 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GridMask Data Augmentation
Jan 13, 2020
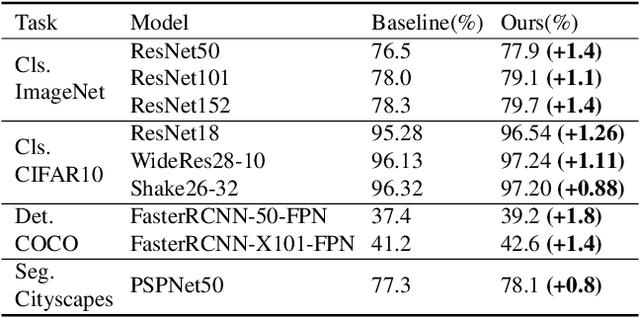



We propose a novel data augmentation method `GridMask' in this paper. It utilizes information removal to achieve state-of-the-art results in a variety of computer vision tasks. We analyze the requirement of information dropping. Then we show limitation of existing information dropping algorithms and propose our structured method, which is simple and yet very effective. It is based on the deletion of regions of the input image. Our extensive experiments show that our method outperforms the latest AutoAugment, which is way more computationally expensive due to the use of reinforcement learning to find the best policies. On the ImageNet dataset for recognition, COCO2017 object detection, and on Cityscapes dataset for semantic segmentation, our method all notably improves performance over baselines. The extensive experiments manifest the effectiveness and generality of the new method.
SuperPatchMatch: an Algorithm for Robust Correspondences using Superpixel Patches
Mar 17, 2019
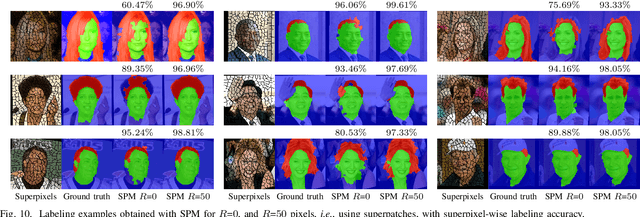

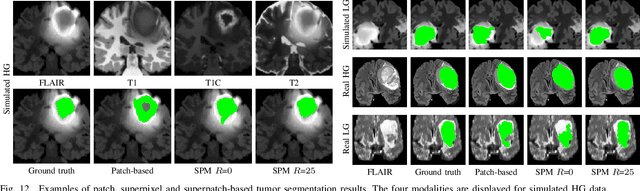
Superpixels have become very popular in many computer vision applications. Nevertheless, they remain underexploited since the superpixel decomposition may produce irregular and non stable segmentation results due to the dependency to the image content. In this paper, we first introduce a novel structure, a superpixel-based patch, called SuperPatch. The proposed structure, based on superpixel neighborhood, leads to a robust descriptor since spatial information is naturally included. The generalization of the PatchMatch method to SuperPatches, named SuperPatchMatch, is introduced. Finally, we propose a framework to perform fast segmentation and labeling from an image database, and demonstrate the potential of our approach since we outperform, in terms of computational cost and accuracy, the results of state-of-the-art methods on both face labeling and medical image segmentation.
