 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOG-Mapping: Octree-based Structured 3D Gaussians for Online Dense Mapping
Aug 30, 2024



3D Gaussian splatting (3DGS) has recently demonstrated promising advancements in RGB-D online dense mapping. Nevertheless, existing methods excessively rely on per-pixel depth cues to perform map densification, which leads to significant redundancy and increased sensitivity to depth noise. Additionally, explicitly storing 3D Gaussian parameters of room-scale scene poses a significant storage challenge. In this paper, we introduce OG-Mapping, which leverages the robust scene structural representation capability of sparse octrees, combined with structured 3D Gaussian representations, to achieve efficient and robust online dense mapping. Moreover, OG-Mapping employs an anchor-based progressive map refinement strategy to recover the scene structures at multiple levels of detail. Instead of maintaining a small number of active keyframes with a fixed keyframe window as previous approaches do, a dynamic keyframe window is employed to allow OG-Mapping to better tackle false local minima and forgetting issues. Experimental results demonstrate that OG-Mapping delivers more robust and superior realism mapping results than existing Gaussian-based RGB-D online mapping methods with a compact model, and no additional post-processing is required.
PGNeXt: High-Resolution Salient Object Detection via Pyramid Grafting Network
Aug 02, 2024



We present an advanced study on more challenging high-resolution salient object detection (HRSOD) from both dataset and network framework perspectives. To compensate for the lack of HRSOD dataset, we thoughtfully collect a large-scale high resolution salient object detection dataset, called UHRSD, containing 5,920 images from real-world complex scenarios at 4K-8K resolutions. All the images are finely annotated in pixel-level, far exceeding previous low-resolution SOD datasets. Aiming at overcoming the contradiction between the sampling depth and the receptive field size in the past methods, we propose a novel one-stage framework for HR-SOD task using pyramid grafting mechanism. In general, transformer-based and CNN-based backbones are adopted to extract features from different resolution images independently and then these features are grafted from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different branches. Comprehensive experiments on UHRSD and widely-used SOD datasets demonstrate that our method can simultaneously locate salient object and preserve rich details, outperforming state-of-the-art methods. To verify the generalization ability of the proposed framework, we apply it to the camouflaged object detection (COD) task. Notably, our method performs superior to most state-of-the-art COD methods without bells and whistles.
Towards Unbalanced Motion: Part-Decoupling Network for Video Portrait Segmentation
Jul 31, 2023Video portrait segmentation (VPS), aiming at segmenting prominent foreground portraits from video frames, has received much attention in recent years. However, simplicity of existing VPS datasets leads to a limitation on extensive research of the task. In this work, we propose a new intricate large-scale Multi-scene Video Portrait Segmentation dataset MVPS consisting of 101 video clips in 7 scenario categories, in which 10,843 sampled frames are finely annotated at pixel level. The dataset has diverse scenes and complicated background environments, which is the most complex dataset in VPS to our best knowledge. Through the observation of a large number of videos with portraits during dataset construction, we find that due to the joint structure of human body, motion of portraits is part-associated, which leads that different parts are relatively independent in motion. That is, motion of different parts of the portraits is unbalanced. Towards this unbalance, an intuitive and reasonable idea is that different motion states in portraits can be better exploited by decoupling the portraits into parts. To achieve this, we propose a Part-Decoupling Network (PDNet) for video portrait segmentation. Specifically, an Inter-frame Part-Discriminated Attention (IPDA) module is proposed which unsupervisely segments portrait into parts and utilizes different attentiveness on discriminative features specified to each different part. In this way, appropriate attention can be imposed to portrait parts with unbalanced motion to extract part-discriminated correlations, so that the portraits can be segmented more accurately. Experimental results demonstrate that our method achieves leading performance with the comparison to state-of-the-art methods.
