 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LoRA-Enhanced Distillation on Guided Diffusion Models
Dec 12, 2023
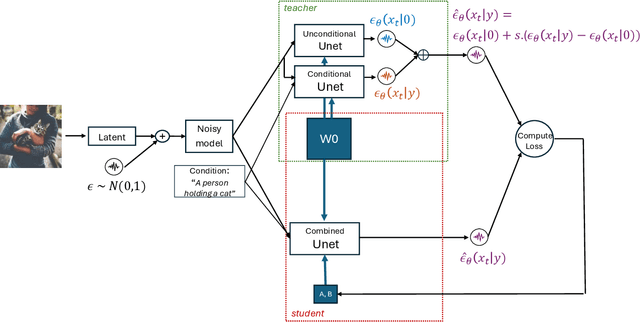


Diffusion models, such as Stable Diffusion (SD), offer the ability to generate high-resolution images with diverse features, but they come at a significant computational and memory cost. In classifier-free guided diffusion models, prolonged inference times are attributed to the necessity of computing two separate diffusion models at each denoising step. Recent work has shown promise in improving inference time through distillation techniques, teaching the model to perform similar denoising steps with reduced computations. However, the application of distillation introduces additional memory overhead to these already resource-intensive diffusion models, making it less practical. To address these challenges, our research explores a novel approach that combines Low-Rank Adaptation (LoRA) with model distillation to efficiently compress diffusion models. This approach not only reduces inference time but also mitigates memory overhead, and notably decreases memory consumption even before applying distillation. The results are remarkable, featuring a significant reduction in inference time due to the distillation process and a substantial 50% reduction in memory consumption. Our examination of the generated images underscores that the incorporation of LoRA-enhanced distillation maintains image quality and alignment with the provided prompts. In summary, while conventional distillation tends to increase memory consumption, LoRA-enhanced distillation offers optimization without any trade-offs or compromises in quality.
Super-Resolution on Rotationally Scanned Photoacoustic Microscopy Images Incorporating Scanning Prior
Dec 12, 2023Photoacoustic Microscopy (PAM) images integrating the advantages of optical contrast and acoustic resolution have been widely used in brain studies. However, there exists a trade-off between scanning speed and image resolution. Compared with traditional raster scanning, rotational scanning provides good opportunities for fast PAM imaging by optimizing the scanning mechanism. Recently, there is a trend to incorporate deep learning into the scanning process to further increase the scanning speed.Yet, most such attempts are performed for raster scanning while those for rotational scanning are relatively rare. In this study, we propose a novel and well-performing super-resolution framework for rotational scanning-based PAM imaging. To eliminate adjacent rows' displacements due to subject motion or high-frequency scanning distortion,we introduce a registration module across odd and even rows in the preprocessing and incorporate displacement degradation in the training. Besides, gradient-based patch selection is proposed to increase the probability of blood vessel patches being selected for training. A Transformer-based network with a global receptive field is applied for better performance. Experimental results on both synthetic and real datasets demonstrate the effectiveness and generalizability of our proposed framework for rotationally scanned PAM images'super-resolution, both quantitatively and qualitatively. Code is available at https://github.com/11710615/PAMSR.git.
Diff-OP3D: Bridging 2D Diffusion for Open Pose 3D Zero-Shot Classification
Dec 12, 2023With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, the methods via transferring Contrastive Language-Image Pre-training (CLIP) to 3D vision have made great progress in the 3D zero-shot classification task. However, these methods primarily focus on aligned pose 3D objects (ap-3os), overlooking the recognition of 3D objects with open poses (op-3os) typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more challenging benchmark for 3D open-pose zero-shot classification. Echoing our benchmark, we design a concise angle-refinement mechanism that automatically optimizes one ideal pose as well as classifies these op-3os. Furthermore, we make a first attempt to bridge 2D pre-trained diffusion model as a classifer to 3D zero-shot classification without any additional training. Such 2D diffusion to 3D objects proves vital in improving zero-shot classification for both ap-3os and op-3os. Our model notably improves by 3.5% and 15.8% on ModelNet10$^{\ddag}$ and McGill$^{\ddag}$ open pose benchmarks, respectively, and surpasses the current state-of-the-art by 6.8% on the aligned pose ModelNet10, affirming diffusion's efficacy in 3D zero-shot tasks.