Compressive MRI quantification using convex spatiotemporal priors and deep auto-encoders
Jan 23, 2020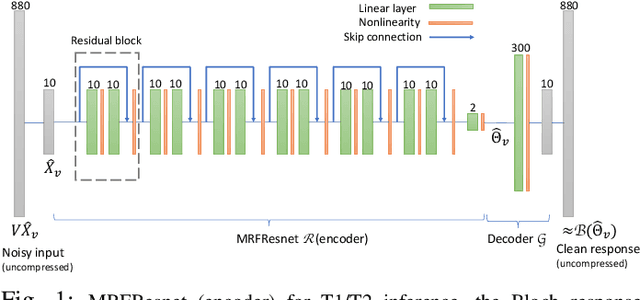
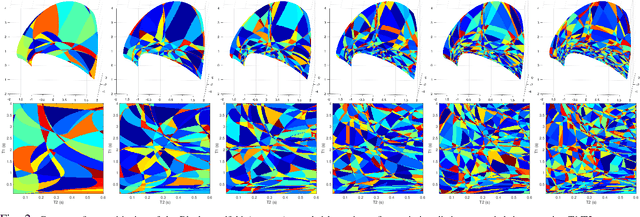
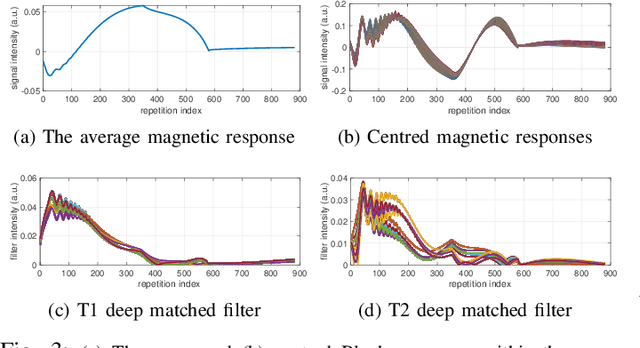
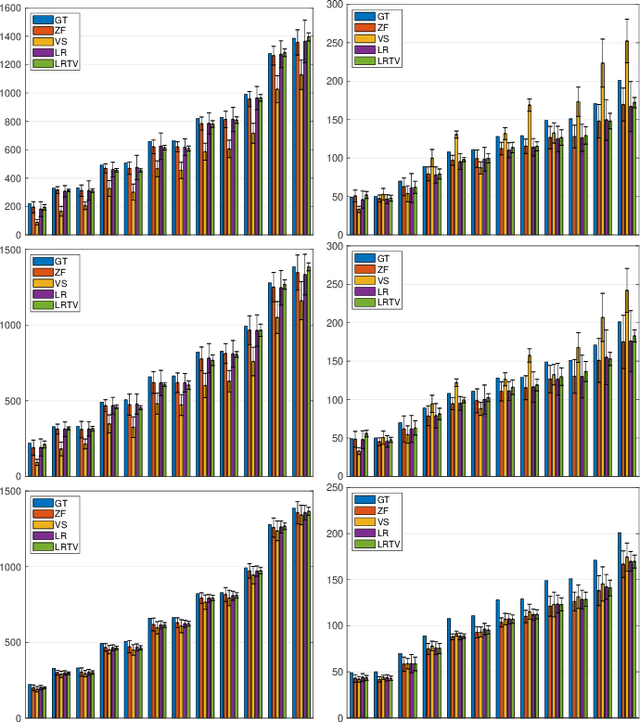
We propose a dictionary-matching-free pipeline for multi-parametric quantitative MRI image computing. Our approach has two stages based on compressed sensing reconstruction and deep learned quantitative inference. The reconstruction phase is convex and incorporates efficient spatiotemporal regularisations within an accelerated iterative shrinkage algorithm. This minimises the under-sampling (aliasing) artefacts from aggressively short scan times. The learned quantitative inference phase is purely trained on physical simulations (Bloch equations) that are flexible for producing rich training samples. We propose a deep and compact auto-encoder network with residual blocks in order to embed Bloch manifold projections through multiscale piecewise affine approximations, and to replace the nonscalable dictionary-matching baseline. Tested on a number of datasets we demonstrate effectiveness of the proposed scheme for recovering accurate and consistent quantitative information from novel and aggressively subsampled 2D/3D quantitative MRI acquisition protocols.
