 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Simulate Dynamic Environments with GameGAN
May 25, 2020

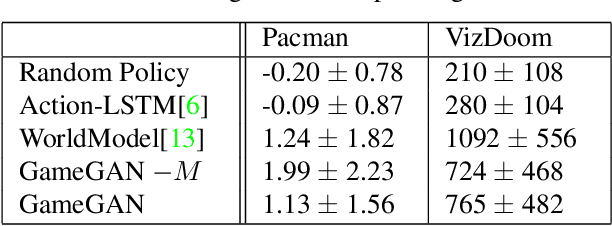
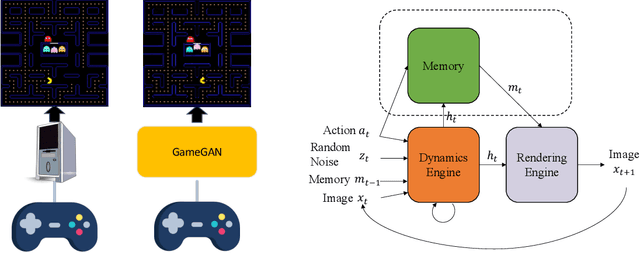

Simulation is a crucial component of any robotic system. In order to simulate correctly, we need to write complex rules of the environment: how dynamic agents behave, and how the actions of each of the agents affect the behavior of others. In this paper, we aim to learn a simulator by simply watching an agent interact with an environment. We focus on graphics games as a proxy of the real environment. We introduce GameGAN, a generative model that learns to visually imitate a desired game by ingesting screenplay and keyboard actions during training. Given a key pressed by the agent, GameGAN "renders" the next screen using a carefully designed generative adversarial network. Our approach offers key advantages over existing work: we design a memory module that builds an internal map of the environment, allowing for the agent to return to previously visited locations with high visual consistency. In addition, GameGAN is able to disentangle static and dynamic components within an image making the behavior of the model more interpretable, and relevant for downstream tasks that require explicit reasoning over dynamic elements. This enables many interesting applications such as swapping different components of the game to build new games that do not exist.
Privileged Pooling: Supervised attention-based pooling for compensating dataset bias
Mar 23, 2020
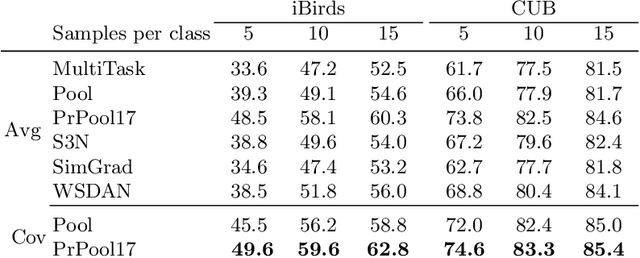
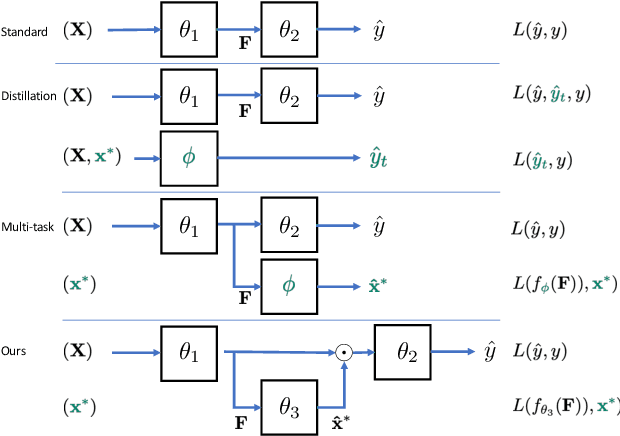
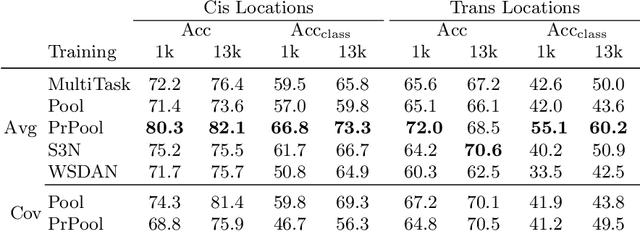
In this paper we propose a novel supervised image classification method that overcomes dataset bias and scarcity of training data using privileged information in the form of keypoints annotations. Our main motivation is recognition of animal species for ecological applications like biodiversity modelling, which can be challenging due to long-tailed species distributions due to rare species, and strong dataset biases in repetitive scenes such as in camera traps. To counteract these challenges, we propose a weakly-supervised visual attention mechanism that has access to keypoints highlighting the most important object parts. This privileged information, implemented via a novel privileged pooling operation, is only accessible during training and helps the model to focus on the regions that are most discriminative. We show that the proposed approach uses more efficiently small training datasets, generalizes better and outperforms competing methods in challenging training conditions.