Spectral and Polarization Vision: Spectro-polarimetric Real-world Dataset
Nov 30, 2023Image datasets are essential not only in validating existing methods in computer vision but also in developing new methods. Most existing image datasets focus on trichromatic intensity images to mimic human vision. However, polarization and spectrum, the wave properties of light that animals in harsh environments and with limited brain capacity often rely on, remain underrepresented in existing datasets. Although spectro-polarimetric datasets exist, these datasets have insufficient object diversity, limited illumination conditions, linear-only polarization data, and inadequate image count. Here, we introduce two spectro-polarimetric datasets: trichromatic Stokes images and hyperspectral Stokes images. These novel datasets encompass both linear and circular polarization; they introduce multiple spectral channels; and they feature a broad selection of real-world scenes. With our dataset in hand, we analyze the spectro-polarimetric image statistics, develop efficient representations of such high-dimensional data, and evaluate spectral dependency of shape-from-polarization methods. As such, the proposed dataset promises a foundation for data-driven spectro-polarimetric imaging and vision research. Dataset and code will be publicly available.
Sound Source Localization for a Source inside a Structure using Ac-CycleGAN
Dec 08, 2023We propose a method for sound source localization (SSL) for a source inside a structure using Ac-CycleGAN under unpaired data conditions. The proposed method utilizes a large amount of simulated data and a small amount of actual experimental data to locate a sound source inside a structure in a real environment. An Ac-CycleGAN generator contributes to the transformation of simulated data into real data, or vice versa, using unpaired data from both domains. The discriminator of an Ac-CycleGAN model is designed to differentiate between the transformed data generated by the generator and real data, while also predicting the location of the sound source. Vectors representing the frequency spectrum of the accelerometers (FSAs) measured at three points outside the structure are used as input data and the source areas inside the structure are used as labels. The input data vectors are concatenated vertically to form an image. Labels are defined by dividing the interior of the structure into eight areas with one-hot encoding for each area. Thus, the SSL problem is redefined as an image-classification problem to stochastically estimate the location of the sound source. We show that it is possible to estimate the sound source location using the Ac-CycleGAN discriminator for unpaired