Rethinking Lightweight Salient Object Detection via Network Depth-Width Tradeoff
Jan 17, 2023Existing salient object detection methods often adopt deeper and wider networks for better performance, resulting in heavy computational burden and slow inference speed. This inspires us to rethink saliency detection to achieve a favorable balance between efficiency and accuracy. To this end, we design a lightweight framework while maintaining satisfying competitive accuracy. Specifically, we propose a novel trilateral decoder framework by decoupling the U-shape structure into three complementary branches, which are devised to confront the dilution of semantic context, loss of spatial structure and absence of boundary detail, respectively. Along with the fusion of three branches, the coarse segmentation results are gradually refined in structure details and boundary quality. Without adding additional learnable parameters, we further propose Scale-Adaptive Pooling Module to obtain multi-scale receptive filed. In particular, on the premise of inheriting this framework, we rethink the relationship among accuracy, parameters and speed via network depth-width tradeoff. With these insightful considerations, we comprehensively design shallower and narrower models to explore the maximum potential of lightweight SOD. Our models are purposed for different application environments: 1) a tiny version CTD-S (1.7M, 125FPS) for resource constrained devices, 2) a fast version CTD-M (12.6M, 158FPS) for speed-demanding scenarios, 3) a standard version CTD-L (26.5M, 84FPS) for high-performance platforms. Extensive experiments validate the superiority of our method, which achieves better efficiency-accuracy balance across five benchmarks.
View-aware Salient Object Detection for 360° Omnidirectional Image
Sep 27, 2022
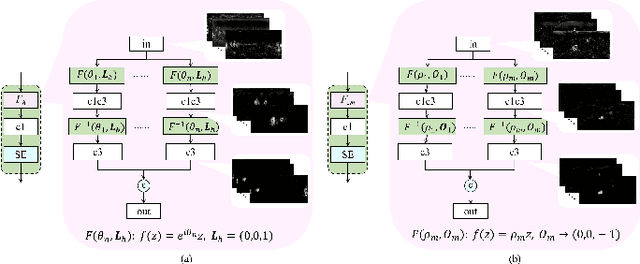

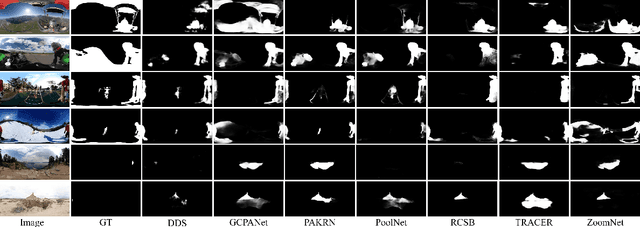
Image-based salient object detection (ISOD) in 360{\deg} scenarios is significant for understanding and applying panoramic information. However, research on 360{\deg} ISOD has not been widely explored due to the lack of large, complex, high-resolution, and well-labeled datasets. Towards this end, we construct a large scale 360{\deg} ISOD dataset with object-level pixel-wise annotation on equirectangular projection (ERP), which contains rich panoramic scenes with not less than 2K resolution and is the largest dataset for 360{\deg} ISOD by far to our best knowledge. By observing the data, we find current methods face three significant challenges in panoramic scenarios: diverse distortion degrees, discontinuous edge effects and changeable object scales. Inspired by humans' observing process, we propose a view-aware salient object detection method based on a Sample Adaptive View Transformer (SAVT) module with two sub-modules to mitigate these issues. Specifically, the sub-module View Transformer (VT) contains three transform branches based on different kinds of transformations to learn various features under different views and heighten the model's feature toleration of distortion, edge effects and object scales. Moreover, the sub-module Sample Adaptive Fusion (SAF) is to adjust the weights of different transform branches based on various sample features and make transformed enhanced features fuse more appropriately. The benchmark results of 20 state-of-the-art ISOD methods reveal the constructed dataset is very challenging. Moreover, exhaustive experiments verify the proposed approach is practical and outperforms the state-of-the-art methods.