Registering large volume serial-section electron microscopy image sets for neural circuit reconstruction using FFT signal whitening
Dec 14, 2016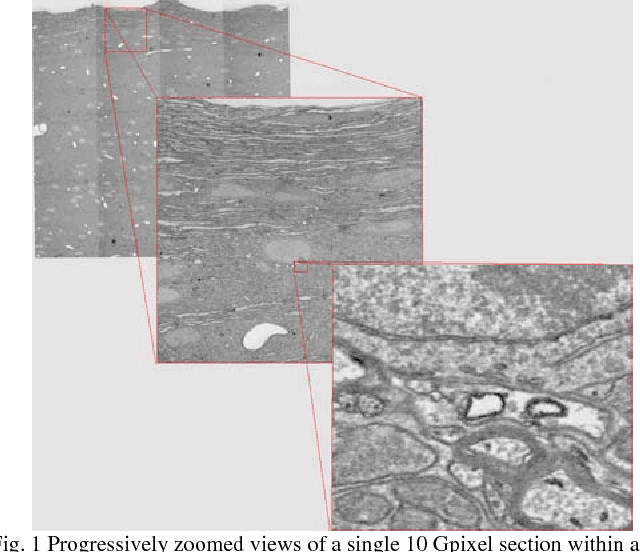
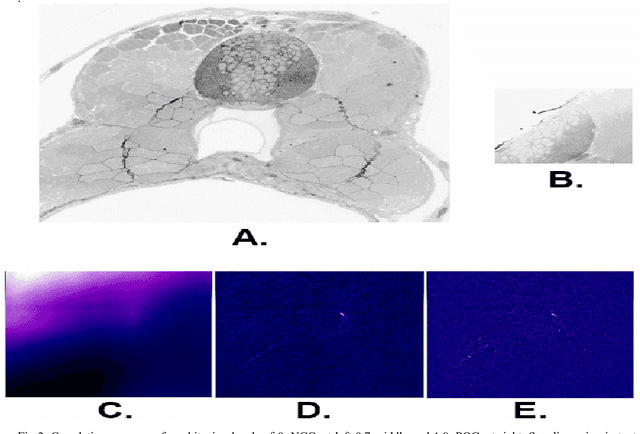
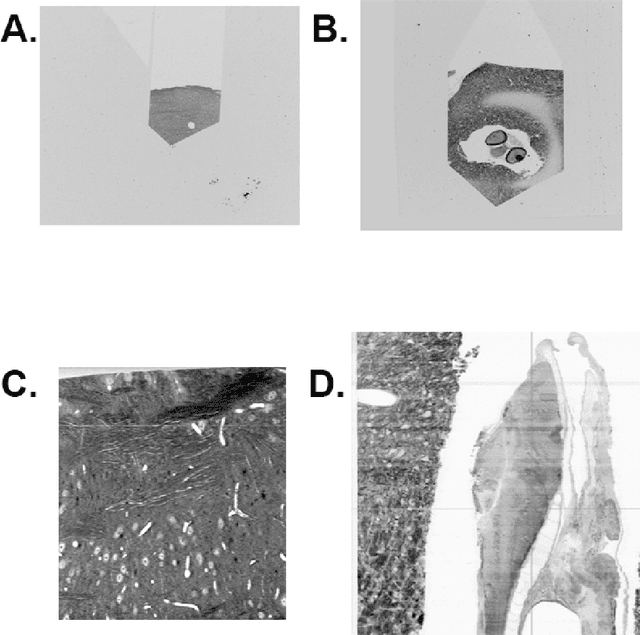
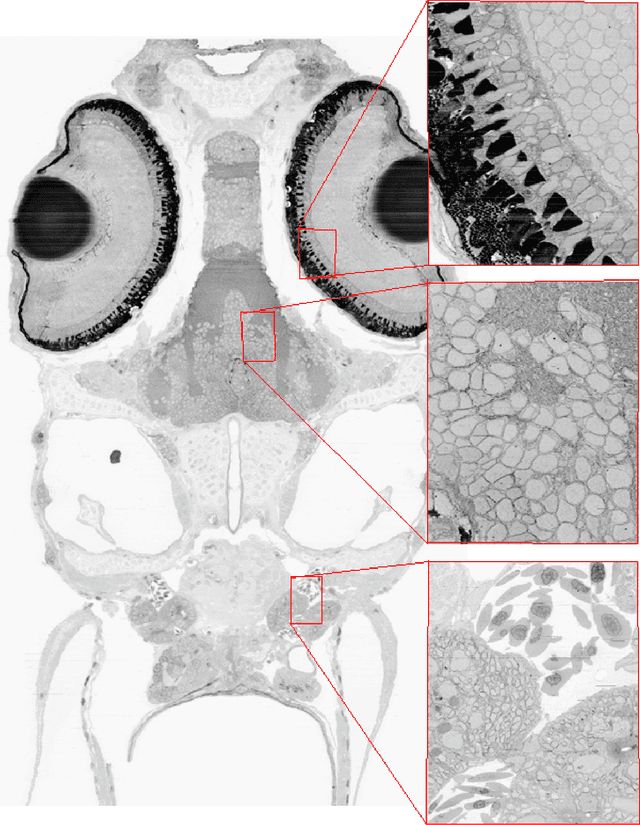
The detailed reconstruction of neural anatomy for connectomics studies requires a combination of resolution and large three-dimensional data capture provided by serial section electron microscopy (ssEM). The convergence of high throughput ssEM imaging and improved tissue preparation methods now allows ssEM capture of complete specimen volumes up to cubic millimeter scale. The resulting multi-terabyte image sets span thousands of serial sections and must be precisely registered into coherent volumetric forms in which neural circuits can be traced and segmented. This paper introduces a Signal Whitening Fourier Transform Image Registration approach (SWiFT-IR) under development at the Pittsburgh Supercomputing Center and its use to align mouse and zebrafish brain datasets acquired using the wafer mapper ssEM imaging technology recently developed at Harvard University. Unlike other methods now used for ssEM registration, SWiFT-IR modifies its spatial frequency response during image matching to maximize a signal-to-noise measure used as its primary indicator of alignment quality. This alignment signal is more robust to rapid variations in biological content and unavoidable data distortions than either phase-only or standard Pearson correlation, thus allowing more precise alignment and statistical confidence. These improvements in turn enable an iterative registration procedure based on projections through multiple sections rather than more typical adjacent-pair matching methods. This projection approach, when coupled with known anatomical constraints and iteratively applied in a multi-resolution pyramid fashion, drives the alignment into a smooth form that properly represents complex and widely varying anatomical content such as the full cross-section zebrafish data.