data across domains. Furthermore, we analyze the discriminative factors for distinguishing the data. The proposed model exhibited an accuracy exceeding 90\% when trained on 80\% of actual data (12.5\% of simulated data). Despite potential imperfections in the domain transformation process carried out by the Ac-CycleGAN generator, the discriminator can effectively distinguish between transferred and real data by selectively utilizing only those features that generate a relatively small transformation error.
Local Statistics for Generative Image Detection
Oct 25, 2023Diffusion models (DMs) are generative models that learn to synthesize images from Gaussian noise. DMs can be trained to do a variety of tasks such as image generation and image super-resolution. Researchers have made significant improvement in the capability of synthesizing photorealistic images in the past few years. These successes also hasten the need to address the potential misuse of synthesized images. In this paper, we highlight the effectiveness of computing local statistics, as opposed to global statistics, in distinguishing digital camera images from DM-generated images. We hypothesized that local statistics should be used to address the spatial non-stationarity problem in images. We show that our approach produced promising results and it is also robust to various perturbations such as image resizing and JPEG compression.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
Taming Latent Diffusion Models to See in the Dark
Dec 02, 2023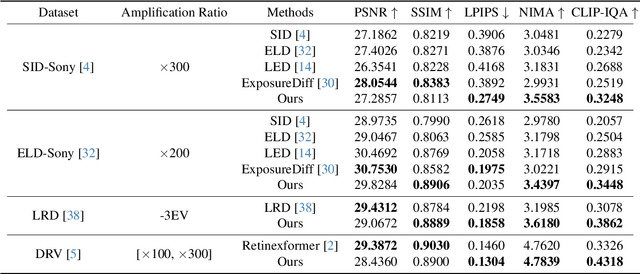
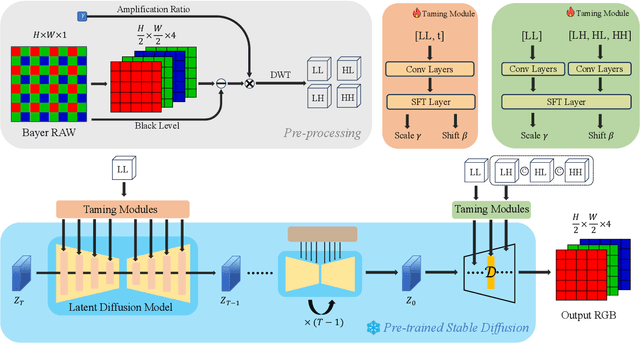


Enhancing a low-light noisy RAW image into a well-exposed and clean sRGB image is a significant challenge in computational photography. Due to the limitation of large-scale paired data, prior approaches have difficulty in recovering fine details and true colors in extremely low-light regions. Meanwhile, recent advancements in generative diffusion models have shown promising generating capabilities, which inspires this work to explore generative priors from a diffusion model trained on a large-scale open-domain dataset to benefit the low-light image enhancement (LLIE) task. Based on this intention, we propose a novel diffusion-model-based LLIE method, dubbed LDM-SID. LDM-SID aims at inserting a set of proposed taming modules into a frozen pre-trained diffusion model to steer its generating process. Specifically, the taming module fed with low-light information serves to output a pair of affine transformation parameters to modulate the intermediate feature in the diffusion model. Additionally, based on the observation of dedicated generative priors across different portions of the diffusion