 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation
Dec 13, 2019
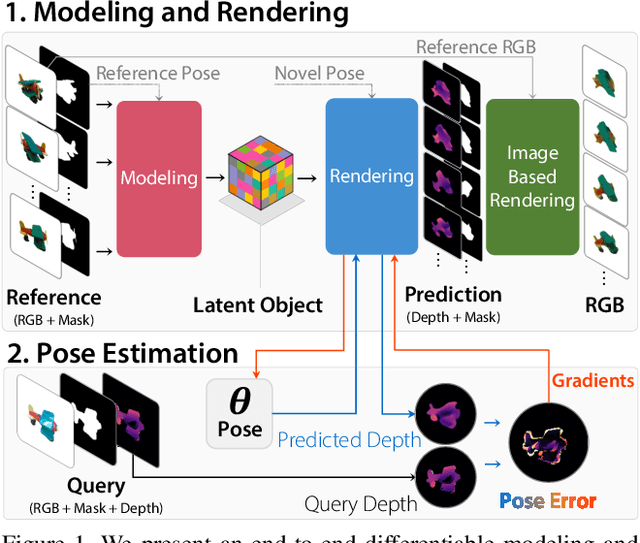
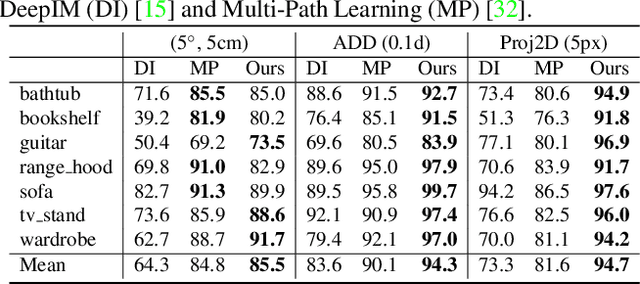
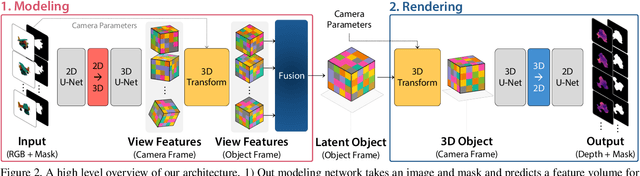
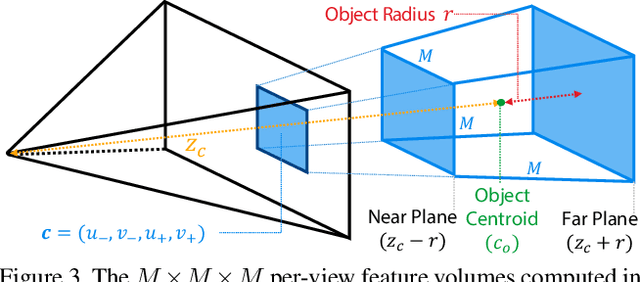
Current 6D object pose estimation methods usually require a 3D model for each object. These methods also require additional training in order to incorporate new objects. As a result, they are difficult to scale to a large number of objects and cannot be directly applied to unseen objects. In this work, we propose a novel framework for 6D pose estimation of unseen objects. We design an end-to-end neural network that reconstructs a latent 3D representation of an object using a small number of reference views of the object. Using the learned 3D representation, the network is able to render the object from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image. By training our network with a large number of 3D shapes for reconstruction and rendering, our network generalizes well to unseen objects. We present a new dataset for unseen object pose estimation--MOPED. We evaluate the performance of our method for unseen object pose estimation on MOPED as well as the ModelNet dataset.