Top-1 Solution of Multi-Moments in Time Challenge 2019
Mar 13, 2020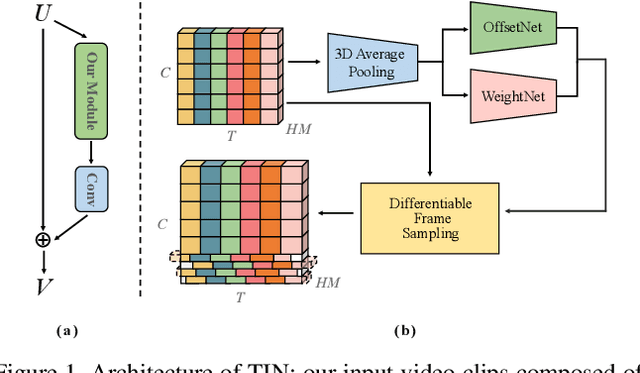
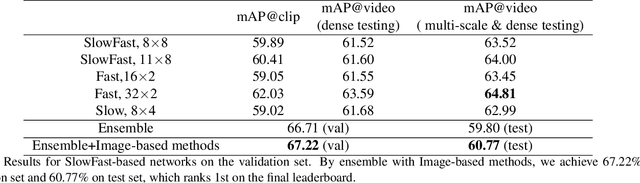
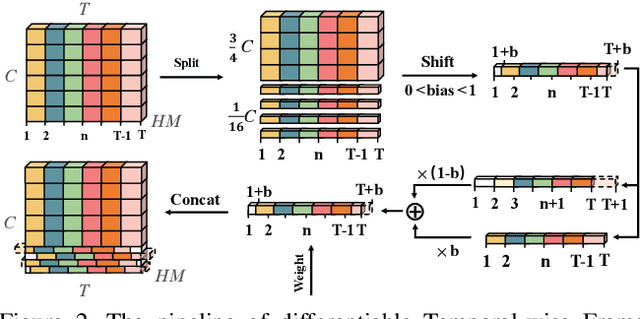
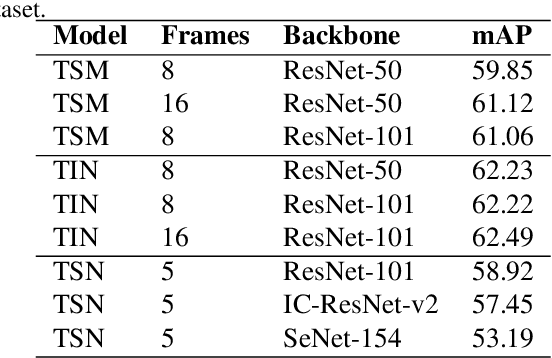
In this technical report, we briefly introduce the solutions of our team 'Efficient' for the Multi-Moments in Time challenge in ICCV 2019. We first conduct several experiments with popular Image-Based action recognition methods TRN, TSN, and TSM. Then a novel temporal interlacing network is proposed towards fast and accurate recognition. Besides, the SlowFast network and its variants are explored. Finally, we ensemble all the above models and achieve 67.22\% on the validation set and 60.77\% on the test set, which ranks 1st on the final leaderboard. In addition, we release a new code repository for video understanding which unifies state-of-the-art 2D and 3D methods based on PyTorch. The solution of the challenge is also included in the repository, which is available at https://github.com/Sense-X/X-Temporal.
