 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
Apr 21, 2026Human video generation remains challenging due to the difficulty of jointly modeling human appearance, motion, and camera viewpoint under limited multi-view data. Existing methods often address these factors separately, resulting in limited controllability or reduced visual quality. We revisit this problem from an image-first perspective, where high-quality human appearance is learned via image generation and used as a prior for video synthesis, decoupling appearance modeling from temporal consistency. We propose a pose- and viewpoint-controllable pipeline that combines a pretrained image backbone with SMPL-X-based motion guidance, together with a training-free temporal refinement stage based on a pretrained video diffusion model. Our method produces high-quality, temporally consistent videos under diverse poses and viewpoints. We also release a canonical human dataset and an auxiliary model for compositional human image synthesis. Code and data are publicly available at https://github.com/Taited/ReImagine.
Exploring Disentangled and Controllable Human Image Synthesis: From End-to-End to Stage-by-Stage
Mar 25, 2025



Achieving fine-grained controllability in human image synthesis is a long-standing challenge in computer vision. Existing methods primarily focus on either facial synthesis or near-frontal body generation, with limited ability to simultaneously control key factors such as viewpoint, pose, clothing, and identity in a disentangled manner. In this paper, we introduce a new disentangled and controllable human synthesis task, which explicitly separates and manipulates these four factors within a unified framework. We first develop an end-to-end generative model trained on MVHumanNet for factor disentanglement. However, the domain gap between MVHumanNet and in-the-wild data produce unsatisfacotry results, motivating the exploration of virtual try-on (VTON) dataset as a potential solution. Through experiments, we observe that simply incorporating the VTON dataset as additional data to train the end-to-end model degrades performance, primarily due to the inconsistency in data forms between the two datasets, which disrupts the disentanglement process. To better leverage both datasets, we propose a stage-by-stage framework that decomposes human image generation into three sequential steps: clothed A-pose generation, back-view synthesis, and pose and view control. This structured pipeline enables better dataset utilization at different stages, significantly improving controllability and generalization, especially for in-the-wild scenarios. Extensive experiments demonstrate that our stage-by-stage approach outperforms end-to-end models in both visual fidelity and disentanglement quality, offering a scalable solution for real-world tasks. Additional demos are available on the project page: https://taited.github.io/discohuman-project/.
1-2-1: Renaissance of Single-Network Paradigm for Virtual Try-On
Jan 09, 2025



Virtual Try-On (VTON) has become a crucial tool in ecommerce, enabling the realistic simulation of garments on individuals while preserving their original appearance and pose. Early VTON methods relied on single generative networks, but challenges remain in preserving fine-grained garment details due to limitations in feature extraction and fusion. To address these issues, recent approaches have adopted a dual-network paradigm, incorporating a complementary "ReferenceNet" to enhance garment feature extraction and fusion. While effective, this dual-network approach introduces significant computational overhead, limiting its scalability for high-resolution and long-duration image/video VTON applications. In this paper, we challenge the dual-network paradigm by proposing a novel single-network VTON method that overcomes the limitations of existing techniques. Our method, namely MNVTON, introduces a Modality-specific Normalization strategy that separately processes text, image and video inputs, enabling them to share the same attention layers in a VTON network. Extensive experimental results demonstrate the effectiveness of our approach, showing that it consistently achieves higher-quality, more detailed results for both image and video VTON tasks. Our results suggest that the single-network paradigm can rival the performance of dualnetwork approaches, offering a more efficient alternative for high-quality, scalable VTON applications.
PICTURE: PhotorealistIC virtual Try-on from UnconstRained dEsigns
Dec 07, 2023



In this paper, we propose a novel virtual try-on from unconstrained designs (ucVTON) task to enable photorealistic synthesis of personalized composite clothing on input human images. Unlike prior arts constrained by specific input types, our method allows flexible specification of style (text or image) and texture (full garment, cropped sections, or texture patches) conditions. To address the entanglement challenge when using full garment images as conditions, we develop a two-stage pipeline with explicit disentanglement of style and texture. In the first stage, we generate a human parsing map reflecting the desired style conditioned on the input. In the second stage, we composite textures onto the parsing map areas based on the texture input. To represent complex and non-stationary textures that have never been achieved in previous fashion editing works, we first propose extracting hierarchical and balanced CLIP features and applying position encoding in VTON. Experiments demonstrate superior synthesis quality and personalization enabled by our method. The flexible control over style and texture mixing brings virtual try-on to a new level of user experience for online shopping and fashion design.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023



In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
FashionTex: Controllable Virtual Try-on with Text and Texture
May 08, 2023



Virtual try-on attracts increasing research attention as a promising way for enhancing the user experience for online cloth shopping. Though existing methods can generate impressive results, users need to provide a well-designed reference image containing the target fashion clothes that often do not exist. To support user-friendly fashion customization in full-body portraits, we propose a multi-modal interactive setting by combining the advantages of both text and texture for multi-level fashion manipulation. With the carefully designed fashion editing module and loss functions, FashionTex framework can semantically control cloth types and local texture patterns without annotated pairwise training data. We further introduce an ID recovery module to maintain the identity of input portrait. Extensive experiments have demonstrated the effectiveness of our proposed pipeline.
MIMO Is All You Need : A Strong Multi-In-Multi-Out Baseline for Video Prediction
Dec 09, 2022