Answering Image Riddles using Vision and Reasoning through Probabilistic Soft Logic
Nov 17, 2016

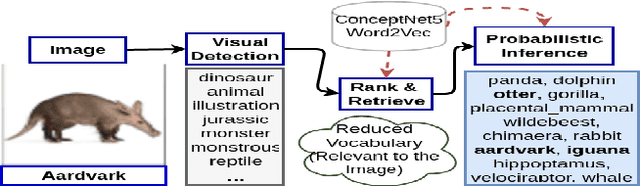
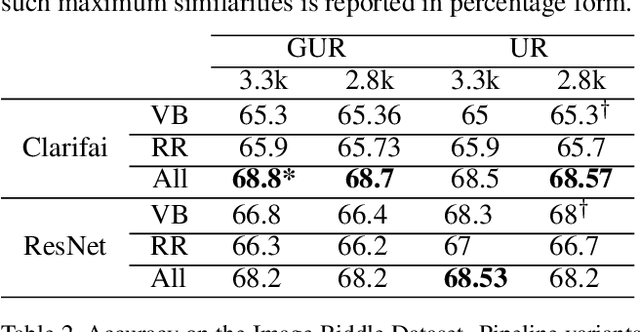
In this work, we explore a genre of puzzles ("image riddles") which involves a set of images and a question. Answering these puzzles require both capabilities involving visual detection (including object, activity recognition) and, knowledge-based or commonsense reasoning. We compile a dataset of over 3k riddles where each riddle consists of 4 images and a groundtruth answer. The annotations are validated using crowd-sourced evaluation. We also define an automatic evaluation metric to track future progress. Our task bears similarity with the commonly known IQ tasks such as analogy solving, sequence filling that are often used to test intelligence. We develop a Probabilistic Reasoning-based approach that utilizes probabilistic commonsense knowledge to answer these riddles with a reasonable accuracy. We demonstrate the results of our approach using both automatic and human evaluations. Our approach achieves some promising results for these riddles and provides a strong baseline for future attempts. We make the entire dataset and related materials publicly available to the community in ImageRiddle Website (http://bit.ly/22f9Ala).
Facial Emotion Recognition Using Deep Learning
Oct 19, 2019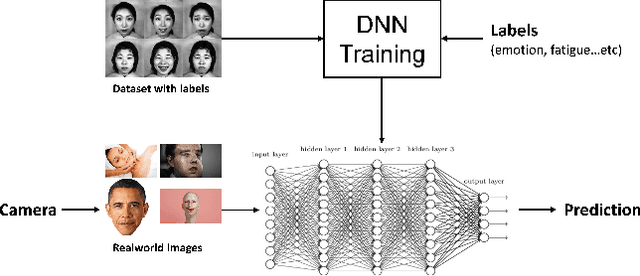
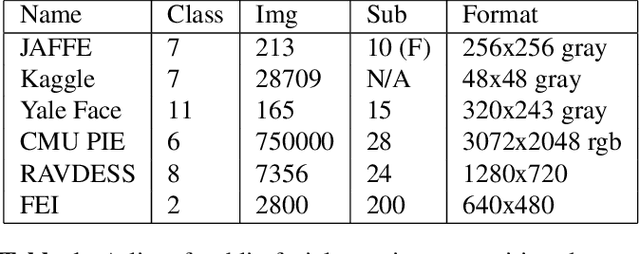
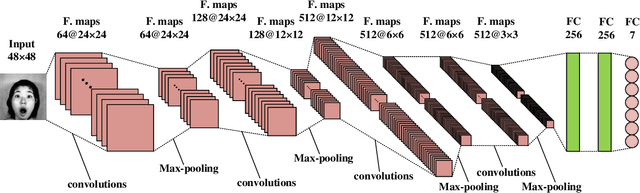
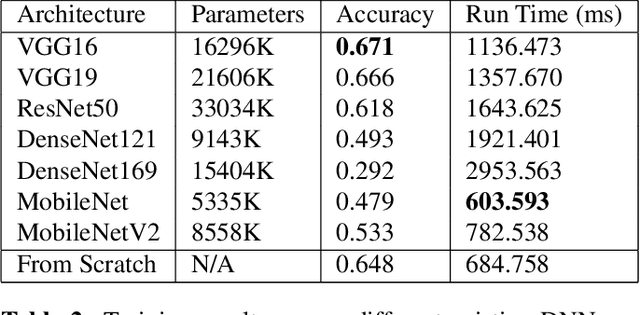
We aim to construct a system that captures real-world facial images through the front camera on a laptop. The system is capable of processing/recognizing the captured image and predict a result in real-time. In this system, we exploit the power of deep learning technique to learn a facial emotion recognition (FER) model based on a set of labeled facial images. Finally, experiments are conducted to evaluate our model using largely used public database.
