 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MimicDiffusion: Purifying Adversarial Perturbation via Mimicking Clean Diffusion Model
Dec 08, 2023
Deep neural networks (DNNs) are vulnerable to adversarial perturbation, where an imperceptible perturbation is added to the image that can fool the DNNs. Diffusion-based adversarial purification focuses on using the diffusion model to generate a clean image against such adversarial attacks. Unfortunately, the generative process of the diffusion model is also inevitably affected by adversarial perturbation since the diffusion model is also a deep network where its input has adversarial perturbation. In this work, we propose MimicDiffusion, a new diffusion-based adversarial purification technique, that directly approximates the generative process of the diffusion model with the clean image as input. Concretely, we analyze the differences between the guided terms using the clean image and the adversarial sample. After that, we first implement MimicDiffusion based on Manhattan distance. Then, we propose two guidance to purify the adversarial perturbation and approximate the clean diffusion model. Extensive experiments on three image datasets including CIFAR-10, CIFAR-100, and ImageNet with three classifier backbones including WideResNet-70-16, WideResNet-28-10, and ResNet50 demonstrate that MimicDiffusion significantly performs better than the state-of-the-art baselines. On CIFAR-10, CIFAR-100, and ImageNet, it achieves 92.67\%, 61.35\%, and 61.53\% average robust accuracy, which are 18.49\%, 13.23\%, and 17.64\% higher, respectively. The code is available in the supplementary material.
Unified framework for diffusion generative models in SO(3): applications in computer vision and astrophysics
Dec 18, 2023Diffusion-based generative models represent the current state-of-the-art for image generation. However, standard diffusion models are based on Euclidean geometry and do not translate directly to manifold-valued data. In this work, we develop extensions of both score-based generative models (SGMs) and Denoising Diffusion Probabilistic Models (DDPMs) to the Lie group of 3D rotations, SO(3). SO(3) is of particular interest in many disciplines such as robotics, biochemistry and astronomy/cosmology science. Contrary to more general Riemannian manifolds, SO(3) admits a tractable solution to heat diffusion, and allows us to implement efficient training of diffusion models. We apply both SO(3) DDPMs and SGMs to synthetic densities on SO(3) and demonstrate state-of-the-art results. Additionally, we demonstrate the practicality of our model on pose estimation tasks and in predicting correlated galaxy orientations for astrophysics/cosmology.
Scaling Laws of Synthetic Images for Model Training ... for Now
Dec 07, 2023Recent significant advances in text-to-image models unlock the possibility of training vision systems using synthetic images, potentially overcoming the difficulty of collecting curated data at scale. It is unclear, however, how these models behave at scale, as more synthetic data is added to the training set. In this paper we study the scaling laws of synthetic images generated by state of the art text-to-image models, for the training of supervised models: image classifiers with label supervision, and CLIP with language supervision. We identify several factors, including text prompts, classifier-free guidance scale, and types of text-to-image models, that significantly affect scaling behavior. After tuning these factors, we observe that synthetic images demonstrate a scaling trend similar to, but slightly less effective than, real images in CLIP training, while they significantly underperform in scaling when training supervised image classifiers. Our analysis indicates that the main reason for this underperformance is the inability of off-the-shelf text-to-image models to generate certain concepts, a limitation that significantly impairs the training of image classifiers. Our findings also suggest that scaling synthetic data can be particularly effective in scenarios such as: (1) when there is a limited supply of real images for a supervised problem (e.g., fewer than 0.5 million images in ImageNet), (2) when the evaluation dataset diverges significantly from the training data, indicating the out-of-distribution scenario, or (3) when synthetic data is used in conjunction with real images, as demonstrated in the training of CLIP models.