Machine Learning enabled Spectrum Sharing in Dense LTE-U/Wi-Fi Coexistence Scenarios
Mar 18, 2020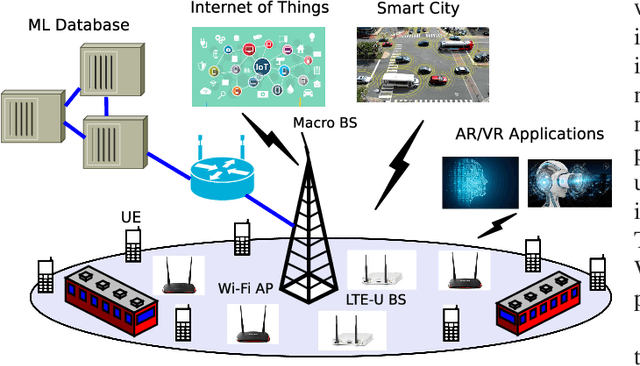
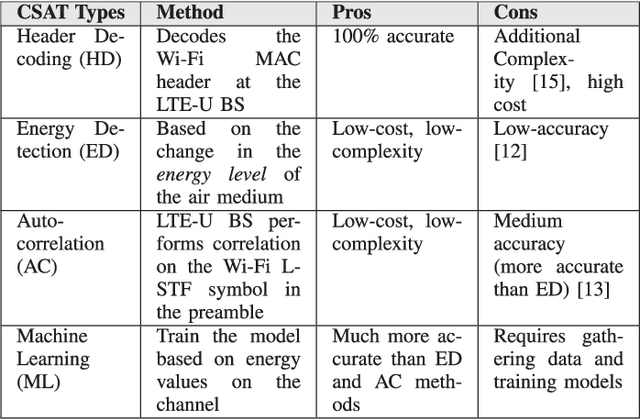
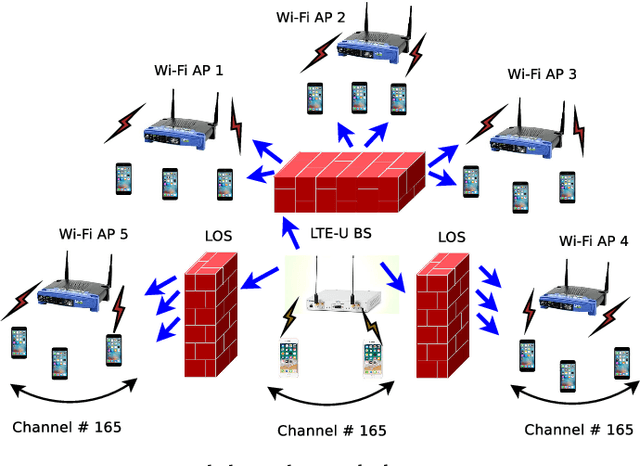
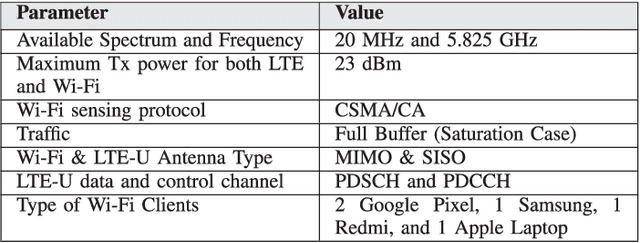
The application of Machine Learning (ML) techniques to complex engineering problems has proved to be an attractive and efficient solution. ML has been successfully applied to several practical tasks like image recognition, automating industrial operations, etc. The promise of ML techniques in solving non-linear problems influenced this work which aims to apply known ML techniques and develop new ones for wireless spectrum sharing between Wi-Fi and LTE in the unlicensed spectrum. In this work, we focus on the LTE-Unlicensed (LTE-U) specification developed by the LTE-U Forum, which uses the duty-cycle approach for fair coexistence. The specification suggests reducing the duty cycle at the LTE-U base-station (BS) when the number of co-channel Wi-Fi basic service sets (BSSs) increases from one to two or more. However, without decoding the Wi-Fi packets, detecting the number of Wi-Fi BSSs operating on the channel in real-time is a challenging problem. In this work, we demonstrate a novel ML-based approach which solves this problem by using energy values observed during the LTE-U OFF duration. It is relatively straightforward to observe only the energy values during the LTE-U BS OFF time compared to decoding the entire Wi-Fi packet, which would require a full Wi-Fi receiver at the LTE-U base-station. We implement and validate the proposed ML-based approach by real-time experiments and demonstrate that there exist distinct patterns between the energy distributions between one and many Wi-Fi AP transmissions. The proposed ML-based approach results in a higher accuracy (close to 99\% in all cases) as compared to the existing auto-correlation (AC) and energy detection (ED) approaches.
