. Our method is based on a robust and efficient metric to calculate per-pixel uncertainties from the predictive posterior distribution. We propose two techniques that eliminate the need for held-out data. The first, based on patch sampling, involves training two NeRF models for each scene. The second is a novel meta-calibrator that only requires the training of one NeRF model. Our proposed approach for obtaining calibrated uncertainties achieves state-of-the-art uncertainty in the sparse-view setting while maintaining image quality. We further demonstrate our method's effectiveness in applications such as view enhancement and next-best view selection.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.
Fully Spiking Denoising Diffusion Implicit Models
Dec 04, 2023Spiking neural networks (SNNs) have garnered considerable attention owing to their ability to run on neuromorphic devices with super-high speeds and remarkable energy efficiencies. SNNs can be used in conventional neural network-based time- and energy-consuming applications. However, research on generative models within SNNs remains limited, despite their advantages. In particular, diffusion models are a powerful class of generative models, whose image generation quality surpass that of the other generative models, such as GANs. However, diffusion models are characterized by high computational costs and long inference times owing to their iterative denoising feature. Therefore, we propose a novel approach fully spiking denoising diffusion implicit model (FSDDIM) to construct a diffusion model within SNNs and leverage the high speed and low energy consumption features of SNNs via synaptic current learning (SCL). SCL fills the gap in that diffusion models use a neural network to estimate real-valued parameters of a predefined probabilistic distribution, whereas SNNs output binary spike trains. The SCL enables us to complete the entire generative process of diffusion models exclusively using SNNs. We demonstrate that the proposed method outperforms the state-of-the-art fully spiking generative model.
TextAug: Test time Text Augmentation for Multimodal Person Re-identification
Dec 04, 2023

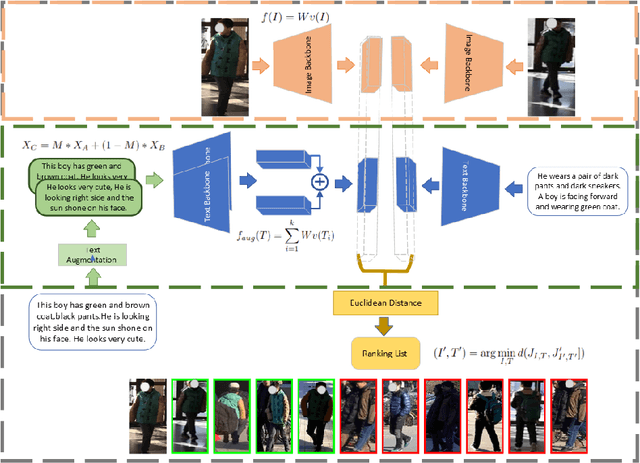
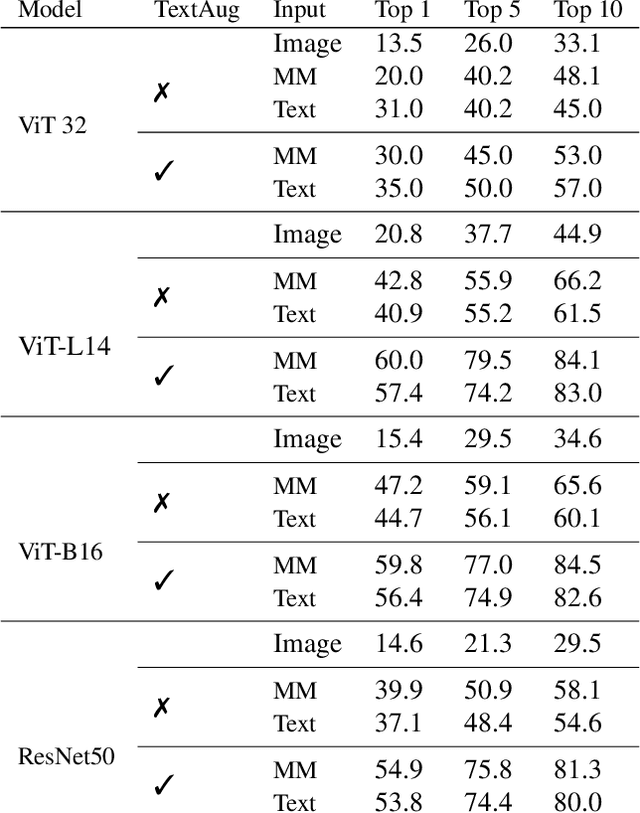
Multimodal Person Reidentification is gaining popularity in the research community due to its effectiveness compared to counter-part unimodal frameworks. However, the bottleneck for multimodal deep learning is the need for a large volume of multimodal training examples. Data augmentation techniques such as cropping, flipping, rotation, etc. are often employed in the image domain to improve the generalization of deep learning models. Augmenting in other modalities than images, such as text, is challenging and requires significant computational resources and external data sources. In this study, we investigate the effectiveness of two computer vision data augmentation techniques: cutout and cutmix, for text augmentation in multi-modal person re-identification. Our approach merges these two augmentation strategies into one strategy called CutMixOut which involves randomly removing words or sub-phrases from a sentence (Cutout) and blending parts of two or more sentences to create diverse examples (CutMix) with a certain probability assigned to each operation. This augmentation was implemented at inference time without any prior training. Our results demonstrate that the proposed technique is simple and effective in improving the performance on multiple multimodal person re-identification benchmarks.