DiffCMR: Fast Cardiac MRI Reconstruction with Diffusion Probabilistic Models
Dec 08, 2023Performing magnetic resonance imaging (MRI) reconstruction from under-sampled k-space data can accelerate the procedure to acquire MRI scans and reduce patients' discomfort. The reconstruction problem is usually formulated as a denoising task that removes the noise in under-sampled MRI image slices. Although previous GAN-based methods have achieved good performance in image denoising, they are difficult to train and require careful tuning of hyperparameters. In this paper, we propose a novel MRI denoising framework DiffCMR by leveraging conditional denoising diffusion probabilistic models. Specifically, DiffCMR perceives conditioning signals from the under-sampled MRI image slice and generates its corresponding fully-sampled MRI image slice. During inference, we adopt a multi-round ensembling strategy to stabilize the performance. We validate DiffCMR with cine reconstruction and T1/T2 mapping tasks on MICCAI 2023 Cardiac MRI Reconstruction Challenge (CMRxRecon) dataset. Results show that our method achieves state-of-the-art performance, exceeding previous methods by a significant margin. Code is available at https://github.com/xmed-lab/DiffCMR.
GenHowTo: Learning to Generate Actions and State Transformations from Instructional Videos
Dec 12, 2023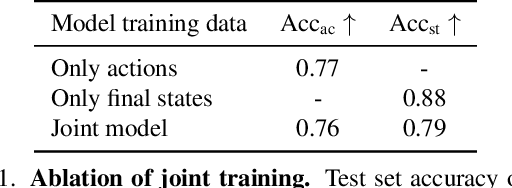
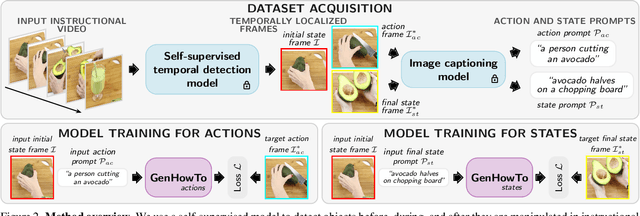
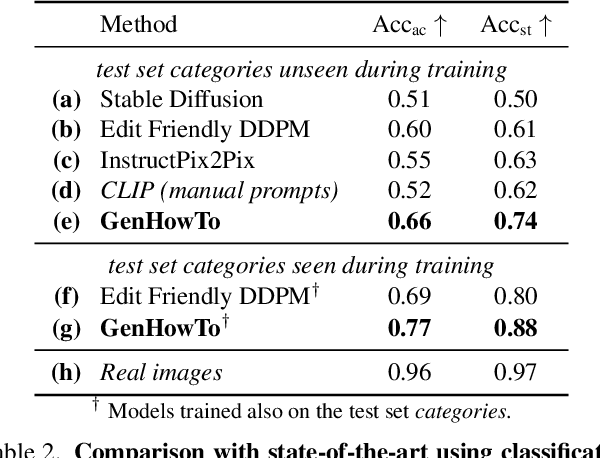

We address the task of generating temporally consistent and physically plausible images of actions and object state transformations. Given an input image and a text prompt describing the targeted transformation, our generated images preserve the environment and transform objects in the initial image. Our contributions are threefold. First, we leverage a large body of instructional videos and automatically mine a dataset of triplets of consecutive frames corresponding to initial object states, actions, and resulting object transformations. Second, equipped with this data, we develop and train a conditioned diffusion model dubbed GenHowTo. Third, we evaluate GenHowTo on a variety of objects and actions and show superior performance compared to existing methods. In particular, we introduce a quantitative evaluation where GenHowTo achieves 88% and 74% on seen and unseen interaction categories, respectively, outperforming prior work by a large margin.