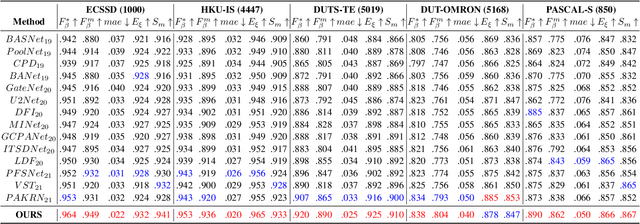
Pyramid Grafting Network for One-Stage High Resolution Saliency Detection
Apr 12, 2022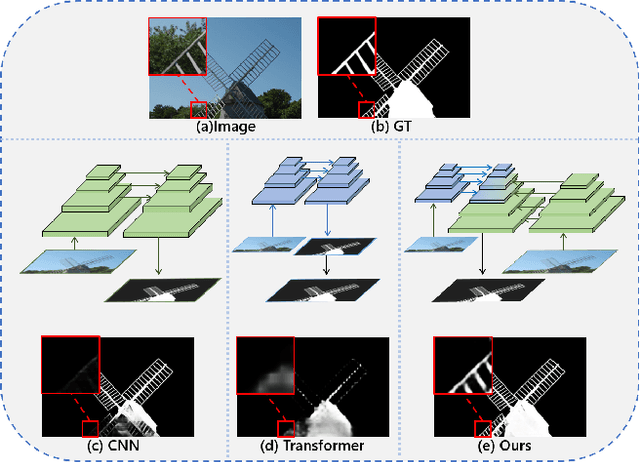
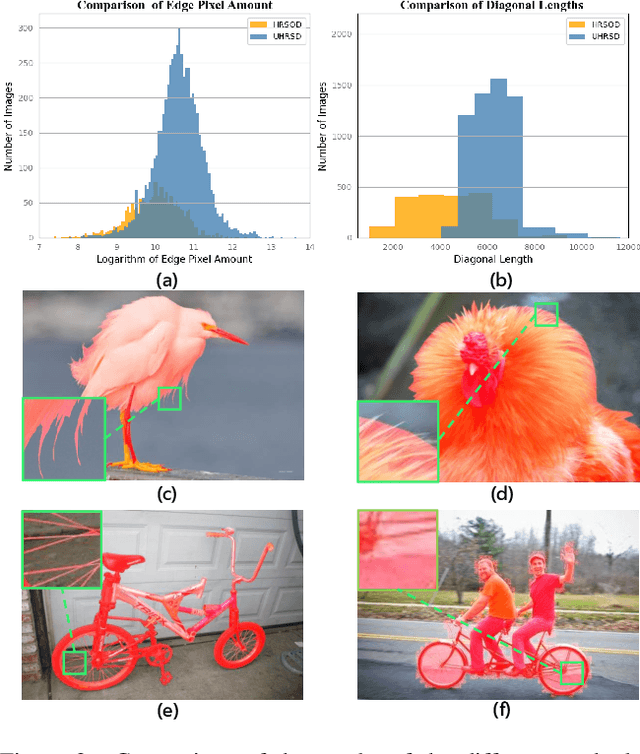

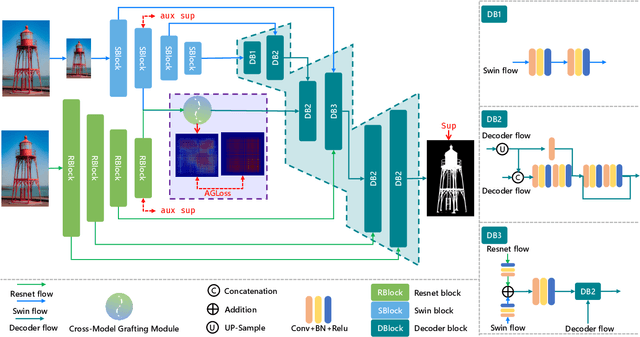
Recent salient object detection (SOD) methods based on deep neural network have achieved remarkable performance. However, most of existing SOD models designed for low-resolution input perform poorly on high-resolution images due to the contradiction between the sampling depth and the receptive field size. Aiming at resolving this contradiction, we propose a novel one-stage framework called Pyramid Grafting Network (PGNet), using transformer and CNN backbone to extract features from different resolution images independently and then graft the features from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different models. We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5,920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task, which can be used for training and testing in future research. Sufficient experiments on UHRSD and widely-used SOD datasets demonstrate that our method achieves superior performance compared to the state-of-the-art methods.