Co-Saliency Spatio-Temporal Interaction Network for Person Re-Identification in Videos
Apr 10, 2020
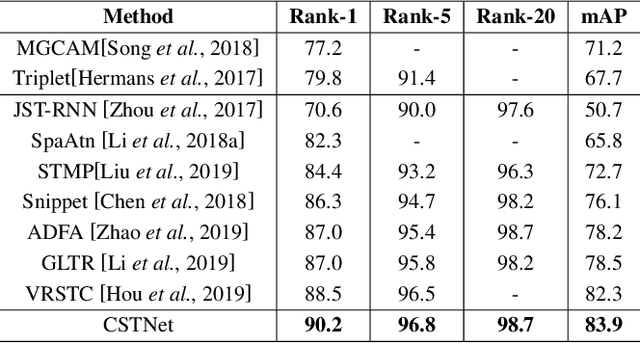
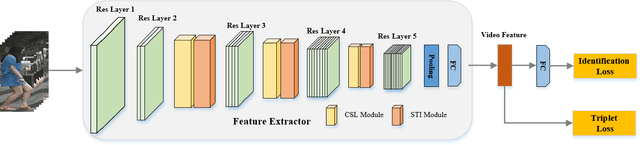
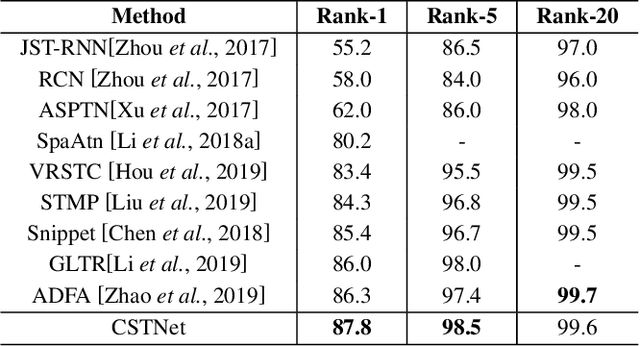
Person re-identification aims at identifying a certain pedestrian across non-overlapping camera networks. Video-based re-identification approaches have gained significant attention recently, expanding image-based approaches by learning features from multiple frames. In this work, we propose a novel Co-Saliency Spatio-Temporal Interaction Network (CSTNet) for person re-identification in videos. It captures the common salient foreground regions among video frames and explores the spatial-temporal long-range context interdependency from such regions, towards learning discriminative pedestrian representation. Specifically, multiple co-saliency learning modules within CSTNet are designed to utilize the correlated information across video frames to extract the salient features from the task-relevant regions and suppress background interference. Moreover, multiple spatialtemporal interaction modules within CSTNet are proposed, which exploit the spatial and temporal long-range context interdependencies on such features and spatial-temporal information correlation, to enhance feature representation. Extensive experiments on two benchmarks have demonstrated the effectiveness of the proposed method.
Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
Aug 03, 2019

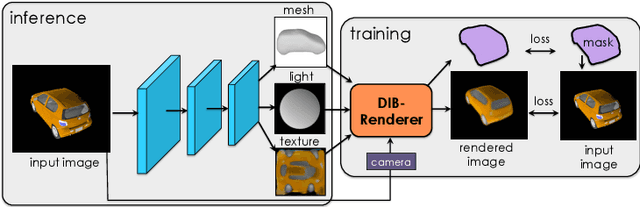

Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-R, a differentiable rendering framework which allows gradients to be analytically computed for all pixels in an image. Key to our approach is to view foreground rasterization as a weighted interpolation of local properties and background rasterization as an distance-based aggregation of global geometry. Our approach allows for accurate optimization over vertex positions, colors, normals, light directions and texture coordinates through a variety of lighting models. We showcase our approach in two ML applications: single-image 3D object prediction, and 3D textured object generation, both trained using exclusively using 2D supervision. Our project website is: https://nv-tlabs.github.io/DIB-R/
Comparing the Performance of L*A*B* and HSV Color Spaces with Respect to Color Image Segmentation
Jun 04, 2015Color image segmentation is a very emerging topic for image processing research. Since it has the ability to present the result in a way that is much more close to the human yes perceive, so todays more research is going on this area. Choosing a proper color space is a very important issue for color image segmentation process. Generally LAB and HSV are the two frequently chosen color spaces. In this paper a comparative analysis is performed between these two color spaces with respect to color image segmentation. For measuring their performance, we consider the parameters: mse and psnr . It is found that HSV color space is performing better than LAB.