Benchmarking Pretrained Vision Embeddings for Near- and Duplicate Detection in Medical Images
Dec 12, 2023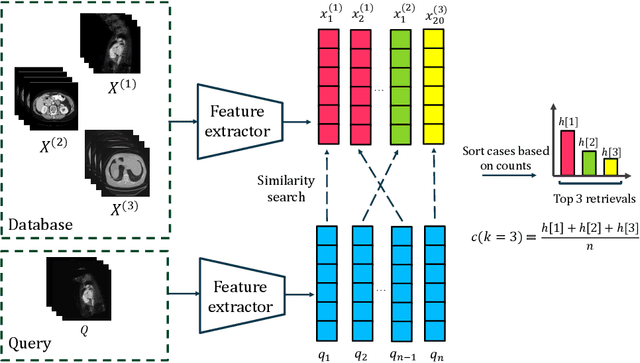
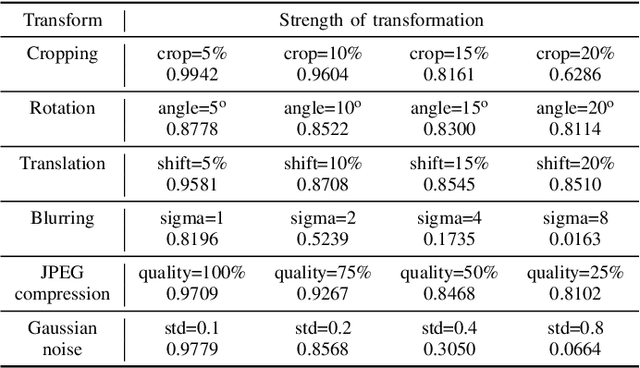
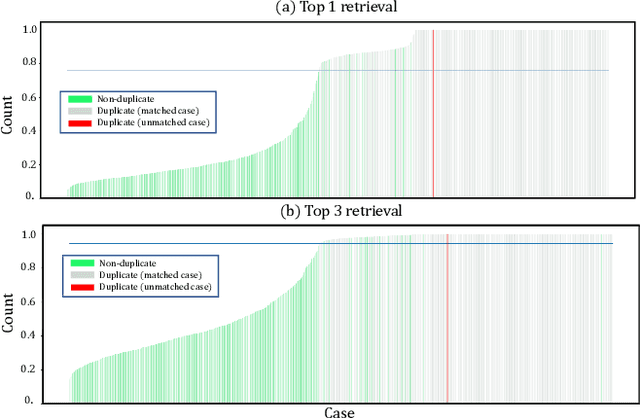
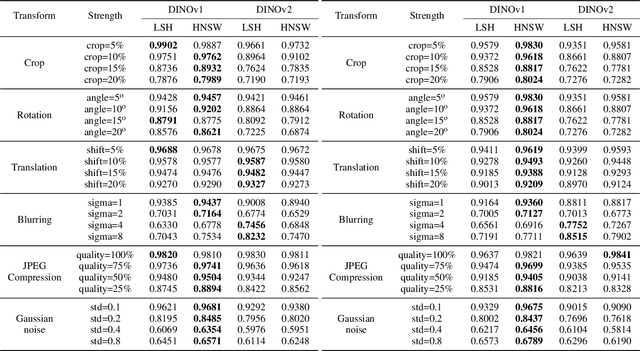
Near- and duplicate image detection is a critical concern in the field of medical imaging. Medical datasets often contain similar or duplicate images from various sources, which can lead to significant performance issues and evaluation biases, especially in machine learning tasks due to data leakage between training and testing subsets. In this paper, we present an approach for identifying near- and duplicate 3D medical images leveraging publicly available 2D computer vision embeddings. We assessed our approach by comparing embeddings extracted from two state-of-the-art self-supervised pretrained models and two different vector index structures for similarity retrieval. We generate an experimental benchmark based on the publicly available Medical Segmentation Decathlon dataset. The proposed method yields promising results for near- and duplicate image detection achieving a mean sensitivity and specificity of 0.9645 and 0.8559, respectively.