Coronary Atherosclerotic Plaque Characterization with Photon-counting CT: a Simulation-based Feasibility Study
Dec 04, 2023Recent development of photon-counting CT (PCCT) brings great opportunities for plaque characterization with much-improved spatial resolution and spectral imaging capability. While existing coronary plaque PCCT imaging results are based on detectors made of CZT or CdTe materials, deep-silicon photon-counting detectors have unique performance characteristics and promise distinct imaging capabilities. In this work, we report a systematic simulation study of a deep-silicon PCCT scanner with a new clinically-relevant digital plaque phantom with realistic geometrical parameters and chemical compositions. This work investigates the effects of spatial resolution, noise, motion artifacts, radiation dose, and spectral characterization. Our simulation results suggest that the deep-silicon PCCT design provides adequate spatial resolution for visualizing a necrotic core and quantitation of key plaque features. Advanced denoising techniques and aggressive bowtie filter designs can keep image noise to acceptable levels at this resolution while keeping radiation dose comparable to that of a conventional CT scan. The ultrahigh resolution of PCCT also means an elevated sensitivity to motion artifacts. It is found that a tolerance of less than 0.4 mm residual movement range requires the application of accurate motion correction methods for best plaque imaging quality with PCCT.
Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning
Dec 05, 2023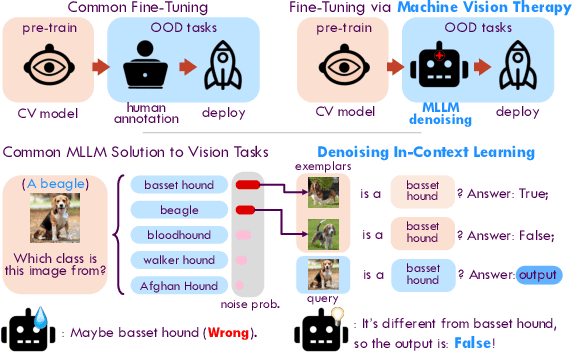
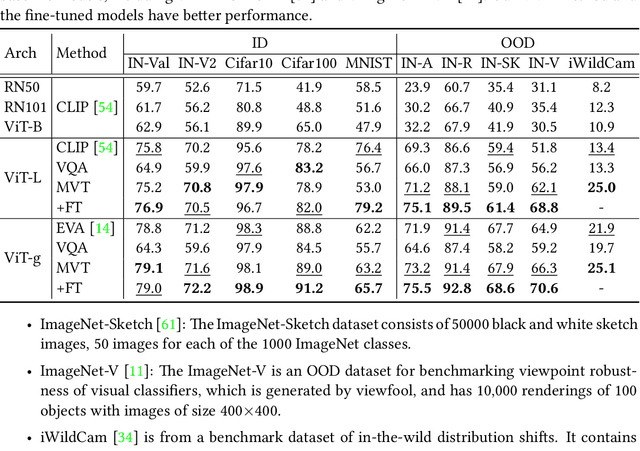
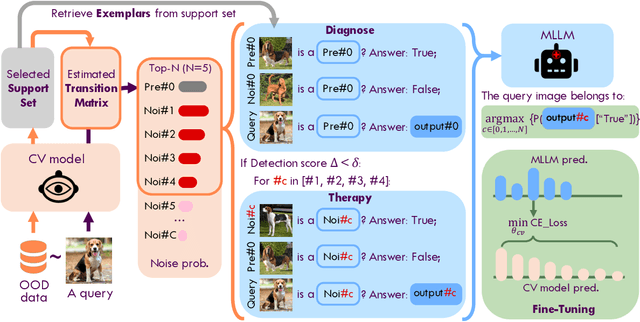
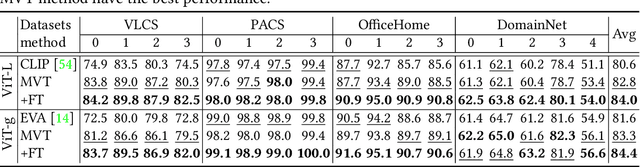
Although vision models such as Contrastive Language-Image Pre-Training (CLIP) show impressive generalization performance, their zero-shot robustness is still limited under Out-of-Distribution (OOD) scenarios without fine-tuning. Instead of undesirably providing human supervision as commonly done, it is possible to take advantage of Multi-modal Large Language Models (MLLMs) that hold powerful visual understanding abilities. However, MLLMs are shown to struggle with vision problems due to the incompatibility of tasks, thus hindering their utilization. In this paper, we propose to effectively leverage MLLMs to conduct Machine Vision Therapy which aims to rectify the noisy predictions from vision models. By fine-tuning with the denoised labels, the learning model performance can be boosted in an unsupervised