Parallel Convolutional Networks for Image Recognition via a Discriminator
Sep 25, 2018
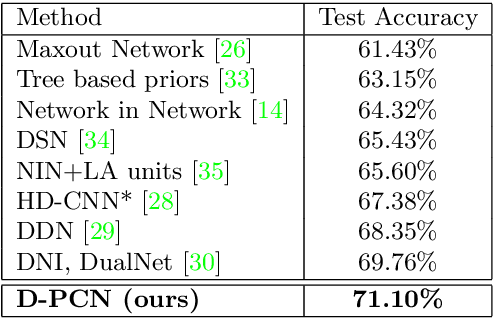
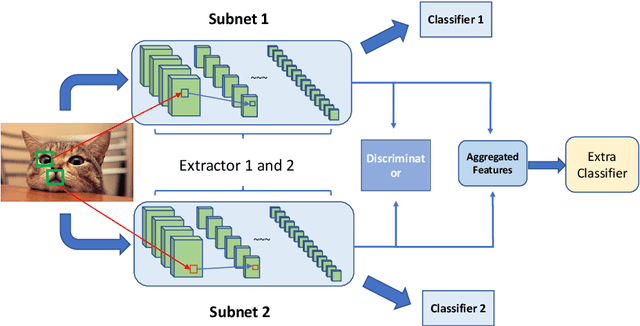
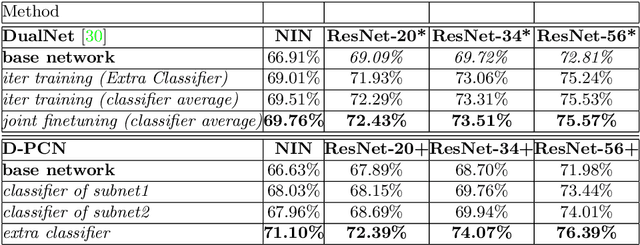
In this paper, we introduce a simple but quite effective recognition framework dubbed D-PCN, aiming at enhancing feature extracting ability of CNN. The framework consists of two parallel CNNs, a discriminator and an extra classifier which takes integrated features from parallel networks and gives final prediction. The discriminator is core which drives parallel networks to focus on different regions and learn different representations. The corresponding training strategy is introduced to ensures utilization of discriminator. We validate D-PCN with several CNN models on benchmark datasets: CIFAR-100, and ImageNet, D-PCN enhances all models. In particular it yields state of the art performance on CIFAR-100 compared with related works. We also conduct visualization experiment on fine-grained Stanford Dogs dataset to verify our motivation. Additionally, we apply D-PCN for segmentation on PASCAL VOC 2012 and also find promotion.
Conditional Single-view Shape Generation for Multi-view Stereo Reconstruction
Apr 14, 2019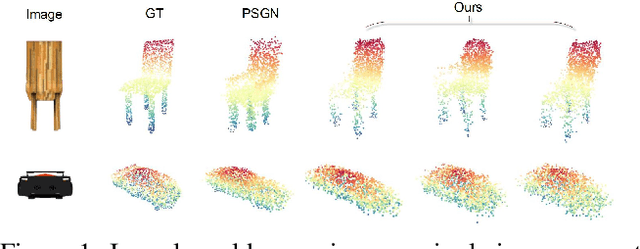
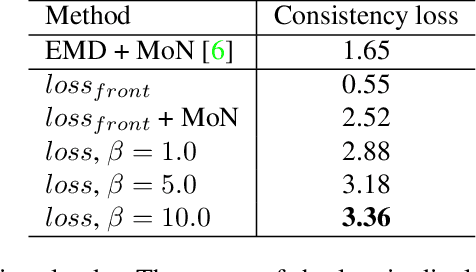
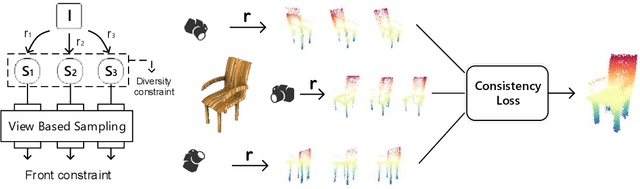
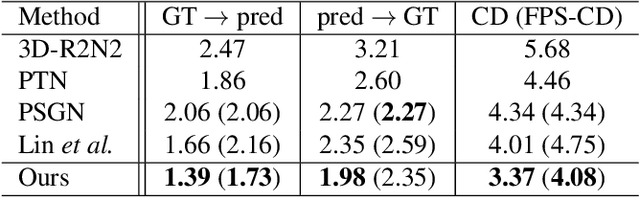
In this paper, we present a new perspective towards image-based shape generation. Most existing deep learning based shape reconstruction methods employ a single-view deterministic model which is sometimes insufficient to determine a single groundtruth shape because the back part is occluded. In this work, we first introduce a conditional generative network to model the uncertainty for single-view reconstruction. Then, we formulate the task of multi-view reconstruction as taking the intersection of the predicted shape spaces on each single image. We design new differentiable guidance including the front constraint, the diversity constraint, and the consistency loss to enable effective single-view conditional generation and multi-view synthesis. Experimental results and ablation studies show that our proposed approach outperforms state-of-the-art methods on 3D reconstruction test error and demonstrate its generalization ability on real world data.