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
Mar 16, 2020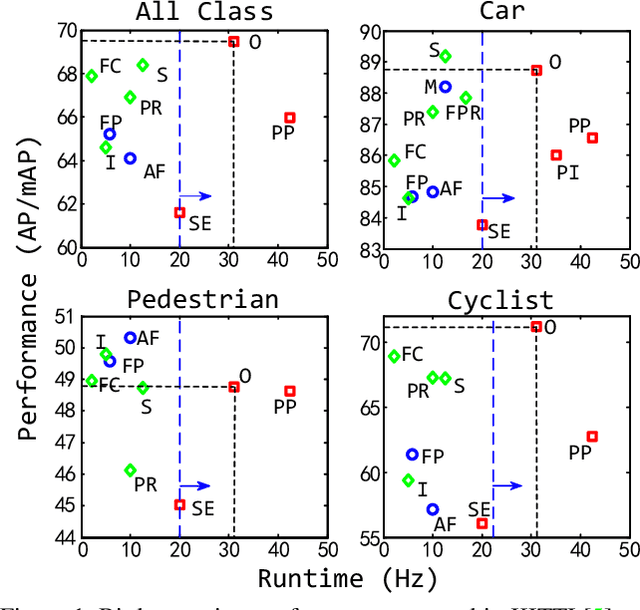
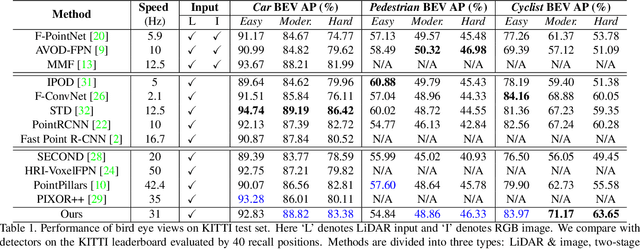
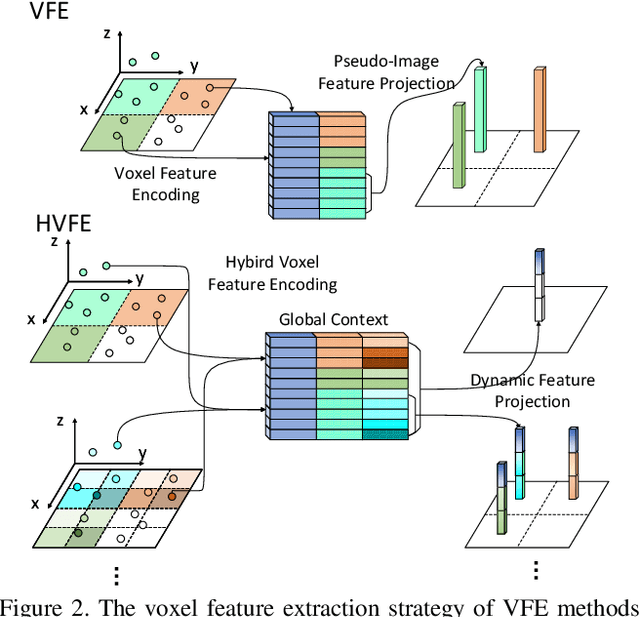
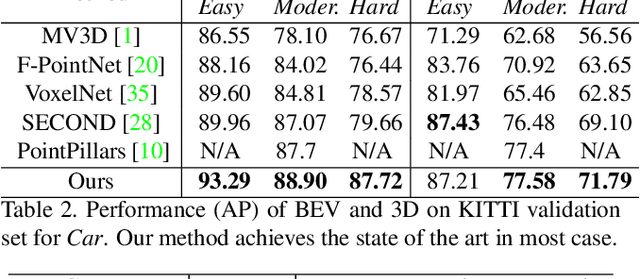
We present Hybrid Voxel Network (HVNet), a novel one-stage unified network for point cloud based 3D object detection for autonomous driving. Recent studies show that 2D voxelization with per voxel PointNet style feature extractor leads to accurate and efficient detector for large 3D scenes. Since the size of the feature map determines the computation and memory cost, the size of the voxel becomes a parameter that is hard to balance. A smaller voxel size gives a better performance, especially for small objects, but a longer inference time. A larger voxel can cover the same area with a smaller feature map, but fails to capture intricate features and accurate location for smaller objects. We present a Hybrid Voxel network that solves this problem by fusing voxel feature encoder (VFE) of different scales at point-wise level and project into multiple pseudo-image feature maps. We further propose an attentive voxel feature encoding that outperforms plain VFE and a feature fusion pyramid network to aggregate multi-scale information at feature map level. Experiments on the KITTI benchmark show that a single HVNet achieves the best mAP among all existing methods with a real time inference speed of 31Hz.