model, we propose to apply 2D discrete wavelet transforms on the input RAW image, resulting in dividing the LLIE task into two essential parts: low-frequency content generation and high-frequency detail maintenance. This enables us to skillfully tame the diffusion model for optimized structural generation and detail enhancement. Extensive experiments demonstrate the proposed method not only achieves state-of-the-art performance in quantitative evaluations but also shows significant superiority in visual comparisons. These findings highlight the effectiveness of leveraging a pre-trained diffusion model as a generative prior to the LLIE task.
Contrastive Vision-Language Alignment Makes Efficient Instruction Learner
Nov 29, 2023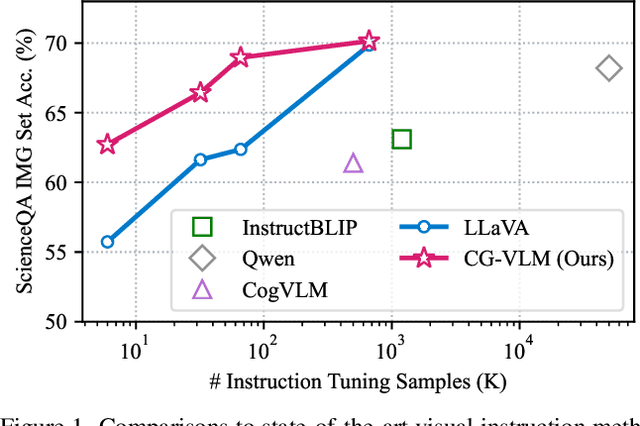
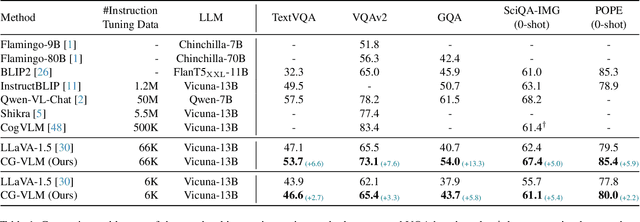
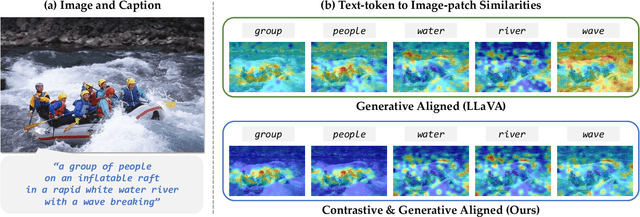
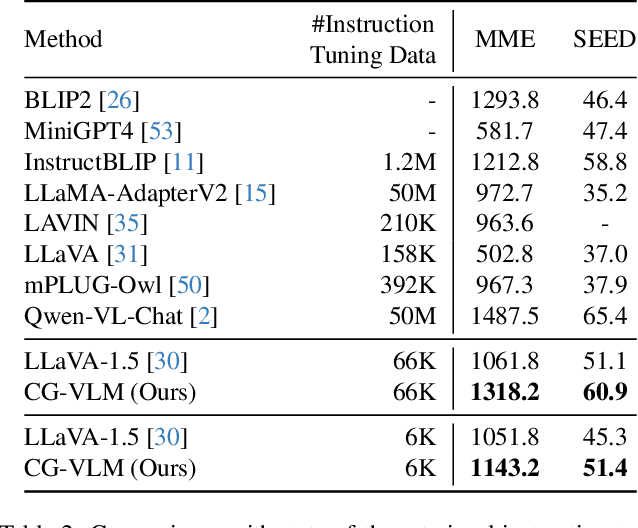
We study the task of extending the large language model (LLM) into a vision-language instruction-following model. This task is crucial but challenging since the LLM is trained on text modality only, making it hard to effectively digest the visual modality. To address this, existing methods typically train a visual adapter to align the representation between a pre-trained vision transformer (ViT) and the LLM by a generative image captioning loss. However, we find that the generative objective can only produce weak alignment for vision and language, making the aligned vision-language model very hungry for the instruction fine-tuning data. In this paper, we propose CG-VLM that applies both Contrastive and Generative alignment objectives to effectively align the representation of ViT and LLM. Different from image level and sentence level alignment in common contrastive learning settings, CG-VLM aligns the image-patch level features and text-token level embeddings, which, however, is very hard to achieve as no explicit grounding patch-token relation provided in standard image captioning datasets. To address this issue, we propose to maximize the averaged similarity between pooled image-patch features and text-token embeddings. Extensive experiments demonstrate that the proposed CG-VLM produces strong vision-language alignment and is an efficient instruction learner. For example, using only 10% instruction tuning data, we reach 95% performance of state-of-the-art method LLaVA [29] on the zero-shot ScienceQA-Image benchmark.
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Dec 05, 2023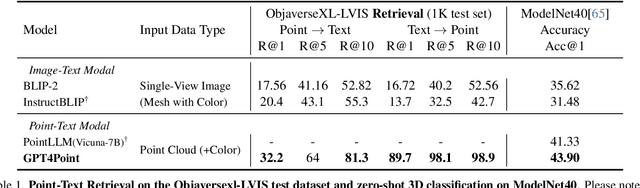
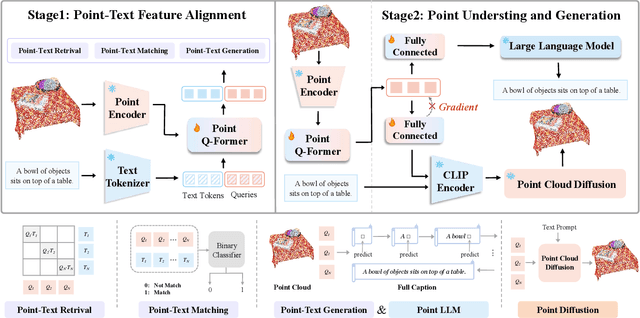
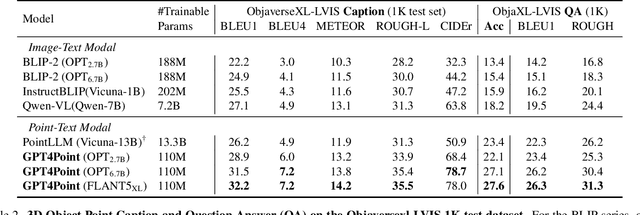
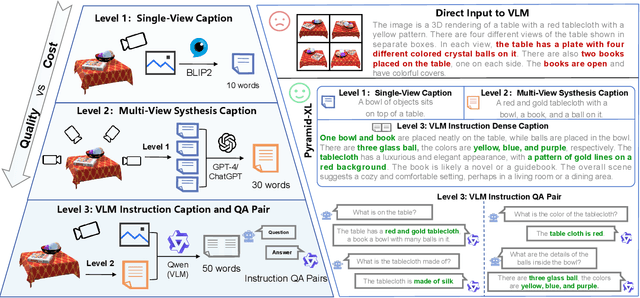
Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.