manner. To solve the incompatibility issue, we propose a novel Denoising In-Context Learning (DICL) strategy to align vision tasks with MLLMs. Concretely, by estimating a transition matrix that captures the probability of one class being confused with another, an instruction containing a correct exemplar and an erroneous one from the most probable noisy class can be constructed. Such an instruction can help any MLLMs with ICL ability to detect and rectify incorrect predictions of vision models. Through extensive experiments on ImageNet, WILDS, DomainBed, and other OOD datasets, we carefully validate the quantitative and qualitative effectiveness of our method. Our code is available at https://github.com/tmllab/Machine_Vision_Therapy.
Learning to Generate Parameters of ConvNets for Unseen Image Data
Oct 24, 2023Typical Convolutional Neural Networks (ConvNets) depend heavily on large amounts of image data and resort to an iterative optimization algorithm (e.g., SGD or Adam) to learn network parameters, which makes training very time- and resource-intensive. In this paper, we propose a new training paradigm and formulate the parameter learning of ConvNets into a prediction task: given a ConvNet architecture, we observe there exists correlations between image datasets and their corresponding optimal network parameters, and explore if we can learn a hyper-mapping between them to capture the relations, such that we can directly predict the parameters of the network for an image dataset never seen during the training phase. To do this, we put forward a new hypernetwork based model, called PudNet, which intends to learn a mapping between datasets and their corresponding network parameters, and then predicts parameters for unseen data with only a single forward propagation. Moreover, our model benefits from a series of adaptive hyper recurrent units sharing weights to capture the dependencies of parameters among different network layers. Extensive experiments demonstrate that our proposed method achieves good efficacy for unseen image datasets on two kinds of settings: Intra-dataset prediction and Inter-dataset prediction. Our PudNet can also well scale up to large-scale datasets, e.g., ImageNet-1K. It takes 8967 GPU seconds to train ResNet-18 on the ImageNet-1K using GC from scratch and obtain a top-5 accuracy of 44.65 %. However, our PudNet costs only 3.89 GPU seconds to predict the network parameters of ResNet-18 achieving comparable performance (44.92 %), more than 2,300 times faster than the traditional training paradigm.