Neural Pose Transfer by Spatially Adaptive Instance Normalization
Mar 16, 2020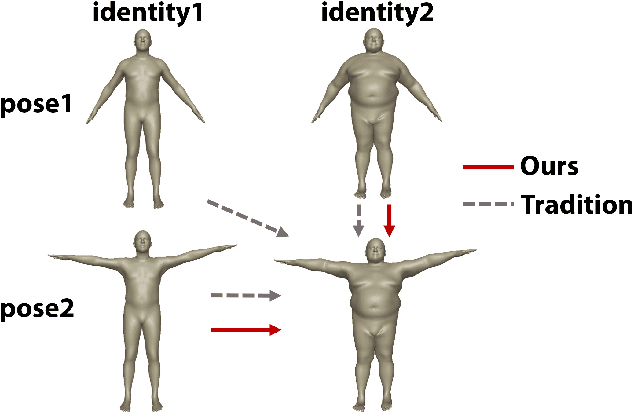
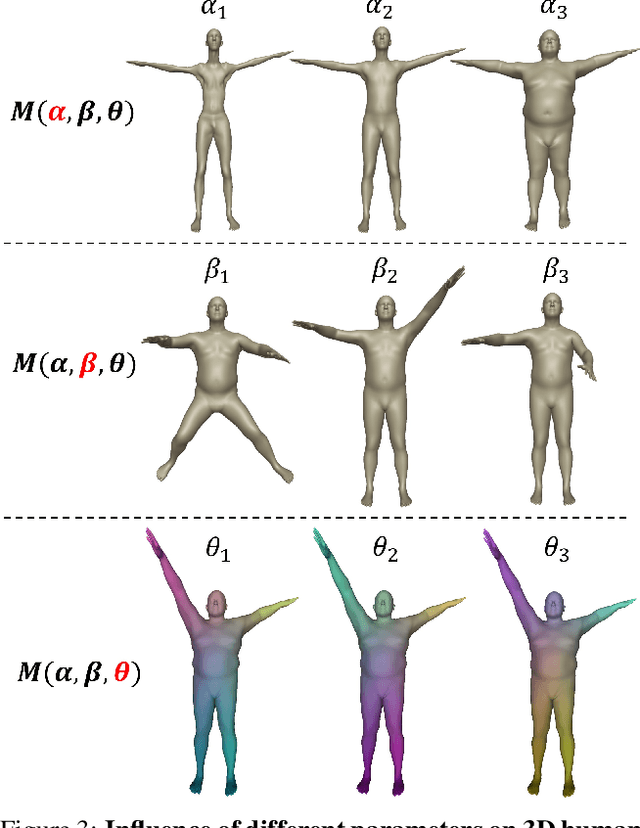

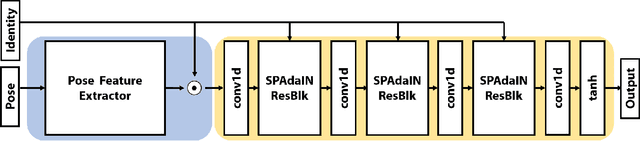
Pose transfer has been studied for decades, in which the pose of a source mesh is applied to a target mesh. Particularly in this paper, we are interested in transferring the pose of source human mesh to deform the target human mesh, while the source and target meshes may have different identity information. Traditional studies assume that the paired source and target meshes are existed with the point-wise correspondences of user annotated landmarks/mesh points, which requires heavy labelling efforts. On the other hand, the generalization ability of deep models is limited, when the source and target meshes have different identities. To break this limitation, we proposes the first neural pose transfer model that solves the pose transfer via the latest technique for image style transfer, leveraging the newly proposed component -- spatially adaptive instance normalization. Our model does not require any correspondences between the source and target meshes. Extensive experiments show that the proposed model can effectively transfer deformation from source to target meshes, and has good generalization ability to deal with unseen identities or poses of meshes. Code is available at https://github.com/jiashunwang/Neural-Pose-Transfer .