Rectangular Pyramid Partitioning using Integrated Depth Sensors (RAPPIDS): A Fast Planner for Multicopter Navigation
Mar 02, 2020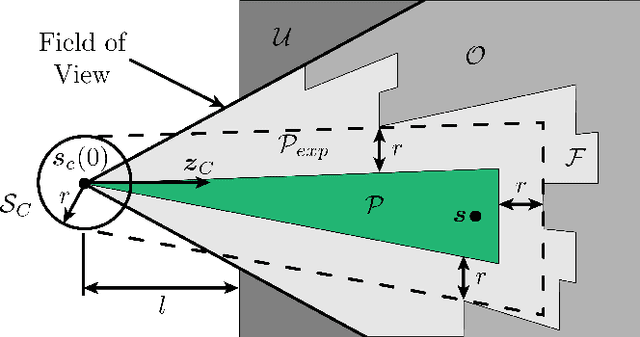


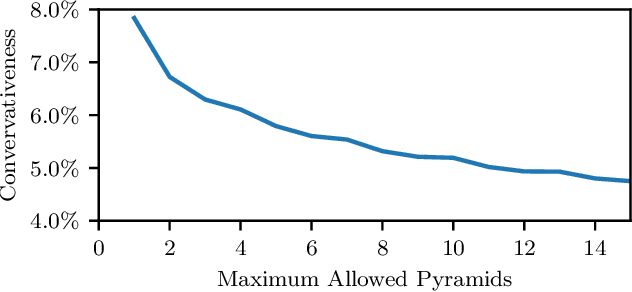
We present a novel multicopter trajectory planning algorithm (RAPPIDS) that is capable of quickly finding local collision-free trajectories given a single depth image from an onboard camera. The algorithm leverages a new pyramid-based spatial partitioning method that enables rapid collision detection between candidate trajectories and the environment. Due to its efficiency, the algorithm can be run at high rates on computationally constrained hardware, evaluating thousands of candidate trajectories in milliseconds. The performance of the algorithm is compared to existing collision checking methods in simulation, showing our method to be capable of evaluating orders of magnitude more trajectories per second. Experimental results are presented showing a quadcopter quickly navigating a previously unseen cluttered environment by running the algorithm on an ODROID-XU4 at 30 Hz.
An empirical study on the effects of different types of noise in image classification tasks
Sep 09, 2016
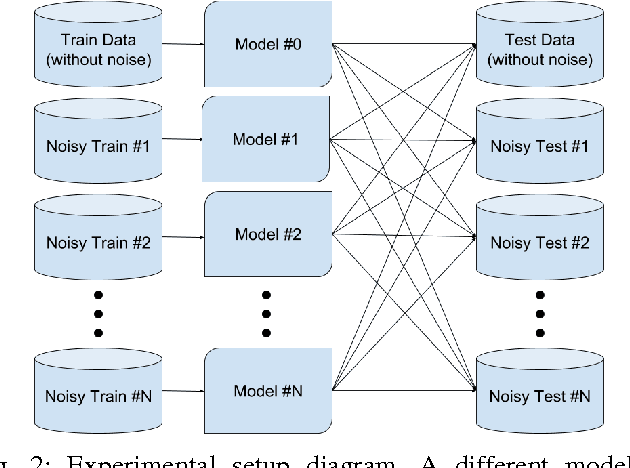

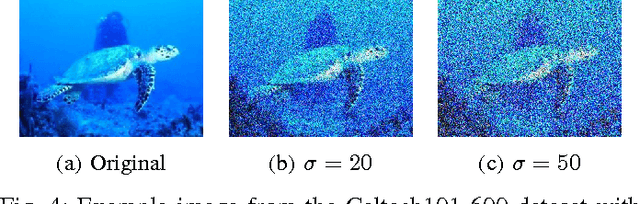
Image classification is one of the main research problems in computer vision and machine learning. Since in most real-world image classification applications there is no control over how the images are captured, it is necessary to consider the possibility that these images might be affected by noise (e.g. sensor noise in a low-quality surveillance camera). In this paper we analyse the impact of three different types of noise on descriptors extracted by two widely used feature extraction methods (LBP and HOG) and how denoising the images can help to mitigate this problem. We carry out experiments on two different datasets and consider several types of noise, noise levels, and denoising methods. Our results show that noise can hinder classification performance considerably and make classes harder to separate. Although denoising methods were not able to reach the same performance of the noise-free scenario, they improved classification results for noisy data.