Receptive Field Broadening and Boosting for Salient Object Detection
Oct 15, 2021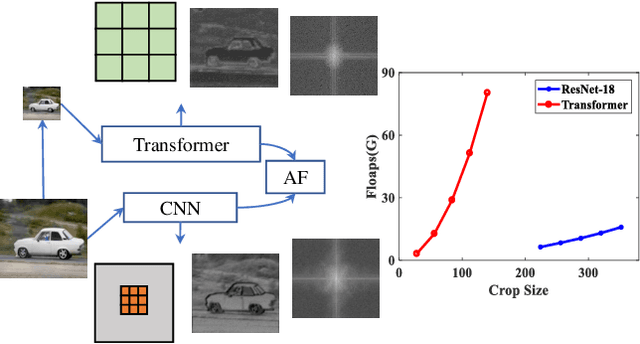
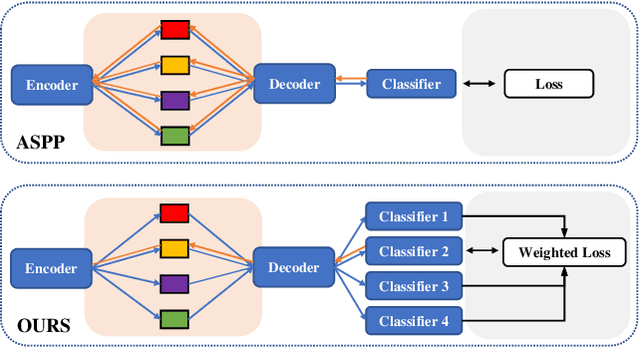
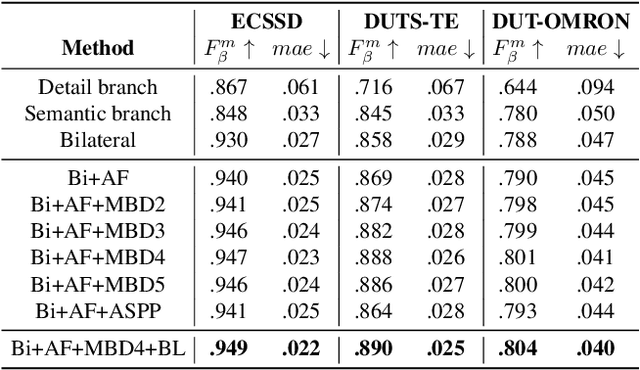
Salient object detection requires a comprehensive and scalable receptive field to locate the visually significant objects in the image. Recently, the emergence of visual transformers and multi-branch modules has significantly enhanced the ability of neural networks to perceive objects at different scales. However, compared to the traditional backbone, the calculation process of transformers is time-consuming. Moreover, different branches of the multi-branch modules could cause the same error back propagation in each training iteration, which is not conducive to extracting discriminative features. To solve these problems, we propose a bilateral network based on transformer and CNN to efficiently broaden local details and global semantic information simultaneously. Besides, a Multi-Head Boosting (MHB) strategy is proposed to enhance the specificity of different network branches. By calculating the errors of different prediction heads, each branch can separately pay more attention to the pixels that other branches predict incorrectly. Moreover, Unlike multi-path parallel training, MHB randomly selects one branch each time for gradient back propagation in a boosting way. Additionally, an Attention Feature Fusion Module (AF) is proposed to fuse two types of features according to respective characteristics. Comprehensive experiments on five benchmark datasets demonstrate that the proposed method can achieve a significant performance improvement compared with the state-of-the-art methods.