Diversified in-domain synthesis with efficient fine-tuning for few-shot classification
Dec 07, 2023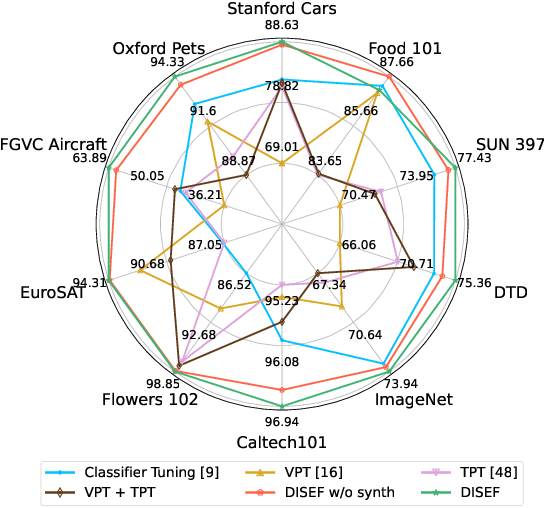

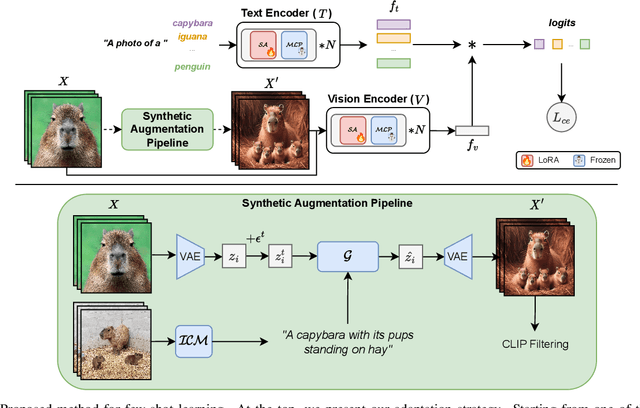
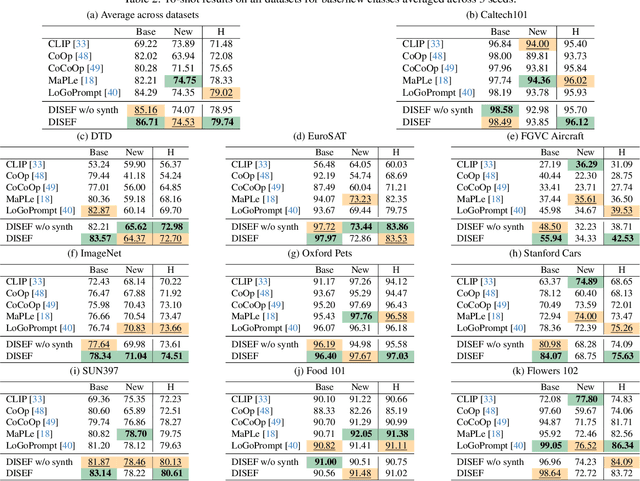
Few-shot image classification aims to learn an image classifier using only a small set of labeled examples per class. A recent research direction for improving few-shot classifiers involves augmenting the labelled samples with synthetic images created by state-of-the-art text-to-image generation models. Following this trend, we propose Diversified In-domain Synthesis with Efficient Fine-tuning (DISEF), a novel approach which addresses the generalization challenge in few-shot learning using synthetic data. DISEF consists of two main components. First, we propose a novel text-to-image augmentation pipeline that, by leveraging the real samples and their rich semantics coming from an advanced captioning model, promotes in-domain sample diversity for better generalization. Second, we emphasize the importance of effective model fine-tuning in few-shot recognition, proposing to use Low-Rank Adaptation (LoRA) for joint adaptation of the text and image encoders in a Vision Language Model. We validate our method in ten different benchmarks, consistently outperforming baselines and establishing a new state-of-the-art for few-shot classification. Code is available at https://github.com/vturrisi/disef.
Approximate Caching for Efficiently Serving Diffusion Models
Dec 07, 2023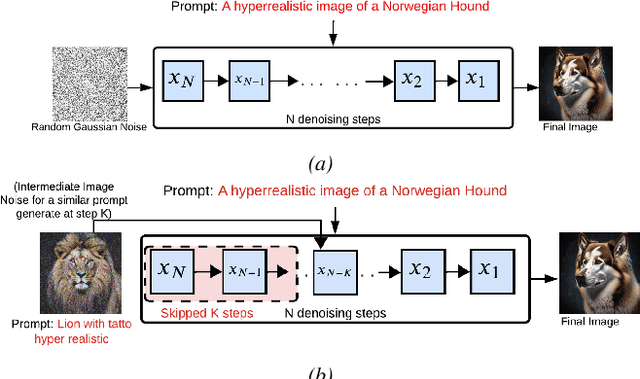
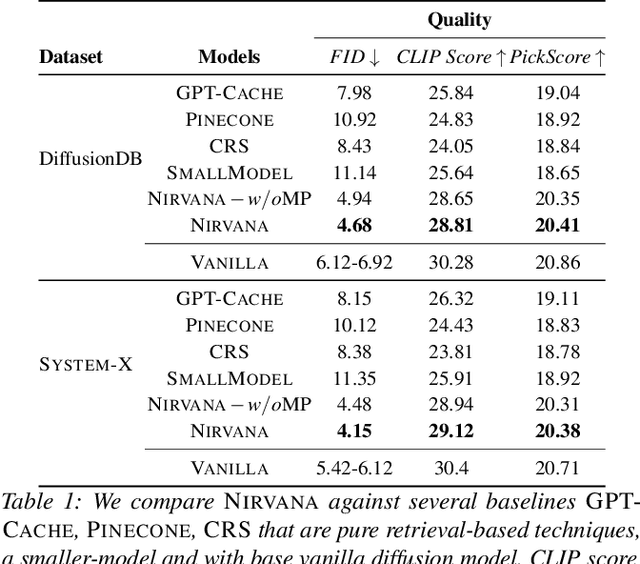
Text-to-image generation using diffusion models has seen explosive popularity owing to their ability in producing high quality images adhering to text prompts. However, production-grade diffusion model serving is a resource intensive task that not only require high-end GPUs which are expensive but also incurs considerable latency. In this paper, we introduce a technique called approximate-caching that can reduce such iterative denoising steps for an image generation based on a prompt by reusing intermediate noise states created during a prior image generation for similar prompts. Based on this idea, we present an end to end text-to-image system, Nirvana, that uses the approximate-caching with a novel cache management-policy Least Computationally Beneficial and Frequently Used (LCBFU) to provide % GPU compute savings, 19.8% end-to-end latency reduction and 19% dollar savings, on average, on two real production workloads. We further present an extensive characterization of real production text-to-image prompts from the perspective of caching, popularity and reuse of intermediate states in a large production environment.
Genixer: Empowering Multimodal Large Language Models as a Powerful Data Generator