Person Re-Identification via Active Hard Sample Mining
Apr 10, 2020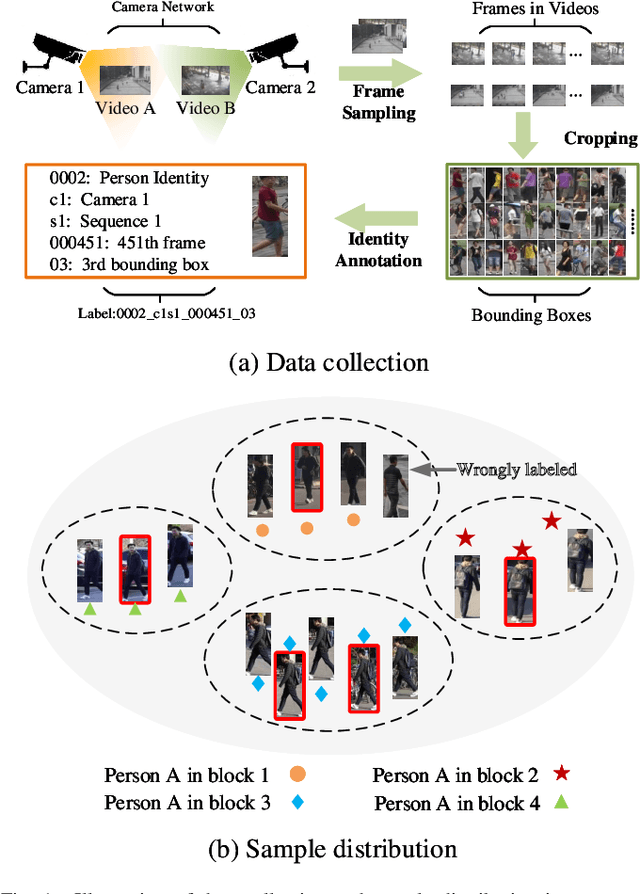
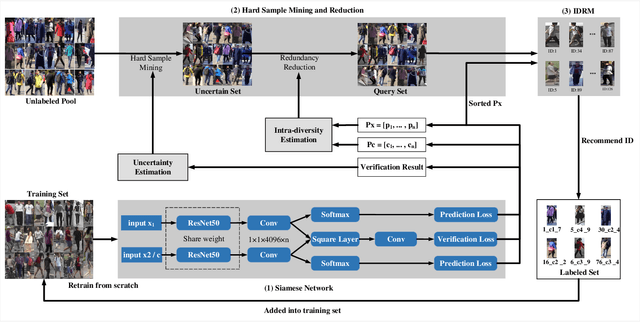
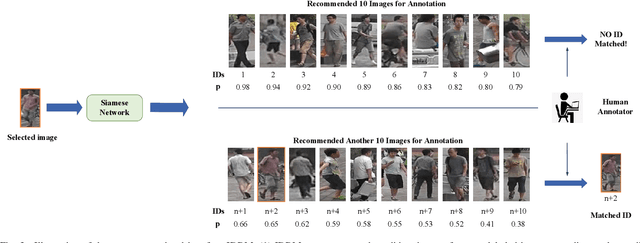

Annotating a large-scale image dataset is very tedious, yet necessary for training person re-identification models. To alleviate such a problem, we present an active hard sample mining framework via training an effective re-ID model with the least labeling efforts. Considering that hard samples can provide informative patterns, we first formulate an uncertainty estimation to actively select hard samples to iteratively train a re-ID model from scratch. Then, intra-diversity estimation is designed to reduce the redundant hard samples by maximizing their diversity. Moreover, we propose a computer-assisted identity recommendation module embedded in the active hard sample mining framework to help human annotators to rapidly and accurately label the selected samples. Extensive experiments were carried out to demonstrate the effectiveness of our method on several public datasets. Experimental results indicate that our method can reduce 57%, 63%, and 49% annotation efforts on the Market1501, MSMT17, and CUHK03, respectively, while maximizing the performance of the re-ID model.