Video Monitoring Queries
Feb 24, 2020
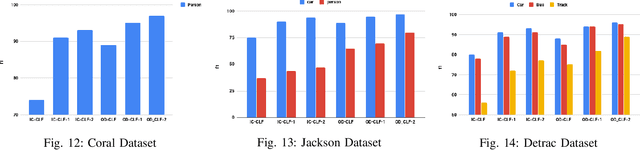
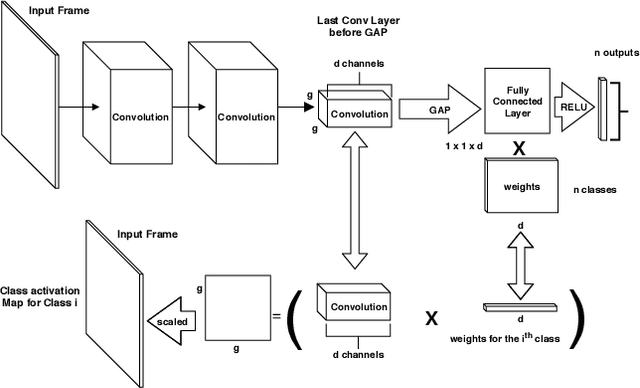

Recent advances in video processing utilizing deep learning primitives achieved breakthroughs in fundamental problems in video analysis such as frame classification and object detection enabling an array of new applications. In this paper we study the problem of interactive declarative query processing on video streams. In particular we introduce a set of approximate filters to speed up queries that involve objects of specific type (e.g., cars, trucks, etc.) on video frames with associated spatial relationships among them (e.g., car left of truck). The resulting filters are able to assess quickly if the query predicates are true to proceed with further analysis of the frame or otherwise not consider the frame further avoiding costly object detection operations. We propose two classes of filters $IC$ and $OD$, that adapt principles from deep image classification and object detection. The filters utilize extensible deep neural architectures and are easy to deploy and utilize. In addition, we propose statistical query processing techniques to process aggregate queries involving objects with spatial constraints on video streams and demonstrate experimentally the resulting increased accuracy on the resulting aggregate estimation. Combined these techniques constitute a robust set of video monitoring query processing techniques. We demonstrate that the application of the techniques proposed in conjunction with declarative queries on video streams can dramatically increase the frame processing rate and speed up query processing by at least two orders of magnitude. We present the results of a thorough experimental study utilizing benchmark video data sets at scale demonstrating the performance benefits and the practical relevance of our proposals.