The mainstream of the existing approaches for video prediction builds up their models based on a Single-In-Single-Out (SISO) architecture, which takes the current frame as input to predict the next frame in a recursive manner. This way often leads to severe performance degradation when they try to extrapolate a longer period of future, thus limiting the practical use of the prediction model. Alternatively, a Multi-In-Multi-Out (MIMO) architecture that outputs all the future frames at one shot naturally breaks the recursive manner and therefore prevents error accumulation. However, only a few MIMO models for video prediction are proposed and they only achieve inferior performance due to the date. The real strength of the MIMO model in this area is not well noticed and is largely under-explored. Motivated by that, we conduct a comprehensive investigation in this paper to thoroughly exploit how far a simple MIMO architecture can go. Surprisingly, our empirical studies reveal that a simple MIMO model can outperform the state-of-the-art work with a large margin much more than expected, especially in dealing with longterm error accumulation. After exploring a number of ways and designs, we propose a new MIMO architecture based on extending the pure Transformer with local spatio-temporal blocks and a new multi-output decoder, namely MIMO-VP, to establish a new standard in video prediction. We evaluate our model in four highly competitive benchmarks (Moving MNIST, Human3.6M, Weather, KITTI). Extensive experiments show that our model wins 1st place on all the benchmarks with remarkable performance gains and surpasses the best SISO model in all aspects including efficiency, quantity, and quality. We believe our model can serve as a new baseline to facilitate the future research of video prediction tasks. The code will be released.
From Single to Multiple: Leveraging Multi-level Prediction Spaces for Video Forecasting
Jul 21, 2021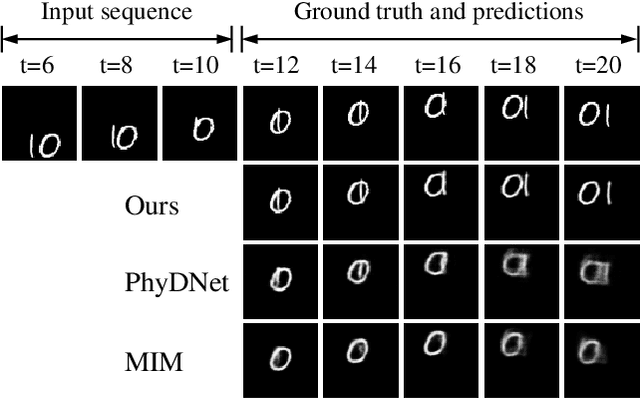
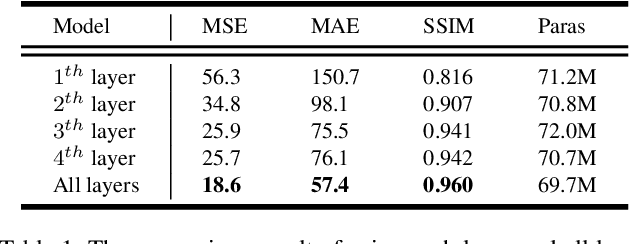
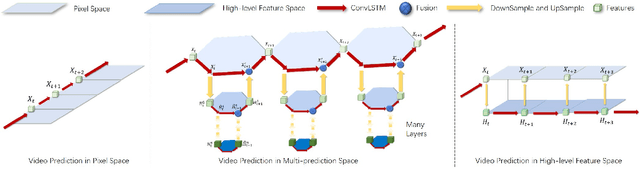
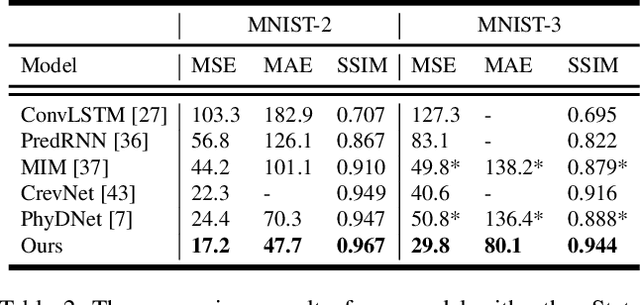
Despite video forecasting has been a widely explored topic in recent years, the mainstream of the existing work still limits their models with a single prediction space but completely neglects the way to leverage their model with multi-prediction spaces. This work fills this gap. For the first time, we deeply study numerous strategies to perform video forecasting in multi-prediction spaces and fuse their results together to boost performance. The prediction in the pixel space usually lacks the ability to preserve the semantic and structure content of the video however the prediction in the high-level feature space is prone to generate errors in the reduction and recovering process. Therefore, we build a recurrent connection between different feature spaces and incorporate their generations in the upsampling process. Rather surprisingly, this simple idea yields a much more significant performance boost than PhyDNet (performance improved by 32.1% MAE on MNIST-2 dataset, and 21.4% MAE on KTH dataset). Both qualitative and quantitative evaluations on four datasets demonstrate the generalization ability and effectiveness of our approach. We show that our model significantly reduces the troublesome distortions and blurry artifacts and brings remarkable improvements to the accuracy in long term video prediction. The code will be released soon.