Bayesian Image Restoration for Poisson Corrupted Image using a Latent Variational Method with Gaussian MRF
Dec 07, 2014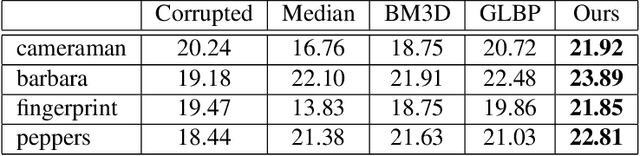


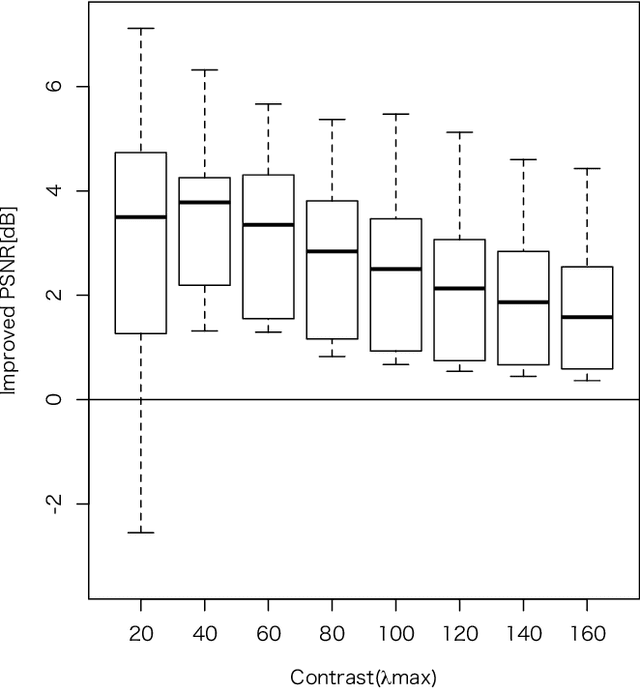
We treat an image restoration problem with a Poisson noise chan- nel using a Bayesian framework. The Poisson randomness might be appeared in observation of low contrast object in the field of imaging. The noise observation is often hard to treat in a theo- retical analysis. In our formulation, we interpret the observation through the Poisson noise channel as a likelihood, and evaluate the bound of it with a Gaussian function using a latent variable method. We then introduce a Gaussian Markov random field (GMRF) as the prior for the Bayesian approach, and derive the posterior as a Gaussian distribution. The latent parameters in the likelihood and the hyperparameter in the GMRF prior could be treated as hid- den parameters, so that, we propose an algorithm to infer them in the expectation maximization (EM) framework using loopy belief propagation(LBP). We confirm the ability of our algorithm in the computer simulation, and compare it with the results of other im- age restoration frameworks.