GeoChat: Grounded Large Vision-Language Model for Remote Sensing
Nov 24, 2023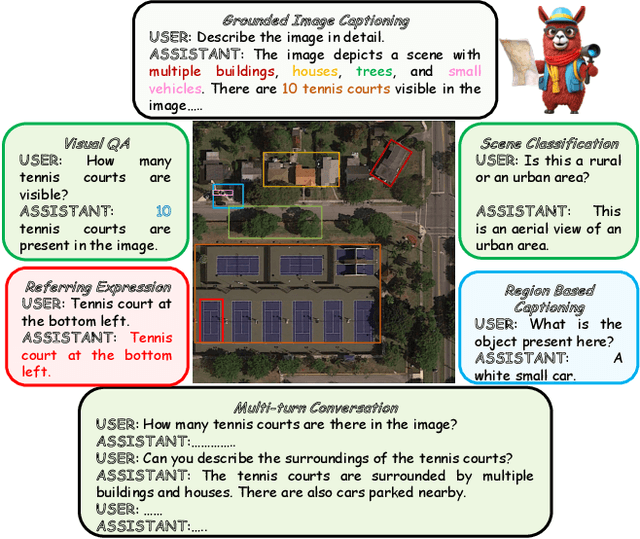
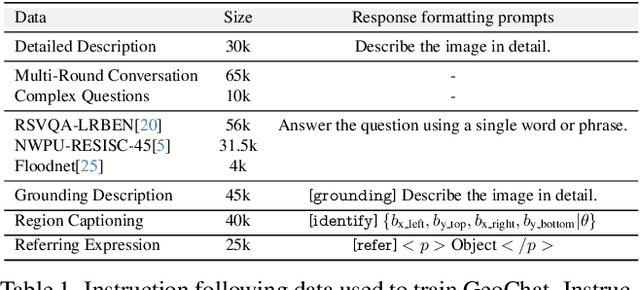
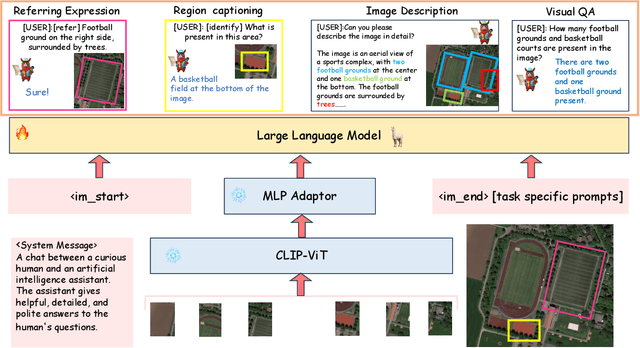
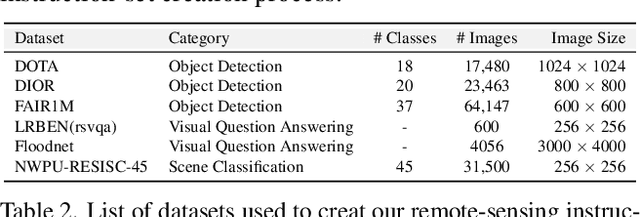
Recent advancements in Large Vision-Language Models (VLMs) have shown great promise in natural image domains, allowing users to hold a dialogue about given visual content. However, such general-domain VLMs perform poorly for Remote Sensing (RS) scenarios, leading to inaccurate or fabricated information when presented with RS domain-specific queries. Such a behavior emerges due to the unique challenges introduced by RS imagery. For example, to handle high-resolution RS imagery with diverse scale changes across categories and many small objects, region-level reasoning is necessary alongside holistic scene interpretation. Furthermore, the lack of domain-specific multimodal instruction following data as well as strong backbone models for RS make it hard for the models to align their behavior with user queries. To address these limitations, we propose GeoChat - the first versatile remote sensing VLM that offers multitask conversational capabilities with high-resolution RS images. Specifically, GeoChat can not only answer image-level queries but also accepts region inputs to hold region-specific dialogue. Furthermore, it can visually ground objects in its responses by referring to their spatial coordinates. To address the lack of domain-specific datasets, we generate a novel RS multimodal instruction-following dataset by extending image-text pairs from existing diverse RS datasets. We establish a comprehensive benchmark for RS multitask conversations and compare with a number of baseline methods. GeoChat demonstrates robust zero-shot performance on various RS tasks, e.g., image and region captioning, visual question answering, scene classification, visually grounded conversations and referring detection. Our code is available at https://github.com/mbzuai-oryx/geochat.
FuseNet: Self-Supervised Dual-Path Network for Medical Image Segmentation
Nov 22, 2023Semantic segmentation, a crucial task in computer vision, often relies on labor-intensive and costly annotated datasets for training. In response to this challenge, we introduce FuseNet, a dual-stream framework for self-supervised semantic segmentation that eliminates the need for manual annotation. FuseNet leverages the shared semantic dependencies between the original and augmented images to create a clustering space, effectively assigning pixels to semantically related clusters, and ultimately generating the segmentation map. Additionally, FuseNet incorporates a cross-modal fusion technique that extends the principles of CLIP by replacing textual data with augmented images. This approach enables the model to learn complex visual representations, enhancing robustness against variations similar to CLIP's text invariance. To further improve edge alignment and spatial consistency between neighboring pixels, we introduce an edge refinement loss. This loss function considers edge information to enhance spatial coherence, facilitating the grouping of nearby pixels with similar visual features. Extensive experiments on skin lesion and lung segmentation datasets demonstrate the effectiveness of our method. \href{https://github.com/xmindflow/FuseNet}{Codebase.}