Correcting Decalibration of Stereo Cameras in Self-Driving Vehicles
Jan 15, 2020
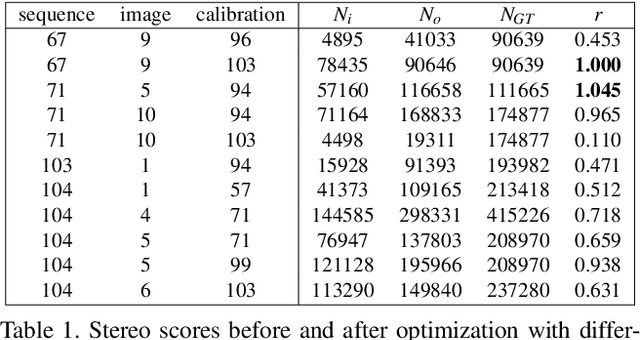

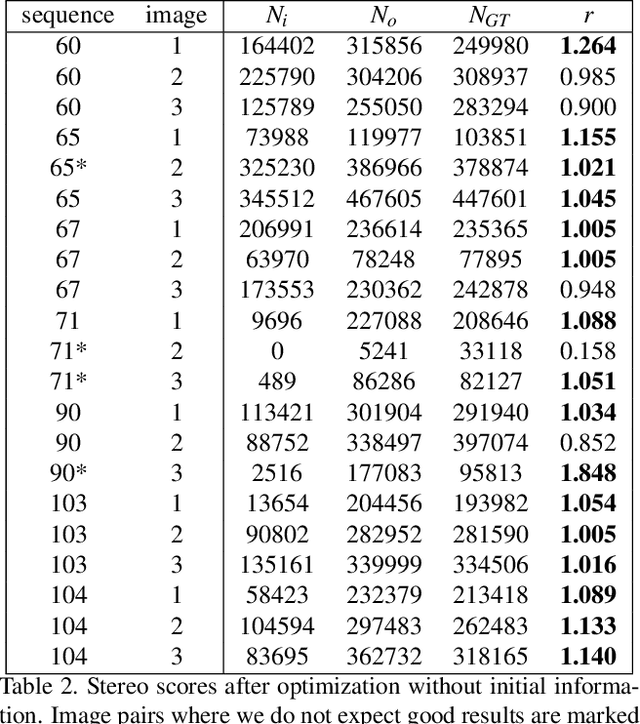
We address the problem of optical decalibration in mobile stereo camera setups, especially in context of autonomous vehicles. In real world conditions, an optical system is subject to various sources of anticipated and unanticipated mechanical stress (vibration, rough handling, collisions). Mechanical stress changes the geometry between the cameras that make up the stereo pair, and as a consequence, the pre-calculated epipolar geometry is no longer valid. Our method is based on optimization of camera geometry parameters and plugs directly into the output of the stereo matching algorithm. Therefore, it is able to recover calibration parameters on image pairs obtained from a decalibrated stereo system with minimal use of additional computing resources. The number of successfully recovered depth pixels is used as an objective function, which we aim to maximize. Our simulation confirms that the method can run constantly in parallel to stereo estimation and thus help keep the system calibrated in real time. Results confirm that the method is able to recalibrate all the parameters except for the baseline distance, which scales the absolute depth readings. However, that scaling factor could be uniquely determined using any kind of absolute range finding methods (e.g. a single beam time-of-flight sensor).
Advances in Hyperspectral Image Classification: Earth monitoring with statistical learning methods
Oct 18, 2013
Hyperspectral images show similar statistical properties to natural grayscale or color photographic images. However, the classification of hyperspectral images is more challenging because of the very high dimensionality of the pixels and the small number of labeled examples typically available for learning. These peculiarities lead to particular signal processing problems, mainly characterized by indetermination and complex manifolds. The framework of statistical learning has gained popularity in the last decade. New methods have been presented to account for the spatial homogeneity of images, to include user's interaction via active learning, to take advantage of the manifold structure with semisupervised learning, to extract and encode invariances, or to adapt classifiers and image representations to unseen yet similar scenes. This tutuorial reviews the main advances for hyperspectral remote sensing image classification through illustrative examples.