Exploring Driving-aware Salient Object Detection via Knowledge Transfer
May 18, 2021
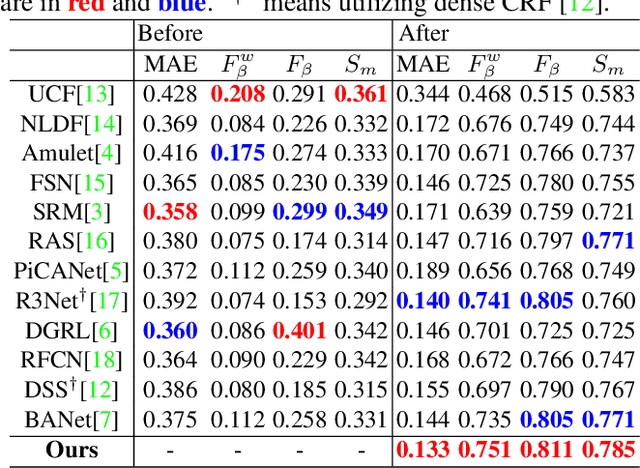

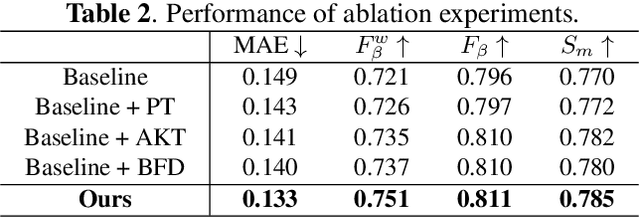
Recently, general salient object detection (SOD) has made great progress with the rapid development of deep neural networks. However, task-aware SOD has hardly been studied due to the lack of task-specific datasets. In this paper, we construct a driving task-oriented dataset where pixel-level masks of salient objects have been annotated. Comparing with general SOD datasets, we find that the cross-domain knowledge difference and task-specific scene gap are two main challenges to focus the salient objects when driving. Inspired by these findings, we proposed a baseline model for the driving task-aware SOD via a knowledge transfer convolutional neural network. In this network, we construct an attentionbased knowledge transfer module to make up the knowledge difference. In addition, an efficient boundary-aware feature decoding module is introduced to perform fine feature decoding for objects in the complex task-specific scenes. The whole network integrates the knowledge transfer and feature decoding modules in a progressive manner. Experiments show that the proposed dataset is very challenging, and the proposed method outperforms 12 state-of-the-art methods on the dataset, which facilitates the development of task-aware SOD.
Salient Object Detection with Purificatory Mechanism and Structural Similarity Loss
Dec 18, 2019

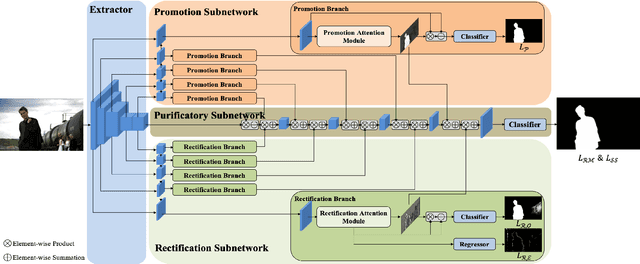
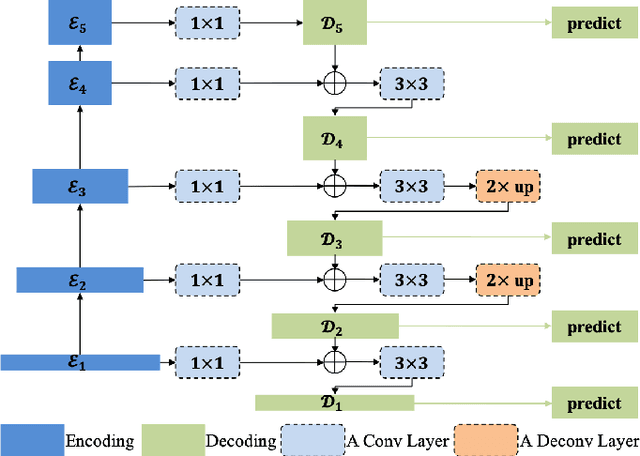
By the aid of attention mechanisms to weight the image features adaptively, recent advanced deep learning-based salient object detection models encourage the predicted results to approximate the ground-truth masks with as large predictable areas as possible. However, these methods do not pay enough attention to small areas prone to misprediction. In this way, it is still tough to accurately locate salient objects due to the existence of regions with indistinguishable foreground and background and regions with complex or fine structures. To address these problems, we propose a novel network with purificatory mechanism and structural similarity loss. Specifically, in order to better locate preliminary salient objects, we first introduce the promotion attention, which is based on spatial and channel attention mechanisms to promote attention to salient regions. Subsequently, for the purpose of restoring the indistinguishable regions that can be regarded as error-prone