Dec 11, 2023Large Language Models (LLMs) excel in understanding human instructions, driving the development of Multimodal LLMs (MLLMs) with instruction tuning. However, acquiring high-quality multimodal instruction tuning data poses a significant challenge. Previous approaches relying on GPT-4 for data generation proved expensive and exhibited unsatisfactory performance for certain tasks. To solve this, we present Genixer, an innovative data generation pipeline producing high-quality multimodal instruction tuning data for various tasks. Genixer collects datasets for ten prevalent multimodal tasks and designs instruction templates to transform these datasets into instruction-tuning data. It then trains pretrained MLLMs to generate task-specific instruction data and proposes an effective data filtering strategy to ensure high quality. To evaluate Genixer, a base MLLM model, Kakapo, is built and achieves SoTA performance in image captioning and visual question answering (VQA) tasks across multiple datasets. Experimental results show that filtered data from Genixer continually improves Kakapo for image captioning and VQA tasks. For the SoTA Shikra MLLM model on the image-region-related tasks, e.g., region caption and detection, Genixer also successfully generates corresponding data and improves its performance. Genixer opens avenues for generating high-quality multimodal instruction data for diverse tasks, enabling innovative applications across domains. The code and models will be released soon.
OT-Attack: Enhancing Adversarial Transferability of Vision-Language Models via Optimal Transport Optimization
Dec 07, 2023Vision-language pre-training (VLP) models demonstrate impressive abilities in processing both images and text. However, they are vulnerable to multi-modal adversarial examples (AEs). Investigating the generation of high-transferability adversarial examples is crucial for uncovering VLP models' vulnerabilities in practical scenarios. Recent works have indicated that leveraging data augmentation and image-text modal interactions can enhance the transferability of adversarial examples for VLP models significantly. However, they do not consider the optimal alignment problem between dataaugmented image-text pairs. This oversight leads to adversarial examples that are overly tailored to the source model, thus limiting improvements in transferability. In our research, we first explore the interplay between image sets produced through data augmentation and their corresponding text sets. We find that augmented image samples can align optimally with certain texts while exhibiting less relevance to others. Motivated by this, we propose an Optimal Transport-based Adversarial Attack, dubbed OT-Attack. The proposed method formulates the features of image and text sets as two distinct distributions and employs optimal transport theory to determine the most efficient mapping between them. This optimal mapping informs our generation of adversarial examples to effectively counteract the overfitting issues. Extensive experiments across various network architectures and datasets in image-text matching tasks reveal that our OT-Attack outperforms existing state-of-the-art methods in terms of adversarial transferability.