Distortion-adaptive Salient Object Detection in 360$^\circ$ Omnidirectional Images
Sep 11, 2019
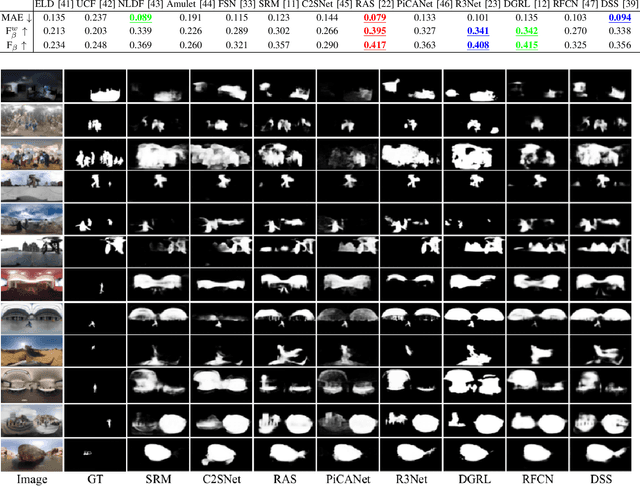


Image-based salient object detection (SOD) has been extensively explored in the past decades. However, SOD on 360$^\circ$ omnidirectional images is less studied owing to the lack of datasets with pixel-level annotations. Toward this end, this paper proposes a 360$^\circ$ image-based SOD dataset that contains 500 high-resolution equirectangular images. We collect the representative equirectangular images from five mainstream 360$^\circ$ video datasets and manually annotate all objects and regions over these images with precise masks with a free-viewpoint way. To the best of our knowledge, it is the first public available dataset for salient object detection on 360$^\circ$ scenes. By observing this dataset, we find that distortion from projection, large-scale complex scene and small salient objects are the most prominent characteristics. Inspired by these foundings, this paper proposes a baseline model for SOD on equirectangular images. In the proposed approach, we construct a distortion-adaptive module to deal with the distortion caused by the equirectangular projection. In addition, a multi-scale contextual integration block is introduced to perceive and distinguish the rich scenes and objects in omnidirectional scenes. The whole network is organized in a progressively manner with deep supervision. Experimental results show the proposed baseline approach outperforms the top-performanced state-of-the-art methods on 360$^\circ$ SOD dataset. Moreover, benchmarking results of the proposed baseline approach and other methods on 360$^\circ$ SOD dataset show the proposed dataset is very challenging, which also validate the usefulness of the proposed dataset and approach to boost the development of SOD on 360$^\circ$ omnidirectional scenes.
PUGeo-Net: A Geometry-centric Network for 3D Point Cloud Upsampling
Feb 24, 2020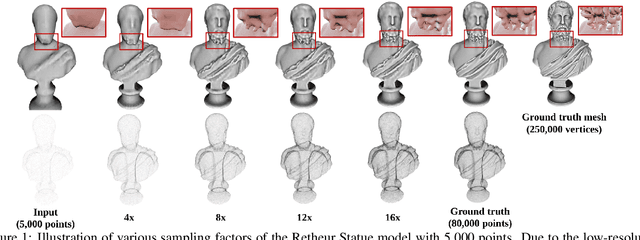
