 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjects Before Words: Object-First Inductive Biases for Grounding Language in Child-View Video
Jun 11, 2026Learning grounded word meaning from natural experience requires resolving two ambiguities in infant-view recordings: when the named referent appears and where it is in a cluttered frame. In SAYCam-style data, caregiver speech is sparse and weakly synchronized with egocentric video, so single-frame contrastive pairing yields noisy positives in which the intended object is absent or entangled with distractors. We propose BabyMind, an object-first bias for child-view contrastive learning under sparse, noisy supervision. BabyMind extracts candidate object embeddings using an offline mask-based region interface, links candidates across a short utterance-centered window into lightweight object files via tracking, and aligns utterances to bags of object files with a prototype-space multiple-instance contrastive objective. Track-coherence and global-object agreement regularizers stabilize learning and transfer object-file structure into the global frame embedding used at evaluation. On SAYCam-S, BabyMind improves Labeled-S 15 forced-choice accuracy by +2.6 points over CVCL and yields consistent gains on in-vocabulary out-of-distribution benchmarks. Code is available at https://github.com/sathiiii/BabyMind.
Pixels Don't Lie (But Your Detector Might): Bootstrapping MLLM-as-a-Judge for Trustworthy Deepfake Detection and Reasoning Supervision
Feb 23, 2026Deepfake detection models often generate natural-language explanations, yet their reasoning is frequently ungrounded in visual evidence, limiting reliability. Existing evaluations measure classification accuracy but overlook reasoning fidelity. We propose DeepfakeJudge, a framework for scalable reasoning supervision and evaluation, that integrates an out-of-distribution benchmark containing recent generative and editing forgeries, a human-annotated subset with visual reasoning labels, and a suite of evaluation models, that specialize in evaluating reasoning rationales without the need for explicit ground truth reasoning rationales. The Judge is optimized through a bootstrapped generator-evaluator process that scales human feedback into structured reasoning supervision and supports both pointwise and pairwise evaluation. On the proposed meta-evaluation benchmark, our reasoning-bootstrapped model achieves an accuracy of 96.2\%, outperforming \texttt{30x} larger baselines. The reasoning judge attains very high correlation with human ratings and 98.9\% percent pairwise agreement on the human-annotated meta-evaluation subset. These results establish reasoning fidelity as a quantifiable dimension of deepfake detection and demonstrate scalable supervision for interpretable deepfake reasoning. Our user study shows that participants preferred the reasonings generated by our framework 70\% of the time, in terms of faithfulness, groundedness, and usefulness, compared to those produced by other models and datasets. All of our datasets, models, and codebase are \href{https://github.com/KjAeRsTuIsK/DeepfakeJudge}{open-sourced}.
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025



The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
Tell me Habibi, is it Real or Fake?
May 28, 2025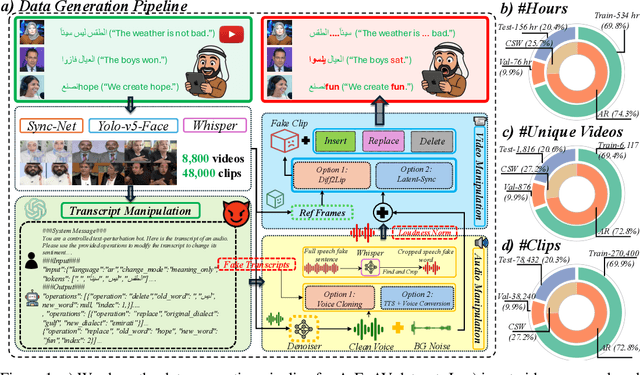
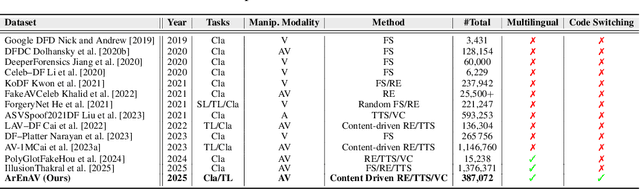
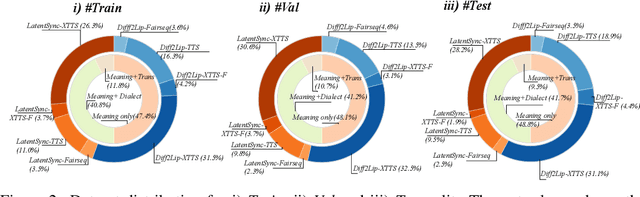