Learning Oracle Attention for High-fidelity Face Completion
Mar 31, 2020
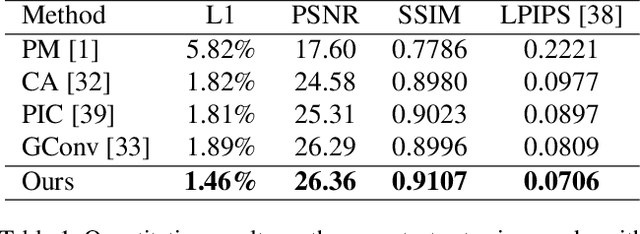
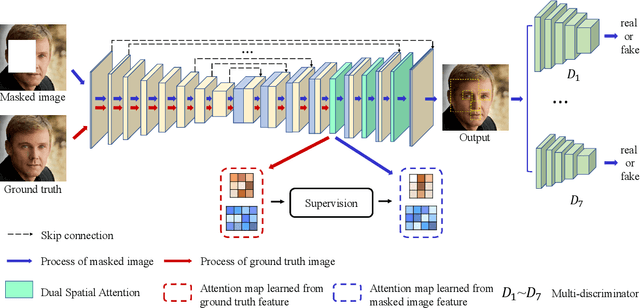

High-fidelity face completion is a challenging task due to the rich and subtle facial textures involved. What makes it more complicated is the correlations between different facial components, for example, the symmetry in texture and structure between both eyes. While recent works adopted the attention mechanism to learn the contextual relations among elements of the face, they have largely overlooked the disastrous impacts of inaccurate attention scores; in addition, they fail to pay sufficient attention to key facial components, the completion results of which largely determine the authenticity of a face image. Accordingly, in this paper, we design a comprehensive framework for face completion based on the U-Net structure. Specifically, we propose a dual spatial attention module to efficiently learn the correlations between facial textures at multiple scales; moreover, we provide an oracle supervision signal to the attention module to ensure that the obtained attention scores are reasonable. Furthermore, we take the location of the facial components as prior knowledge and impose a multi-discriminator on these regions, with which the fidelity of facial components is significantly promoted. Extensive experiments on two high-resolution face datasets including CelebA-HQ and Flickr-Faces-HQ demonstrate that the proposed approach outperforms state-of-the-art methods by large margins.
Aggregated Learning: A Vector-Quantization Approach to Learning Neural Network Classifiers
Jan 12, 2020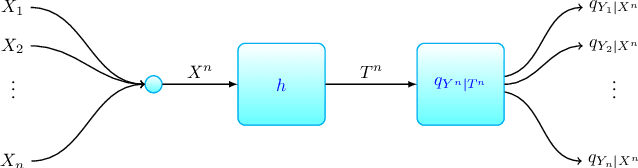


We consider the problem of learning a neural network classifier. Under the information bottleneck (IB) principle, we associate with this classification problem a representation learning problem, which we call "IB learning". We show that IB learning is, in fact, equivalent to a special class of the quantization problem. The classical results in rate-distortion theory then suggest that IB learning can benefit from a "vector quantization" approach, namely, simultaneously learning the representations of multiple input objects. Such an approach assisted with some variational techniques, result in a novel learning framework, "Aggregated Learning", for classification with neural network models. In this framework, several objects are jointly classified by a single neural network. The effectiveness of this framework is verified through extensive experiments on standard image recognition and text classification tasks.