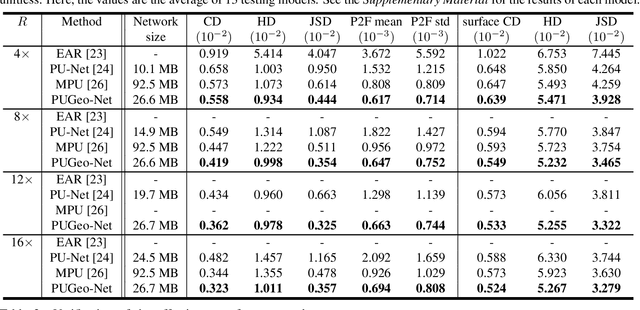
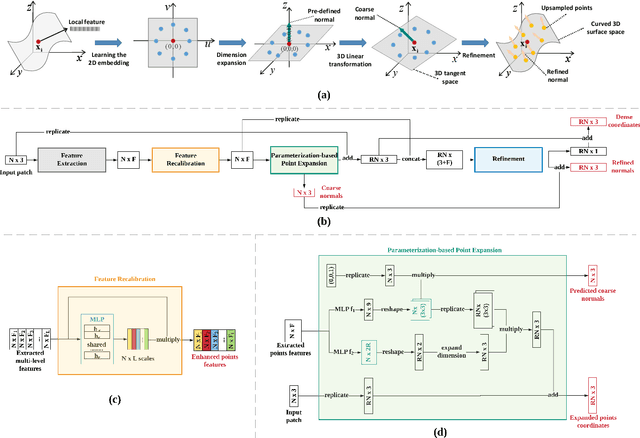
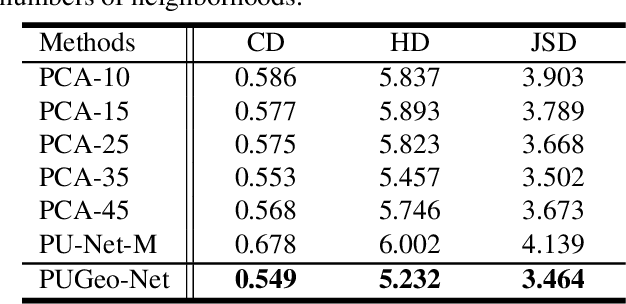
This paper addresses the problem of generating uniform dense point clouds to describe the underlying geometric structures from given sparse point clouds. Due to the irregular and unordered nature, point cloud densification as a generative task is challenging. To tackle the challenge, we propose a novel deep neural network based method, called PUGeo-Net, that learns a $3\times 3$ linear transformation matrix $\bf T$ for each input point. Matrix $\mathbf T$ approximates the augmented Jacobian matrix of a local parameterization and builds a one-to-one correspondence between the 2D parametric domain and the 3D tangent plane so that we can lift the adaptively distributed 2D samples (which are also learned from data) to 3D space. After that, we project the samples to the curved surface by computing a displacement along the normal of the tangent plane. PUGeo-Net is fundamentally different from the existing deep learning methods that are largely motivated by the image super-resolution techniques and generate new points in the abstract feature space. Thanks to its geometry-centric nature, PUGeo-Net works well for both CAD models with sharp features and scanned models with rich geometric details. Moreover, PUGeo-Net can compute the normal for the original and generated points, which is highly desired by the surface reconstruction algorithms. Computational results show that PUGeo-Net, the first neural network that can jointly generate vertex coordinates and normals, consistently outperforms the state-of-the-art in terms of accuracy and efficiency for upsampling factor $4\sim 16$
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 02, 2019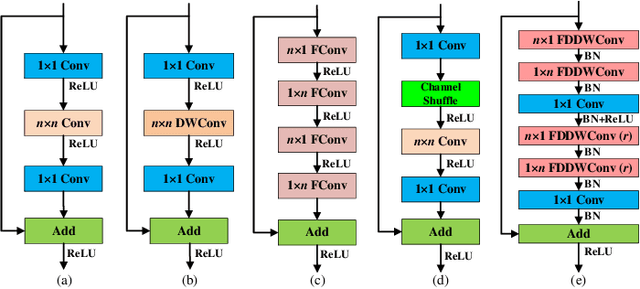
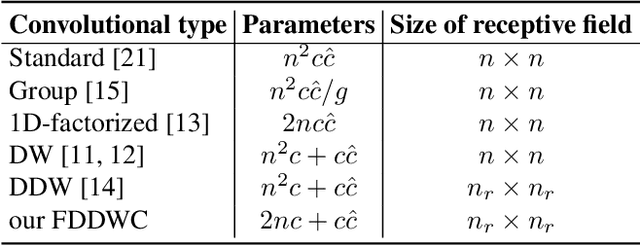
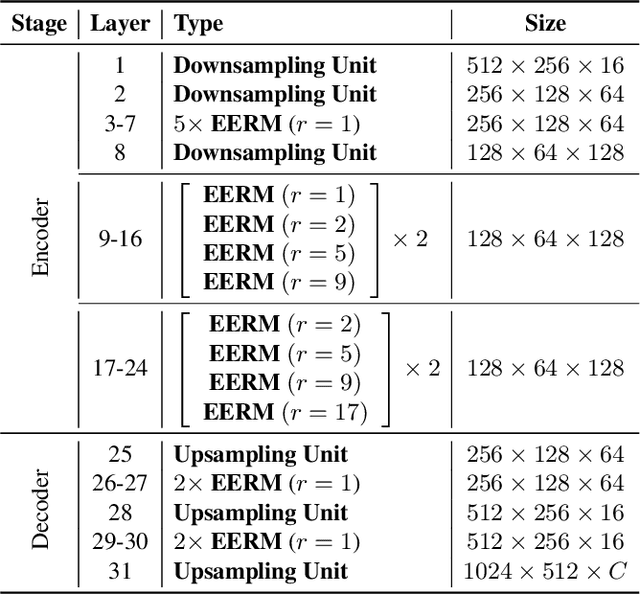

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single GTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.