regions of one model, we propose the rectification attention, which is learned from the areas of wrong prediction and guide the network to focus on error-prone regions thus rectifying errors. Through these two attentions, we use the Purificatory Mechanism to impose strict weights with different regions of the whole salient objects and purify results from hard-to-distinguish regions, thus accurately predicting the locations and details of salient objects. In addition to paying different attention to these hard-to-distinguish regions, we also consider the structural constraints on complex regions and propose the Structural Similarity Loss. The proposed loss models the region-level pair-wise relationship between regions to assist these regions to calibrate their own saliency values. In experiments, the proposed approach efficiently outperforms 19 state-of-the-art methods on six datasets with a notable margin.
Exploring Reciprocal Attention for Salient Object Detection by Cooperative Learning
Sep 18, 2019
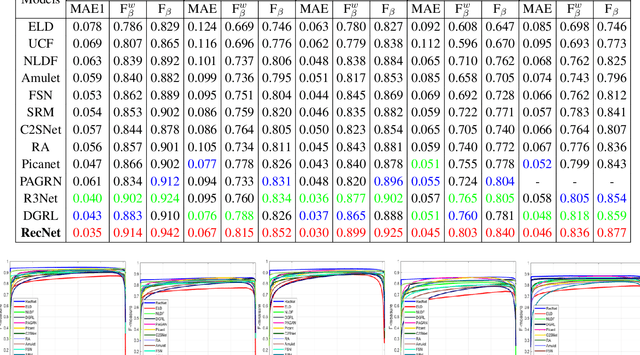
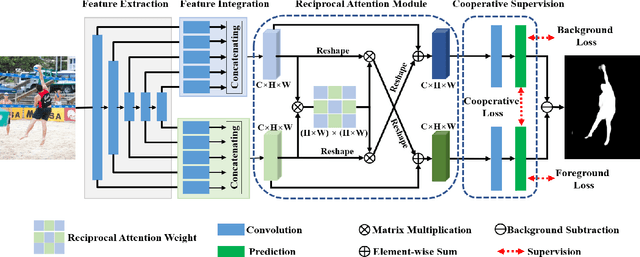
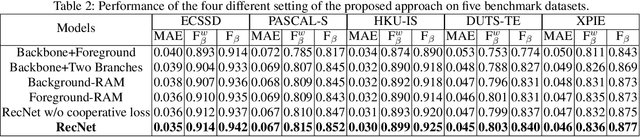
Typically, objects with the same semantics are not always prominent in images containing different backgrounds. Motivated by this observation that accurately salient object detection is related to both foreground and background, we proposed a novel cooperative attention mechanism that jointly considers reciprocal relationships between background and foreground for efficient salient object detection. Concretely, we first aggregate the features at each side-out of traditional dilated FCN to extract the initial foreground and background local responses respectively. Then taking these responses as input, reciprocal attention module adaptively models the nonlocal dependencies between any two pixels of the foreground and background features, which is then aggregated with local features in a mutual reinforced way so as to enhance each branch to generate more discriminative foreground and background saliency map. Besides, cooperative losses are particularly designed to guide the multi-task learning of foreground and background branches, which encourages our network to obtain more complementary predictions with clear boundaries. At last, a simple but effective fusion strategy is utilized to produce the final saliency map. Comprehensive experimental results on five benchmark datasets demonstrate that our proposed method performs favorably against the state-of-the-art approaches in terms of all compared evaluation metrics.