Deepfake generation methods are evolving fast, making fake media harder to detect and raising serious societal concerns. Most deepfake detection and dataset creation research focuses on monolingual content, often overlooking the challenges of multilingual and code-switched speech, where multiple languages are mixed within the same discourse. Code-switching, especially between Arabic and English, is common in the Arab world and is widely used in digital communication. This linguistic mixing poses extra challenges for deepfake detection, as it can confuse models trained mostly on monolingual data. To address this, we introduce \textbf{ArEnAV}, the first large-scale Arabic-English audio-visual deepfake dataset featuring intra-utterance code-switching, dialectal variation, and monolingual Arabic content. It \textbf{contains 387k videos and over 765 hours of real and fake videos}. Our dataset is generated using a novel pipeline integrating four Text-To-Speech and two lip-sync models, enabling comprehensive analysis of multilingual multimodal deepfake detection. We benchmark our dataset against existing monolingual and multilingual datasets, state-of-the-art deepfake detection models, and a human evaluation, highlighting its potential to advance deepfake research. The dataset can be accessed \href{https://huggingface.co/datasets/kartik060702/ArEnAV-Full}{here}.
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
Nov 28, 2024



While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they fall short in addressing the unique demands of geospatial applications. Generic VLM benchmarks are not designed to handle the complexities of geospatial data, which is critical for applications such as environmental monitoring, urban planning, and disaster management. Some of the unique challenges in geospatial domain include temporal analysis for changes, counting objects in large quantities, detecting tiny objects, and understanding relationships between entities occurring in Remote Sensing imagery. To address this gap in the geospatial domain, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, and temporal analysis. Our benchmark features over 10,000 manually verified instructions and covers a diverse set of variations in visual conditions, object type, and scale. We evaluate several state-of-the-art VLMs to assess their accuracy within the geospatial context. The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific examples, highlighting the room for further improvements. Specifically, the best-performing GPT4o achieves only 40\% accuracy on MCQs, which is only double the random guess performance. Our benchmark is publicly available at https://github.com/The-AI-Alliance/GEO-Bench-VLM .
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
GeoChat: Grounded Large Vision-Language Model for Remote Sensing
Nov 24, 2023Recent advancements in Large Vision-Language Models (VLMs) have shown great promise in natural image domains, allowing users to hold a dialogue about given visual content. However, such general-domain VLMs perform poorly for Remote Sensing (RS) scenarios, leading to inaccurate or fabricated information when presented with RS domain-specific queries. Such a behavior emerges due to the unique challenges introduced by RS imagery. For example, to handle high-resolution RS imagery with diverse scale changes across categories and many small objects, region-level reasoning is necessary alongside holistic scene interpretation. Furthermore, the lack of domain-specific multimodal instruction following data as well as strong backbone models for RS make it hard for the models to align their behavior with user queries. To address these limitations, we propose GeoChat - the first versatile remote sensing VLM that offers multitask conversational capabilities with high-resolution RS images. Specifically, GeoChat can not only answer image-level queries but also accepts region inputs to hold region-specific dialogue. Furthermore, it can visually ground objects in its responses by referring to their spatial coordinates. To address the lack of domain-specific datasets, we generate a novel RS multimodal instruction-following dataset by extending image-text pairs from existing diverse RS datasets. We establish a comprehensive benchmark for RS multitask conversations and compare with a number of baseline methods. GeoChat demonstrates robust zero-shot performance on various RS tasks, e.g., image and region captioning, visual question answering, scene classification, visually grounded conversations and referring detection. Our code is available at https://github.com/mbzuai-oryx/geochat.